零基础掌握 Vanna Text2SQL 框架:从原理到实战训练指南
在数据驱动决策的时代,SQL 作为查询数据库的核心语言,却成了非技术人员获取数据的 “拦路虎”。而 Vanna 框架的出现,彻底改变了这一现状 —— 它基于检索增强生成(RAG)技术,能将自然语言自动转化为可执行的 SQL,让不懂代码的人也能轻松玩转数据库。本文将从 Vanna 的核心原理出发,逐步讲解环境搭建、模型训练全流程,并结合实战案例演示如何通过训练提升 SQL 生成准确性,帮你快速上手这一高效工具。
一、认识 Vanna:让自然语言 “对话” 数据库的开源框架
在开始实战前,我们首先要明确:Vanna 究竟是什么?它为何能实现 “自然语言转 SQL” 的魔法?
1.1 Vanna 核心定位与优势
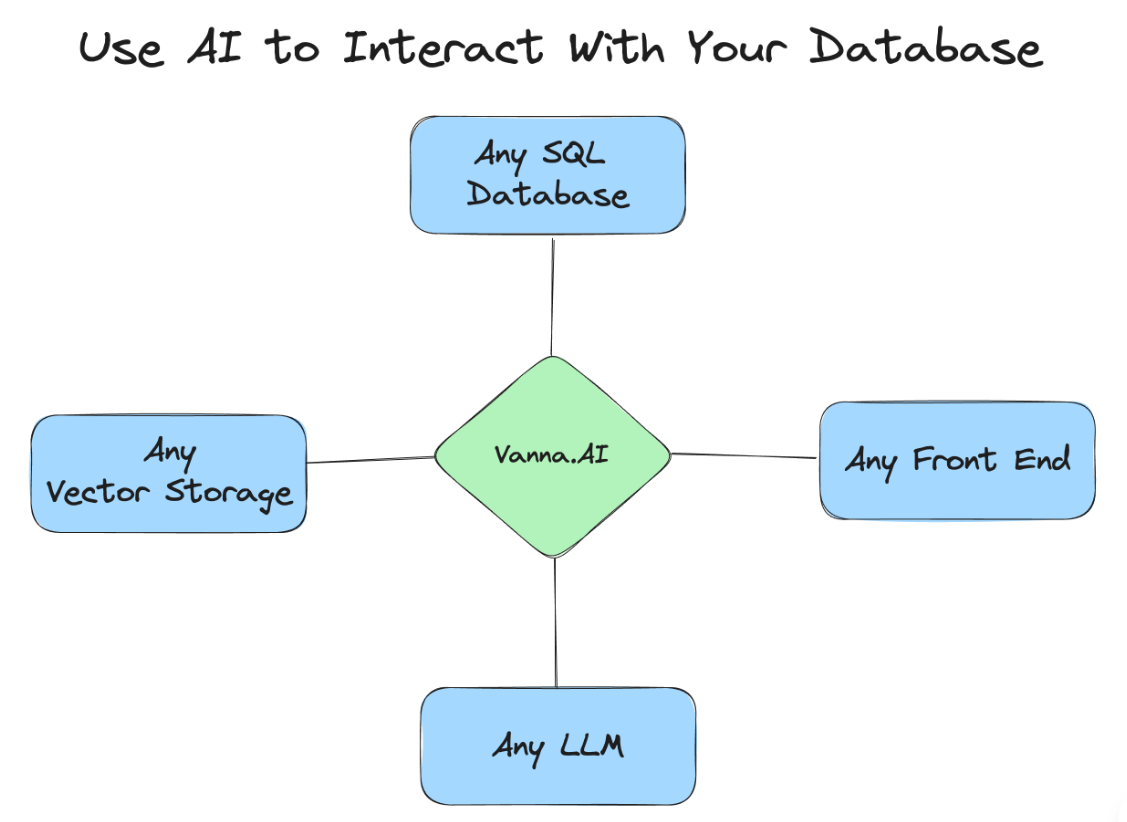
Vanna 是一款基于 MIT 许可的开源 Python RAG 框架,专为 SQL 生成设计,核心目标是降低数据库查询的技术门槛。无论是产品经理、运营人员还是业务分析师,都能通过日常语言提问(如 “本月下单的客户有哪些?”),直接获取数据库查询结果,无需掌握复杂的 SQL 语法。
它的核心优势体现在三点:
- 兼容性强:支持任何 SQL 数据库(SQLite、MySQL、PostgreSQL 等)、任何向量数据库(Milvus、ChromaDB 等)和任何大语言模型(Deepseek、OpenAI 等);
- 自动化程度高:从问题理解、SQL 生成、执行到结果可视化,全流程无需手动干预;
- 可迭代优化:支持通过训练数据持续提升 SQL 生成准确性,适配不同业务场景。
官网与开源地址:
- 官网:https://vanna.ai/
- GitHub:https://github.com/vanna-ai/vanna
1.2 Vanna 工作原理:从 “提问” 到 “出结果” 的 7 步流程
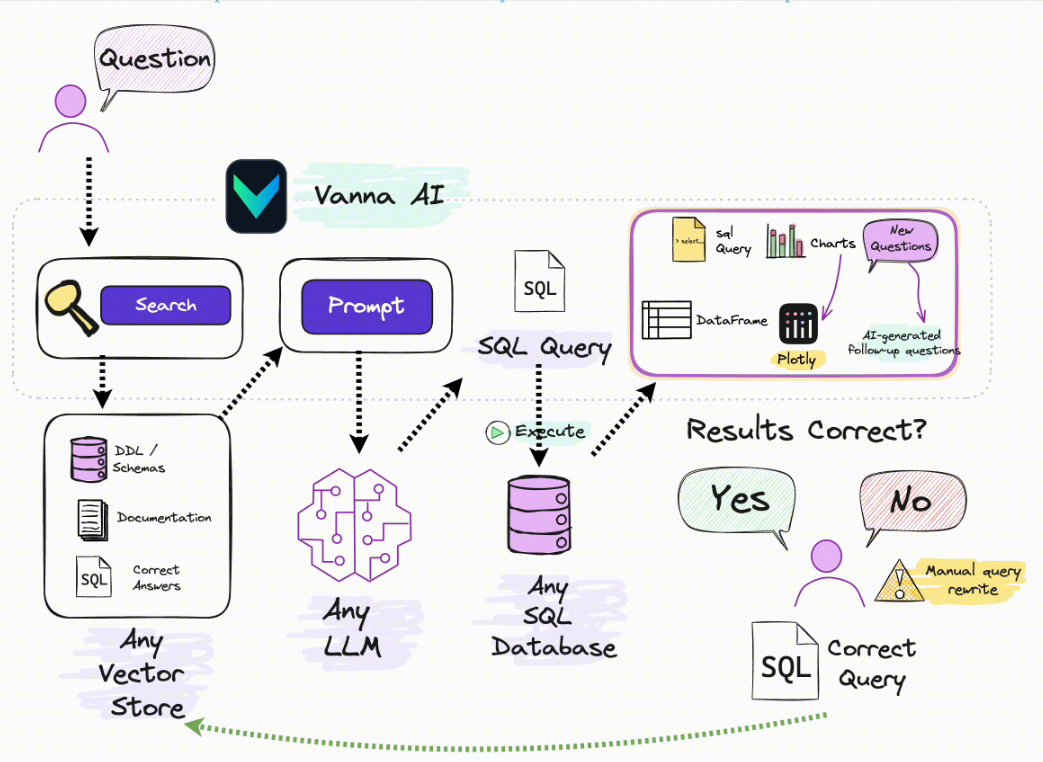
Vanna 的核心是 “RAG 检索增强 + LLM 生成”,整个工作流程可拆解为 7 个关键步骤,确保生成的 SQL 准确匹配用户需求:
- 用户提问:用户输入自然语言问题(如 “每位顾客在各流派上花费了多少?”);
- 搜索相关信息:系统从向量数据库中检索与问题相关的核心数据,包括 3 类关键信息:
- DDL 语句(数据库表结构定义,如字段名、数据类型、关联关系);
- 业务文档(如 “高价值客户定义为订单总额超 10000 元”);
- 历史正确 SQL(用户过往的有效查询案例);
- 生成提示(Prompt):根据检索到的信息,构造包含 “表结构 + 业务规则 + 历史案例” 的提示,引导 LLM 理解问题上下文;
- LLM 生成 SQL:大语言模型(如 Deepseek)基于提示,将自然语言转化为语法正确的 SQL 语句;
- 执行 SQL 查询:系统连接目标数据库,自动执行生成的 SQL;
- 结果可视化:通过 Pandas DataFrame 展示表格结果,或用 Plotly 生成图表(如柱状图、折线图),同时提供后续问题建议;
- 校验与反馈:若结果正确,直接返回;若错误,支持用户手动修改 SQL,修改后的案例会被重新存入向量数据库,用于后续模型优化。
1.3 Vanna 核心组件:三大模块支撑全流程
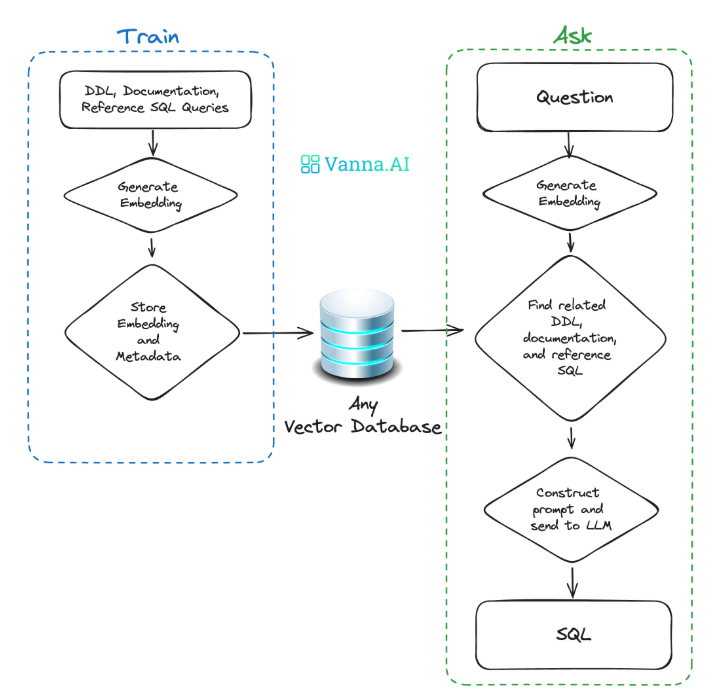
Vanna 的架构以VannaBase为基础,衍生出两大核心组件,分工明确且可灵活扩展:
| 组件类型 | 核心作用 | 示例类 |
|---|---|---|
VannaBase | 定义公共方法与接口(如日志记录、SQL 生成、嵌入提取),是所有组件的父类 | class VannaBase(ABC) |
| 大语言模型访问组件 | 连接 LLM,处理提示生成与 SQL 输出,继承自VannaBase | OpenAI_Chat(连接 OpenAI 模型)、Deepseek_Chat(连接 Deepseek 模型) |
| 向量数据库访问组件 | 存储 DDL、文档、历史 SQL 的嵌入向量,支持高效检索,继承自VannaBase | Milvus_VectorStore(连接 Milvus)、ChromaDB_VectorStore(连接 ChromaDB) |
实战中,我们只需新建类继承 “LLM 组件 + 向量数据库组件”,即可快速搭建专属的 Text2SQL 系统。
二、实战准备:环境搭建与数据库连接
在训练模型前,需完成环境安装、数据库配置两大准备工作,本文以 “Milvus 向量数据库 + Deepseek 模型 + MySQL 数据库” 为例演示(其他组合流程类似)。
2.1 安装核心依赖模块
通过pip命令安装 Vanna 框架、向量生成工具、Milvus 客户端,执行以下命令:
# 安装Vanna框架核心库
pip install vanna
# 安装句子嵌入模型(用于生成文本向量)
pip install sentence-transformers
# 安装Milvus客户端(含模型支持)
pip install pymilvus[model]
# 若使用MySQL,需额外安装MySQL连接器
pip install pymysql
2.2 连接目标数据库
Vanna 支持多种数据库连接,只需调用对应的connect_to_xxx方法即可。以下是两种常用数据库的连接示例:
示例 1:连接 SQLite(本地文件数据库,无需服务)
SQLite 无需提前启动服务,只需指定数据库文件路径:
# 初始化Vanna实例后,连接SQLite
vn.connect_to_sqlite("./chinook.sqlite") # chinook.sqlite为本地数据库文件
示例 2:连接 MySQL(需提前启动 MySQL 服务)
需提供数据库地址、端口、用户名、密码和数据库名:
# 连接MySQL数据库(以student_db数据库为例)
vn.connect_to_mysql(host="127.0.0.1", # 本地数据库地址port=3306, # MySQL默认端口user="root", # 用户名password="123456", # 密码dbname="student_db" # 目标数据库名
)
三、模型训练:三大维度提升 SQL 生成准确性
训练是 Vanna 的核心环节 —— 通过输入 DDL、业务文档、示例 SQL,让模型理解数据库结构与业务规则,从而生成更精准的 SQL。训练需覆盖 “表结构”“业务上下文”“查询案例” 三个维度,缺一不可。
3.1 维度 1:用 DDL 语句训练(让模型懂表结构)
DDL(数据定义语言)是数据库的 “骨架”,包含表名、字段名、数据类型、主键 / 外键关联等关键信息,是模型生成 SQL 的基础。
训练逻辑:
通过vn.train(ddl="DDL语句")将表结构存入向量数据库,支持单表或多表一次性导入。
实战示例(学生成绩数据库):
假设student_db数据库包含student(学生信息表)和score(成绩表),DDL 训练代码如下:
def train_ddl():# 定义两张表的DDL语句,包含字段注释(增强模型理解)ddl = """-- 学生基本信息表CREATE TABLE student (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '学生唯一ID,自增主键',stu_name VARCHAR(30) NOT NULL COMMENT '学生姓名,不能为空',major VARCHAR(10) NOT NULL COMMENT '学生专业(如计算机、数学)',enrollment_year DATE NOT NULL COMMENT '入学年份(如2023-09-01)',age INT NOT NULL COMMENT '学生年龄') COMMENT = '存储学生基础信息';-- 学生成绩表(与student表通过student_id关联)CREATE TABLE score (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '成绩记录ID,自增主键',student_id INT NOT NULL COMMENT '关联student表的id字段',subject VARCHAR(50) NOT NULL COMMENT '科目名称(如高等数学、Python)',score DECIMAL(5,2) NOT NULL COMMENT '成绩(精确到小数点后2位)',exam_date DATE NOT NULL COMMENT '考试日期',semester VARCHAR(20) NOT NULL COMMENT '学期(如2023-2024-1)',-- 外键关联:删除/更新student表数据时,同步影响score表FOREIGN KEY (student_id) REFERENCES student(id) ON DELETE CASCADE ON UPDATE CASCADE) COMMENT = '存储学生各科成绩信息';"""# 执行DDL训练vn.train(ddl=ddl)# 调用函数完成训练
train_ddl()
关键注意点:
- 务必添加
COMMENT注释(如字段含义、表用途),模型会通过注释理解业务语义; - 若数据库表已存在,可通过查询获取 DDL(如 MySQL 用
SHOW CREATE TABLE student;),无需手动编写。
3.2 维度 2:用业务文档训练(让模型懂业务规则)
业务文档是 “隐性知识” 的载体,比如 “高价值客户定义”“核心指标计算逻辑” 等,仅靠表结构无法覆盖。通过vn.train(documentation="文档内容"),可将这些规则传入模型,避免生成不符合业务逻辑的 SQL。
实战示例:
针对学生成绩数据库,添加以下业务文档训练:
def train_documentation():# 业务规则1:定义“优秀成绩”vn.train(documentation="优秀成绩指单科分数≥90分,良好成绩指80分≤分数<90分")# 业务规则2:定义“应届毕业生”vn.train(documentation="应届毕业生指enrollment_year(入学年份)为2021年且当前年份为2025年的学生")# 业务规则3:成绩排名逻辑vn.train(documentation="总成绩排名按学生所有科目分数之和降序排列,分数相同则按入学年份升序排列")# 调用函数完成训练
train_documentation()
关键注意点:
- 文档内容需简洁明确,避免歧义(如 “高价值客户” 需明确金额阈值);
- 后续业务规则更新时,只需重新执行
train(documentation)即可覆盖旧规则。
3.3 维度 3:用 SQL 示例训练(让模型懂查询逻辑)
SQL 示例是 “显性案例”,通过 “自然语言问题 + 正确 SQL” 的配对训练,让模型学习不同场景下的查询逻辑(如分组统计、关联查询、排序筛选),尤其适合复杂 SQL 生成(如多表关联、子查询)。
训练逻辑:
通过vn.train(sql="SQL语句", question="对应的自然语言问题")实现 “问题 - SQL” 配对训练,若省略question,模型会自动解析 SQL 含义。
实战示例:
针对学生成绩数据库,添加 3 个典型 SQL 示例训练:
def train_sql_examples():# 示例1:查询计算机专业的学生信息vn.train(question="查询计算机专业所有学生的姓名、专业和入学年份",sql="SELECT stu_name, major, enrollment_year FROM student WHERE major = '计算机'")# 示例2:统计各专业的平均成绩vn.train(question="统计每个专业的学生平均成绩(保留2位小数)",sql="""SELECT s.major, ROUND(AVG(sc.score), 2) AS avg_scoreFROM student sJOIN score sc ON s.id = sc.student_idGROUP BY s.majorORDER BY avg_score DESC""")# 示例3:查询某学期高等数学成绩≥90分的学生vn.train(question="查询2023-2024-1学期高等数学成绩≥90分的学生姓名和分数",sql="""SELECT s.stu_name, sc.scoreFROM student sJOIN score sc ON s.id = sc.student_idWHERE sc.subject = '高等数学' AND sc.semester = '2023-2024-1' AND sc.score ≥ 90""")# 调用函数完成训练
train_sql_examples()
关键注意点:
- 示例需覆盖核心业务场景(如统计、筛选、关联),示例越多,模型准确性越高;
- SQL 需确保语法正确(可先在数据库中执行验证),避免错误案例影响模型判断。
四、运行的源码和演示
两段两段代码均基于 vanna 框架,整合 OpenAI(对接 deepseek 模型)与 Milvus 向量数据库,实现 “自然语言提问→数据库查询→智能回答” 流程。
核心逻辑:通过训练数据库表结构(DDL)让模型理解数据结构,将用户问题转为 SQL 查询并返回自然语言答案。
案例一:
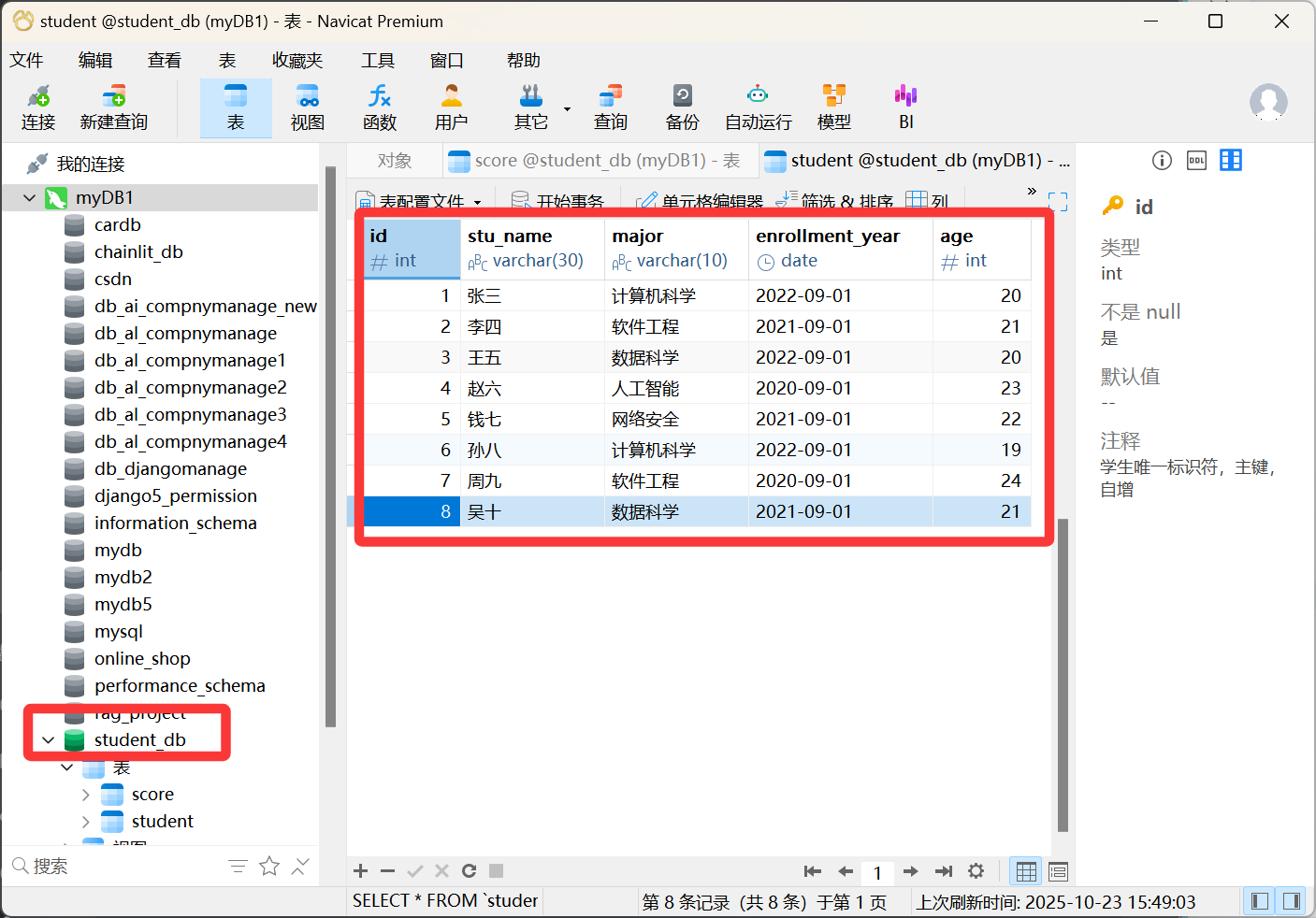
连接 MySQL 的 student_db,训练学生表和成绩表结构,提问学生信息。
初始数据:
# 导⼊OpenAI类,⽤于与OpenAI API进⾏交互,⽀持⽂本⽣成、图像⽣成等功能
from openai import OpenAI
# 导⼊model模块,通常⽤于指定与数据库相关的模型操作,此处可能是示意,实际代码中应具体化
# 导⼊MilvusClient类,⽤于与Milvus数据库进⾏交互
from pymilvus import MilvusClient, model
