安徽省住房和城乡建设厅门户网站网站百度权重怎么提升
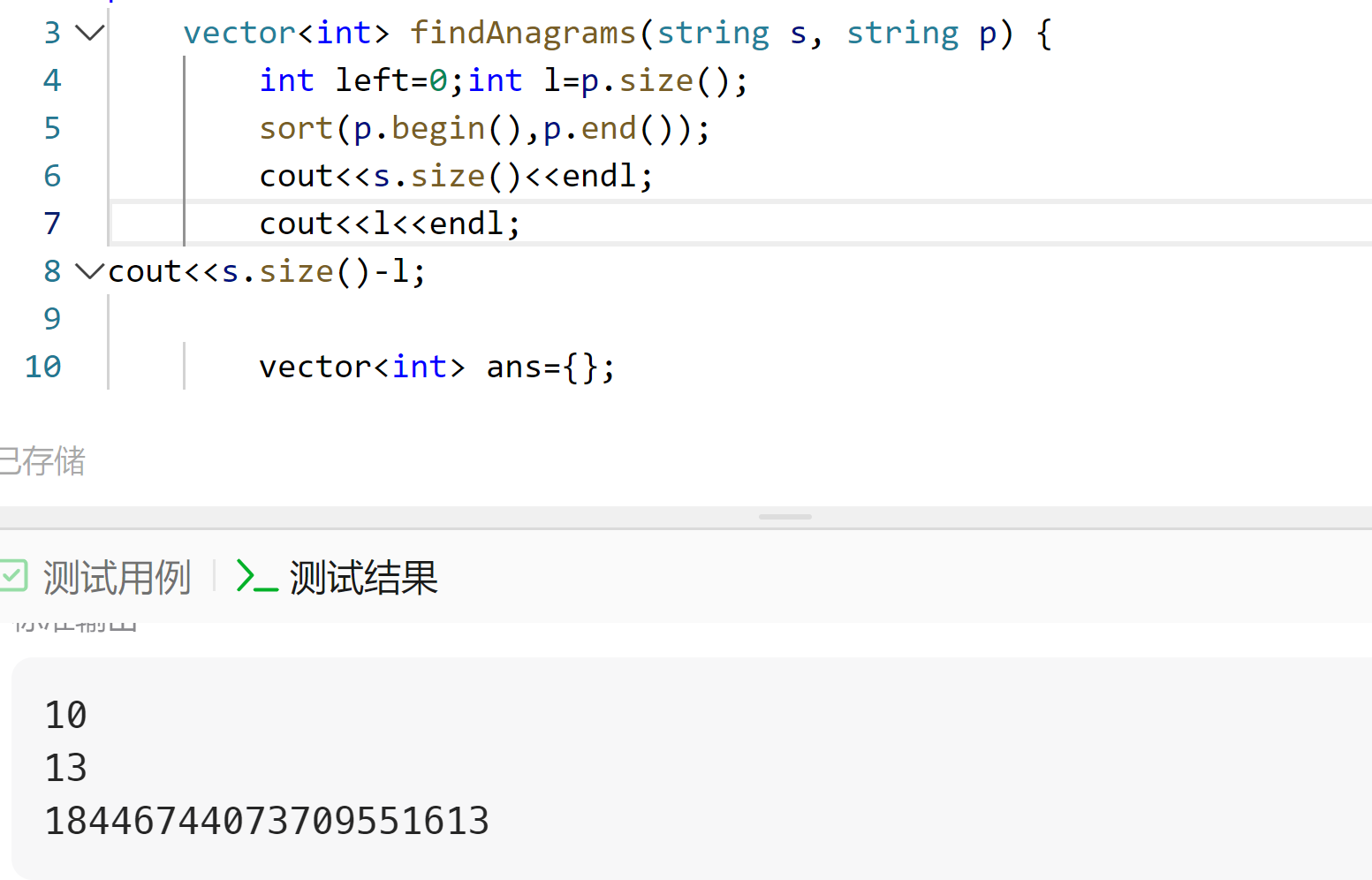
不应该是10-13=-3吗
ChatGLM
![]()
引用
从代码片段来看,函数 findAnagrams 的目的是在字符串 s 中找到所有与字符串 p 是字母异位词的子串的起始索引。
代码中有一些调试输出语句,这些语句可能会影响程序的正常逻辑。具体来说:
cpp
复制
cout << s.size() << endl;
cout << l << endl;
cout << s.size() - 1;
这些输出语句会打印出 s 的大小、l(即 p 的大小)和 s.size() - 1 的值。但这些并不是计算字母异位词的逻辑部分。
根据测试结果中的输出:
复制
10
13
18446744073709551613
我们可以看到输出的三个数字分别是 10, 13 和一个非常大的数 18446744073709551613。这个非常大的数实际上是 INT_MAX 的值,通常表示某种错误或异常情况。
考虑到你的问题 “不应该是10-13=-3吗”,可能是在期望某种特定的计算结果。然而,从当前代码来看,并没有直接进行 10 - 13 这样的操作。可能是你在期望某个逻辑上的结果,但当前的代码实现并不符合那个预期。
如果你希望得到 10 - 13 = -3 这样的结果,你可能需要检查并修正代码的逻辑部分,确保它正确地实现了寻找字母异位词的功能,并且没有多余的调试输出干扰正常的程序流程。
另外,确保 vector<int> ans; 被正确初始化和使用来存储结果,而不是仅仅声明了一个空的向量。
解决:只要单独拎出s.size()设为ls,ls-l就是正常的-3了,具体原因未可知、、
函数和方法的区别
ChatGLM

在编程中,函数(Function)和方法(Method)是两个经常被提及的概念,它们在某些方面相似,但也存在一些关键的区别。以下是它们的主要区别:
-
定义和作用范围:
- 函数:通常是指在程序中定义的一系列语句,用于完成特定的任务。函数可以独立于任何对象而存在,可以在全局作用域或局部作用域中定义。
- 方法:是特定于对象的函数,通常与面向对象编程(OOP)相关。方法是在类的定义中声明,并且与类的实例(对象)相关联。
-
调用方式:
- 函数:可以直接通过函数名调用,不需要与任何对象关联。
- 方法:必须通过对象或类来调用。在面向对象编程中,方法调用通常与特定的对象实例相关联。
-
访问对象的属性:
- 函数:通常不直接访问对象的属性,除非通过参数传递。
- 方法:可以访问所属对象的属性和其他方法,因为它们与特定的对象实例相关联。
-
继承和多态:
- 函数:通常不涉及继承和多态的概念。
- 方法:在面向对象编程中,方法可以被子类继承和重写,实现多态性。
-
语法:
- 函数:在许多编程语言中,函数的定义不依赖于任何类或对象。
- 方法:在面向对象编程语言中,方法的定义通常包含在类的定义中。
以下是一些示例,展示了函数和方法的区别:
Python 示例:
python
复制
# 函数
def add(a, b):return a + b# 类和它的方法
