第五章:RAG:让AI“知其所能,亦知其不能”
1. 引言:AI的“知识困境”与破局之道
在人工智能技术飞速发展的今天,大型语言模型(LLM)已展现出惊人的文本生成能力。从撰写新闻报道到创作诗歌,从代码生成到逻辑推理,AI的“才华”似乎已触及人类认知的多个领域。然而,当用户向ChatGPT询问专业医学问题时,常会得到看似合理却存在事实错误的回答;当金融分析师依赖AI进行风险评估时,模型可能因缺乏实时数据而给出过时建议。这些场景揭示了一个核心矛盾:AI的“知识广度”与“专业深度”之间存在天然鸿沟。
这种困境源于LLM的固有缺陷:其知识来源于预训练阶段的静态数据,难以动态更新;面对复杂领域问题时,模型可能因缺乏上下文关联能力而“胡编乱造”。例如,在医疗诊断中,同一症状可能对应多种疾病,而LLM往往无法结合患者病史、基因数据等动态信息进行多步推理。正如深度学习批评者Gary Marcus所言:“当前AI系统仍停留在‘记忆模仿’阶段,缺乏真正的理解与推理能力。”
在此背景下,检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生。它通过将外部知识库与生成模型深度融合,赋予AI“动态查资料”的能力,使其在生成答案前能主动检索权威信息,从而显著提升回答的准确性、专业性和可解释性。本文将系统解析RAG的技术原理、核心优势、应用场景及未来挑战,揭示其如何成为破解AI“知识困境”的关键钥匙。
2、RAG的技术本质:从“闭卷考试”到“开卷作答”
2.1 传统LLM的“记忆依赖”与局限性
传统LLM的工作模式类似于“闭卷考试”:模型通过预训练阶段的海量文本学习,将知识压缩为参数权重,生成答案时完全依赖内部记忆。这种模式在通用领域表现优异,但在专业场景中暴露出三大缺陷:
- 知识时效性差:模型无法实时获取最新数据。例如,2025年新发布的医学指南或金融政策无法被已训练的LLM感知。
- 领域深度不足:专业领域(如法律、科研)需要精确的多步推理,而LLM在长推理链中易丢失逻辑一致性。例如,在法律案件分析中,模型可能忽略关键法条的上下文关联。
- 上下文敏感性弱:同一术语在不同场景下含义迥异,LLM常无法捕捉细微差别。如“细胞”在生物学中指生命基本单位,在金融领域可能代指“小额资金”。
2.2 RAG的“检索-生成”双引擎架构
RAG通过引入外部知识库,将AI的工作模式转变为“开卷作答”。其核心流程分为三步:
- 知识检索:根据用户输入,从结构化/非结构化知识库中检索相关文档片段。例如,在医疗问答中,系统会从电子健康记录、临床指南中提取患者病史和诊疗建议。
# 简化的RAG检索过程示意
def retrieve_information(question, knowledge_base):# 将问题转换为向量表示question_embedding = embed(question)# 在知识库中寻找最相关的文档relevant_docs = vector_search(question_embedding, knowledge_base)return relevant_docs- 信息融合:将检索结果与原始问题输入生成模型,结合上下文生成答案。例如,结合患者症状和最新研究,生成包含用药禁忌的个性化治疗方案。
