Linux-基础IO(1)
在讲解基础IO的知识前,首先,我们先铺垫一些关于文件共识。
在C/C++我们也有了解过一些些文件的内容,但是我们并不知道它的原理,甚至对它有一些抵触的心理,所以,我们得先打破这种局面。
建立共识:
1.文件=内容+属性。
2.文件分为打开的文件和未打开的文件。
那么,打开的文件是谁打开的?进程,它实质上是关于进程和文件的关系。
未打开的文件,放在哪里呢,我们最关心的问题是什么?
未打开的文件放在磁盘当中,我们都知道,未打开的文件非常多,我们最关心的是文件如何被分门别类的储存好?来使得我们可以快速的进行增删查改。
3.大量文件被打开,必须先被加载到内存,因此,进程与打开文件的关系必然是1:n
即,操作系统的内部,一定存在大量的被打开的文件,OS肯定要管理这些被打开的文件,怎么管理,同样用到六个字:“先描述,再组织”
在内核中,一个被打开的文件,都必须有自己的文件打开对象,包含文件的很多属性。
eg:
struct xxxx(文件属性;struct xxxx*next(链表形式组织起来))。
大概流程:
1.先看C语言的文件接口:
2.认识文件系统接口
3.谈谈访问文件的本质
4.重定向+缓冲区
5.补充其他
C语言写文件
(先看现象)
#include<stdio.h>
#include<string.h>
//fopen fwrite
int main()
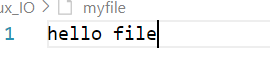
{FILE*fp=fopen("myfile","w");//FILE*fp=fopen("myfile","a");if(fp==NULL){perror("fopen");return;}const char*msg="hello file";int n=fwrite(msg,strlen(msg),1,fp);if(n==0)perror("fwrite");fclose(fp); return 0;
