2025年MathorCup数学应用挑战赛---大数据竞赛赛题分析







赛道 A:基于计算机视觉的集装箱智能破损检测
赛道 B:物流理赔风险识别及服务升级问题
咱们先把这两个赛道的核心区别拎清楚——赛道A是纯纯“看图片干活”,专门找集装箱上的破损;赛道B是“扒表格算账”,琢磨物流理赔的风险,俩方向完全不搭边,咱们逐个赛道、逐个问题掰开揉碎了说,都用大白话,不整那些生僻术语。
先看赛道A,集装箱破损检测这块,适合的学生得是玩过图片识别的,比如计算机科学、人工智能、自动化这些专业,尤其是平时接触过“看图片找东西”的同学,上手会快很多。咱们先讲第一个问题:判断图片里的集装箱有没有残损。这是A赛道里最基础的活,不用找破损在哪,就给个“有”或“没有”的答案,有点像你刷手机看图,判断“这张图里有没有猫”一样,只是对象换成了集装箱的破损。用到的模型也不用自己从零搭,像ResNet、EfficientNet这些现成的图片分类框架,网上一搜全是代码,改改输入输出就能用。但重点不在模型多复杂,而在“处理图片”——你想啊,港口的图片里乱七八糟的,有机器、天空、地面,还有反光、阴影、下雨天的水痕,这些都容易让模型认错,得先给图片“做个大扫除”,比如裁掉没用的背景、调调亮度去掉阴影;另外,没残损的图片可能比有残损的多好多,要是模型光看这些“没问题”的图,最后可能就偷懒只认“没残损”,漏了真正有问题的,所以得想办法平衡数据,比如多复制点有残损的图,或者少用点没残损的图,这才是这个问题的关键。
接下来是A赛道的第二个问题,也是最难的:既要找到破损在哪,还得说出是“凹陷”“裂纹”还是“锈蚀”。这就比第一个问题难多了,不光要知道“有”,还得用框把破损圈出来,甚至精确到每个像素——比如裂纹就几像素宽,得让模型能“看见”这么小的东西,还得区分开长得像的破损,比如深凹痕和破洞,一不小心就认错了。用到的模型一般是能同时干“找位置+标细节”的,比如Mask R-CNN,既能画框又能标像素;要是想快点出结果,也能用YOLO先画框找位置,再用U-Net补细节标分割。这里最头疼的是“多尺度检测”,大的锈蚀还好认,小的裂纹可能就一条细线,模型很容易漏看,所以得让模型像用放大镜一样,一层一层看图片的不同大小细节;另外,区分相似破损也得下功夫,可能得专门给这些像的破损样本做标注,让模型多学几遍。
最后是A赛道的第三个问题,评估前两个模型好不好用。这就简单了,不用建模,就是给模型“打分”。比如第一个问题判断“有没有破损”,不能只看“准确率”——因为没残损的图多,准确率高不代表能把所有有破损的都找出来,得看“召回率”,也就是到底漏了多少有破损的;第二个问题检测分割,要看“框得准不准”(行业里叫mAP)和“分割得对不对”(叫mIoU)。这些指标用Python的sklearn库就能算,重点是选对指标,别用错了——比如第一个问题用准确率,看似分高,其实没意义;另外,还得分析结果,比如召回率低,到底是因为小裂纹没看见,还是背景干扰太大,得说清楚原因,不能光甩个分数就完事。
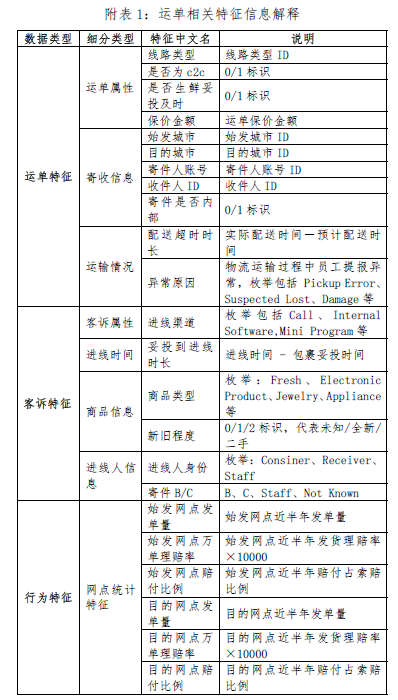
