公司名称域名网站八戒网站建设
向量数据库基础入门:RAG 与向量检索基础认知构建
📌 一、什么是 RAG?
**RAG(Retrieval-Augmented Generation)**是一种结合“信息检索”和“文本生成”的技术机制,核心目标是:
🔎 检索外部知识来增强大语言模型(LLM)的生成质量、上下文关联性与事实准确性。
换句话说,就是让 ChatGPT 这类大模型“不再闭门造车”,而是“先查资料,再回答问题”。
📍 传统大模型的局限:
| 问题 | 描述 |
|---|---|
| ✅ 信息闭塞 | 训练数据静态,无法获取最新内容 |
| ❌ 容易幻觉 | 编出不存在的内容(hallucination) |
| 🧱 私有知识注入难 | 企业/个人文档无法嵌入模型权重 |
| 💰 模型训练成本高 | 想更新知识只能再训练/微调 |
✅ RAG 的优势:
| 模块 | 功能 |
|---|---|
| 检索模块(Retriever) | 从知识库找出与提问最相关的信息 |
| 生成模块(LLM) | 利用检索结果 + 问题生成答案 |
| 整体效果 | 保留 LLM 语言能力 + 增加知识精度与更新能力 |
🧱 二、RAG 的结构框架与标准工作流程
向量数据库的结构
如图所示
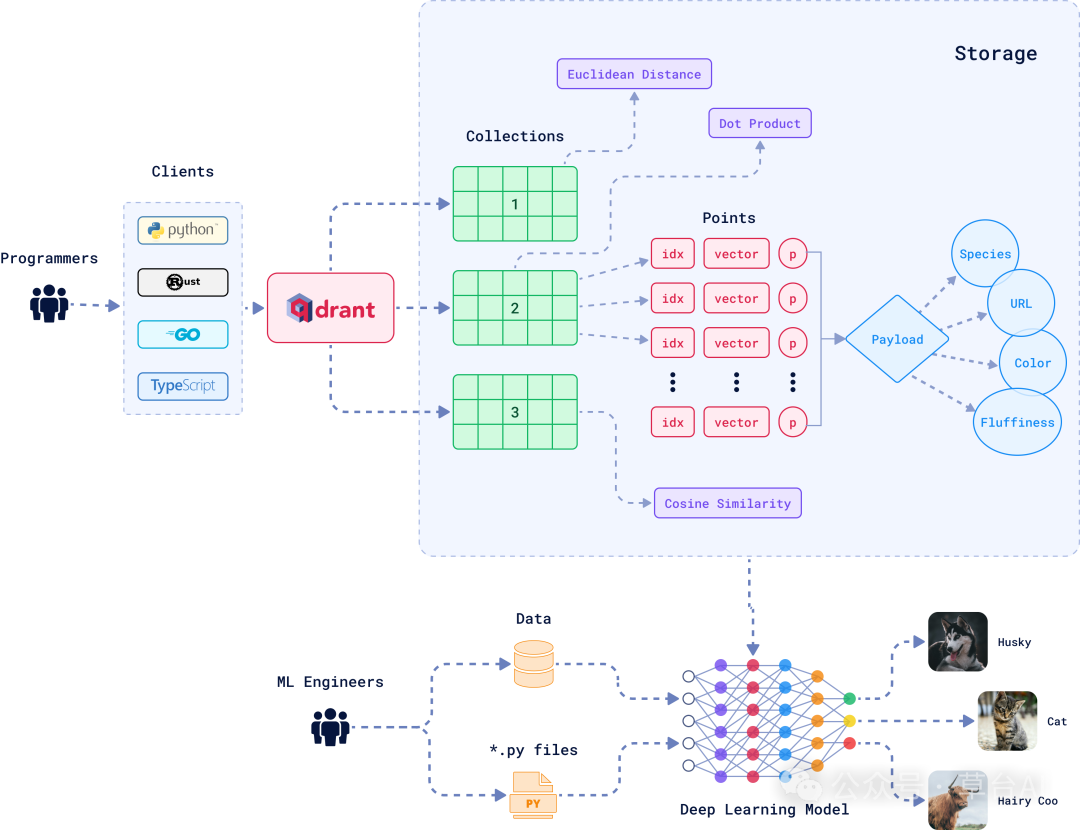
这张图展示的是:
如何将经过深度学习模型编码的向量(向量化后的 chunk)写入 Qdrant,并如何支持多种查询方式(点积、欧几里得距离、余弦相似度)进行高效语义检索。
🧱 图中模块分解讲解
我们来按结构顺序,从左至右、从下至上拆解讲解:
- 底部:深度学习模型 + 数据来源
数据来源:
.py files 表示 ML 工程师使用 Python 写的嵌入模型代码
Data 表示用来训练或推理的文本、图像、标签等
深度学习模型:
模型可以是嵌入模型(如 BERT、bge、E5)
输入的是文字或图像(如猫图、狗图)
输出的是一个固定长度的向量(比如 768维)
💡你可以理解为:这是将 chunk 转为向量的过程。
🟢 2. 中间:Points + Payload 存储结构
这一块是整个图的核心结构,构成了 Qdrant 中的“点集存储结构”(Points)。
每个向量点由三部分组成:
| 成员 | 含义 | 示例 |
|---|---|---|
idx | 向量的唯一索引 | "doc_001_chunk_01" |
vector | 实际的嵌入向量 | [0.012, -0.293, ..., 0.087] |
p / Payload | 该向量的元信息(非向量内容) | {"url":..., "color":"white"} |
📘 Payload 是什么?