- 结果验证:通过标注信息来源、展示推理路径,增强答案的可信度。例如,在金融分析中,模型会引用实时市场数据并说明分析逻辑。
技术实现层面,RAG依赖两大关键组件:
- 检索模块:采用向量搜索(如FAISS)、语义匹配(如BERT)或图遍历算法,从知识库中定位最相关内容。例如,谷歌Vertex AI Search通过两阶段检索(近似最近邻算法初筛+深度学习模型重排序)提升准确性。
- 生成模块:基于Transformer架构的LLM(如GPT-4、Qwen)将检索信息整合为自然语言回答。例如,在科研文献综述中,模型可结合1200篇论文生成结构化报告。
2.3 RAG与传统RAG的进化:从“文本块”到“知识图谱”
早期RAG技术(如Facebook 2020年提出的原型)通过分割文档为独立文本块并向量存储,实现了基础检索功能。然而,这种“碎片化”方式在专业领域面临两大挑战:
- 复杂查询理解困难:专业问题常涉及多实体、多关系(如“结合患者基因突变和最新靶向药研究推荐治疗方案”),传统RAG难以捕捉语义关联。
- 分散知识整合不足:领域知识分散在文档、数据库中,传统RAG因牺牲上下文信息导致检索准确性下降。
为解决这些问题,图检索增强生成(GraphRAG)应运而生。其核心创新在于:
- 知识图谱构建:自动提取实体(如疾病、药物)和关系(如“治疗”“禁忌”),形成结构化网络。例如,在医疗领域构建包含症状、检查、疗法的动态图谱。
- 多跳推理支持:通过图遍历算法沿关系路径扩展,发现隐含关联。例如,从“胸痛”出发,遍历“冠心病→PCI手术→双抗治疗”路径,生成完整诊疗建议。
- 可解释性增强:保留知识结构关系,生成答案时展示推理路径。例如,在法律咨询中,模型会标注“根据《民法典》第1062条和类似案例判决”。
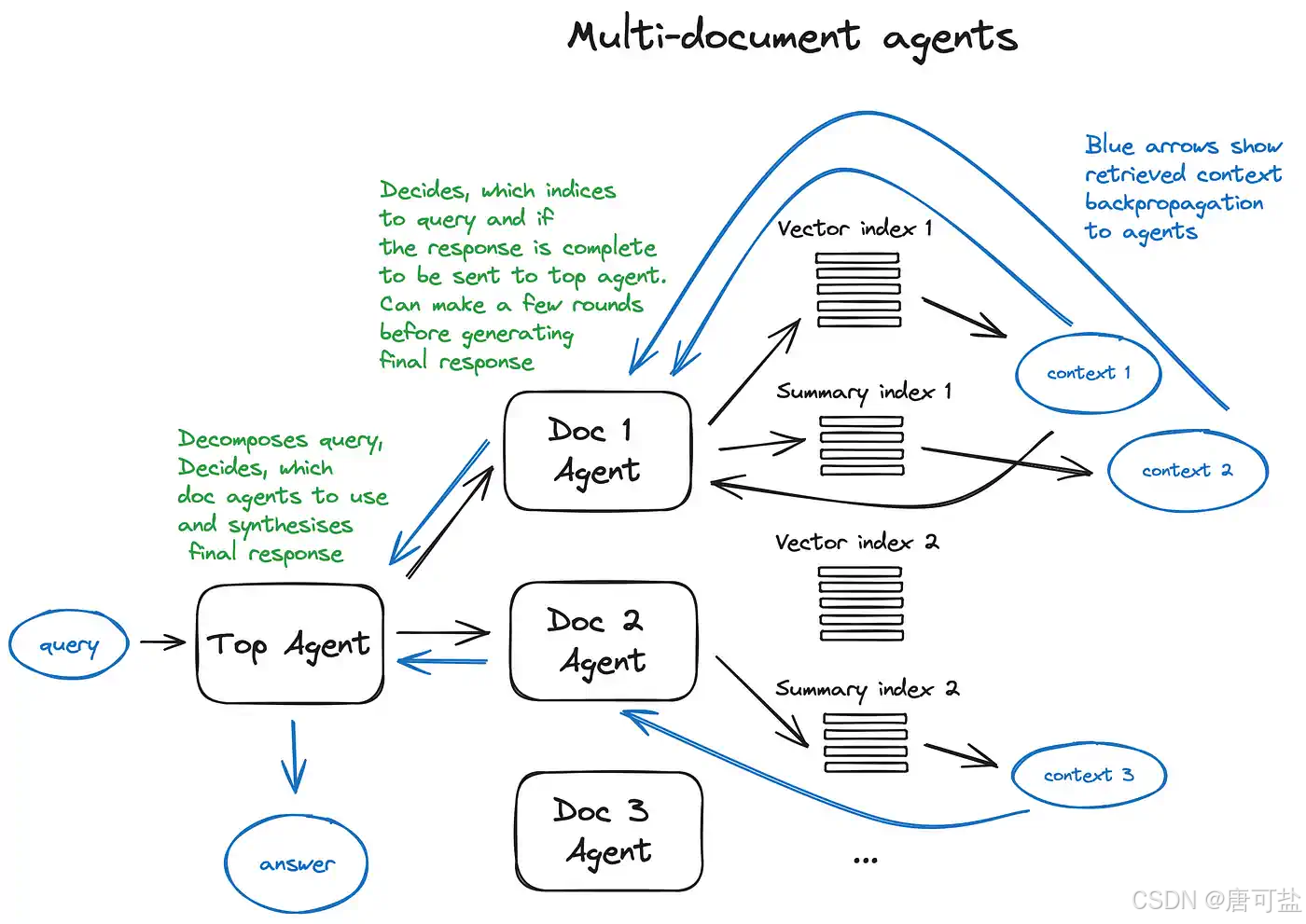
3. RAG如何实现“知不知”的技术突破
3.1. RAG的核心机制:从“记忆作答”到“检索生成”
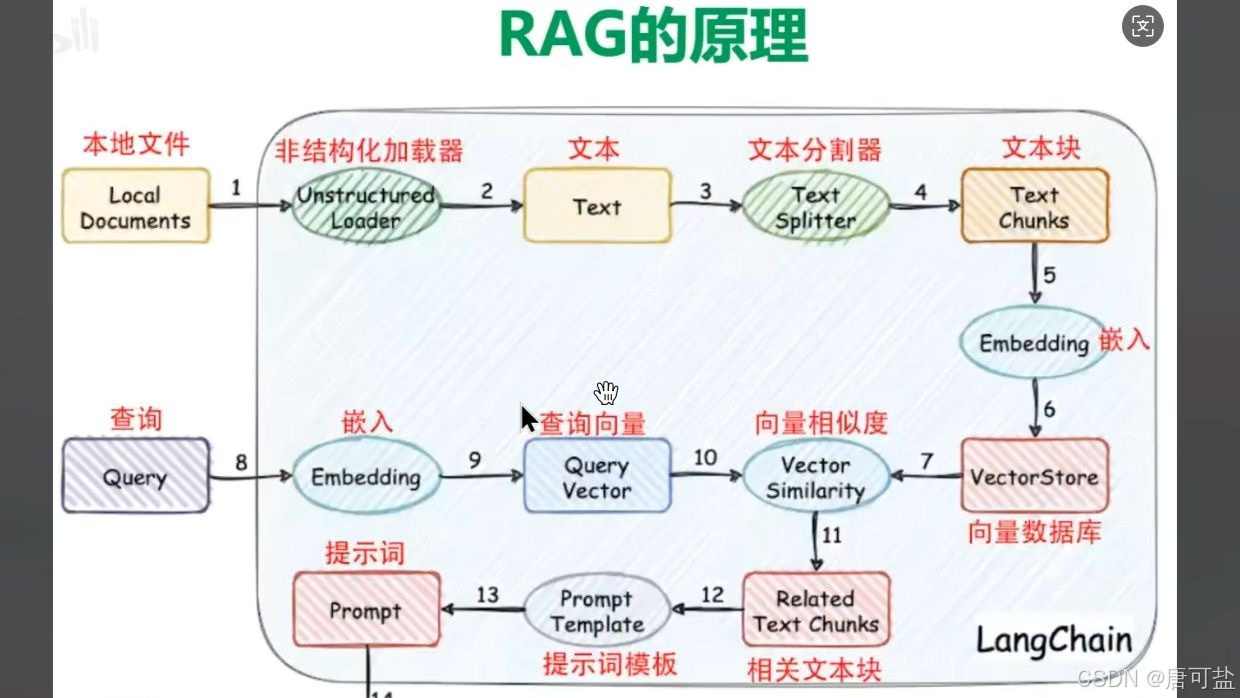
RAG的核心思想可以概括为八个字:先检索,后生成。它将信息检索与内容生成两个环节有机结合,形成一个闭环的智能问答系统。整个流程可分为三个核心阶段:索引构建、相似性检索与增强生成。
3.1.1. 索引构建:为知识库“编码”
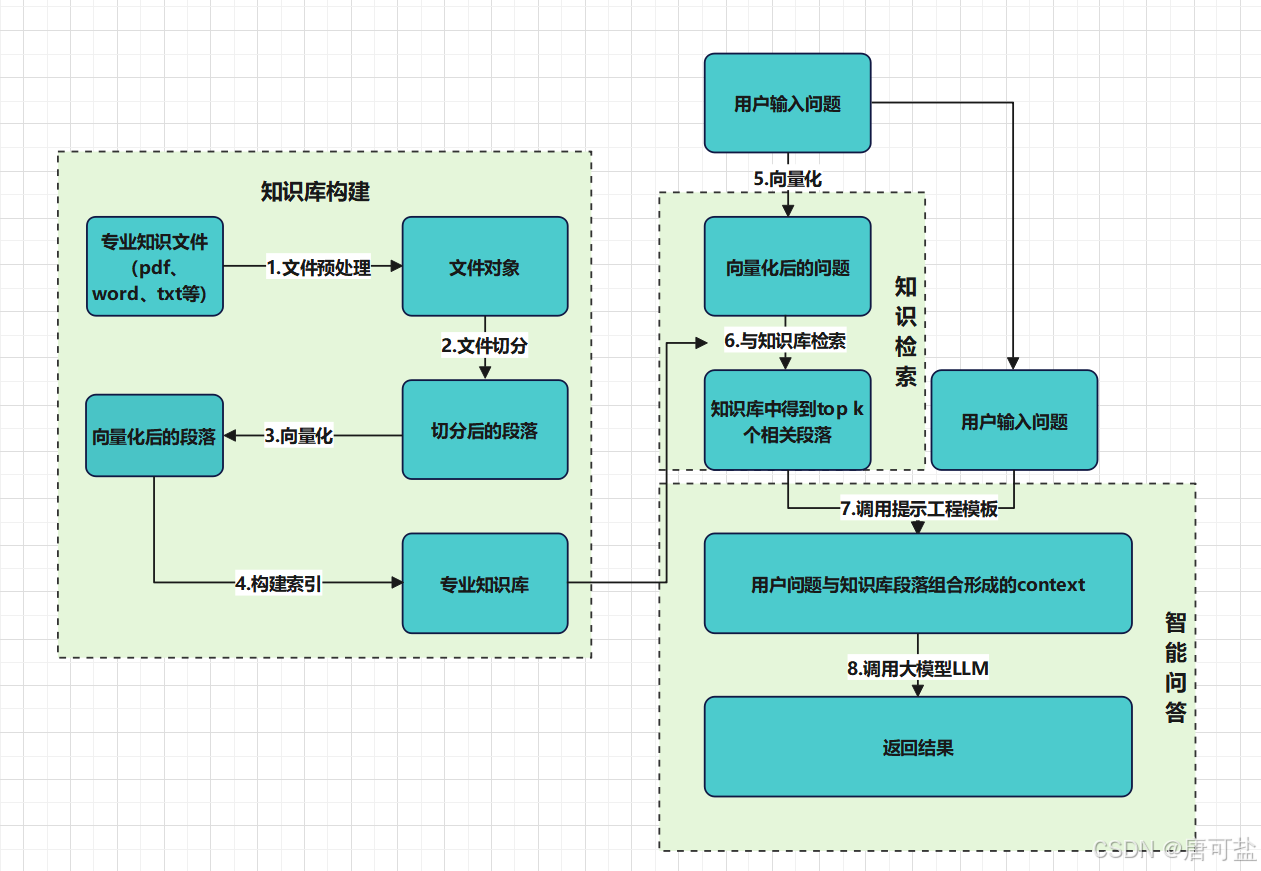
索引构建是RAG的基石,相当于为AI建立一个可快速查阅的“数字图书馆”。这一过程包括以下步骤:
- 数据加载:系统首先从各种来源(如PDF文档、网页、数据库、Excel表格等)收集原始数据。这些数据可能是企业的产品手册、历史工单、技术白皮书,或是公开的学术论文、新闻资讯。