class Calculator:def add(self, a, b):return a + b# 调用函数
result = add(2, 3)# 创建对象并调用方法
calc = Calculator()
result = calc.add(2, 3)
Java 示例:
java
复制
// 函数
public class Main {public static int add(int a, int b) {return a + b;}// 类和它的方法class Calculator {public int add(int a, int b) {return a + b;}}public static void main(String[] args) {// 调用函数int result = add(2, 3);// 创建对象并调用方法Calculator calc = new Calculator();int result = calc.add(2, 3);}
}
在这些示例中,add 函数是独立于任何对象的,而 add 方法是与 Calculator 类的实例相关联的。

用户_uBiEPA
计算前缀和的时间复杂度
ChatGLM
计算前缀和的时间复杂度通常是 O(n),其中 n 是数组的长度。前缀和是一种常用的技术,用于快速计算数组中某个区间的元素之和。
前缀和的定义
前缀和数组 prefixSum 是一个长度为 n+1 的数组,其中 prefixSum[i] 表示原数组中从第一个元素到第 i-1 个元素的和。具体来说:
prefixSum[0] = 0(表示没有元素的和)prefixSum[1] = arr[0]prefixSum[2] = arr[0] + arr[1]- …
prefixSum[i] = arr[0] + arr[1] + ... + arr[i-1]
计算过程
计算前缀和的伪代码如下:
plaintext
复制
prefixSum[0] = 0
for i from 1 to n:prefixSum[i] = prefixSum[i-1] + arr[i-1]
时间复杂度分析
- 初始化:
prefixSum[0] = 0,这一步是 O(1)。 - 循环计算:从 i=1 到 n,每次计算
prefixSum[i]只需要 O(1) 的时间。
因此,整个循环的时间复杂度是 O(n)。
应用
一旦计算了前缀和数组,你可以用 O(1) 的时间复杂度来查询任意子数组的和。例如,要查询数组 arr 中从索引 l 到 r 的子数组和,可以使用:
plaintext
复制
sum(l, r) = prefixSum[r+1] - prefixSum[l]
总结
- 计算前缀和的时间复杂度:O(n)
- 查询子数组和的时间复杂度:O(1)
这种高效性使得前缀和在许多算法和问题中非常有用,特别是在需要频繁查询数组区间和的场景中。
用户_uBiEPA
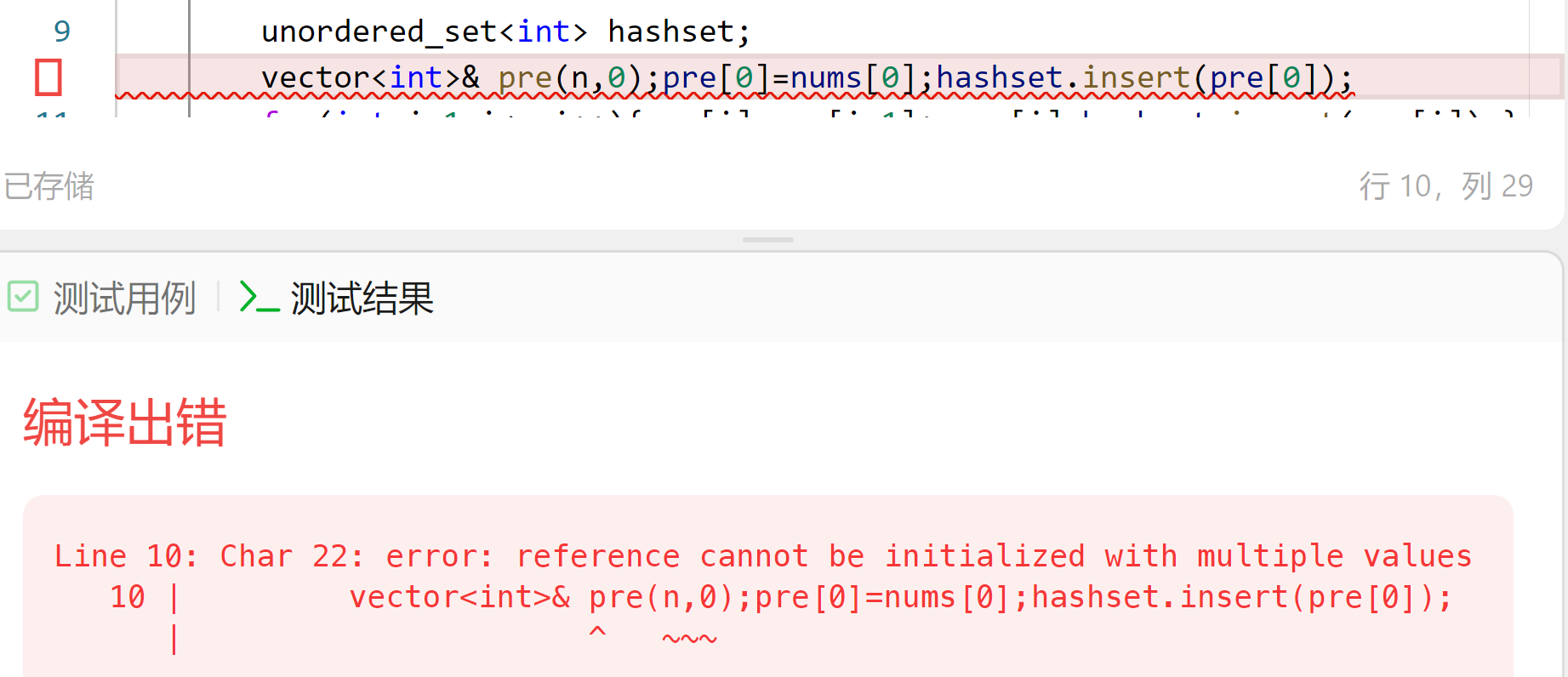
vector初始化,如果指定了个数,不能带&符号
ChatGLM