再来说赛道B,物流理赔风险识别,这个适合玩表格数据的同学,比如数据科学、统计学、金融工程,要是物流管理专业的同学懂业务,上手会更顺,因为这个赛道全是跟运单相关的表格数据,不用碰图片。第一个问题是给运单分三类:“合理诉求”“诉求偏高”“严重超额”,核心是根据“理赔差额”(实际赔的钱减客户要的钱)和“实际赔付金额”来划界限。这一步不用急着建模,得先“摸透数据规律”——比如画个直方图看看,“合理诉求”的差额是不是堆在一起很密集,“严重超额”的是不是散在外面很稀疏,还得符合业务要求:严重超额的运单不能超过3%,合理诉求的得不少于85%。具体做的时候,先画散点图、直方图看看数据分布,再用K-means聚成3类,或者按“实际赔付金额”分档——比如100块以下、100到500块、500块以上,每档里再按差额的分位数划界,比如每档里差额最小的5%算严重超额,这样既符合数据规律,又能满足业务占比要求。这里要注意别“一刀切”,比如实际赔1000块和赔100块的运单,就算差额一样,也不能归为一类,必须按赔付金额分档定标准,不然就不符合实际业务逻辑了。
B赛道的第二个问题是预测实际赔付金额,也就是算“这单该赔多少钱”,属于连续值预测,不难。用到的模型不用复杂的神经网络,就用处理表格数据最顺手的“树模型”,比如随机森林、XGBoost、LightGBM,这些模型抗干扰能力强,还不用怎么调参。重点在“特征工程”——表格里有很多分类数据,比如“商品类型”是生鲜还是电子产品,得转成数字(行业里叫One-Hot编码);还有缺失值,比如有的运单没填保价金额,得补上,用均值或者中位数都行;另外,像运单号这种跟赔付金额没关系的特征,得删掉,不然会干扰模型。还有个小麻烦是异常值,比如有的运单赔几万块,这种极少数的情况很容易带偏模型,得先找出来处理,比如用“盖帽法”把特别大的值限制在某个范围里。
B赛道最难的是第三个问题:用第一个问题的规则建模型,预测新运单的类别,还得处理“严重超额样本少”的问题,最后对比两种预测方法的好坏。严重超额的样本只占3%,要是直接建模,模型很可能只认“合理诉求”,漏了严重超额的,所以得想办法处理——比如用SMOTE造点“严重超额”的假样本,或者调模型的class weight,给严重超额的样本更多“权重”,让模型重视它。建模还是用XGBoost、LightGBM这些树模型,重点是把之前处理好的特征喂进去。对比方法的时候得客观,不能只说哪个好:直接分类的好处是一步到位,不用先预测赔付金额,避免了两次误差叠加;但坏处是没利用好“赔付金额+差额”的业务逻辑。而先预测赔付金额再分类,好处是符合实际业务流程,先算该赔多少再判断合理不;但坏处是如果赔付金额预测不准,后面的分类也会错,相当于误差会累积。这部分得把优缺点说透,不能糊弄。
最后咱们总结下:想玩图片、调视觉模型的,选赛道A,适合计算机、AI相关专业,最难的是问题2的检测分割,核心是搞定多尺度和相似破损;想扒表格、玩数据的,选赛道B,适合数据科学、统计相关专业,最难的是问题3的不平衡处理和方法对比,核心是搞定少数样本和业务逻辑。俩赛道门槛不一样,但只要找准自己擅长的方向,上手都不算难。