- 文本分块(Chunking):原始文档通常很长,直接处理效率低下且容易丢失关键信息。因此,需要将长文本分割成较小的片段,称为“块”(chunk)。每个块通常包含200至1000个字符(或token),确保语义的完整性。常见的分块策略包括按段落或句子边界切割,或使用递归分块器(Recursive Text Splitter)优先在语义断点处分割。
- 向量嵌入(Embedding):计算机无法直接理解文字的含义,因此需要将文本转化为数学向量。通过使用BERT、Sentence-BERT、BGE等嵌入模型,每个文本块被转换为一个高维向量(如768维)。这些向量捕捉了文本的语义信息,使得语义相近的文本(如“苹果手机”和“iPhone”)在向量空间中距离更近。
- 向量存储:生成的向量及其对应的原始文本被存储到专门的向量数据库中,如FAISS、Milvus、Pinecone或Chroma。这些数据库支持高效的相似性搜索,能够在毫秒级时间内从海量数据中找到最相关的片段。
3.1.2. 相似性检索:AI的“资料筛选员”
当用户提出问题时,RAG系统进入检索阶段。这一过程模拟了人类“查资料”的行为:
- 查询向量化:用户的提问(query)同样被送入嵌入模型,转换为与文档块相同维度的向量。
- 相似度计算:系统在向量数据库中计算查询向量与所有文档向量的相似度。常用的算法包括余弦相似度、点积或欧几里得距离。相似度最高的Top-K个文档块(如前5个)被选为候选答案。
- 检索策略优化:为了提高检索的准确性和召回率,现代RAG系统采用多种高级策略:
- 混合检索(Hybrid Retrieval):结合语义检索(向量相似度)和关键词检索(如BM25),兼顾语义理解和精确匹配。
- 查询重写:将用户模糊的提问(如“怎么修电脑?”)重写为多个更具体的子问题(如“电脑蓝屏怎么办?”、“电脑无法开机如何处理?”),以提高检索覆盖率。
- 元数据过滤:利用文档的元数据(如发布日期、作者、分类)进行过滤,确保检索结果的时效性和相关性。
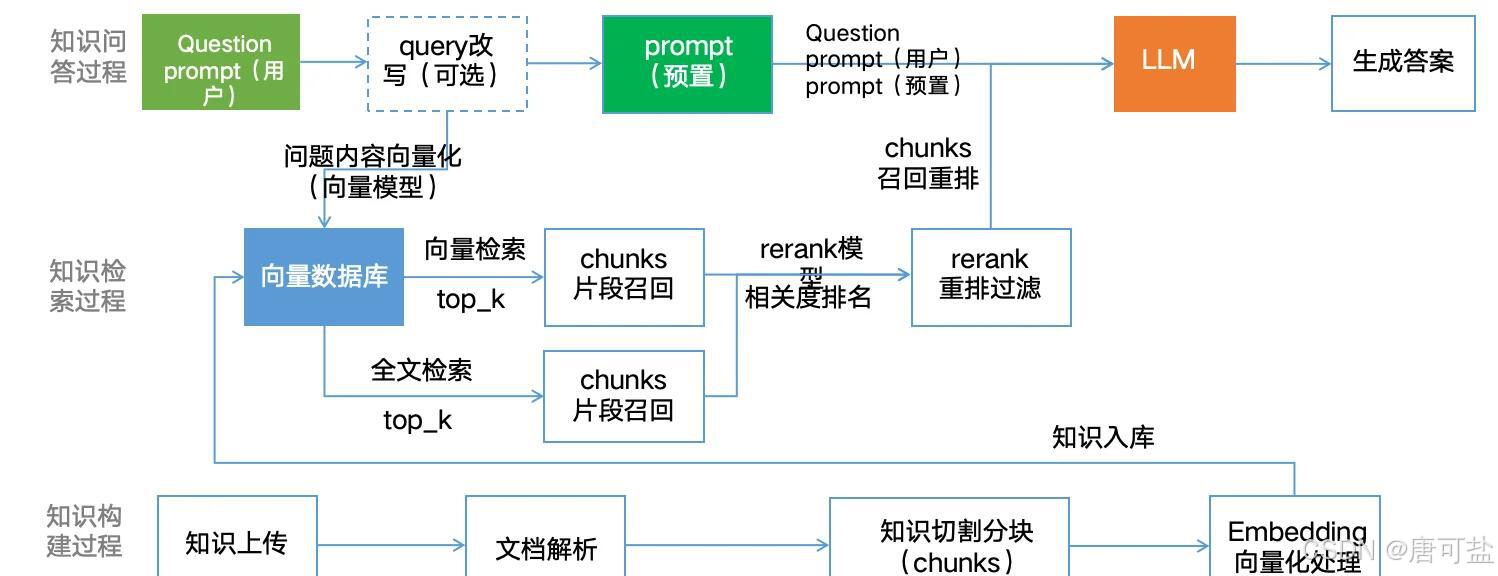
3.1.3. 增强生成:基于证据的“答案组装”
检索到的相关文档块并非最终答案,而是作为“参考资料”输入给大语言模型。这一阶段的关键是提示工程(Prompt Engineering):
- 构建增强提示(Augmented Prompt):系统将用户的原始问题、检索到的相关文本片段以及生成指令(如“请基于以下信息回答”)组合成一个结构化的提示词(prompt)。
- 生成最终响应:大语言模型接收此增强提示,结合自身的语言能力,生成逻辑清晰、自然流畅的回答。由于回答基于真实文档,其准确性和可追溯性大大提高。
- 结果重排序与上下文压缩:在生成前,系统可能对检索结果进行二次筛选(重排序),剔除冗余或低相关性内容,确保LLM只处理最优质的信息。
举例说明:场景:用户向一个企业知识库AI助手提问。
第一步:用户提出原始问题
原始问题: “我们公司今年的年假制度有什么变化?”
