北京海淀财政局网站asp.net 4.0网站开发
目录
引言
1 NameNode水平扩展原理
1.1 传统HDFS架构的局限性
1.2 联邦机制的基本原理
1.3 联邦架构的关键组件
2 多个Namespace的路由规则配置
2.1 客户端挂载表概念
2.2 挂载表配置示例
2.3 挂载表匹配规则
2.4 配置示例
3 BlockPool与Namespace的映射关系
3.1 BlockPool概念
3.2 BlockPool与Namespace关系
3.3 关键特性
4 联邦集群的运维挑战
4.1 主要运维挑战
4.2 应对策略
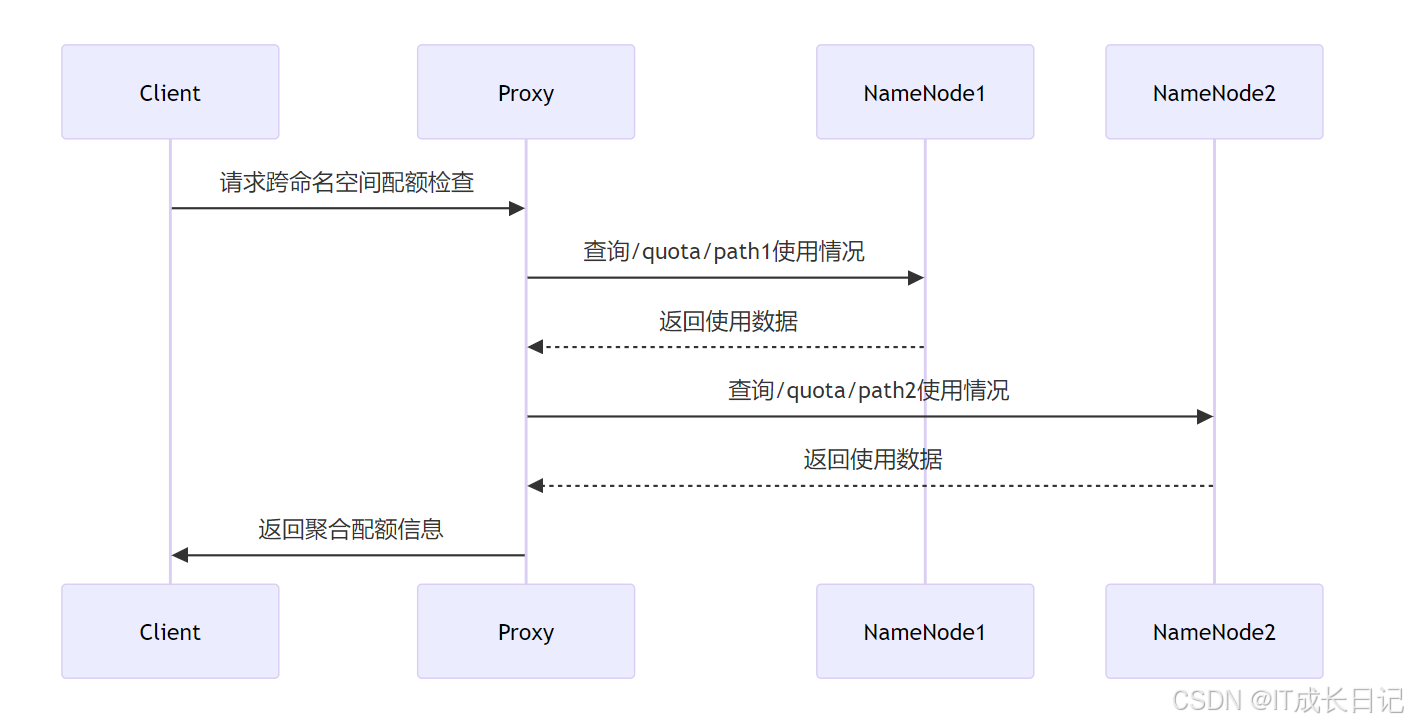
5 跨Namespace的配额管理
5.1 配额管理挑战
5.2 配额管理命令
5.3 跨Namespace配额管理策略
6 总结
引言
在大数据时代,随着数据量的爆炸式增长,Hadoop分布式文件系统(HDFS)面临着前所未有的扩展性挑战。传统的单一NameNode架构逐渐显露出性能瓶颈,而联邦机制(Federation)的引入为HDFS的水平扩展提供了解决方案。
1 NameNode水平扩展原理
1.1 传统HDFS架构的局限性
传统HDFS采用单一NameNode架构,所有元数据都存储在单个NameNode的内存中。这种架构存在两个主要问题:
- 内存限制:NameNode需要将所有文件系统的元数据(包括文件、目录、块信息)保存在内存中,随着数据量增长,内存成为瓶颈
- 吞吐量限制:所有客户端请求都必须通过单个NameNode,导致其成为系统吞吐量的瓶颈
1.2 联邦机制的基本原理
联邦机制通过引入多个NameNode来实现水平扩展,每个NameNode管理文件系统命名空间的一部分。这些NameNode相互独立,不需要相互协调,从而实现了:
