【图像超分】论文复现:轻量化超分 | RLFN的Pytorch源码复现,跑通源码,整合到EDSR-PyTorch中进行训练、测试
【图像超分】论文复现:轻量化超分 | RLFN的Pytorch源码复现,跑通源码,整合到EDSR-PyTorch中进行训练、测试
前言
论文题目:Residual Local Feature Network for Efficient Super-Resolution
论文地址:https://arxiv.org/abs/2205.07514
论文源码:https://github.com/bytedance/RLFN
NTIRE 2022高效超分辨率挑战赛运行赛道第一名
摘要:基于深度学习的方法在单幅图像超分辨率(SISR)中取得了很好的效果。然而,高效超分辨率的最新进展主要集中在减少参数数量和FLOPs(每秒所执行的浮点运算次数,用来衡量计算机的计算能力以及模型的复杂度),并通过复杂的层连接策略提高特征利用率来聚合更强大的特征。这些结构可能不是实现更高运行速度所必需的,这使得它们难以部署到资源受限的设备上。本文提出了一种新的残差局部特征网络(RLFN)。主要思想是使用三层卷积进行残差局部特征学习,简化特征聚合,在模型性能和推理时间之间实现了很好的权衡。此外,我们回顾了流行的对比损失,并观察到其特征提取器的中间特征的选择对性能有很大影响。此外,我们还提出了一种新的多阶段暖启动训练策略。在每个阶段,利用前几个阶段的预训练权值来提高模型的性能。结合改进的对比损失和训练策略,所提出的RLFN在运行时间方面优于所有最先进的高效图像SR模型,同时保持SR的PSNR和SSIM。此外,我们还获得了NTIRE 2022高效超分辨率挑战赛运行赛道第一名。
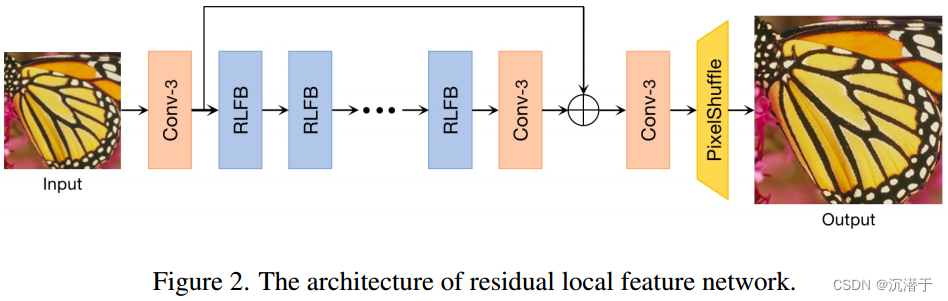
网络结构
RLFN主要由三部分组成:第一部分特征提取卷积、多个堆叠残差局部特征块(rlfb)和重构模块。
数据
| model | Runtime[ms] | Params[M] | Flops[G] | Acts[M] | GPU Mem[M] |
|---|---|---|---|---|---|
| RLFN_ntire | 27.11 | 0.317 | 19.70 | 80.05 | 377.91 |
模型代码
模型现在有三个版本,分别为rlfn.py,rlfn_ntire.py,rlfn_s.py
rlfn.py
# -*- coding: utf-8 -*-
# Copyright 2022 ByteDance
import torch.nn as nn
from model import blockclass RLFN(nn.Module):"""Residual Local Feature Network (RLFN)Model definition of RLFN in `Residual Local Feature Network forEfficient Super-Resolution`"""def __init__(self,in_channels=3,out_channels=3,feature_channels=52,upscale=4):super(RLFN, self).__init__()self.conv_1 = block.conv_layer(in_channels,feature_channels,kernel_size=3)self.block_1 = block.RLFB(feature_channels)self.block_2 = block.RLFB(feature_channels)self.block_3 = block.RLFB(feature_channels)self.block_4 = block.RLFB(feature_channels)self.block_5 = block.RLFB(feature_channels)self.block_6 = block.RLFB(feature_channels)self.conv_2 = block.conv_layer(feature_channels,feature_channels,kernel_size=3)self.upsampler = block.pixelshuffle_block(feature_channels,out_channels,upscale_factor=upscale)def forward(self, x):out_feature = self.conv_1(x)out_b1 = self.block_1(out_feature)out_b2 = self.block_2(out_b1)out_b3 = self.block_3(out_b2)out_b4 = self.block_4(out_b3)out_b5 = self.block_5(out_b4)out_b6 = self.block_6(out_b5)out_low_resolution = self.conv_2(out_b6) + out_featureoutput = self.upsampler(out_low_resolution)return outputrlfn_ntire.py