是的,这段代码中的初始化确实有问题。错误信息指出“reference cannot be initialized with multiple values”,意思是引用不能被多个值初始化。
具体来说,问题在于 vector<int>& pre(n, 0); 这一行。这里尝试将 pre 初始化为一个大小为 n 且值为 0 的 vector<int>,但同时又将 pre 声明为一个对 vector<int> 的引用。这是不允许的,因为引用必须在声明时绑定到一个具体的变量,而不能同时指定大小和初始值。
正确的做法是将 pre 声明为一个普通的 vector<int> 变量,并在之后进行初始化。下面是修正后的代码:
cpp
复制
unordered_set<int> hashset;
vector<int> pre(n, 0); // 正确的初始化方式
pre[0] = nums[0];
hashset.insert(pre[0]);
这样,pre 就会被正确地初始化为一个大小为 n 且所有元素都为 0 的 vector<int>,然后你可以继续使用 pre 进行后续的操作。

详尽版vector初始化
在 C++ 中,vector 是一个能够存储多个同类型元素的动态数组,它提供了许多方便的成员函数用于元素的初始化、插入、删除等操作。当你声明并初始化一个 vector 时,你不能使用 & 符号,因为 & 是引用声明符,而 vector 不是引用类型。
以下是一些 vector 初始化的示例:
-
声明一个空的
vector:cpp
复制
std::vector<int> vec; -
初始化一个具有特定大小且所有元素都为 0 的
vector:cpp
复制
std::vector<int> vec(10); // 10 个元素,每个元素都是 0 -
初始化一个具有特定大小且所有元素都为特定值的
vector:cpp
复制
std::vector<int> vec(10, 42); // 10 个元素,每个元素都是 42 -
使用初始化列表来初始化
vector:cpp
复制
std::vector<int> vec = {1, 2, 3, 4, 5}; // 5 个元素,分别是 1, 2, 3, 4, 5 -
使用数组和数组大小来初始化
vector:cpp
复制
int arr[] = {1, 2, 3, 4, 5}; std::vector<int> vec(std::begin(arr), std::end(arr)); // 使用数组初始化 -
拷贝另一个
vector:cpp
复制
std::vector<int> vec1 = {1, 2, 3, 4, 5}; std::vector<int> vec2 = vec1; // 拷贝构造函数
为什么不能使用 & 符号?
& 符号在 C++ 中用于声明引用。引用是已存在变量的别名,而 vector 是一个对象,它不是引用类型。当你声明一个 vector 时,你是在创建一个新的对象,而不是在引用一个已存在的对象。
如果你尝试使用 & 符号来声明一个 vector,你会得到一个编译错误,因为 vector 不是引用类型。例如:
cpp
复制
std::vector<int>& vec(10); // 错误:不能将 vector 初始化为引用