}以“w”打开文件:
本来myfile文件有:这些内容的
编译执行后
以“a”打开文件


读文件
//fopen fread
int main()
{FILE*fp=fopen("myfile","r");if(fp==NULL){perror("fopen");return;}char buf[128];char*msg="hello Linux";while(1){size_t s=fread(buf,1,strlen(msg),fp);if(s>0){buf[s]=0;printf("%s\n",buf);}if(feof(fp))break;}fclose(fp);return 0;
}以“r”读-打开文件
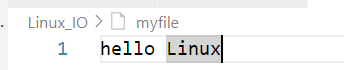

总结:
w:写入,清空并重头写
a:写入,以追加形式写入
另外,我们上面的路径都是当前路径,即进程的当前路径cwd,也就是说如果我更改了当前进程的cwd,就可以把文件新建到其他目录。

上面是写到文件中,那么如果想要输出信息到显示器中,我们有一下三个输入输出流
分别是:stdout(显示器文件),stdiin(键盘文件),stderr(显示器文件)
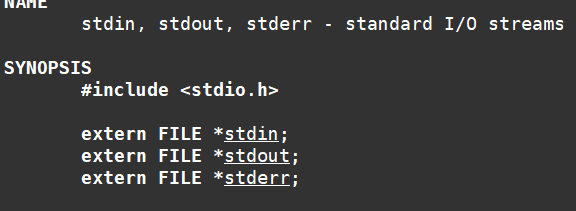

C程序默认在启动的时候,会打开三个标准输入输出流(文件)
这是OS的特性,进程默认会打开键盘,显示器,显示器。
ps:
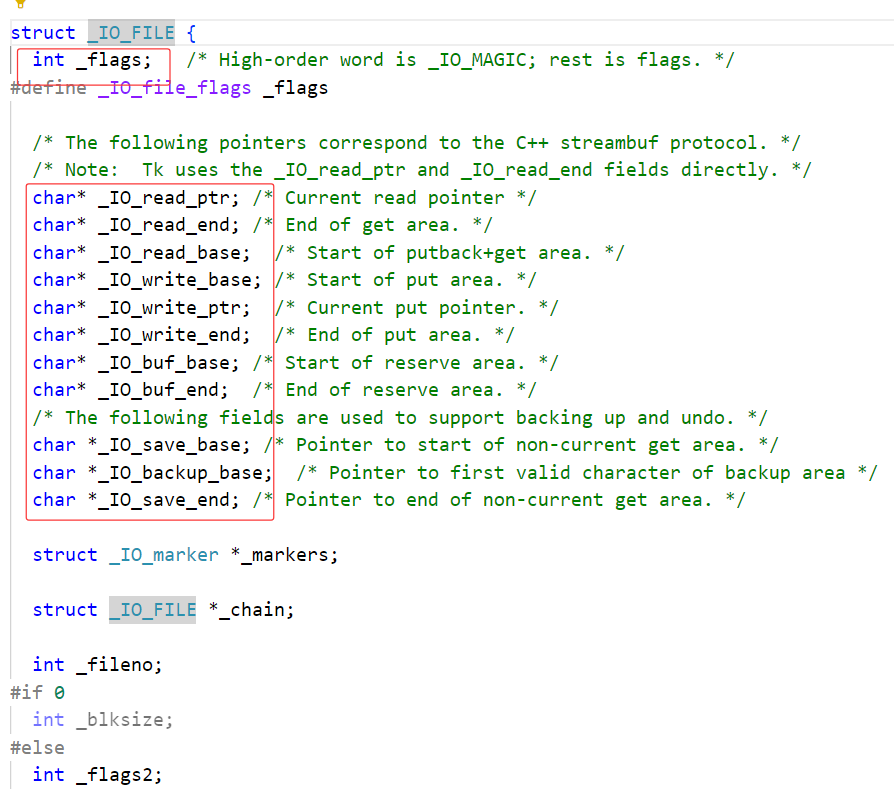
看一下FILE的属性内容:
FILE是自己封装的结构体,这里面必须封装文件描述符!
认识文件系统调用:
文件其实是在磁盘上,磁盘是外部设备,访问磁盘文件其实就是访问硬件!
我们在之前了解到:
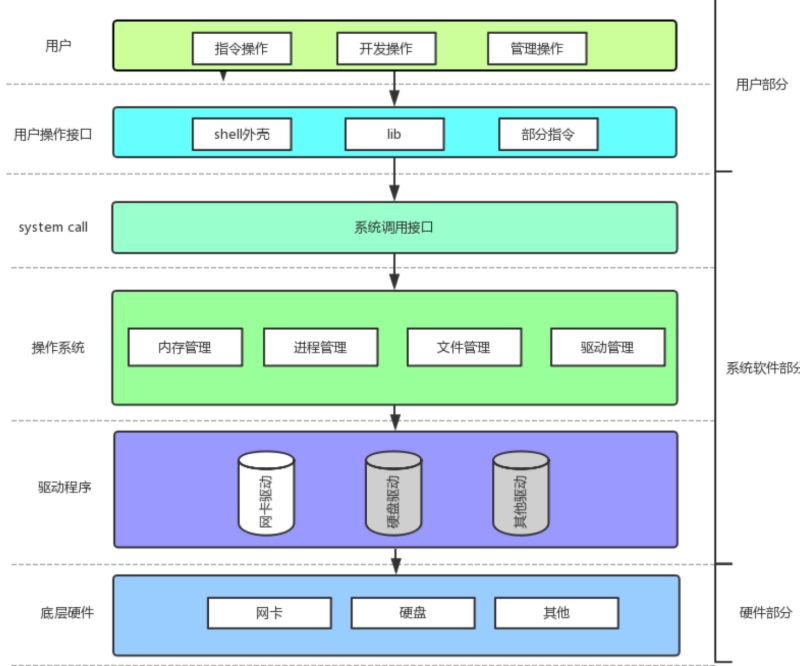
我们几乎所有的库只要是访问硬件设备,必定要封装系统调用。为什么一定要封装?