# -*- coding: utf-8 -*-
# Copyright 2022 ByteDance
import torch.nn as nn
from model import blockclass RLFN_Prune(nn.Module):"""Residual Local Feature Network (RLFN)Model definition of RLFN in NTIRE 2022 Efficient SR Challenge"""def __init__(self,in_channels=3,out_channels=3,feature_channels=46,mid_channels=48,upscale=4):super(RLFN_Prune, self).__init__()self.conv_1 = block.conv_layer(in_channels,feature_channels,kernel_size=3)self.block_1 = block.RLFB(feature_channels, mid_channels)self.block_2 = block.RLFB(feature_channels, mid_channels)self.block_3 = block.RLFB(feature_channels, mid_channels)self.block_4 = block.RLFB(feature_channels, mid_channels)self.conv_2 = block.conv_layer(feature_channels,feature_channels,kernel_size=3)self.upsampler = block.pixelshuffle_block(feature_channels,out_channels,upscale_factor=upscale)def forward(self, x):out_feature = self.conv_1(x)out_b1 = self.block_1(out_feature)out_b2 = self.block_2(out_b1)out_b3 = self.block_3(out_b2)out_b4 = self.block_4(out_b3)out_low_resolution = self.conv_2(out_b4) + out_featureoutput = self.upsampler(out_low_resolution)return outputrlfn_s.py
# -*- coding: utf-8 -*-
# Copyright 2022 ByteDance
import torch.nn as nn
from model import blockclass RLFN_S(nn.Module):"""Residual Local Feature Network (RLFN)Model definition of RLFN_S in `Residual Local Feature Network for Efficient Super-Resolution`"""def __init__(self,in_channels=3,out_channels=3,feature_channels=48,upscale=4):super(RLFN_S, self).__init__()self.conv_1 = block.conv_layer(in_channels,feature_channels,kernel_size=3)self.block_1 = block.RLFB(feature_channels)self.block_2 = block.RLFB(feature_channels)self.block_3 = block.RLFB(feature_channels)self.block_4 = block.RLFB(feature_channels)self.block_5 = block.RLFB(feature_channels)self.block_6 = block.RLFB(feature_channels)self.conv_2 = block.conv_layer(feature_channels,feature_channels,kernel_size=3)self.upsampler = block.pixelshuffle_block(feature_channels,out_channels,upscale_factor=upscale)def forward(self, x):out_feature = self.conv_1(x)out_b1 = self.block_1(out_feature)out_b2 = self.block_2(out_b1)out_b3 = self.block_3(out_b2)out_b4 = self.block_4(out_b3)out_b5 = self.block_5(out_b4)out_b6 = self.block_6(out_b5)out_low_resolution = self.conv_2(out_b6) + out_featureoutput = self.upsampler(out_low_resolution)return outputblock.py