- 命名空间扩展:多个NameNode共同管理更大的命名空间
- 性能扩展:客户端请求可以分散到不同的NameNode,提高整体吞吐量
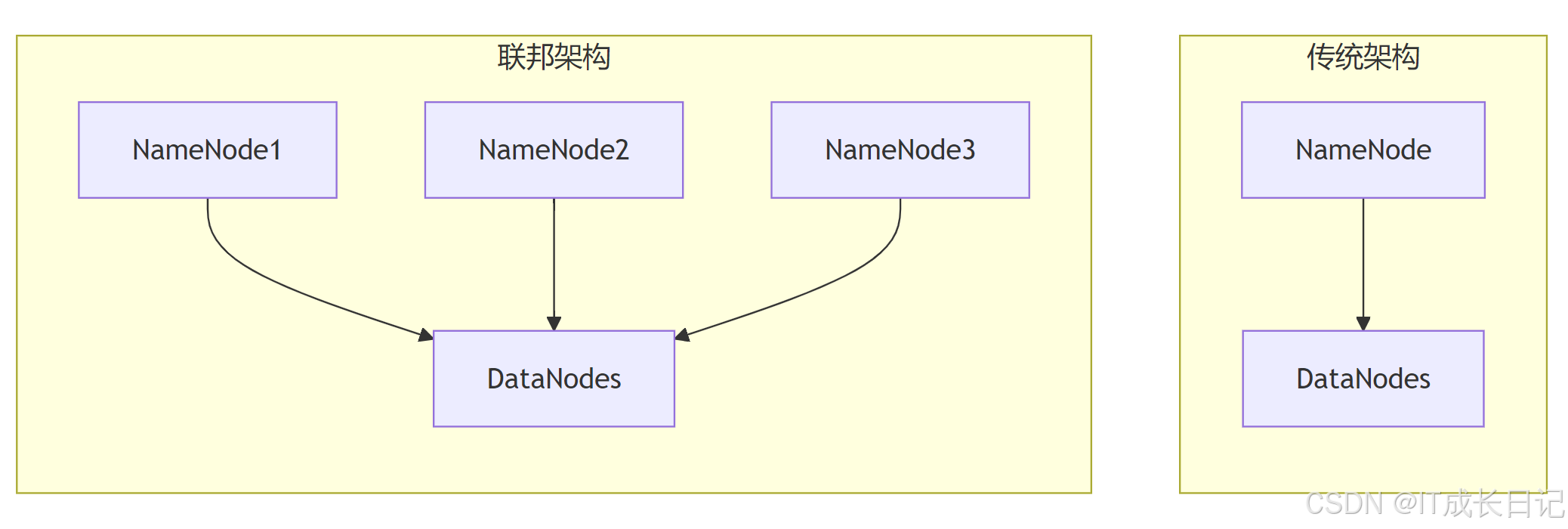
1.3 联邦架构的关键组件
- 多个NameNode:每个管理独立的命名空间
- 共享的DataNode池:所有DataNode为所有NameNode存储数据块
- BlockPool:每个NameNode在DataNode上有独立的数据块池
- 客户端挂载表:决定如何将路径映射到特定的NameNode
2 多个Namespace的路由规则配置
2.1 客户端挂载表概念
客户端挂载表(client.mount.table)是联邦机制中的关键配置,它定义了文件系统路径到特定NameNode的映射关系。通过这个表,客户端知道对于特定的路径应该访问哪个NameNode。
2.2 挂载表配置示例
# 典型的client.mount.table配置如下:
/user => nn1:8020
/data => nn2:8020
/projects => nn3:8020
/tmp => nn1:8020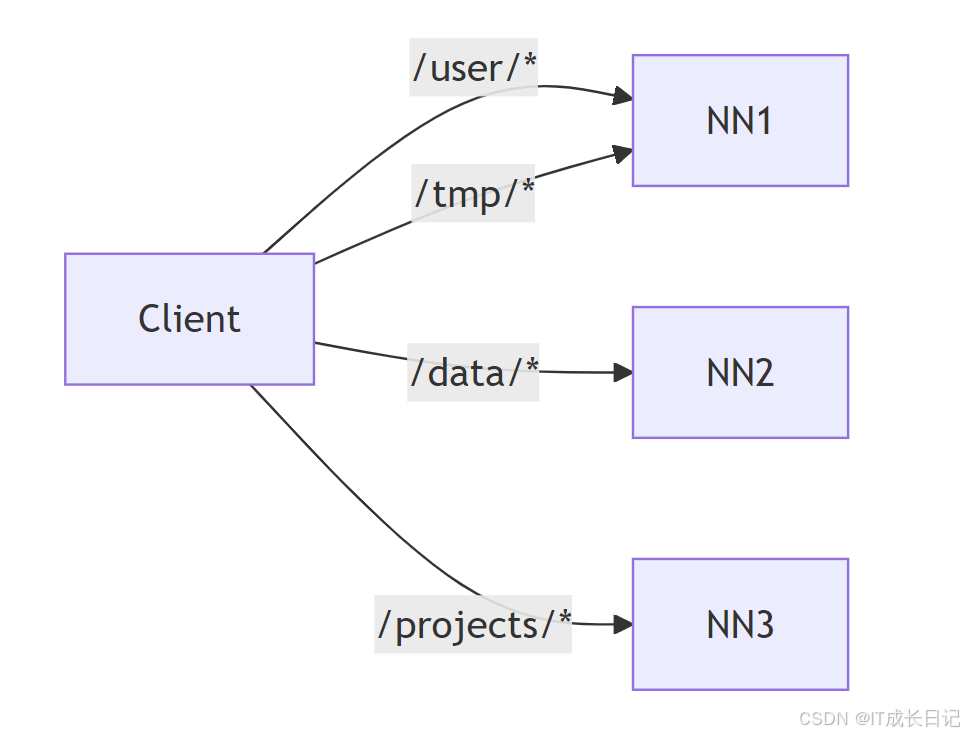
2.3 挂载表匹配规则
- 最长前缀匹配:客户端会寻找与路径匹配的最长前缀
- 默认命名空间:如果没有匹配项,则使用配置的默认命名空间
- 配置位置:通常在core-site.xml中通过fs.defaultFS指定默认命名空间,在hdfs-site.xml中配置挂载表
2.4 配置示例
<!-- core-site.xml -->
<property><name>fs.defaultFS</name><value>hdfs://nn1:8020</value>