Payload 是非向量数据,但与向量关联:
类似于“标签 / 源信息 / 分类属性”
在 RAG 中经常用于:
来源文档 URL
文档类型(pdf/markdown)
主题类别(如“金融” / “医疗”)
🟢 3. 上方:多种相似度计算方式
Qdrant 支持三种检索方式:
| 距离计算方式 | 含义 | 应用场景 |
|---|---|---|
| Euclidean Distance(欧几里得距离) | 基于直线距离 | 距离越小越相似 |
| Dot Product(点积) | 两个向量方向一致性 | 高阶匹配任务 |
| Cosine Similarity(余弦相似度)✅ | 看向量夹角是否接近 | 最常用于文本匹配 |
🟩 4. 右上角:Collections
Qdrant 允许你创建多个“集合”(collections):
每个 collection 可以理解为一个独立的向量表
比如:
collection_1: 产品知识库
collection_2: 技术手册库
collection_3: 用户反馈数据
你可以在 RAG 系统中根据业务拆分多个知识集合,提高检索效率。
🧑💻 5. 左侧:客户端调用方式
开发者可以用多种语言来操作 Qdrant 接口:
Python:最常见,用于 RAG 项目中配合 LangChain/LlamaIndex
Rust:Qdrant 原生语言
Go、TypeScript:也可用于服务端/前端集成
→ 在 RAG 系统中,通常是用 Python SDK 操作 Qdrant。
🧠 总结:这张图在 RAG 系统中的意义
| 功能 | 对应图中内容 | 作用 |
|---|---|---|
| 文档嵌入 | Deep Learning Model 输出 vector | 将 chunk 向量化 |
| 知识存储 | Qdrant 的 Points | 存储向量 + metadata |
| 检索能力 | Cosine / Dot / Euclidean | 支持多方式相似度计算 |
| 数据管理 | Collections + Payload | 多集合 + 精细过滤 |
| 开发集成 | Python 等客户端 | 用于构建 RAG 应用接口 |
RAG的工作流程
RAG 的核心目标是:
让大语言模型(LLM)具备“查资料再回答”的能力。
它结构上是两大部分协同:
| 模块 | 功能 | 常见工具 |
|---|---|---|
| 用户输入 | 提供查询意图 | 输入界面 / API |
| 嵌入模型(Embedder) | 将用户输入转为向量(语义表示) | OpenAI、bge、E5 |
| 向量数据库(Vector Store) | 存储所有文档向量,支持相似度检索 | FAISS、Qdrant |
| 检索器(Retriever) | 从向量库中取 Top-k 最相关内容 | LangChain Retriever / LlamaIndex Retriever |
| Prompt 构建器 | 把用户问题 + 检索内容拼成 LLM 的输入 | PromptTemplate |
| LLM(生成器) | 用 LLM 生成文本回答 | GPT-4、Claude、Moonshot |
| 答案输出 | 传给用户,支持附带来源 | UI、API 响应 |
📌 小提示:
有时候 RAG 也会加入一个 Reranker:对 Top-K 检索结果进行再排序,以提升精准度。
Chunk(文档切块)大小、检索 Top-K 个数、拼接上下文长度,这些都会影响最终效果。
三、向量检索机制详解(RAG 的底层引擎)
1️⃣ 什么是文本向量化(Embedding)?
嵌入模型将一段文本变成一个固定长度的高维向量:
“图神经网络是一种处理图结构数据的模型”-> [1,2,3]
🛠 常用嵌入模型:
| 模型 | 优势 | 是否开源 |
|---|---|---|
text-embedding-ada-002 | OpenAI 出品,泛用性强 | ❌ |
bge-base-zh, bge-m3 | 中文效果非常好 | ✅ |
E5, GTE, Cohere-embed | 英文任务性能优 | ✅ |
文本是如何被向量化的?(向量检索底层机制)
文本嵌入就是:将自然语言文本编码为一个向量(向量表示其语义特征)。
举例说明:
输入句子:“图神经网络可以用于社交网络分析”
输出向量:一个 768 维的浮点数组,比如:
[0.0231, -0.0452, 0.3164, …, -0.0017] # len = 768 or 1536
是句子还是词?——取决于模型类型
| 嵌入模型 | 输入粒度 | 输出向量代表 |
|---|---|---|
OpenAI text-embedding-ada-002 | 整段文本(几句话也行) | 整体句向量 |
| bge-base | 支持句子级 | 句向量 |
| E5 | 支持问答分开训练(Query/Passage) | Query 向量 + 文档向量匹配 |
| Word2Vec、GloVe | 词级嵌入(token) | 每个词一个向量(过时) |
💡 在 RAG 中:
一般是 对一个段落 / chunk 进行整体嵌入,输出一个句向量或段落向量,用来做语义检索匹配。
嵌入模型内部是如何做的?