正确的初始化方法
如果你需要声明一个 vector 的引用,你可以在声明时使用 & 符号,但必须在初始化之后再进行。例如:
cpp
复制
std::vector<int> vec = {1, 2, 3, 4, 5};
std::vector<int>& vecRef = vec; // 正确:vecRef 是 vec 的引用
在这种情况下,vecRef 是 vec 的引用,任何对 vecRef 的修改都会反映到 vec 上。
总结来说,vector 的初始化不需要使用 & 符号,因为 vector 不是引用类型。你只需要使用上述的正确初始化方法即可。
hashset有3个0,我像只去掉一个0
ChatGLM
如果你想在 unordered_set<int> 中只保留一个 0 而去除多余的,你可以直接使用 unordered_set 的特性,因为它本身就会自动去重。当你尝试插入相同的值时,unordered_set 会忽略后续的插入操作,只保留一个。
如果你已经有一个包含多个 0 的 unordered_set<int>,并且想要确保只保留一个 0,你可以先清除所有的 0,然后再次插入一个 0。以下是相应的代码示例:
cpp
复制
#include <iostream>
#include <unordered_set>
#include <vector>int main() {std::unordered_set<int> hashset;std::vector<int> nums = {0, 1, 0, 2, 0, 3}; // 示例数组// 假设我们想将nums中的元素插入到hashset中for (int num : nums) {hashset.insert(num);}// 如果hashset中0的数量多于1个,我们只保留一个0if (hashset.count(0) > 1) {hashset.erase(0); // 先清除所有的0hashset.insert(0); // 再插入一个0}// 输出hashset中的元素for (int num : hashset) {std::cout << num << " ";}return 0;
}
在这个示例中,我们首先将一个包含多个 0 的数组 nums 的元素插入到 hashset 中。然后,我们检查 hashset 中 0 的数量,如果多于一个,我们就先清除所有的 0,然后再插入一个 0。这样,hashset 中就只会有一个 0。
请注意,这个方法会在 hashset 中保留一个 0,即使原始数组 nums 中没有 0。如果你希望只有在原始数组中至少有一个 0 时才保留 0,你可以先检查 hashset 中是否包含 0,然后再进行去重操作。

用户_uBiEPA
hashset自动去重,多次insert(0) 那会hashset.count(0) 增加吗
ChatGLM

不会。在C++中,unordered_set(哈希集合)是一个集合容器,用于存储唯一元素,即自动去重。当你尝试向unordered_set中插入一个已经存在的元素时,该操作将不会改变集合的内容,因此hashset.count(0)不会增加。