</property><!-- hdfs-site.xml -->
<property><name>dfs.nameservices</name><value>nn1,nn2,nn3</value>
</property><property><name>dfs.client.mount.table</name><value>/user hdfs://nn1:8020/data hdfs://nn2:8020/projects hdfs://nn3:8020/tmp hdfs://nn1:8020</value>
</property>3 BlockPool与Namespace的映射关系
3.1 BlockPool概念
在联邦机制中,每个NameNode都有一个独立的BlockPool。BlockPool是DataNode上为特定NameNode存储数据块的逻辑分区。这种设计使得:
- 多个NameNode可以共享相同的DataNode集群
- 每个NameNode管理自己的数据块,互不干扰
3.2 BlockPool与Namespace关系
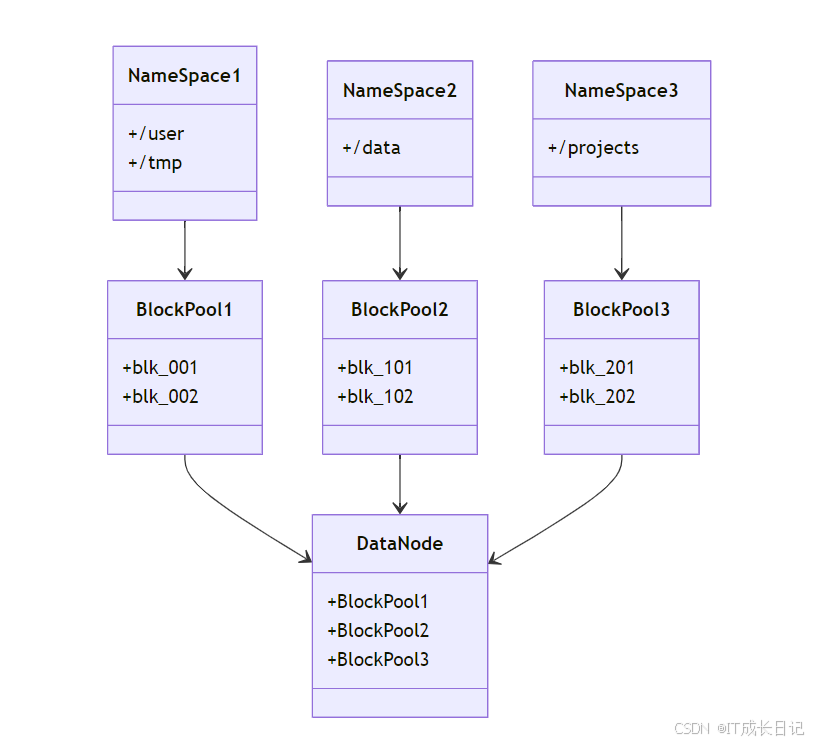
3.3 关键特性
- 独立性:每个BlockPool只属于一个Namespace
- 共享存储:所有BlockPool共享相同的DataNode物理存储
- 隔离性:一个Namespace的问题不会影响其他Namespace的数据
4 联邦集群的运维挑战
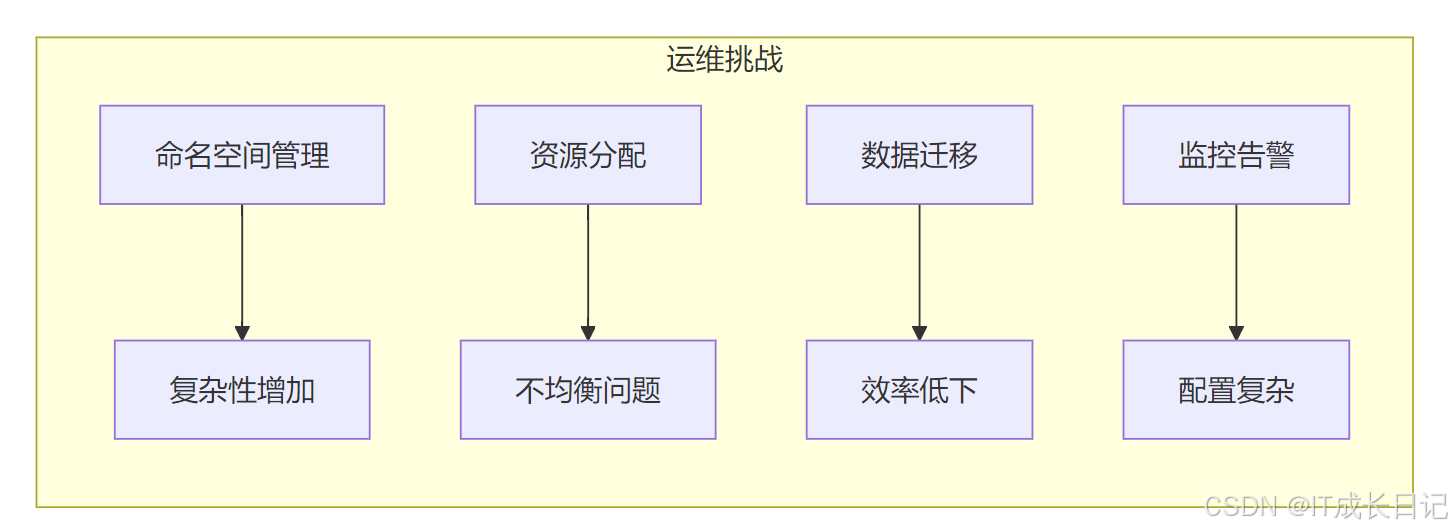
4.1 主要运维挑战
命名空间管理复杂性增加
- 需要管理多个独立的命名空间
- 跨命名空间操作变得复杂