# # 导⼊OpenAI_Chat类,⽤于与OpenAI的ChatGPT API进⾏交互
from vanna.openai.openai_chat import OpenAI_Chat
# 导⼊Milvus_VectorStore类,⽤于在Milvus数据库中存储和管理向量数据
from vanna.milvus.milvus_vector import Milvus_VectorStore# 定义获取嵌入向量的函数
def pymilvus_embedding_function():"""创建一个SentenceTransformerEmbeddingFunction实例。使用指定的模型名称和设备来创建实例,用于生成文本嵌入向量。"""sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction(model_name='BAAI/bge-small-zh-v1.5', # 指定模型名称device='cpu' # 指定设备,例如 'cpu' 或 'cuda:0')return sentence_transformer_ef# 创建Milvus类,继承自Milvus_VectorStore和OpenAI_Chat
class Milvus(Milvus_VectorStore, OpenAI_Chat):def __init__(self):# 创建MilvusClient实例,连接到本地Milvus数据库milvus_client = MilvusClient(uri="http://127.0.0.1:19530")# 初始化配置字典,包含嵌入函数、Milvus客户端、模型参数等config = {"embedding_function": pymilvus_embedding_function(),"milvus_client": milvus_client,"model": "deepseek-chat","temperature": 0.7,# "dialect": "SQLLite","dialect": "mysql"}# 创建OpenAI客户端实例,使用指定的API密钥和基础URLllm_config = OpenAI(api_key="sk-b598eef38ae9446ba078a0899f74f64f",base_url="https://api.deepseek.com/v1")# 初始化Milvus_VectorStore:创建Milvus_VectorStore实例,并传入配置字典Milvus_VectorStore.__init__(self, config=config)# 初始化OpenAI_Chat实例:创建OpenAI_Chat实例,并传入配置字典和OpenAI客户端实例OpenAI_Chat.__init__(self, client=llm_config, config=config)vn = Milvus()
vn.connect_to_mysql(host="127.0.0.1",port=3306,user="root",password="123456",dbname="student_db"
)
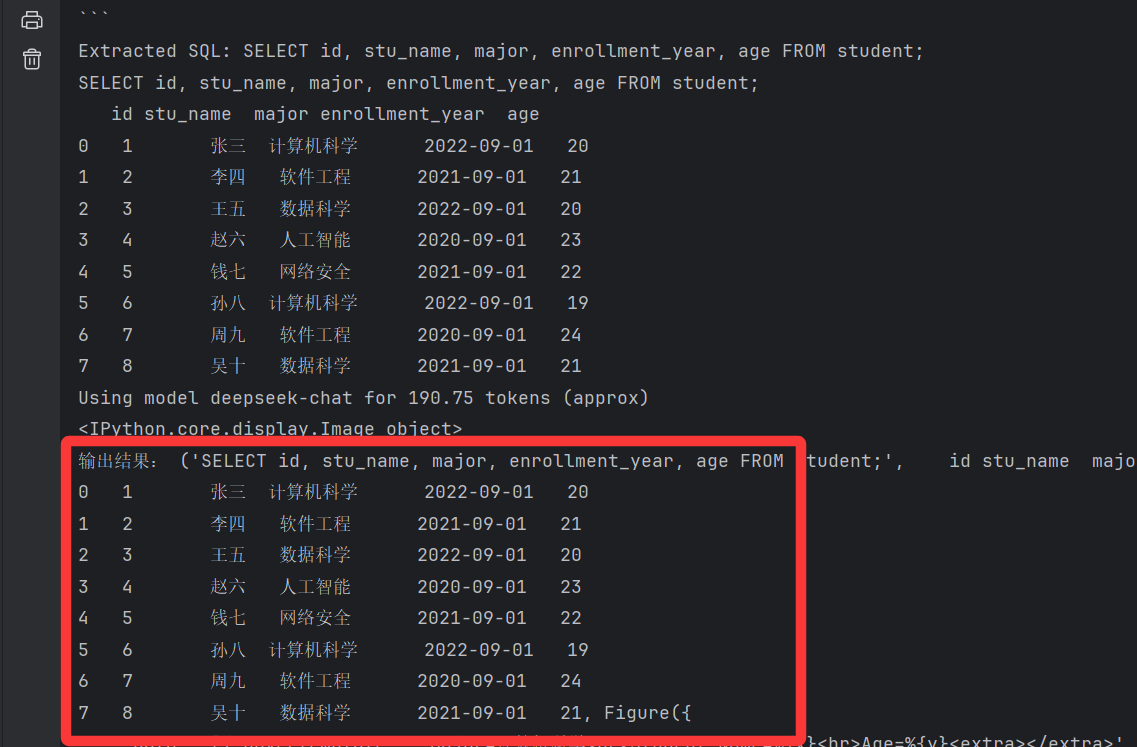