count成员函数用于返回集合中具有特定值的元素的数量。由于unordered_set只存储唯一元素,所以对于任何给定的值,count函数的返回值只能是0或1。
如果你多次执行hashset.insert(0),只要0已经存在于集合中,后续的插入操作将不会生效,hashset.count(0)将始终返回1。
这里是一个简单的示例来演示这一点:
cpp
复制
#include <iostream>
#include <unordered_set>int main() {std::unordered_set<int> hashset;// 插入0多次hashset.insert(0);hashset.insert(0);hashset.insert(0);// 输出0在集合中的数量std::cout << "Count of 0 in hashset: " << hashset.count(0) << std::endl;return 0;
}
无论你执行多少次hashset.insert(0),输出都将始终是:
复制
Count of 0 in hashset: 1
这表明unordered_set中只保留了一个0,并且count函数的返回值没有增加。

用户_uBiEPA
set呢
ChatGLM

在C++中,std::set也是一个集合容器,它存储唯一元素并自动保持元素有序。与std::unordered_set类似,std::set也会自动去重。当你尝试向std::set中插入一个已经存在的元素时,该操作不会改变集合的内容,因此set.count(0)也不会增加。
std::set的count成员函数同样用于返回集合中具有特定值的元素的数量。由于std::set只存储唯一元素,所以对于任何给定的值,count函数的返回值只能是0或1。
这里是一个简单的示例来演示std::set的行为:
cpp
复制
#include <iostream>
#include <set>int main() {std::set<int> mySet;// 插入0多次mySet.insert(0);mySet.insert(0);mySet.insert(0);// 输出0在集合中的数量std::cout << "Count of 0 in set: " << mySet.count(0) << std::endl;return 0;
}
无论你执行多少次mySet.insert(0),输出都将始终是:
复制
Count of 0 in set: 1
这表明std::set中只保留了一个0,并且count函数的返回值没有增加。
总结来说,无论是std::unordered_set还是std::set,它们都保证元素的唯一性,多次插入相同的元素不会增加该元素在集合中的计数。

用户_uBiEPA
想要知道一个元素出现了几次,用什么‘
ChatGLM

如果你想要知道一个元素在集合中出现了几次,那么你应该使用一个能够记录元素出现次数的数据结构。在C++中,常用的数据结构包括:
-
std::map:这是一个有序的键值对容器,可以存储键和对应的值。你可以使用元素作为键,其出现次数作为值。