第二步:系统检索相关文本片段
系统在内部文档、知识库或数据库中搜索,找到了以下最相关的一段文本(这可能是来自公司HR的最新通知):
检索到的文本片段:
【人力资源部通知 - 2024年1月更新】
自2024年1月1日起,公司年假制度调整如下:
员工累计工作已满1年不满10年的,年休假天数从原来的7天调整为10天。
员工累计工作已满10年不满20年的,年休假天数维持15天不变。
新增“福利年假”:司龄每满一年,额外增加1天福利年假,上限为10天。
年假申请需提前至少3个工作日通过OA系统提交。
第三步:构建增强提示(Augmented Prompt)
系统将以上三个部分组合成一个结构清晰、指令明确的提示词。这是最关键的一步,它直接决定了模型回答的质量和准确性。
【最终构建的结构化提示词】
text
请基于以下信息,准确、清晰地回答用户的问题。如果信息不足以回答问题,请直接说明。
【相关信息】
【人力资源部通知 - 2024年1月更新】
自2024年1月1日起,公司年假制度调整如下:
1. 员工累计工作已满1年不满10年的,年休假天数从原来的7天调整为10天。
2. 员工累计工作已满10年不满20年的,年休假天数维持15天不变。
3. 新增“福利年假”:司龄每满一年,额外增加1天福利年假,上限为10天。
4. 年假申请需提前至少3个工作日通过OA系统提交。
【用户问题】
我们公司今年的年假制度有什么变化?
【回答要求】
请用简洁的列表形式概括主要变化。
第四步:大语言模型(LLM)的响应
现在,大语言模型收到了这个结构化的增强提示。它清楚地知道:
任务:基于【相关信息】回答【用户问题】。
格式:用简洁的列表形式概括变化。
边界:不能胡编乱造,答案必须来自提供的信息。
因此,LLM会生成类似下面的回答:
根据公司2024年的最新规定,年假制度的主要变化如下:
法定年假增加:工龄1-10年的员工,年假从7天增加至10天。
新增福利年假:引入了“福利年假”制度,根据司龄每年增加1天(上限10天)。
申请流程明确:年假申请需提前至少3个工作日通过OA系统提交。
(注:工龄10-20年员工的15天年假规定保持不变。)
3.2. RAG的技术优势:为何它是AI进化的关键一步?
RAG的出现,标志着AI从“封闭式推理”向“开放式检索推理”的重要转变。其技术优势体现在多个维度:
1. 知识实时性与动态更新
RAG系统无需重新训练模型即可更新知识。企业只需将新政策、新产品文档或最新研究报告添加到知识库中,系统便能立即检索并引用。这使得AI能够持续保持“与时俱进”,在新闻、金融、科技等快速变化的领域具有巨大优势。
2. 答案可追溯,提升可信度
RAG生成的答案通常附带来源引用,用户可以点击链接查看原始文档。这种“可追溯性”极大增强了AI的可信度,尤其在医疗、法律、教育等高风险领域,用户不再需要盲目相信AI的“黑箱”输出。
3. 降低“幻觉”,增强可靠性
由于回答必须基于检索到的真实信息,RAG显著减少了AI“胡编乱造”的可能性。当知识库中没有相关信息时,AI可以明确告知“未找到相关资料”,而非强行生成错误答案,真正实现了“知其不能”。
4. 成本效益与领域适应性
相比微调大模型,RAG的部署和维护成本更低。企业无需投入大量算力进行模型训练,只需构建和维护知识库即可。同时,通过更换知识库,同一套RAG系统可快速应用于客服、法律、医疗、教育等多个场景,展现出极强的灵活性。
3. Embedding模型选择
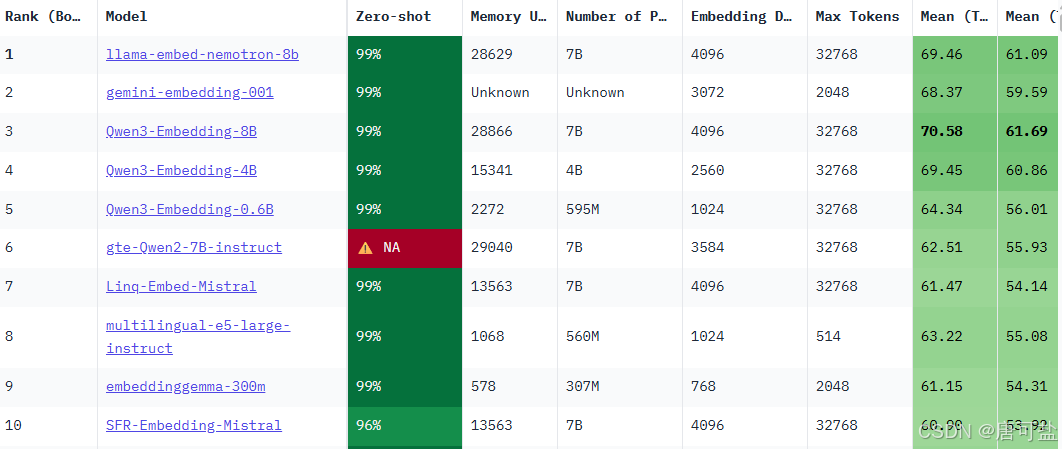
最权威的MTEB榜单由Hugging Face维护,比较了1000多种语言中的100多种文本嵌入模型。
官网地址:https://huggingface.co/spaces/mteb/leaderboard
3.1. 常见的Embedding模型
3.1.1. 通用文本嵌入模型
1. BGE-M3(智源研究院)
• 特点:支持100+语言,输入长度达8192 tokens,融合密集、稀疏、多向量混合检索,适合跨语言长文档检索。
• 适用场景:跨语言长文档检索、高精度RAG应用。
• 文件大小:2.3G
2. text-embedding-3-large(OpenAI)
• 特点:向量维度3072,长文本语义捕捉能力强,英文表现优秀。
• 适用场景:英文内容优先的全球化应用。
3. Jina-embeddings-v2-small(Jina AI)
• 特点:参数量仅35M,支持实时推理(RT<50ms),适合轻量化部署。
• 适用场景:轻量级文本处理、实时推理任务。
3.1.2. 中文嵌入模型
1. xiaobu-embedding-v2
• 特点:针对中文语义优化,语义理解能力强。
• 适用场景:中文文本分类、语义检索。
2. M3E-Base
• 特点:针对中文优化的轻量模型,适合本地私有化部署。
• 适用场景:中文法律、医疗领域检索任务。
• 文件大小:0.4G (m3e-base)
3. stella-mrl-large-zh-v3.5-1792
• 特点:处理大规模中文数据能力强,捕捉细微语义关系。
• 适用场景:中文文本高级语义分析、自然语言处理任务。
3.1.3. 指令驱动与复杂任务模型
1. gte-Qwen2-7B-instruct(阿里巴巴)
• 特点:基于Qwen大模型微调,支持代码与文本跨模态检索。
• 适用场景:复杂指令驱动任务、智能问答系统。
2. E5-mistral-7B(Microsoft)
• 特点:基于Mistral架构,Zero-shot任务表现优异。
• 适用场景:动态调整语义密度的复杂系统。
3.1.4. 企业级与复杂系统
1. BGE-M3(智源研究院)
• 特点:适合企业级部署,支持混合检索。
• 适用场景:企业级语义检索、复杂RAG应用。
2. E5-mistral-7B(Microsoft)
• 特点:适合企业级部署,支持指令微调。
• 适用场景:需要动态调整语义密度的复杂系统。
3.2. Embedding模型使用示例
3.2.1. bge-m3模型使用
from FlagEmbedding import BGEM3FlagModel
model = BGEM3FlagModel('BAAI/bge-m3', use_fp16=True) # Setting use_fp16 to True speeds up
computation with a slight performance degradationsentences_1 = ["What is BGE M3?", "Defination of BM25"]sentences_2 = ["BGE M3 is an embedding model supporting dense
retrieval, lexical matching and multi-vector interaction.", "BM25 is a bag-of-words retrieval function that ranks a set of
documents based on the query terms appearing in each document"]
embeddings_1 = model.encode(sentences_1, batch_size=12, max_length=8192, # If you don't need such a
long length, you can set a smaller value to speed up the
encoding process.)['dense_vecs']
embeddings_2 = model.encode(sentences_2)['dense_vecs']
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
输出结果:
[[0.626 0.3477]
[0.3499 0.678 ]]
similarity = embeddings_1 @ embeddings_2.T
在计算两组嵌入向量(embeddings)之间的相似度矩阵。
embeddings_1 包含了第一组句子 (sentences_1) 的嵌入向量,形状为 [sentences_1的数量, 嵌入维度]
embeddings_2 包含了第二组句子 (sentences_2) 的嵌入向量,形状为 [sentences_2的数量, 嵌入维度]
embeddings_2.T 是对 embeddings_2 进行转置操作,形状变为[嵌入维度, sentences_2的数量]
@ 符号在Python中表示矩阵乘法运算
=> 通过矩阵乘法计算了两组句子之间的余弦相似度矩阵。结果 similarity 的形状是 [sentences_1的数量, sentences_2的数量]。
[[0.626 0.3477]
[0.3499 0.678 ]]
可以看出:
"What is BGE M3?" 与 "BGE M3 is an embedding model..." 的相似度为 0.6265(较高)
"What is BGE M3?" 与 "BM25 is a bag-of-words retrieval
function..." 的相似度为 0.3477(较低)
"Defination of BM25" 与 "BGE M3 is an embedding model..." 的相似度为 0.3499(较低)
"Defination of BM25" 与 "BM25 is a bag-of-words retrieval
function..." 的相似度为 0.678(较高)
3.2.2. gte-qwen2模型使用
import torch
import torch.nn.functional as F
from torch import Tensor
from modelscope import AutoTokenizer, AutoModel# 定义最后一个token池化函数
# 该函数从最后的隐藏状态中提取每个序列的最后一个有效token的表示
def last_token_pool(last_hidden_states: Tensor,attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])if left_padding:
return last_hidden_states[:, -1]else:
sequence_lengths = attention_mask.sum(dim=1) - 1batch_size = last_hidden_states.shape[0]return last_hidden_states[torch.arange(batch_size,
device=last_hidden_states.device), sequence_lengths]# 将任务描述和查询组合成特定格式的指令
def get_detailed_instruct(task_description: str, query: str) -> str:return f'Instruct: {task_description}\nQuery: {query}'
task = 'Given a web search query, retrieve relevant passages that answer the
query'
queries = [get_detailed_instruct(task, 'how much protein should a female eat'), # 女性应该摄入多少蛋白质get_detailed_instruct(task, 'summit define') # summit(顶峰)的定义
]# 检索文档
documents = ["As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.", # 关于女性蛋白质摄入量的文档"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments." # 关于summit定义的文档
]
# 将查询和文档合并为一个输入文本列表
input_texts = queries + documents# 设置模型路径
model_dir = "/root/autodl-tmp/models/iic/gte_Qwen2-1___5B-instruct"
# 加载分词器,trust_remote_code=True允许使用远程代码
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# 加载模型
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True)
max_length = 8192
batch_dict = tokenizer(input_texts, max_length=max_length, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
# 使用last_token_pool函数从最后的隐藏状态中提取每个序列的表示
embeddings = last_token_pool(outputs.last_hidden_state,
batch_dict['attention_mask'])embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())输出结果:
[[78.49691772460938, 17.04286003112793],
[14.924489974975586, 75.37960815429688]]
总结:
gte-Qwen2-7B-instruct 是基于 Qwen2的指令优化型嵌入模型
- 指令优化:经过大量指令-响应对的训练,特别擅长理解和生成高质量的文本。
- 性能表现:在文本生成、问答系统、文本分类、情感分析、命名实体识别和语义匹配等任务中表现优异。
- 适合场景:适合复杂问答系统,处理复杂的多步推理问题,能够生成准确且自然的答案。
- 优势:
- 指令理解和执行能力强,适合复杂的指令驱动任务。
- 多语言支持,能够处理多种语言的文本。
- 在文本生成和语义理解任务中表现优异。
- 局限:
- 计算资源需求较高,适合资源充足的环境。
4. 项目实战:迪士尼RAG助手
4.1. 需求描述
- 为迪士尼构建一个7x24小时在线的AI客服助手:
- 自动化解答高频问题:如票务、入园须知、会员权益等,降低人工客服压力。
- 提供准确的回答:确保所有回答均来自官方知识库,避免信息错误或过时。
- 处理多模态查询:不仅能回答文本问题,还能理解并回应关于图片(如活动海报)的查询。
- 需求难点有哪些:
知识来源多样化:知识库包含多种格式的文档,如 PDF 格式的官方规定、Word 格式的内部FAQ、网页公告、以及包含大量图片和表格的活动介绍文件。
- 非结构化数据处理:如何有效提取并理解 PDF 和 Word 文档中的表格与图片信息,这是RAG成功的关键。
- 知识的有效组织:如何将海量、零散的知识点切片(Chunking)并建立索引,确保检索的准确性。
- 保证答案的有效性:如何让最终生成的答案严格基于检索到的内容,避免LLM出现幻觉。
- 背景信息

4.2. 技术选型
- 文档处理库: PyMuPDF (处理PDF), python-docx (处理Word), pytesseract (OCR识别图片中的文字)。
- 文本Embedding模型: text-embedding-v4 (性能优秀,支持可变维度)。
- 图像Embedding模型: CLIP (由OpenAI开发,能同时理解图片和文本,是多模态RAG的核心)。
- 向量数据库/库: FAISS,作为向量检索引擎的核心,性能极高
注意:在生产环境中,可以使用Milvus, ChromaDB 或 Elasticsearch,他们提供了完整数据管理服务
- LLM: Qwen-turbo 用于最终答案的生成。
- 流程编排框架: 不依赖于LangChain,直接使用底层API
4.3. 数据预处理
4.3.1. docx格式文档处理
代码示例
def parse_docx(file_path):doc = DocxDocument(file_path)content_chunks = []
for element in doc.element.body:if element.tag.endswith('p'): # 段落处理paragraph_text = ""for run in element.findall('.//w:t', {'w':
'http://schemas.openxmlformats.org/wordprocessingml/2006/main'}):paragraph_text += run.text if run.text else "" if paragraph_text.strip():content_chunks.append({"type": "text", "content":
paragraph_text.strip()}) elif element.tag.endswith('tbl'): # 表格处理转换为Markdown格式md_table = []table = [t for t in doc.tables if t._element is element][0]if table.rows:header = [cell.text.strip() for cell in table.rows[0].cells]md_table.append("| " + " | ".join(header) + " |")md_table.append("|" + "---|"*len(header))for row in table.rows[1:]:row_data = [cell.text.strip() for cell in row.cells]md_table.append("| " + " | ".join(row_data) + " |")table_content = "\n".join(md_table)if table_content.strip():content_chunks.append({"type": "table", "content": table_content})
return content_chunks- 整体功能:
函数 parse_docx 读取一个 .docx 文件,遍历文件中的所有元素 (段落和表格),并将它们提取成一个个独立的内容区块 (chunks)。
- 段落处理 (if element.tag.endswith('p')):
找出文档中的所有段落。
它会逐一提取每个段落内的纯文本内容,去除多余的空白,然后将其标记为 "type": "text" 并存储起来。
- 表格处理 (elif element.tag.endswith('tbl')):
专门处理文档中的“表格”。
它会将 Word 原生的表格格式转换为通用的 Markdown 格式。程序会先读取表头,然后逐行读取单元格数据,最后组合成 Markdown 表格字符串,并标记为 "type": "table"。
4.3.2. pdf格式文档处理
代码示例
def parse_pdf(file_path, image_dir):doc = fitz.open(file_path)content_chunks = []for page_num, page in enumerate(doc):# 提取文本text = page.get_text("text")content_chunks.append({"type": "text", "content": text, "page": page_num + 1})# 提取图片for img_index, img in enumerate(page.get_images(full=True)):xref = img[0]base_image = doc.extract_image(xref)image_bytes = base_image["image"]image_ext = base_image["ext"]image_path = os.path.join(image_dir,
f"{os.path.basename(file_path)}_p{page_num+1}_{img_index}.{image_ext}")with open(image_path, "wb") as f:f.write(image_bytes)content_chunks.append({"type": "image", "path": image_path, "page": page_num + 1})return content_chunks- 整体功能:
parse_pdf 使用 fitz (PyMuPDF) 库打开并逐页读取 PDF 文档。它的核心目标是将 PDF 这种复合式文档,拆解成纯文本和独立的图片文件,以便 RAG 模型后续能分别处理和理解。
- 文本提取 (page.get_text("text")):
代码遍历每一页,使用 get_text() 方法抓取该页所有的纯文本内容。
它将每页的文本保存为一个独立的区块 (chunk),并附上页码。
- 图片提取 (page.get_images()):
侦测并提取页面中的所有嵌入图片。
它将每张图片的二进制数据读取出来,以唯一的文件名(包含原始文件名、页码和图片索引)保存到指定的image_dir 目录下。同时,它会记录图片的存储路径
4.3.3. 图片文件格式处理(.jpg .png .jpeg)
代码示例
def image_to_text(image_path):try:image = Image.open(image_path)# OCR文字识别ocr_text = pytesseract.image_to_string(image, lang='chi_sim+eng').strip()return {"ocr": ocr_text}except Exception as e:print(f"处理图片失败 {image_path}: {e}")return {"ocr": ""}
- image_to_text 的作用是“看图识字”
它接收一个图片文件的路径,通过OCR,提取图片中包含的文字信息,适合扫描版 PDF 或截图。
- OCR 技术 (pytesseract.image_to_string):
代码调用了 pytesseract 库,它是 Tesseract OCR 引擎的Python 封装。
image_to_string 方法是执行识别的核心。
lang='chi_sim+eng' 参数告诉 OCR 引擎要同时识别简体中文和英文两种语言
4.3.4. 文本模态处理
代码示例
def get_text_embedding(text):response = client.embeddings.create(model="text-embedding-v4",input=text,dimensions=1024
)return response.data[0].embedding维度:1024维
模型:text-embedding-v4
适用:语义相似度计算
4.3.5. 图像模态处理
1. 代码示例:CLIP图像Embeddin
def get_image_embedding(image_path):image = Image.open(image_path)inputs = clip_processor(images=image, return_tensors="pt")with torch.no_grad():image_features = clip_model.get_image_features(**inputs)return image_features[0].numpy()维度:512维
模型:CLIP ViT-Base-Patch32
适用:跨模态检索
2. 代码示例: CLIP文本Embedding(用于图像检索)
def get_clip_text_embedding(text):inputs = clip_processor(text=text, return_tensors="pt")with torch.no_grad():text_features = clip_model.get_text_features(**inputs)return text_features[0].numpy()- 与图像向量在同一空间
- 支持跨模态相似度计算
- 用于文本到图像的检索
4.3.6. 混合检索策略
代码示例
# 文本检索
query_text_vec =
np.array([get_text_embedding(query)]).astype('float32')
distances, text_ids = text_index.search(query_text_vec, k)# 图像检索
if any(keyword in query.lower() for keyword in image_keywords):query_clip_vec =
np.array([get_clip_text_embedding(query)]).astype('float32')distances, image_ids = image_index.search(query_clip_vec, 2)# 混合排序
text_results = [(match, distance, "text") for match, distance in
zip(matches, distances)]
image_results = [(match, distance, "image") for match, distance in
zip(matches, distances)]# 优先文本,强制包含图像
for result, distance, result_type in sorted(text_results,
key=lambda x: x[1]):retrieved_context.append(result)
if image_results:best_image = min(image_results, key=lambda x: x[1])retrieved_context.append(best_image[0])结合文本和图像的搜索结果,为LLM提供更丰富的上下文:
- 并行检索:文本与图像分路进行
代码首先会无条件地执行文本检索。它将用户查询(query)向量化,然后在文本索引库 (text_index) 中搜索最相似的 k 个文本片段。
与此同时,它会进行一次判断:仅当用户查询包含“海报”、“图片”等预设的图像关键词时,才会触发图像检索。图像检索使用专门的 CLIP 模型生成向量,并在图像索引库 (image_index) 中搜索最相关的图片。
- 排序策略:“文本优先,强制包含最佳图片”
采用了一种有偏向的策略。
首先,将所有检索到的文本结果按照相关性(距离 distance)从高到低排序。
然后,如果图像检索被触发,它会从图片结果中选出唯一一张最相关的图片(best_image)
4.4. 源码示例
1. 固定长度切片
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
固定长度切片策略
在句子边界进行切分,避免切断句子
"""def improved_fixed_length_chunking(text, chunk_size=512, overlap=50):"""改进的固定长度切片 - 在句子边界切分"""chunks = []start = 0while start < len(text):end = start + chunk_size# 尝试在句子边界切分if end < len(text):# 寻找最近的句子结束符for i in range(end, max(start, end - 100), -1):if text[i] in '.!?。!?':end = i + 1breakchunk = text[start:end]if len(chunk.strip()) > 0:chunks.append(chunk.strip())start = end - overlapreturn chunksdef print_chunk_analysis(chunks, method_name):"""打印切片分析结果"""print(f"\n{'='*60}")print(f"📋 {method_name}")print(f"{'='*60}")if not chunks:print("❌ 未生成任何切片")returntotal_length = sum(len(chunk) for chunk in chunks)avg_length = total_length / len(chunks)min_length = min(len(chunk) for chunk in chunks)max_length = max(len(chunk) for chunk in chunks)print(f"📊 统计信息:")print(f" - 切片数量: {len(chunks)}")print(f" - 平均长度: {avg_length:.1f} 字符")print(f" - 最短长度: {min_length} 字符")print(f" - 最长长度: {max_length} 字符")print(f" - 长度方差: {max_length - min_length} 字符")print(f"\n📝 切片内容:")for i, chunk in enumerate(chunks, 1):print(f" 块 {i} ({len(chunk)} 字符):")print(f" {chunk}")print()# 测试文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""if __name__ == "__main__":print("🎯 固定长度切片策略测试")print(f"📄 测试文本长度: {len(text)} 字符")# 使用改进的固定长度切片chunks = improved_fixed_length_chunking(text, chunk_size=300, overlap=50)print_chunk_analysis(chunks, "固定长度切片")2. 语义切片
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
语义切片策略
基于句子边界进行切分,保持语义完整性