def train2():vn.train(ddl="""-- 学生信息表CREATE TABLE student (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '学生唯一标识符,主键,自增',stu_name VARCHAR ( 30 ) NOT NULL COMMENT '学生姓名,最大长度30个字符,不能为空',major VARCHAR ( 10 ) NOT NULL COMMENT '学生专业,最大长度10个字符,不能为空',enrollment_year DATE NOT NULL COMMENT '入学年份,日期类型,不能为空',age INT NOT NULL COMMENT '学生年龄,整数类型,不能为空') COMMENT = '学生基本信息表,用于存储学生相关数据';-- 学生成绩表CREATE TABLE score (id INT AUTO_INCREMENT PRIMARY KEY COMMENT '成绩记录唯一标识符,主键,自增',student_id INT NOT NULL COMMENT '学生ID,外键关联student表',SUBJECT VARCHAR ( 50 ) NOT NULL COMMENT '科目名称,最大长度50个字符,不能为空',score DECIMAL ( 5, 2 ) NOT NULL COMMENT '成绩分数,数值类型,精确到小数点后两位,不能为空',exam_date DATE NOT NULL COMMENT '考试日期,日期类型,不能为空',semester VARCHAR ( 20 ) NOT NULL COMMENT '学期,如2023-2024-1,最大长度20个字符,不能为空',FOREIGN KEY ( student_id ) REFERENCES student ( id ) ON DELETE CASCADE ON UPDATE CASCADE) COMMENT = '学生成绩表,用于存储学生各科成绩信息';""")train2()obj = vn.ask("请告诉我所有学生信息:")
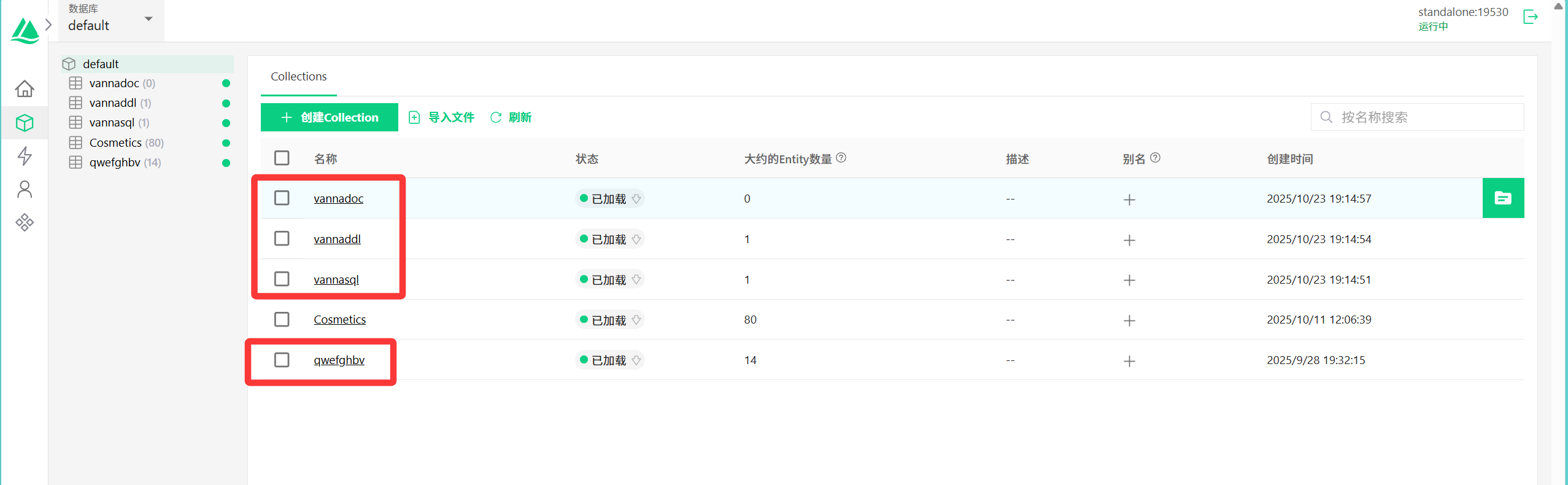
print("输出结果:",obj)运行结束后会创建对应的向量数据库,储存刚刚训练的信息:
以下是查询结果,通过vanna已经成功根据训练数据查询到数据库内容:
后续可以将返回的结果交给大模型,大模型根据这个结果输出指定数据。
案例二:
SQLite 连接(connect_to_sqlite),实际未连接具体业务数据库,训练数据来自 SQLite 系统表(sqlite_master)的表结构。
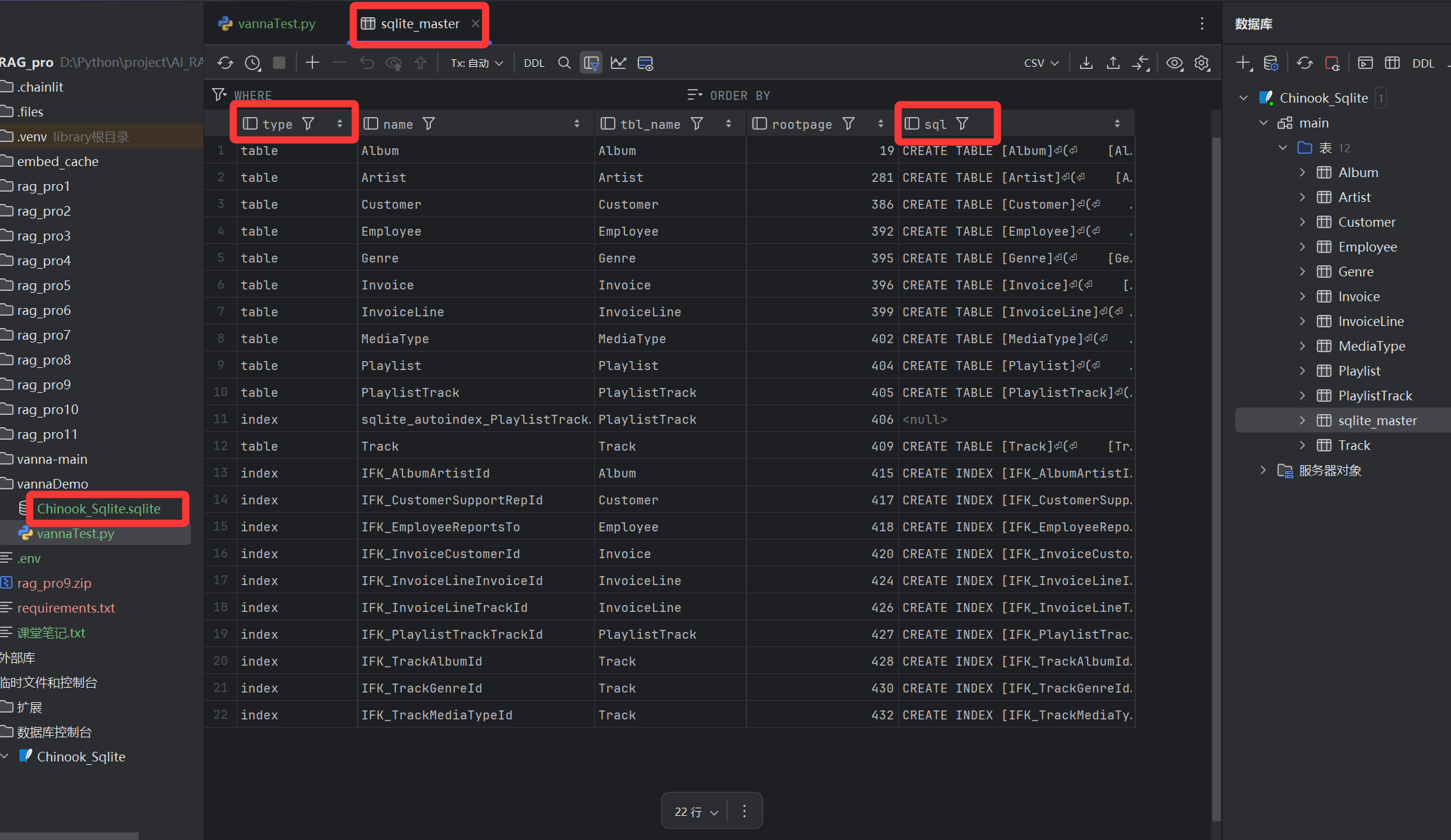
示例代码:
# 导入必要的库
from openai import OpenAI
from pymilvus import MilvusClient, model
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.milvus.milvus_vector import Milvus_VectorStore
import sqlite3
import pandas as pd
import time# 定义嵌入函数
def pymilvus_embedding_function():sentence_transformer_ef = model.dense.SentenceTransformerEmbeddingFunction(model_name='BAAI/bge-small-zh-v1.5',device='cpu')return sentence_transformer_ef# 创建 Milvus 类