-
std::unordered_map:这是一个无序的键值对容器,与std::map类似,但是它不保证元素的顺序,通常提供更快的访问速度。
下面是使用std::unordered_map来记录元素出现次数的示例:
cpp
复制
#include <iostream>
#include <unordered_map>int main() {std::unordered_map<int, int> countMap;// 假设我们有一些元素int elements[] = {0, 1, 2, 0, 3, 0, 1};// 记录每个元素出现的次数for (int elem : elements) {countMap[elem]++;}// 查询元素0出现的次数std::cout << "Element 0 appears " << countMap[0] << " times." << std::endl;return 0;
}
在这个示例中,我们遍历了一个元素数组,并使用countMap[elem]++来增加每个元素在unordered_map中的计数。然后,我们可以通过countMap[0]来查询元素0出现的次数。
如果你只需要记录元素是否出现,而不关心出现的次数,那么可以使用std::set或std::unordered_set。但是,如果你需要知道元素出现的具体次数,那么std::map或std::unordered_map是更合适的选择。
用户_uBiEPA
td::unordered\_map<int, int\> countMap; // 假设我们有一些元素 int elements\[\] = {0, 1, 2, 0, 3, 0, 1}; // 记录每个元素出现的次数 for (int elem : elements) { countMap\[elem\]++; } // 查询元素0出现的次数 std::cout << "Element 0 appears " << countMap\[0\] << " times." << std::endl; return 0;
这是默认初始建对应的值为0吗
ChatGLM
![]()
引用
是的,当你使用 std::unordered_map(或 std::map)并尝试访问一个不存在的键时,它会自动为该键创建一个默认初始化的值。对于内置类型如 int,默认初始化的值是 0。因此,在代码中,当你第一次尝试增加 countMap[elem] 的值时,如果 elem 还没有作为键存在于 countMap 中,unordered_map 会自动创建一个键值对,其中键是 elem,值是默认初始化的 0。
在接下来的代码中:
cpp
复制
for (int elem : elements) {countMap[elem]++;
}
对于数组 elements 中的每个元素,countMap[elem]++ 的操作会先检查 elem 是否已经作为键存在于 countMap 中。如果不存在,它会创建一个新键 elem 并将其值初始化为 0,然后立即增加其值到 1。如果 elem 已经存在,它只会增加现有键的值。