# -*- coding: utf-8 -*-
# 编码声明,确保文件支持中文等Unicode字符
# Copyright 2022 ByteDance
# 版权声明,归属ByteDance公司from collections import OrderedDict
# 导入OrderedDict,用于创建有序字典
import torch.nn as nn
# 导入PyTorch的神经网络模块
import torch.nn.functional as F# 导入PyTorch的函数式接口,包含各种激活函数、池化等操作def _make_pair(value):# 将输入值转换为长度为2的元组(如果输入是整数)if isinstance(value, int):# 如果输入是整数,将其转换为两个相同元素的元组value = (value,) * 2return valuedef conv_layer(in_channels,out_channels,kernel_size,bias=True):"""重写卷积层,实现自适应填充(padding)"""kernel_size = _make_pair(kernel_size)# 计算填充大小,使卷积前后特征图尺寸不变(当步长为1时)padding = (int((kernel_size[0] - 1) / 2),int((kernel_size[1] - 1) / 2))# 返回创建的卷积层return nn.Conv2d(in_channels,out_channels,kernel_size,padding=padding,bias=bias)def activation(act_type, inplace=True, neg_slope=0.05, n_prelu=1):"""激活函数层工厂函数,支持['relu', 'lrelu', 'prelu']三种类型参数----------act_type: str激活函数类型,必须是['relu', 'lrelu', 'prelu']中的一种inplace: bool是否使用inplace操作(节省内存)neg_slope: float'lrelu'或'prelu'在负区间的斜率n_prelu: int'prelu'的参数数量----------"""act_type = act_type.lower()# 转换为小写,确保输入不区分大小写if act_type == 'relu':# 创建ReLU激活层layer = nn.ReLU(inplace)elif act_type == 'lrelu':# 创建LeakyReLU激活层layer = nn.LeakyReLU(neg_slope, inplace)elif act_type == 'prelu':# 创建PReLU激活层layer = nn.PReLU(num_parameters=n_prelu, init=neg_slope)else:# 不支持的激活函数类型则抛出异常raise NotImplementedError('激活层 [{:s}] 未实现'.format(act_type))return layerdef sequential(*args):"""将传入的模块按顺序添加到Sequential容器中参数----------args: 按顺序传入的模块定义-------"""if len(args) == 1:# 如果只有一个参数if isinstance(args[0], OrderedDict):# 不支持OrderedDict作为输入raise NotImplementedError('sequential不支持OrderedDict输入')return args[0]modules = []# 遍历所有传入的模块for module in args:if isinstance(module, nn.Sequential):# 如果是Sequential容器,将其内部模块展开添加for submodule in module.children():modules.append(submodule)elif isinstance(module, nn.Module):# 如果是单个模块,直接添加modules.append(module)# 创建并返回新的Sequential容器return nn.Sequential(*modules)def