class Milvus(Milvus_VectorStore, OpenAI_Chat):def __init__(self):milvus_client = MilvusClient(uri="http://127.0.0.1:19530")config = {"embedding_function": pymilvus_embedding_function(),"milvus_client": milvus_client,"model": "qwen-plus","temperature": 0.7,"dialect": "SQLite",}llm_config = OpenAI(api_key="sk-7077b6f235fc44efb80be8f244bea3d5",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")Milvus_VectorStore.__init__(self, config=config)OpenAI_Chat.__init__(self, client=llm_config, config=config)vn = Milvus()# 创建数据库
def create_school_database(db_name="schools.db"):conn = sqlite3.connect(db_name)cursor = conn.cursor()cursor.execute("""CREATE TABLE IF NOT EXISTS student (id INTEGER PRIMARY KEY AUTOINCREMENT,name TEXT NOT NULL,age INTEGER NOT NULL,major TEXT NOT NULL,enrollment_year INTEGER NOT NULL)""")cursor.execute("""CREATE TABLE IF NOT EXISTS teacher (id INTEGER PRIMARY KEY AUTOINCREMENT,name TEXT NOT NULL,department TEXT NOT NULL,hire_date DATE NOT NULL,email TEXT UNIQUE)""")cursor.execute("""CREATE TABLE IF NOT EXISTS course (id INTEGER PRIMARY KEY AUTOINCREMENT,course_code TEXT UNIQUE NOT NULL,course_name TEXT NOT NULL,credits INTEGER NOT NULL,teacher_id INTEGER,FOREIGN KEY (teacher_id) REFERENCES teacher (id))""")cursor.execute("""CREATE TABLE IF NOT EXISTS enrollment (id INTEGER PRIMARY KEY AUTOINCREMENT,student_id INTEGER NOT NULL,course_id INTEGER NOT NULL,enrollment_date DATE NOT NULL,grade REAL,FOREIGN KEY (student_id) REFERENCES student (id),FOREIGN KEY (course_id) REFERENCES course (id),UNIQUE (student_id, course_id))""")conn.commit()return conn# 插入测试数据(带清空)
