PaddleOCR-VL实测与思考
一、问题和需求
1.1 说明
全网首发PaddleOCR-VL的VLLM部署教程【万字血泪史】-CSDN博客
上篇博文使用vllm安装好了PaddleOCR-VL。本章实测一下这个模型的效果如何,主要从下述几个方面测评,资源消耗情况,各种版面的非格式化图片效果,内置的LLM能否的理解一些格式化输出的需求,准确率如何,模型压力测试效果。
深挖模型的处理原理,探究如何把这个应用到实际的生产中。
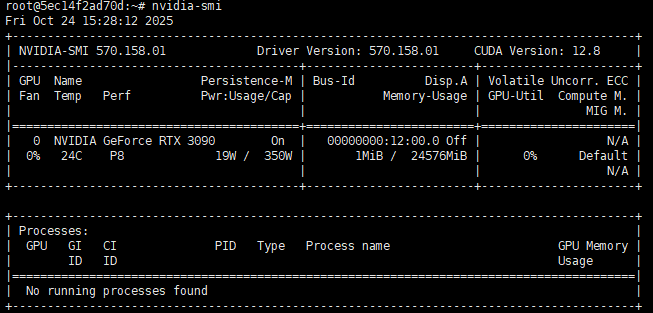
1.2 设备情况
检测硬件设备的相关代码
nvidia-smi
nvidia-smi --query-gpu=compute_cap --format=csv
nvcc --version
如果是虚拟环境,可以使用这个命令
python -c "import torch; print(f'PyTorch 版本: {torch.__version__}'); print(f'PyTorch 构建所用的CUDA版本: {torch.version.cuda}'); print(f'CUDA 是否可用: {torch.cuda.is_available()}'); device_count = torch.cuda.device_count() if torch.cuda.is_available() else 0; print(f'可用GPU数量: {device_count}'); [print(f'GPU{i}名称: {torch.cuda.get_device_name(i)}') for i in range(device_count)] if torch.cuda.is_available() else print('未检测到可用于PyTorch的GPU。')"
主设备情况:
root@5ec14f2ad70d:~# nvidia-smi --query-gpu=compute_cap --format=csv
compute_cap
8.6
root@5ec14f2ad70d:~# nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Mon_Apr__3_17:16:06_PDT_2023
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
主机cuda是12.1,最高支持12.8版本。
服务端:(vllm部署的ppocr-vl虚拟环境,ppocr-vllm)
PyTorch 版本: 2.8.0+cu128
PyTorch 构建所用的CUDA版本: 12.8
CUDA 是否可用: True
可用GPU数量: 1
GPU0名称: NVIDIA GeForce RTX 3090
客户端:(部署了paddlepaddle-gpu框架的虚拟环境,ppocr-vl)
无torch包
二、 服务端
2.1 vllm启动模型
paddlex_genai_server --model_name PaddleOCR-VL-0.9B --backend vllm --port 8118
该命令支持的参数如下:
| 参数 | 说明 |
|---|---|
--model_name | 模型名称 |
--model_dir | 模型目录 |
--host | 服务器主机名 |
--port | 服务器端口号 |
--backend | 后端名称,即使用的推理加速框架名称,可选 vllm 或 sglang |
--backend_config | 可指定 YAML 文件,包含后端配置 |
如果想调整参数,先去vllm官网找效果参数Optimization and Tuning - vLLM
- 创建 YAML 文件
vllm_config.yaml,内容如下:
gpu-memory-utilization: 0.8
- 启动服务时指定配置文件路径,例如使用
paddleocr genai_server命令:
paddleocr genai_server --model_name PaddleOCR-VL-0.9B --backend vllm --backend_config /path/vllm_config.yaml --port 8118
三、 客户端
3.1 使用python API方式
创建一个PaddleOCRProcessor.py文件
import os
import time
from paddleocr import PaddleOCRVLclass PaddleOCRProcessor:def __init__(self, use_doc_orientation_classify=False,use_doc_unwarping=False,use_layout_detection=True):"""初始化OCR处理管道:param use_doc_orientation_classify: 是否使用文档方向分类:param use_doc_unwarping: 是否使用文本图像矫正:param use_layout_detection: 是否使用版面区域检测"""self.pipeline = PaddleOCRVL(vl_rec_backend="vllm-server",vl_rec_server_url="http://127.0.0.1:8118/v1",use_doc_orientation_classify=use_doc_orientation_classify,use_doc_unwarping=use_doc_unwarping,use_layout_detection=use_layout_detection)def process_image(self, input_path, output_dir):"""处理单张图像并保存结果:param input_path: 输入图像路径:param output_dir: 输出目录路径"""# 确保输出目录存在os.makedirs(output_dir, exist_ok=True)# 开始计时start_time = time.time()print(f"开始处理图像: {os.path.basename(input_path)}")print("=" * 50)# 执行OCR识别output = self.pipeline.predict(input=input_path,save_path=output_dir)# 计算总处理时间end_time = time.time()total_time = end_time - start_time# 处理并保存结果for i, res in enumerate(output):print(f"\n===== 页面 {i+1} 结果 =====")res.print() # 打印结构化输出# 生成唯一文件名(基于输入文件名)base_name = os.path.splitext(os.path.basename(input_path))[0]if len(output) > 1:base_name += f"_page{i+1}"# 保存结果res.save_to_json(save_path=output_dir)res.save_to_markdown(save_path=output_dir)res.save_to_img(save_path=output_dir) # 保存可视化图片print(f"\n处理完成!结果已保存至: {output_dir}")print(f"总耗时: {total_time:.2f} 秒")# 使用示例
if __name__ == "__main__":# 初始化处理器(可根据需要调整参数)processor = PaddleOCRProcessor(use_doc_orientation_classify=True,use_doc_unwarping=True)# 指定输入和输出路径input_image = r"/root/lanyun-tmp/ppocr-vl/img/信息.png" # 替换为实际图像路径output_directory = "/root/lanyun-tmp/ppocr-vl/output" # 替换为输出目录# 处理图像processor.process_image(input_image, output_directory)3.2 手写体公式
上来就先测试一下最难的
输入:

输出:

这个的话,主要是输入的字也比较差乱,整理来说,模型的输出还是很强的。
1)缺失了部分信息
2)大致都可以识别出来
3.3 分析过程
| 文件名 | 文件类型 | 核心功能与内容 |
|---|---|---|
| | 图片 | 版面检测可视化:直观展示模型如何划分文档中的不同区域(如文本、公式、表格)。 |
| | 图片 | 阅读顺序可视化:在版面检测的基础上,用数字序号标明模型推测的正确阅读顺序。 |
| | 数据文件 | 结构化识别结果:包含所有识别出的文本、公式、位置坐标、置信度等机器可读的完整信息。 |
| | 文档 | 结构化文档重建:将 JSON 文件中的信息,按照阅读顺序整理成可读性良好的 Markdown 文档。 |
先进行目标检测,再进行阅读顺序标记,在识别成json文件,最后变成md格式文件
版面目标检测,区分哪个部分是什么

阅读顺序打分

这个很厉害,确实是这样的阅读顺序。
消耗的速度是3.27s
3.4 表格识别

效果很好,可以把印章下的公司名称识别出来。比之前测评的所有OCR模型效果都好,而且,没有把表格心内搞错。
3.5 小结
1)PaddleOCR-VL的开源意味着OCR正式进入2.0时代,有紧凑的VLM模型能够把图片的阅读顺序标识出来,这个是很有用的,这意味着我们工程化处理一张图片的时候,完全可以根据图片的阅读顺序来让LLM介绍这个图片的内容信息。
2)模型越来越小,速度越来越快,多模态RAG系统可以根据这个开发起来。意味着根据图片精细化地回答用户问题完全可能,因为json文件中还带有元素的坐标位置。
四、参考内容
使用教程 - PaddleOCR 文档