pixelshuffle_block(in_channels,out_channels,upscale_factor=2,kernel_size=3):"""根据 upscale_factor 对特征进行上采样(像素重排)"""# 创建卷积层,输出通道数为目标通道数乘以 upscale_factor 的平方conv = conv_layer(in_channels,out_channels * (upscale_factor ** 2),kernel_size)# 创建像素重排层,实现上采样pixel_shuffle = nn.PixelShuffle(upscale_factor)# 将卷积层和像素重排层按顺序组合return sequential(conv, pixel_shuffle)class ESA(nn.Module):"""增强空间注意力机制(ESA)的修改版,源自论文`Residual Feature Aggregation Network for Image Super-Resolution`注:此处删除了原实现中未使用的`conv_max`和`conv3_`相关代码"""def __init__(self, esa_channels, n_feats, conv):#esa_channels:16super(ESA, self).__init__()# 初始化ESA通道数f = esa_channels# 1x1卷积压缩通道数self.conv1 = conv(n_feats, f, kernel_size=1)# 1x1卷积处理跳跃连接的特征self.conv_f = conv(f, f, kernel_size=1)# 3x3卷积,步长为2,无填充(用于降采样)self.conv2 = conv(f, f, kernel_size=3, stride=2, padding=0)# 3x3卷积,带填充(用于特征提取)self.conv3 = conv(f, f, kernel_size=3, padding=1)# 1x1卷积恢复通道数self.conv4 = conv(f, n_feats, kernel_size=1)# Sigmoid激活函数,生成注意力权重self.sigmoid = nn.Sigmoid()# ReLU激活函数self.relu = nn.ReLU(inplace=True)def forward(self, x):# 对输入特征进行通道压缩c1_ = (self.conv1(x))# 降采样c1 = self.conv2(c1_)# 最大池化进一步降采样v_max = F.max_pool2d(c1, kernel_size=7, stride=3)# 特征提取c3 = self.conv3(v_max)# 上采样恢复到原始特征图尺寸c3 = F.interpolate(c3, (x.size(2), x.size(3)),mode='bilinear', align_corners=False)# 处理跳跃连接的特征cf = self.conv_f(c1_)# 特征融合并恢复通道数c4 = self.conv4(c3 + cf)# 生成注意力权重m = self.sigmoid(c4)# 注意力加权return x * mclass RLFB(nn.Module):"""残差局部特征块(RLFB)"""def __init__(self,in_channels,mid_channels=None,out_channels=None,esa_channels=16):super(RLFB, self).__init__()# 如果未指定中间通道数,默认与输入通道数相同if mid_channels is None:mid_channels = in_channels# 如果未指定输出通道数,默认与输入通道数相同if out_channels is None:out_channels = in_channels# 第一个卷积层(3x3)self.c1_r = conv_layer(in_channels, mid_channels, 3)# 第二个卷积层(3x3)self.c2_r = conv_layer(mid_channels, mid_channels, 3)# 第三个卷积层(3x3),恢复到输入通道数self.c3_r = conv_layer(mid_channels, in_channels, 3)# 1x1卷积调整通道数到输出通道数self.c5 = conv_layer(in_channels, out_channels, 1)# ESA注意力模块self.esa = ESA(esa_channels, out_channels, nn.Conv2d)# LeakyReLU激活函数self.act = activation('lrelu', neg_slope=0.05)def forward(self, x):# 第一层卷积out = (self.c1_r(x))# 激活函数out = self.act(out)# 第二层卷积out = (self.c2_r(out))# 激活函数out = self.act(out)# 第三层卷积out = (self.c3_r(out))# 激活函数out = self.act(out)# 残差连接(跳跃连接)out = out + x# 通过1x1卷积和ESA注意力模块out = self.esa(self.c5(out))return out