1.系统不相信任何人
2.程序不能直接绕过我们的操作系统,直接去访问硬件,必须要贯穿OS的方式去访问。
因此,open是操作系统的接口,而fopen是C/C++库的接口。
上面的 fopen fclose fread fwrite 都是C标准库当中的函数,我们称之为库函数(libc)。
而, open close read write lseek 都属于系统提供的接口,称之为系统调用接口
那么,现在我们来认识open:
头文件:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限(否则会乱码)
O_APPEND: 追加写
返回值:
成功:新打开的文件描述符
失败:-1#include<unistd.h>
ssize_t write(int fd, const void *buf, size_t count);ssize_t read(int fd, void *buf, size_t count);
//open read
int main()
{int fd=open("myfile",O_RDONLY);if(fd<0){perror("open");return 1;}const char* msg="hello Linux!";printf("strlen:%d",strlen(msg));// printf("sizeof:%d",sizeof(msg));char buf[128];while(1){ssize_t s=read(fd,buf,strlen(msg));if(s>0){buf[s]=0;printf("%s\n",buf);}elsebreak;}close(fd);return 0;
}
int main()
{int fd=open("myfile",O_WRONLY,O_CREAT,0666);if(fd<0){perror("open");return 1;}const char*msg="hello Linux!";write(fd,msg,strlen(msg));return 0;
}open函数的返回值
它返回的是一个数组的下标,叫做文件描述符
其中Linux进程默认情况下会有3个缺省打开的文件描述符,分别是标准输入0, 标准输出1, 标准错误2. 0,1,2对应的物理设备一般是:键盘,显示器,显示器
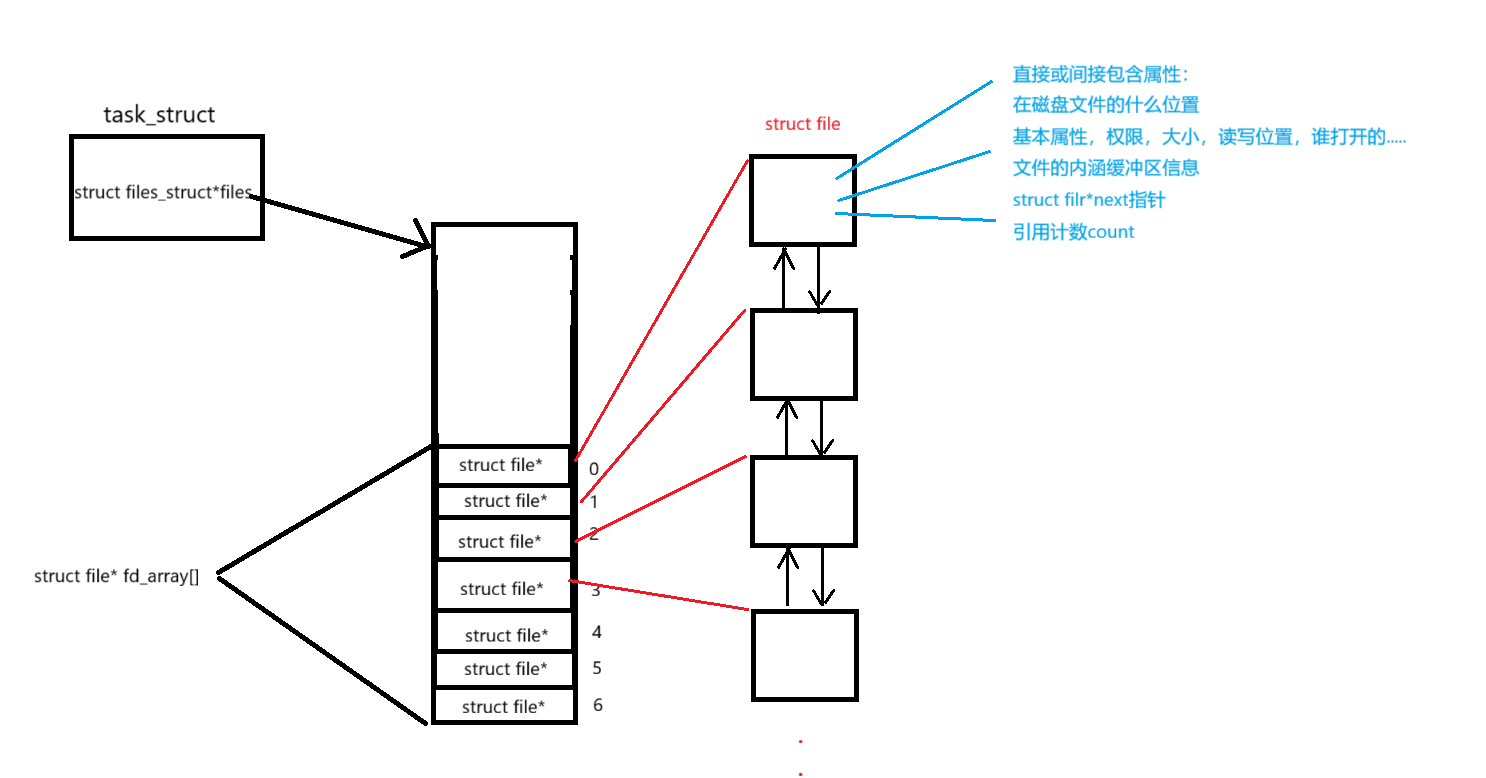
而现在知道,文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包涵一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件
现在来证明一下:
int main()
{char buf[128];ssize_t s=read(0,buf,sizeof(buf));if(s>0){buf[s]=0;write(1,buf,strlen(buf));write(2,buf,strlen(buf));}else{perror("read");return 1;}return 0;
}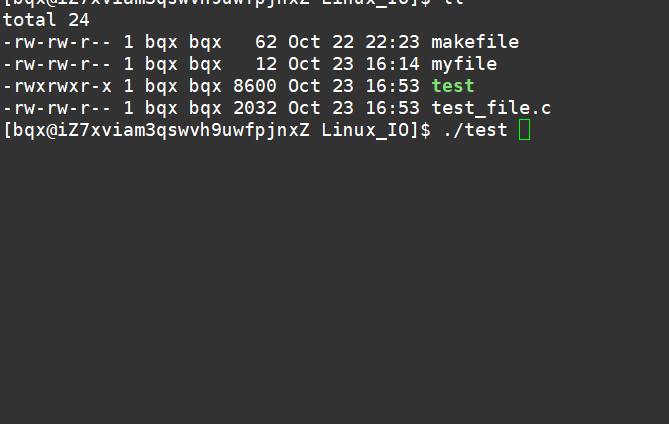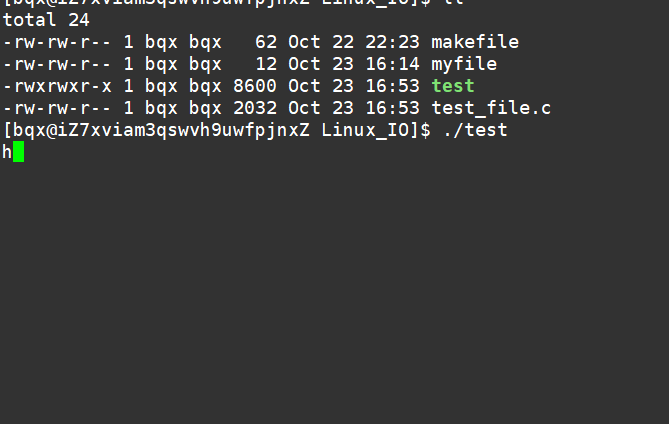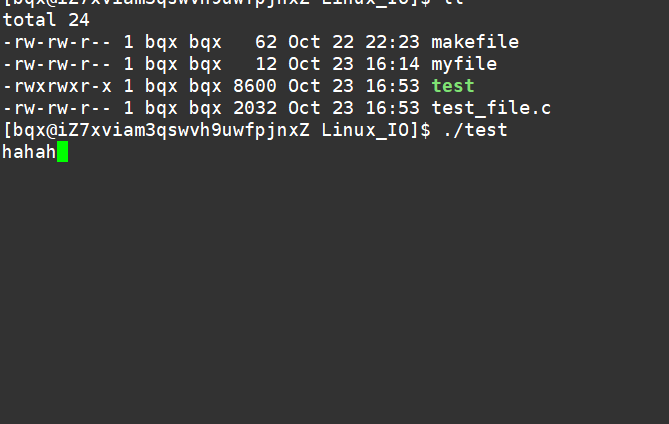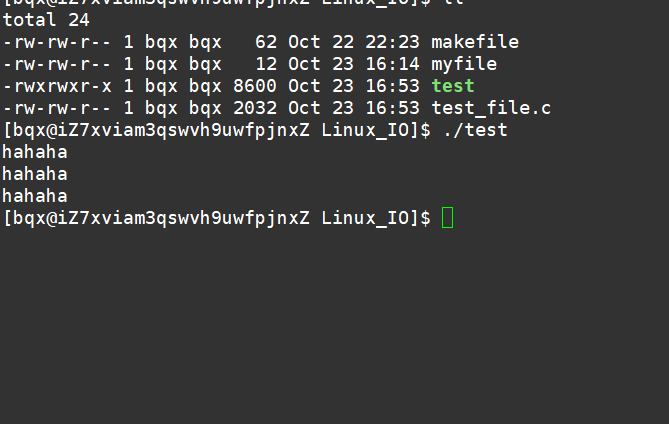
因为,Linux下默认标准输入,标准输出,标准错误分别占了文件描述符表的0,1,2.