因此,当你查询 countMap[0] 时,它会返回元素 0 出现的次数,因为每次 0 出现在数组中时,它的计数就会增加。在这个特定的例子中,元素 0 出现了三次,所以 countMap[0] 的值将是 3。
sort(字符串)
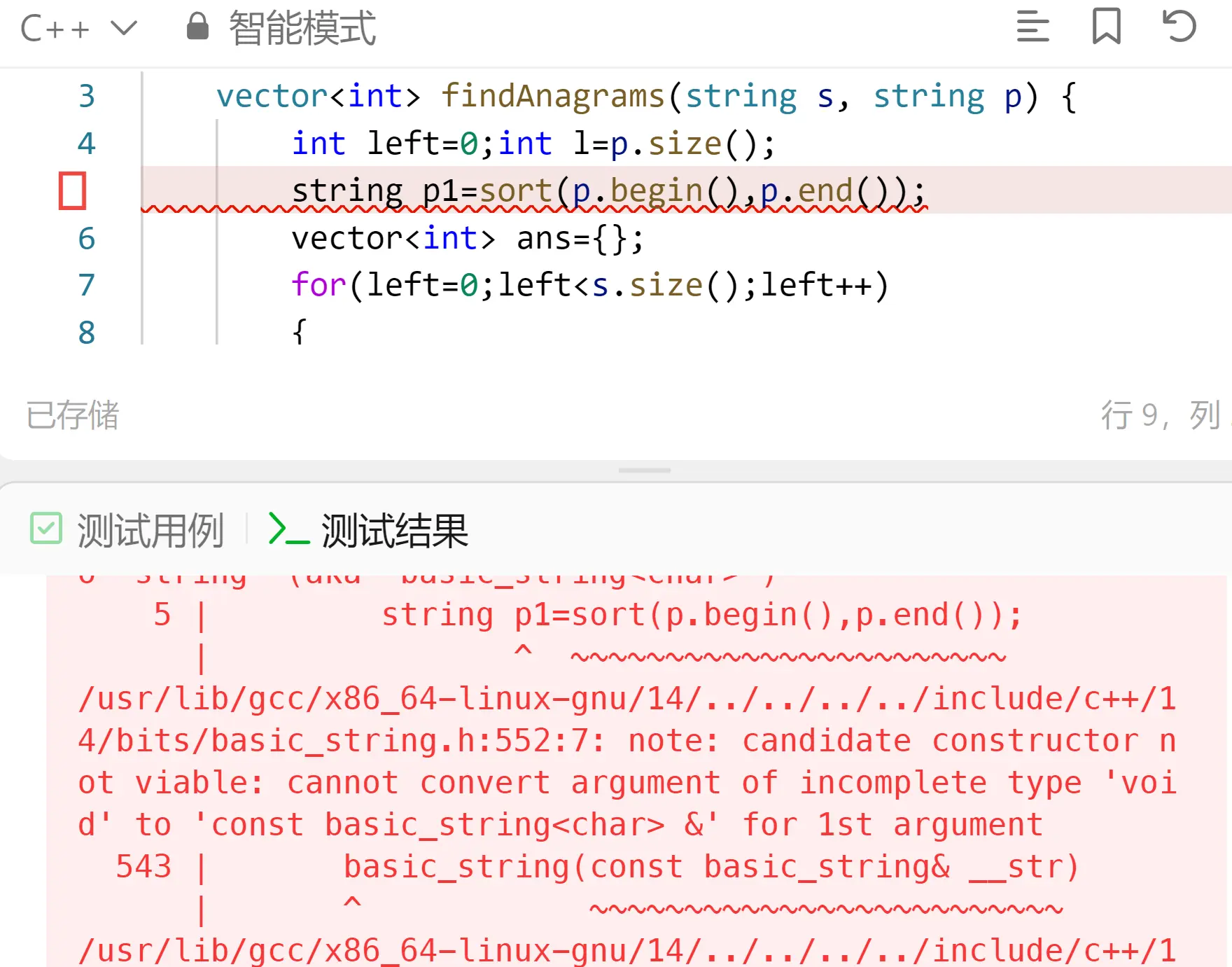 从图片中可以看到,代码在编译时出现了错误。错误信息指出,无法将一个不完整的类型(void)转换为字符串类型(const basic_string<char>&)。具体来说,问题出在以下这一行:
从图片中可以看到,代码在编译时出现了错误。错误信息指出,无法将一个不完整的类型(void)转换为字符串类型(const basic_string<char>&)。具体来说,问题出在以下这一行:
cpp
复制
string p1 = sort(p.begin(), p.end());
这个问题的原因是 sort() 函数返回的是指向最后一个元素的迭代器,而不是排序后的子串。因此,不能直接将其赋值给一个字符串。
要解决这个问题,可以创建一个新的字符串来存储排序后的结果。例如:
cpp
复制
string p1 = string(p.begin(), p.end()); // 先复制一份p
sort(p1.begin(), p1.end()); // 对复制的字符串进行排序
这样就可以正确地得到排序后的字符串了。
在C++中,没有直接的sort(str)这种用法来对字符串进行排序。但是,C++提供了强大的标准库,其中包括<algorithm>头文件,里面有一个sort函数可以用来对各种容器进行排序,包括字符串。
如果你想要对字符串中的字符进行排序,你可以使用如下代码:
cpp
复制
#include <iostream>
#include <string>
#include <algorithm>int main() {std::string str = "hello";std::sort(str.begin(), str.end());std::cout << "Sorted string: " << str << std::endl;return 0;
}
这段代码会将字符串"hello"中的字符按照字典序进行排序,输出结果为"ehllo"。
需要注意的是,sort函数默认使用小于比较符进行排序,如果你需要其他类型的排序(比如降序),你可以提供自定义的比较函数。
例如,如果你想按照降序排序,你可以这样做:
cpp
复制
#include <iostream>
#include <string>
#include <algorithm>int main() {std::string str = "hello";std::sort(str.begin(), str.end(), std::greater<char>());std::cout << "Sorted string: " << str << std::endl;return 0;
}
这样输出结果就会是"ollhe"。
所以,虽然C++没有直接的sort(str)这种用法,但是通过标准库中的sort函数,你可以很容易地对字符串进行排序。