虽然不同模型实现不同,但基本结构如下
文本 → 分词(Tokenizer)→ 转ID → 送入 Transformer → Pooling(平均/首位)→ 得到整体向量
详细流程(以 BERT 为例):
文本分词(tokenize):
“图神经网络可以用于社交网络分析”
→ [“图”, “神经”, “网络”, “可以”, “用于”, “社交”, “网络”, “分析”]
编码为 token ids,输入模型
输出多个 token 向量 → 做 Pooling:
[CLS] 向量(句首代表)或平均所有 token 向量
得到整句的语义向量:用于表示整个 chunk 的“意思”
RAG 中 embedding 应该如何做?
| Chunk | 嵌入粒度 | 推荐做法 |
|---|---|---|
| 一句话 | 可以嵌入,但语义太少,不稳定 | |
| 一段话(300~600字) | ✅ 最佳嵌入单元 | |
| 一个页面 | 太大,丢失重点,模型输入也受限 |
→ 所以常见做法是:
文档 → 按段切分成 chunk → 每个 chunk 嵌入 → 存入向量库
🔍 一个完整例子:embedding 到检索
文档片段(chunk):
“图神经网络是一种对图结构数据建模的方法,能用于社交网络中用户关系的表示与预测。”
用 bge-m3 模型对它做 embedding → 得到一个 1024维向量
用户输入问题:“怎么用 GNN 分析用户关系?”
把问题也做 embedding → 得一个 query 向量
然后计算 query 向量与所有 chunk 向量的相似度 → 取最相似的 Top-K 段作为 LLM 输入上下文
2️⃣ 什么是 Chunk?为什么要切分文档?
一个 100 页的 PDF 不能直接嵌入 → 要拆成小块(chunk)
每个 chunk 生成一个向量,存进向量数据库
检索时才好比对语义相似度
📐 Chunk 切分的关键点:
| 策略 | 说明 |
|---|---|
| 固定长度切分 | 每 500 字分一块,容易实现但有时割裂语义 |
| 滑动窗口 | 有重叠区域,避免信息割裂(例如 500 长度 + 100 overlap) |
| 按标题/段落切分 | 更智能,适合结构化文本,如 Markdown、PDF |
3️⃣ 什么是向量数据库?有什么用?
向量数据库(Vector Database)是用来存储所有向量化的 chunk,并能快速返回“与某个查询向量最相近的几个结果”。
📦 常见向量数据库:
| 名称 | 优点 | 部署方式 |
|---|---|---|
| FAISS | 本地运行、轻量级、无依赖 | ✅ |
| Qdrant | 支持 Metadata 检索、API 友好 | ✅ |
| Milvus | 海量向量支持、企业级 | ✅ |
| Weaviate | 多模态扩展性好 | ✅ |
| Pinecone | SaaS 服务,免部署 | ❌(收费) |
4️⃣ 如何检索 Top-K 相似内容?
核心方法是:相似度计算(通常是余弦相似度
vec(q): 用户问题的向量
vec(v): 向量库中每个 chunk 的向量
Top-K:选出最相似的前 K 个 chunk 作为“候选知识”
四、从输入到输出:一次完整的 RAG 流程拆解(举例)
用户输入:“请解释图神经网络在社交网络分析中的作用”
✅ 系统执行过程:
🔍 嵌入模型将问题转为向量 q
📚 检索向量库,找到如下几个 chunk(知识段):
“图神经网络能在节点之间建模信息传播”
“在社交网络中,GNN 可用于推荐好友关系”
…
🧩 Prompt 拼接(简化示意):
【知识支持】
- 图神经网络能在节点之间建模信息传播。
- 在社交网络中,GNN 可用于推荐好友关系。
【用户问题】
请解释图神经网络在社交网络分析中的作用。
🤖 LLM 根据内容生成答案:
图神经网络(GNN)在社交网络分析中可建模用户之间的关系并进行推荐,如好友预测、群组划分等…
| 特征 | 传统 IR + QA | 纯LLM | ✅ RAG |
|---|---|---|---|
| 精度 | 高,但模板化 | 语言自然,但常幻觉 | 高精度 + 高语言自然度 |
| 更新能力 | 强,可换文档 | 差,需要重训 | 强,可更新文档库 |
| 灵活性 | 较差 | 高 | 高 |
| 应用难度 | 中 | 低 | 中高(但最值得) |