对此,我们创建文件的文件描述符,即是从下表3开始的,现在我们来证明一下:
int main() {int fd=open("myfile",O_RDONLY);printf("fd:%d\n",fd);close(fd);return 0;; }
结论:
文件描述符的分配规则:在files_struct数组当中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。

用户缓冲区的理解:
我们先来几段代码看看他们呈现出的不同现象,以此来引入缓冲区的概念:
一:带fork版本的:
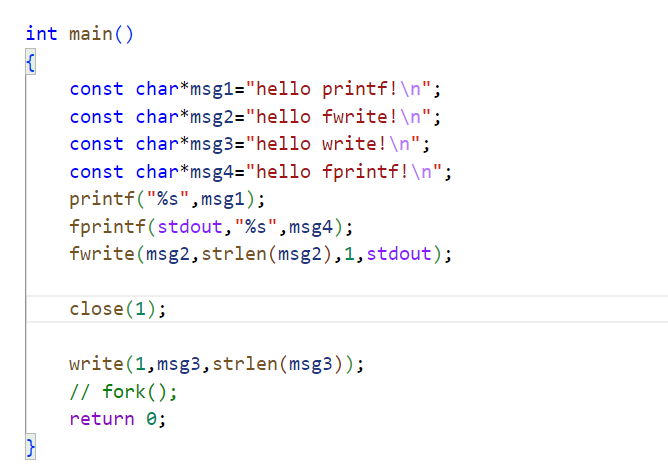
int main() {const char*msg1="hello printf!\n";const char*msg2="hello fwrite!\n";const char*msg3="hello write!\n";const char*msg4="hello fprintf!\n";printf("%s",msg1);fprintf(stdout,"%s",msg4);fwrite(msg2,strlen(msg2),1,stdout);write(1,msg3,strlen(msg3));fork();return 0; }
重定向:


不带fork版本:

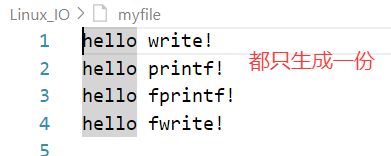
我们从上面不同现象可以看出:这一定与fork脱离不了关系!!(我们待会再说)
继续,如果我们
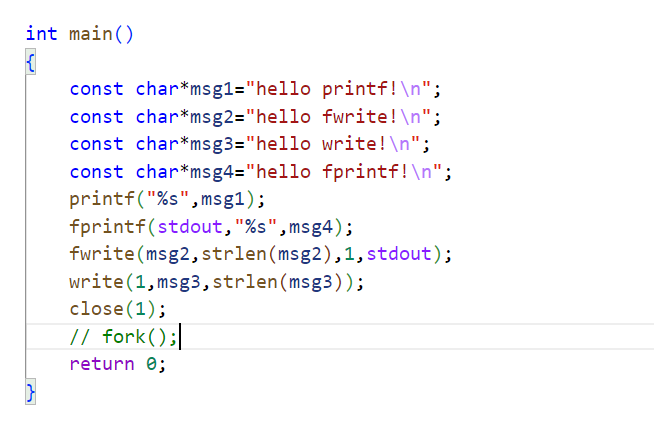

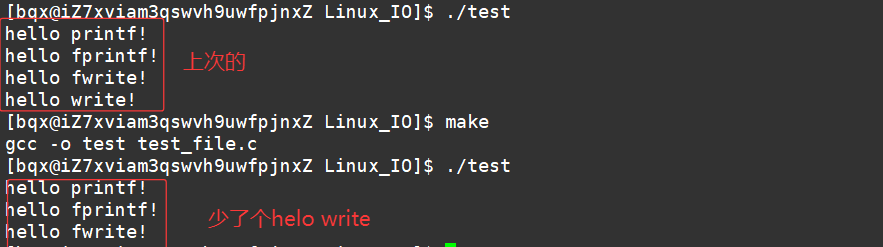
上面我们了解到,write是系统接口,当在write之前关闭了stdout标准输出时,没有打印出来。
这说明了printf,fprintf,fwrite这些缓冲区一定不在操作系统内部,不是系统级别的缓冲区。
因此,这些是C语言给我们提供的一个缓冲区。
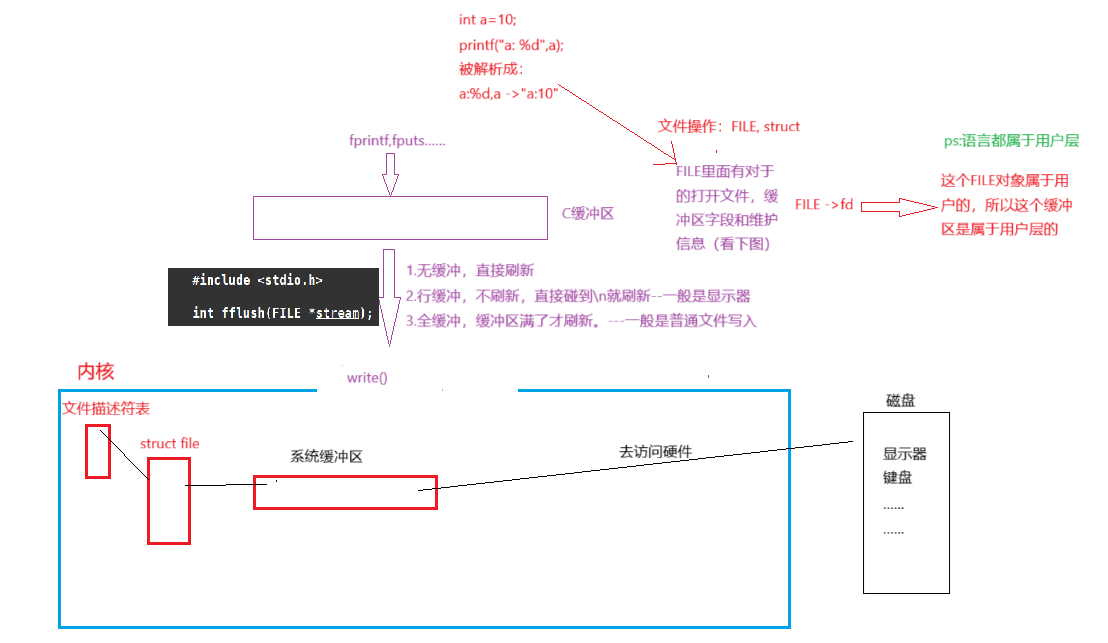
我们来补充一下关于缓冲区的刷新问题:分为三种情况
