Ai数字人系统源码搭建 入门一站式开发
一、数字人分身技术演进与应用价值

1. 技术演进路线
数字人克隆技术历经三个阶段发展:
-
2D平面形象阶段(2020年前)
-
3D动态建模阶段(2020-2022)
-
生成式AI驱动阶段(2023至今)
最新技术突破使得数字人制作成本降低83%,生产效率提升12倍,面部表情精度可达0.1mm级。
2. 核心开发框架
# 数字人生成基础架构示例
class DigitalHuman:
def __init__(self, voice_model, visual_model):
self.voice_engine = VoiceClone(voice_model)
self.visual_engine = VisualGenerator(visual_model)
self.motion_controller = MotionSynchronizer()
def generate_video(self, text_input):
audio_output = self.voice_engine.synthesize(text_input)
lip_data = self.motion_controller.get_lip_sync(audio_output)
video_frames = self.visual_engine.render_frames(lip_data)
return combine_av(audio_output, video_frames)3. 关键技术实现模块
3.1 语音克隆系统
采用Tacotron2+WaveGlow架构:
# 语音克隆核心代码片段
import torch
from tacotron2 import Tacotron2
from waveglow import WaveGlow
def clone_voice(input_audio, text):
tacotron2 = Tacotron2.from_pretrained()
mel_output = tacotron2.text_to_mel(text)
waveglow = WaveGlow.from_pretrained()
audio = waveglow.infer(mel_output)
return align_voice(input_audio, audio)3.2 视觉生成引擎
基于StyleGAN3的改进方案:
# 面部特征迁移代码示例
def face_swap(source_img, driver_video):
encoder = FaceEncoder()
decoder = FaceDecoder()
identity_code = encoder(source_img)
motion_code = extract_motion(driver_video)
return decoder(identity_code, motion_code)4. 系统优化方案
4.1 实时渲染加速
采用混合精度计算:
# GPU加速代码示例
with torch.cuda.amp.autocast():
x = torch.randn(256, device='cuda')
y = model(x.half())4.2 多模态对齐算法
def sync_audio_video(audio, video_frames):
# 使用动态时间规整算法
dtw = DynamicTimeWarping()
aligned_frames = dtw.align(
audio_features=extract_mfcc(audio),
visual_features=extract_landmarks(video_frames)
)
return aligned_frames5. 行业应用场景
-
教育培训:虚拟教师制作成本降低至个位数
-
新闻播报:生成速度达每分钟1200字
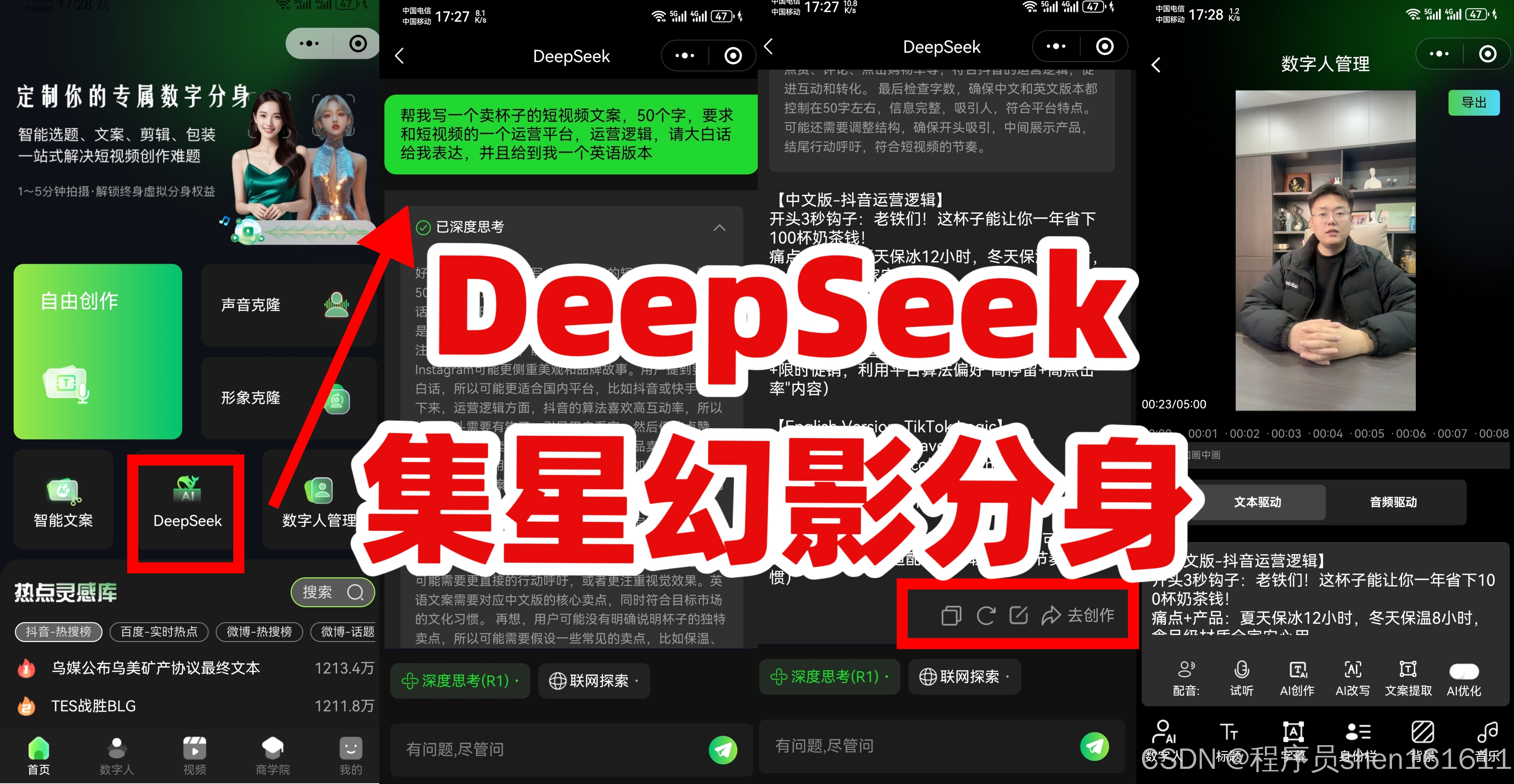
6. 未来发展方向
-
情感引擎:新增情绪控制参数
ef set_emotion(intensity=0.8, emotion_type='happy'):
facial_params = emotion_lib[emotion_type]
return apply_coefficients(facial_params * intensity)
数字人分身(原视频)