【AI论文】机器人学习:教程
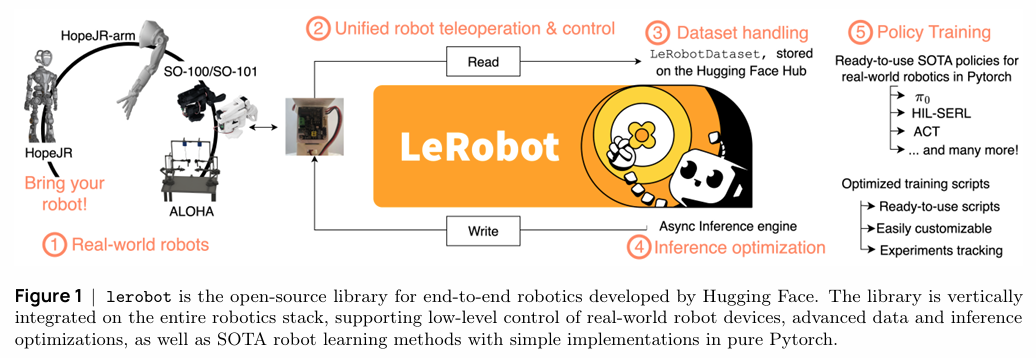
摘要:机器人学习正处于转折点,得益于机器学习领域的快速进展以及大规模机器人数据日益丰富的可用性。这一从经典基于模型的方法向数据驱动、基于学习的范式的转变,正为自主系统解锁前所未有的能力。本教程将带领读者探索现代机器人学习的全景,从强化学习与行为克隆的基础原理出发,一路延伸至具备跨任务甚至跨机器人形态操作能力的通用型、受语言条件约束的模型。本教程旨在为研究人员和从业者提供指引,我们的目标是为读者提供必要的概念理解与实践工具,助其在机器人学习领域的发展中贡献力量,教程中还包含了在lerobot框架中实现的即用型示例。Huggingface链接:Paper page,论文链接:2510.12403
研究背景和目的
研究背景:
随着机器学习技术的快速发展,特别是深度学习与大规模机器人数据的可用性增加,机器人学习领域正经历着从传统基于模型的方法向数据驱动、学习驱动的范式转变。这一转变解锁了自主系统前所未有的能力,使得机器人能够在复杂和动态的环境中执行多样化的任务。传统的机器人学习方法,如基于动力学模型的控制方法,虽然在特定任务和机器人平台上取得了显著成果,但面临着集成难度大、可扩展性差以及对环境建模要求高等挑战。
与此同时,现代机器学习技术,特别是强化学习(RL)和行为克隆(BC),通过从大量数据中学习,提供了更加灵活和通用的解决方案。
研究目的:
本研究旨在探索现代机器人学习的方法和应用,特别是强化学习和行为克隆技术在机器人自主操作中的潜力。
具体研究目的包括:
- 介绍基础概念:为研究人员和从业者提供强化学习和行为克隆等现代机器人学习技术的概念理解和实用工具。
- 开发开放工具:通过开发并开源lerobot库,支持从基础到高级的机器人学习技术实现,促进研究社区的协作和扩展。
- 探索多任务与跨机器人应用:研究能够处理多样化任务和机器人平台的通用学习模型,减少对特定任务和机器人平台的依赖。
- 分析现有方法的局限性:深入分析传统基于动力学模型的方法和现代学习方法的局限性,为未来的研究提供方向。
研究方法
1. 强化学习(RL):
- 理论介绍:简要介绍强化学习的基本概念,包括马尔可夫决策过程(MDP)、奖励函数、值函数和策略梯度等。
- 算法实现:在lerobot库中实现多种强化学习算法,如SAC(Soft Actor-Critic)、PPO(Proximal Policy Optimization)等,并提供代码示例和实验结果。
- 实际应用:通过真实世界和模拟环境中的实验,展示强化学习在机器人操作中的应用,包括平面操作、移动操作和全身控制等。
2. 行为克隆(BC):
- 理论介绍:介绍行为克隆的基本概念,即通过监督学习从专家演示中学习策略。
- 生成模型应用:探讨变分自编码器(VAE)、扩散模型(DM)和流匹配(FM)等生成模型在行为克隆中的应用,提高策略学习的多模态性和鲁棒性。
- 行动分块技术:介绍Action Chunking with Transformers(ACT)和Diffusion Policy(DP)等技术,通过学习动作块而非单个动作,减少行为克隆中的误差累积问题。
3. 通用机器人模型:
- 数据集构建:介绍Open X-Embodiment和DROID等大规模机器人数据集的构建方法,促进跨任务和跨机器人平台的数据共享。
- 模型架构:探讨基于Transformer的通用机器人模型架构,如π0和SmolVLA,通过大规模预训练和微调,实现跨任务和跨机器人平台的操作。