复现过程
准备工作
首先配置一下EDSR的环境
下载DIV2K的数据集,数据集地址:https://data.vision.ee.ethz.ch/cvl/DIV2K/

下载RLFN的项目,网址:https://github.com/bytedance/RLFN
下载EDSR的项目,网址:https://github.com/sanghyun-son/EDSR-PyTorch
训练
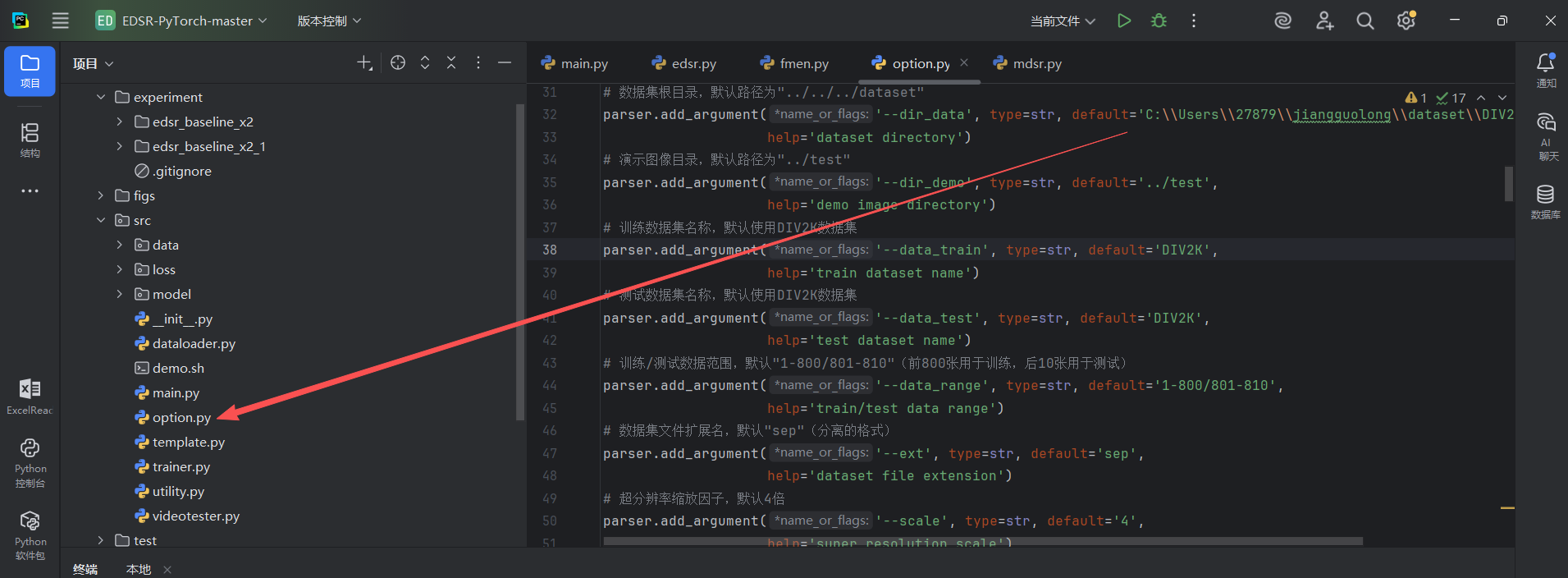
在这个文件中有一个dir_data
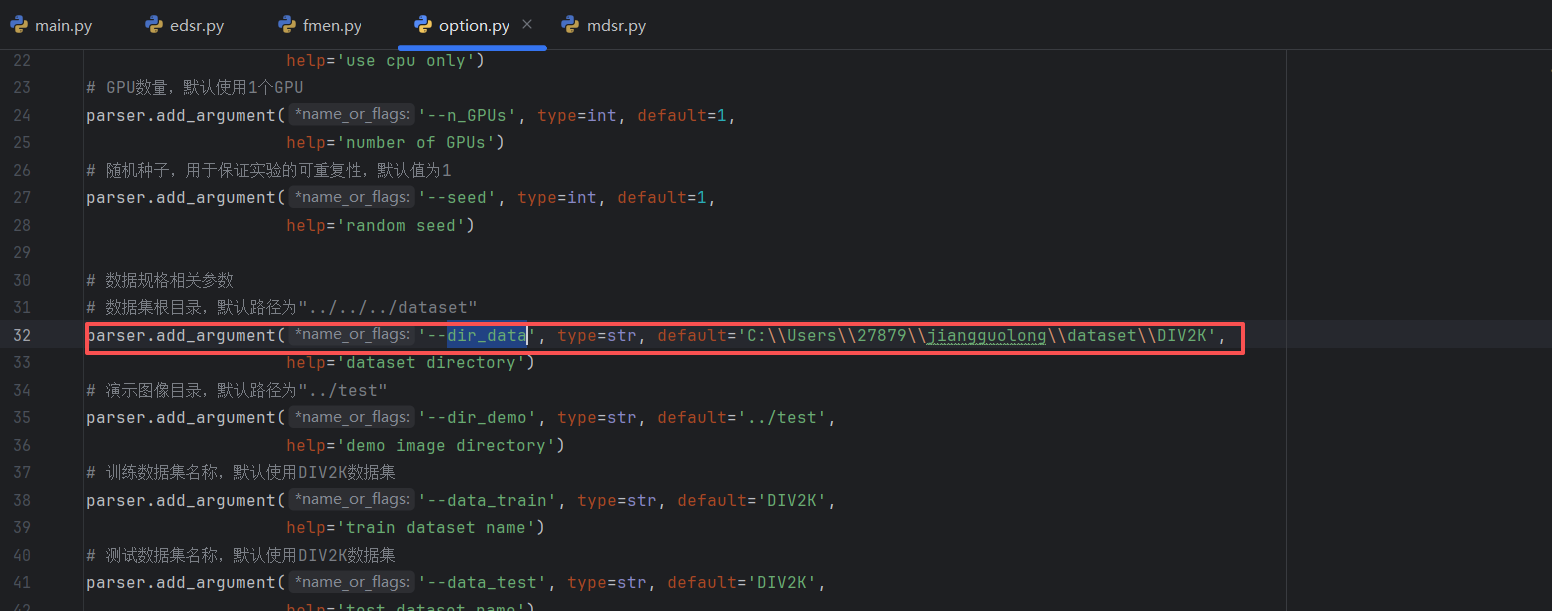
改为自己下载的数据集的位置
然后在FMEN中复制rlfn.py和block.py到EDSR中的src中的model
在src中打开终端
python main.py --model FMEN --scale 4 --patch_size 48 --epochs 300 --save RLFN_baseline_x4 --reset
测试
测试就在RLFN项目中有一个test_demo.py中测试
test_demo.py
# 版权声明:原作者为Yawei Li等人,协议为MIT,可能经字节跳动修改
# 导入操作系统路径处理库,用于处理文件/文件夹路径
import os.path
# 导入日志记录库,用于输出运行过程中的关键信息(如模型参数、处理进度)
import logging
# 从collections导入有序字典类,用于有序存储测试结果(如运行时间)
from collections import OrderedDict
# 导入PyTorch库,深度学习框架,用于加载模型、处理张量和GPU计算
import torch# 从utils工具包导入日志配置函数,用于初始化日志格式和存储路径
from utils import utils_logger
# 从utils工具包导入图像处理函数(如读取图片、张量转换、保存图片),命名为util简化调用
from utils import utils_image as util
# 从utils工具包导入模型统计函数,用于计算模型的计算量(FLOPs)和激活次数
from utils.model_summary import get_model_flops, get_model_activation
# 从model模型包导入RLFN_Prune类,这是超分辨率任务使用的核心模型
from model.rlfn_ntire import RLFN_Prune
from model.rlfn import RLFNdef main():# 1. 初始化日志系统:日志名称为"NTIRE2022-EfficientSR",日志保存到"NTIRE2022-EfficientSR.log"文件utils_logger.logger_info('NTIRE2022-EfficientSR', log_path='NTIRE2022-EfficientSR.log')# 获取日志实例,后续用logger.info()输出关键信息到控制台和日志文件logger = logging.getLogger('NTIRE2022-EfficientSR')# --------------------------------# 2. 基础配置:设置数据路径、GPU/CPU环境# --------------------------------# 注释:原测试集为DIV2K的901-1000张图,当前改为自定义数据路径# 测试数据根目录:拼接当前工作目录(os.getcwd())和"data"文件夹,即"./data"testsets = os.path.join(os.getcwd(), 'data')# 低分辨率(LR)图片文件夹名:自定义为"shangbo_Low_images",对应路径为"./data/shangbo_Low_images"testset_L = 'Urban100/image_SRF_4/LR'# 初始化当前GPU设备(若有多个GPU,默认使用第0个)torch.cuda.current_device()# 清空GPU缓存,释放未使用的显存,避免显存不足问题torch.cuda.empty_cache()# 禁用cudnn的benchmark模式:避免首次运行时花时间优化,适合输入图片尺寸不固定的场景torch.backends.cudnn.benchmark = False# 选择计算设备:优先使用GPU(cuda),若无GPU则使用CPUdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# --------------------------------# 3. 