资源分配与平衡
- 不同命名空间可能发展不均衡
- 需要监控每个命名空间的使用情况
数据迁移困难
- 跨命名空间的数据移动效率低
- 需要额外的工具支持
监控与告警复杂性
- 需要为每个命名空间设置监控
- 告警策略需要针对不同命名空间定制
4.2 应对策略
- 自动化工具开发:开发自动化工具管理多个命名空间
- 统一监控平台:建立统一的监控平台覆盖所有命名空间
- 标准化配置:制定配置标准,减少管理复杂度
- 容量规划:定期评估各命名空间使用情况,提前规划
5 跨Namespace的配额管理
5.1 配额管理挑战
在联邦环境中,配额管理面临新的挑战:
- 配额只能在单个命名空间内设置
- 缺乏全局视角的配额管理
- 跨命名空间的目录可能需要统一的配额限制
5.2 配额管理命令
# 设置目录配额(限制文件和目录数量)
hdfs dfsadmin -setQuota <quota> <directory># 清除目录配额
hdfs dfsadmin -clrQuota <directory># 设置空间配额(限制字节数)
hdfs dfsadmin -setSpaceQuota <quota> <directory>5.3 跨Namespace配额管理策略
- 代理层管理:在客户端和NameNode之间增加代理层,实现全局配额管理
- 定期审计:定期审计各命名空间使用情况,手动调整
- 自定义脚本:开发脚本跨命名空间汇总使用情况
6 总结
HDFS联邦机制通过引入多个NameNode有效解决了单一命名空间的扩展性问题。通过客户端挂载表、BlockPool等机制,实现了命名空间的水平扩展。然而,这种架构也带来了运维复杂性的增加,特别是在配额管理、监控等方面。理解这些核心概念和挑战,对于设计和维护大规模HDFS集群至关重要。