- 实验验证:在多种机器人平台和任务上验证通用机器人模型的性能,展示其在不同环境和任务中的适应性和鲁棒性。
研究结果
1. 强化学习结果:
- 算法性能:通过实验验证,SAC和PPO等强化学习算法在模拟和真实世界环境中均表现出色,特别是在连续状态和动作空间的任务中。
- 实际应用:强化学习在机器人平面操作、移动操作和全身控制等任务中成功应用,展示了其在复杂环境中的自主操作能力。
- 挑战与限制:尽管强化学习在机器人学习中取得了显著进展,但仍面临样本效率低、安全性差和奖励设计困难等挑战。
2. 行为克隆结果:
- 生成模型效果:VAE、DM和FM等生成模型在行为克隆中表现出色,提高了策略学习的多模态性和鲁棒性。特别是DP在仅需少量专家演示的情况下,即可实现高性能的机器人操作。
- 行动分块技术:ACT和DP等行动分块技术有效减少了行为克隆中的误差累积问题,提高了长时间操作的稳定性和可靠性。
- 实际应用案例:通过真实世界中的精细操作任务(如酱料倾倒和瑜伽垫展开)验证了行为克隆技术的有效性。
3. 通用机器人模型结果:
- 跨任务与跨平台性能:基于Transformer的通用机器人模型(如π0和SmolVLA)在多种任务和机器人平台上表现出色,展示了其在不同环境和任务中的适应性和鲁棒性。
- 数据集贡献:Open X-Embodiment和DROID等大规模数据集的构建为通用机器人模型的发展提供了有力支持,促进了跨任务和跨机器人平台的数据共享和模型训练。
- 模型效率与可访问性:SmolVLA等紧凑且高效的通用机器人模型降低了对计算资源的要求,提高了模型的实用性和可访问性。
研究局限
1. 数据依赖性:
- 数据标注成本:尽管大规模数据集的构建为机器人学习提供了有力支持,但数据标注过程仍需大量人力和时间成本。
- 数据多样性:现有数据集在任务和机器人平台上的多样性仍有限,可能限制模型在不同环境和任务中的泛化能力。
2. 模型局限性:
- 样本效率:尽管强化学习在模拟环境中取得了显著进展,但在真实世界中的样本效率仍然较低,需要大量交互数据才能达到满意性能。
- 安全性与鲁棒性:强化学习在探索过程中可能产生不安全或破坏性的行为,特别是在真实世界环境中。此外,模型对环境变化和扰动的鲁棒性仍需进一步提高。
3. 评估与比较:
- 评估指标:现有评估指标主要关注任务完成情况,难以全面评估模型在叙事连贯性、文化适应性和风格保真度等方面的表现。
- 跨平台比较:不同研究在机器人平台、任务设置和评估指标等方面存在差异,难以进行直接比较和综合评估。
未来研究方向
1. 数据集扩展与多样性增强:
- 扩大数据集规模:进一步收集和标注大规模机器人数据,提高数据集的多样性和覆盖范围。
- 跨模态数据融合:探索多模态数据(如视觉、语言和力觉)的融合方法,提高模型对复杂环境的感知和理解能力。
2. 模型改进与优化:
- 提高样本效率:研究更高效的强化学习算法和行为克隆技术,减少对大量交互数据的依赖。
- 增强安全性与鲁棒性:开发更安全的强化学习算法和鲁棒的行为克隆模型,确保模型在真实世界环境中的可靠性和稳定性。
3. 评估与标准化:
- 开发综合评估指标:建立全面评估机器人学习模型性能的综合指标体系,涵盖任务完成情况、叙事连贯性、文化适应性和风格保真度等多个方面。
- 标准化评估流程:制定标准化的评估流程和基准测试,促进不同研究之间的直接比较和综合评估。
4. 实际应用与部署:
- 探索实际应用场景:将机器人学习技术应用于实际生产和生活场景中,如智能制造、家庭服务和医疗辅助等。
- 开发可部署系统:研究机器人学习模型的实际部署方法,包括模型压缩、硬件加速和实时推理等关键技术,推动技术的商业化应用。