"""import redef semantic_chunking(text, max_chunk_size=512):"""基于语义的切片 - 按句子分割"""# 使用正则表达式分割句子sentences = re.split(r'[.!?。!?\n]+', text)chunks = []current_chunk = ""for sentence in sentences:sentence = sentence.strip()if not sentence:continue# 如果当前句子加入后超过最大长度,保存当前块if len(current_chunk) + len(sentence) > max_chunk_size and current_chunk:chunks.append(current_chunk.strip())current_chunk = sentenceelse:current_chunk += " " + sentence if current_chunk else sentence# 添加最后一个块if current_chunk.strip():chunks.append(current_chunk.strip())return chunksdef print_chunk_analysis(chunks, method_name):"""打印切片分析结果"""print(f"\n{'='*60}")print(f"📋 {method_name}")print(f"{'='*60}")if not chunks:print("❌ 未生成任何切片")returntotal_length = sum(len(chunk) for chunk in chunks)avg_length = total_length / len(chunks)min_length = min(len(chunk) for chunk in chunks)max_length = max(len(chunk) for chunk in chunks)print(f"📊 统计信息:")print(f" - 切片数量: {len(chunks)}")print(f" - 平均长度: {avg_length:.1f} 字符")print(f" - 最短长度: {min_length} 字符")print(f" - 最长长度: {max_length} 字符")print(f" - 长度方差: {max_length - min_length} 字符")print(f"\n📝 切片内容:")for i, chunk in enumerate(chunks, 1):print(f" 块 {i} ({len(chunk)} 字符):")print(f" {chunk}")print()# 测试文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""if __name__ == "__main__":print("🎯 语义切片策略测试")print(f"📄 测试文本长度: {len(text)} 字符")# 使用语义切片chunks = semantic_chunking(text, max_chunk_size=300)print_chunk_analysis(chunks, "语义切片")3. LLM语义切片
from openai import OpenAI
import json
import os
import redef advanced_semantic_chunking_with_llm(text, max_chunk_size=512):"""使用LLM进行高级语义切片"""# 检查环境变量api_key = os.getenv("DASHSCOPE_API_KEY")client = OpenAI(api_key=api_key,base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")prompt = f"""
请将以下文本按照语义完整性进行切片,每个切片不超过{max_chunk_size}字符。
要求:
1. 保持语义完整性
2. 在自然的分割点切分
3. 返回JSON格式的切片列表,格式如下:
{{"chunks": ["第一个切片内容","第二个切片内容",...]
}}文本内容:
{text}请返回JSON格式的切片列表:
"""try:print("正在调用LLM进行语义切片...")response = client.chat.completions.create(model="qwen-turbo-latest",messages=[{"role": "system", "content": "你是一个专业的文本切片助手。请严格按照JSON格式返回结果,不要添加任何额外的标记。"},{"role": "user", "content": prompt}])result = response.choices[0].message.contentprint(f"LLM返回结果: {result[:200]}...")# 清理结果,移除可能的Markdown代码块标记cleaned_result = result.strip()if cleaned_result.startswith('```'):# 移除开头的 ```json 或 ```cleaned_result = re.sub(r'^```(?:json)?\s*', '', cleaned_result)if cleaned_result.endswith('```'):# 移除结尾的 ```cleaned_result = re.sub(r'\s*```$', '', cleaned_result)# 解析JSON结果chunks_data = json.loads(cleaned_result)# 处理不同的返回格式if "chunks" in chunks_data:return chunks_data["chunks"]elif "slice" in chunks_data:# 如果返回的是包含"slice"字段的列表if isinstance(chunks_data, list):return [item.get("slice", "") for item in chunks_data if item.get("slice")]else:return [chunks_data["slice"]]else:# 如果直接返回字符串列表if isinstance(chunks_data, list):return chunks_dataelse:print(f"意外的返回格式: {chunks_data}")return []except json.JSONDecodeError as e:print(f"JSON解析失败: {e}")print(f"原始结果: {result}")# 尝试手动解析try:# 尝试提取JSON部分json_match = re.search(r'\{.*\}', result, re.DOTALL)if json_match:json_str = json_match.group()chunks_data = json.loads(json_str)if "chunks" in chunks_data:return chunks_data["chunks"]except:pass except Exception as e:print(f"LLM切片失败: {e}")def test_chunking_methods():"""测试不同的切片方法"""# 示例文本text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""print("\n=== LLM高级语义切片测试 ===")try:chunks = advanced_semantic_chunking_with_llm(text, max_chunk_size=300)print(f"LLM高级语义切片生成 {len(chunks)} 个切片:")for i, chunk in enumerate(chunks):print(f"LLM语义块 {i+1} (长度: {len(chunk)}): {chunk}")except Exception as e:print(f"LLM切片测试失败: {e}")if __name__ == "__main__":test_chunking_methods()4. 层次切片
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
层次切片策略
基于文档结构层次进行切片
"""def hierarchical_chunking(text, target_size=512, preserve_hierarchy=True):"""层次切片 - 基于文档结构层次进行切片"""chunks = []# 定义层次标记hierarchy_markers = {'title1': ['# ', '标题1:', '一、', '1. '],'title2': ['## ', '标题2:', '二、', '2. '],'title3': ['### ', '标题3:', '三、', '3. '],'paragraph': ['\n\n', '\n']}# 分割文本为行lines = text.split('\n')current_chunk = ""current_hierarchy = []for line in lines:line = line.strip()if not line:continue# 检测当前行的层次级别line_level = Nonefor level, markers in hierarchy_markers.items():for marker in markers:if line.startswith(marker):line_level = levelbreakif line_level:break# 如果没有检测到层次标记,默认为段落if not line_level:line_level = 'paragraph'# 判断是否需要开始新的切片should_start_new_chunk = False# 1. 