加载超分辨率模型# --------------------------------# 模型权重文件路径:拼接"model_zoo"文件夹和"rlfn_ntire_x4.pth",即"./model_zoo/rlfn_ntire_x4.pth"model_path = os.path.join('model_zoo', 'rlfn_ntire_x4.pth')# 初始化RLFN_Prune模型:输入通道数3(RGB彩色图),输出通道数3(同样为RGB图)model = RLFN_Prune(in_channels=3, out_channels=3)# 加载预训练权重到模型:strict=True表示权重文件的键必须与模型参数完全匹配,避免加载错误model.load_state_dict(torch.load(model_path), strict=True)# 设置模型为评估模式(eval()):关闭训练时的 dropout、批量归一化(BN)更新,确保推理结果稳定model.eval()# 冻结模型所有参数:禁用梯度计算,减少显存占用,加速推理for k, v in model.named_parameters():v.requires_grad = False# 将模型移动到选定的设备(GPU/CPU),确保计算在目标设备上进行model = model.to(device)# 计算并记录模型参数总数:sum()累加所有参数的元素数量(numel())number_parameters = sum(map(lambda x: x.numel(), model.parameters()))# 将参数数量输出到日志logger.info('Params number: {}'.format(number_parameters))# --------------------------------# 4. 配置图片读取路径和结果保存路径# --------------------------------# 低分辨率图片文件夹的完整路径:拼接数据根目录和低分辨率文件夹名L_folder = os.path.join(testsets, testset_L)# 超分辨率结果保存文件夹的完整路径:在数据根目录下新建"xxx_results"文件夹E_folder = os.path.join(testsets, testset_L + '_results')# 调用工具函数创建结果文件夹:若文件夹已存在则不重复创建,避免报错util.mkdir(E_folder)# 初始化有序字典,用于记录测试结果:这里先只记录每张图的运行时间test_results = OrderedDict()test_results['runtime'] = []# 将低分辨率图片路径和结果保存路径输出到日志,确认路径正确logger.info(L_folder)logger.info(E_folder)# 初始化图片计数变量,用于记录当前处理的是第几张图idx = 0# 初始化GPU计时事件:用于精确测量模型推理时间(比CPU计时更准确,避免GPU异步影响)start = torch.cuda.Event(enable_timing=True)end = torch.cuda.Event(enable_timing=True)# 5. 循环读取低分辨率图片,逐张进行超分辨率处理# util.get_image_paths(L_folder):获取文件夹下所有支持格式的图片路径列表for img in util.get_image_paths(L_folder):# --------------------------------# (1) 读取并预处理低分辨率图片(img_L)# --------------------------------# 图片计数+1,更新当前处理的图片序号idx += 1# 提取图片文件名和后缀:如路径"a/b/c.png",img_name是"c",ext是".png"img_name, ext = os.path.splitext(os.path.basename(img))# 将当前处理的图片序号和文件名输出到日志,方便追踪进度logger.info('{:->4d}--> {:>10s}'.format(idx, img_name + ext))# 读取低分辨率图片:uint格式(像素值0-255),3通道(RGB)img_L = util.imread_uint(img, n_channels=3)# 将uint格式图片转为4维张量(batch, channel, height, width):batch=1(单张图),方便模型输入img_L = util.uint2tensor4(img_L)# 像素值缩放:原张量是0-1范围(uint2tensor4默认转换),乘以255恢复为0-255范围,匹配模型训练时的输入格式img_L = img_L * 255.