1.无缓冲,直接刷新
2.行缓冲,不刷新,直接碰到\n就刷新--一般是显示器
3.全缓冲,缓冲区满了才刷新。---一般是普通文件写入
因此,对于显示器文件的刷新方案是行刷新,所以在printf执行完就会立即遇到\n的时候,将数据进行行刷新,即用户刷新的本质,就是将数据通过1+write写入到内核中。
1.进程退出的时候也会进行刷新!!
2. 缓冲区的作用(为什么要有这个缓冲区??)
- 解决效率问题:直接频繁地进行 I/O 操作(比如往磁盘写数据、从键盘读数据)效率很低。缓冲区可以先把数据暂存起来,攒到一定量后再一次性进行 I/O 操作,减少 I/O 次数,提升整体效率。
- 配合格式化:像 printf 这类带格式化输出的函数,需要先把数据按格式整理好,缓冲区能为这种“整理 - 输出”的过程提供暂存空间,让格式化和输出的节奏更合理。
2. 缓冲区的位置
C 语言中的 FILE 结构体(由 fopen 等函数返回的对象)里,包含了对应打开文件的用户级缓冲区字段和维护信息。 FILE 对象属于用户层(因为 C 语言本身是运行在用户空间的),所以它内部的缓冲区也属于用户级缓冲区,而非操作系统内核直接管理的缓冲区。
3. 缓冲区的刷新时机
- 调用 fflush(stdout) 可以主动刷新标准输出( stdout )的缓冲区,把暂存的数据立刻输出。
- 进程调用 exit() 退出时,也会自动刷新缓冲区,确保数据不会因为进程退出而丢失。
有了上面的了解,我们就可以来解释为什么带fork与不带fork重定向出来的结果不同的原因!
一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
printf fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后
但是进程退出之后,会统一刷新,写入文件当中。
但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
write 没有变化,说明没有所谓的缓冲
好了,本次先分享到这里,我们下次继续,希望我们都一起进步!
最后,到了本次鸡汤环节:
慢慢前进!