如果遇到更高级别的标题,开始新切片if preserve_hierarchy and line_level in ['title1', 'title2']:should_start_new_chunk = True# 2. 如果当前切片长度超过目标大小if len(current_chunk) + len(line) > target_size and current_chunk.strip():should_start_new_chunk = True# 3. 如果遇到段落分隔符且当前切片已经足够长if line_level == 'paragraph' and len(current_chunk) > target_size * 0.8:should_start_new_chunk = True# 开始新切片if should_start_new_chunk and current_chunk.strip():chunks.append(current_chunk.strip())current_chunk = ""current_hierarchy = []# 添加当前行到切片if current_chunk:current_chunk += "\n" + lineelse:current_chunk = line# 更新层次信息if line_level != 'paragraph':current_hierarchy.append(line_level)# 处理最后一个切片if current_chunk.strip():chunks.append(current_chunk.strip())return chunksdef print_chunk_analysis(chunks, method_name):"""打印切片分析结果"""print(f"\n{'='*60}")print(f"📋 {method_name}")print(f"{'='*60}")if not chunks:print("❌ 未生成任何切片")returntotal_length = sum(len(chunk) for chunk in chunks)avg_length = total_length / len(chunks)min_length = min(len(chunk) for chunk in chunks)max_length = max(len(chunk) for chunk in chunks)print(f"📊 统计信息:")print(f" - 切片数量: {len(chunks)}")print(f" - 平均长度: {avg_length:.1f} 字符")print(f" - 最短长度: {min_length} 字符")print(f" - 最长长度: {max_length} 字符")print(f" - 长度方差: {max_length - min_length} 字符")print(f"\n📝 切片内容:")for i, chunk in enumerate(chunks, 1):print(f" 块 {i} ({len(chunk)} 字符):")print(f" {chunk}")print()# 测试文本 - 包含层次结构
text = """
# 迪士尼乐园门票指南## 一、门票类型介绍### 1. 基础门票类型
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。### 2. 特殊门票类型
年票适合经常游玩的游客,提供更多优惠和特权。VIP门票包含快速通道服务,可减少排队时间。团体票适用于10人以上团队,享受团体折扣。## 二、购票渠道与流程### 1. 官方购票渠道
购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。这些渠道提供最可靠的服务和最新的票务信息。### 2. 第三方平台
第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。建议优先选择官方渠道以确保购票安全。### 3. 证件要求
所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。## 三、入园须知### 1. 入园时间
乐园通常在上午8:00开园,晚上8:00闭园,具体时间可能因季节和特殊活动调整。建议提前30分钟到达园区。### 2. 安全检查
入园前需要进行安全检查,禁止携带危险物品、玻璃制品等。建议轻装简行,提高入园效率。### 3. 园区服务
园区内提供寄存服务、轮椅租赁、婴儿车租赁等服务,可在游客服务中心咨询详情。生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""if __name__ == "__main__":print("🎯 层次切片策略测试")print(f"📄 测试文本长度: {len(text)} 字符")# 使用层次切片chunks = hierarchical_chunking(text, target_size=300, preserve_hierarchy=True)print_chunk_analysis(chunks, "层次切片") 5. 滑动窗口切片
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
滑动窗口切片策略
固定长度、有重叠的文本分割方法
"""def sliding_window_chunking(text, window_size=512, step_size=256):"""滑动窗口切片"""chunks = []for i in range(0, len(text), step_size):chunk = text[i:i + window_size]if len(chunk.strip()) > 0:chunks.append(chunk.strip())return chunksdef print_chunk_analysis(chunks, method_name):"""打印切片分析结果"""print(f"\n{'='*60}")print(f"📋 {method_name}")print(f"{'='*60}")if not chunks:print("❌ 未生成任何切片")returntotal_length = sum(len(chunk) for chunk in chunks)avg_length = total_length / len(chunks)min_length = min(len(chunk) for chunk in chunks)max_length = max(len(chunk) for chunk in chunks)print(f"📊 统计信息:")print(f" - 切片数量: {len(chunks)}")print(f" - 平均长度: {avg_length:.1f} 字符")print(f" - 最短长度: {min_length} 字符")print(f" - 最长长度: {max_length} 字符")print(f" - 长度方差: {max_length - min_length} 字符")print(f"\n📝 切片内容:")for i, chunk in enumerate(chunks, 1):print(f" 块 {i} ({len(chunk)} 字符):")print(f" {chunk}")print()# 测试文本
text = """
迪士尼乐园提供多种门票类型以满足不同游客需求。一日票是最基础的门票类型,可在购买时选定日期使用,价格根据季节浮动。两日票需要连续两天使用,总价比购买两天单日票优惠约9折。特定日票包含部分节庆活动时段,需注意门票标注的有效期限。购票渠道以官方渠道为主,包括上海迪士尼官网、官方App、微信公众号及小程序。第三方平台如飞猪、携程等合作代理商也可购票,但需认准官方授权标识。所有电子票需绑定身份证件,港澳台居民可用通行证,外籍游客用护照,儿童票需提供出生证明或户口本复印件。生日福利需在官方渠道登记,可获赠生日徽章和甜品券。半年内有效结婚证持有者可购买特别套票,含皇家宴会厅双人餐。军人优惠现役及退役军人凭证件享8折,需至少提前3天登记审批。
"""if __name__ == "__main__":print("🎯 滑动窗口切片策略测试")print(f"📄 测试文本长度: {len(text)} 字符")# 使用滑动窗口切片chunks = sliding_window_chunking(text, window_size=300, step_size=150)print_chunk_analysis(chunks, "滑动窗口切片") 6. Qwen-VL图像理解
import json
import os
import dashscope
from dashscope import MultiModalConversation
import tracebacktry:# 设置API密钥dashscope.api_key = "sk-39b5e3974d304bab8f37db3aea987995"# 检查API密钥是否设置成功print(f"API Key set: {dashscope.api_key}")# 构建消息local_file_path = 'file://2-万圣节.jpeg'messages = [{'role': 'user','content': [{'image': local_file_path},{'text': '这是一张什么海报?'}]}]print("Sending request to Qwen-VL-Plus model...")response = MultiModalConversation.call(model='qwen-vl-plus',messages=messages)# 打印响应print("Response received:")print(json.dumps(response, indent=2, ensure_ascii=False))except Exception as e:print(f"Error occurred: {type(e).__name__}: {str(e)}")print("Traceback:")traceback.print_exc()