# 将预处理后的张量移动到目标设备(GPU/CPU),确保与模型在同一设备上img_L = img_L.to(device)# 记录推理开始时间(GPU事件计时)start.record()# 模型推理:输入低分辨率张量,输出超分辨率张量(img_E)img_E = model(img_L)# 记录推理结束时间(GPU事件计时)end.record()# 等待GPU完成所有计算(同步操作),确保计时准确,避免异步导致的时间误差torch.cuda.synchronize()# 将当前图片的推理时间(毫秒)存入测试结果字典test_results['runtime'].append(start.elapsed_time(end)) # milliseconds# 注释:以下是CPU计时的备用代码,当前未启用;原理与GPU计时类似,但精度较低# torch.cuda.synchronize()# start = time.time()# img_E = model(img_L)# torch.cuda.synchronize()# end = time.time()# test_results['runtime'].append(end-start) # seconds# --------------------------------# (2) 后处理并保存超分辨率图片(img_E)# --------------------------------# 像素值反向缩放:将模型输出的0-255范围张量,除以255恢复为0-1范围,方便后续转换为uint格式img_E = img_E / 255.# 将4维张量转为uint格式图片(0-255):自动处理张量维度,去除batch维度img_E = util.tensor2uint(img_E)# 保存超分辨率图片:路径为结果文件夹+原文件名前4位+后缀(如"1234.png"),避免文件名过长util.imsave(img_E, os.path.join(E_folder, img_name + '_SR' + ext)) # 加_SR区分超分图# 6. 统计并输出模型性能指标(计算量、激活次数、参数数量)# 设置模型输入维度:(通道数, 高度, 宽度),即3通道256x256图片,用于计算FLOPs和激活次数input_dim = (3, 256, 256) # set the input dimension# 计算模型在指定输入维度下的激活次数和卷积层数量activations, num_conv = get_model_activation(model, input_dim)# 激活次数单位转换:除以1e6,转为"百万次(M)",方便阅读activations = activations / 10 ** 6# 输出激活次数到日志,保留4位小数logger.info("{:>16s} : {:<.4f} [M]".format("#Activations", activations))# 输出卷积层数量到日志logger.info("{:>16s} : {:<d}".format("#Conv2d", num_conv))# 计算模型在指定输入维度下的计算量(FLOPs):False表示不打印详细层信息flops = get_model_flops(model, input_dim, False)# 计算量单位转换:除以1e9,转为"十亿次(G)",方便阅读flops = flops / 10 ** 9# 输出计算量到日志,保留4位小数logger.info("{:>16s} : {:<.4f} [G]".format("FLOPs", flops))# 重新计算模型参数总数(与前面一致,此处为重复验证或统一格式)num_parameters = sum(map(lambda x: x.numel(), model.parameters()))# 参数数量单位转换:除以1e6,转为"百万个(M)",方便阅读num_parameters = num_parameters / 10 ** 6# 输出参数数量到日志,保留4位小数logger.info("{:>16s} : {:<.4f} [M]".format("#Params", num_parameters))# 7. 计算并输出平均推理时间(单位:毫秒)# 平均时间计算:所有图片的运行时间总和 ÷ 图片数量(直接保留毫秒单位)ave_runtime_ms = sum(test_results['runtime']) / len(test_results['runtime'])# 输出平均推理时间到日志,保留6位小数,显示测试文件夹路径logger.info('------> Average runtime of ({}) is : {:.6f} milliseconds'.format(L_folder, ave_runtime_ms))# 8. 程序入口:若当前脚本是直接运行(而非被导入),则执行main()函数
if __name__ == '__main__':main()