def insert_test_data(conn):cursor = conn.cursor()# 清空所有表cursor.execute("DELETE FROM enrollment")cursor.execute("DELETE FROM course")cursor.execute("DELETE FROM student")cursor.execute("DELETE FROM teacher")cursor.execute("DELETE FROM sqlite_sequence WHERE name IN ('student', 'teacher', 'course', 'enrollment')")# 插入数据students_data = [("张三", 20, "计算机科学", 2022),("李四", 19, "数学", 2023),("王五", 21, "物理", 2021),("赵六", 20, "化学", 2022),("钱七", 22, "生物", 2020)]cursor.executemany("INSERT INTO student (name, age, major, enrollment_year) VALUES (?, ?, ?, ?)", students_data)teachers_data = [("陈教授", "计算机科学", "2015-09-01", "chen@university.edu"),("刘副教授", "数学", "2018-03-15", "liu@university.edu"),("杨博士", "物理", "2020-07-01", "yang@university.edu"),("周讲师", "化学", "2019-11-20", "zhou@university.edu")]cursor.executemany("INSERT INTO teacher (name, department, hire_date, email) VALUES (?, ?, ?, ?)", teachers_data)courses_data = [("CS101", "编程基础", 3, 1),("MATH201", "高等数学", 4, 2),("PHY301", "量子力学", 3, 3),("CHEM101", "有机化学", 3, 4),("CS201", "数据结构", 3, 1)]cursor.executemany("INSERT INTO course (course_code, course_name, credits, teacher_id) VALUES (?, ?, ?, ?)", courses_data)enrollments_data = [(1, 1, "2023-09-01", 85.5),(1, 5, "2023-09-01", 90.0),(2, 2, "2023-09-01", 78.0),(3, 3, "2023-09-01", 92.5),(4, 4, "2023-09-01", 88.0),(5, 2, "2023-09-01", 95.0),(2, 1, "2024-03-01", None),(3, 4, "2024-03-01", None)]cursor.executemany("INSERT INTO enrollment (student_id, course_id, enrollment_date, grade) VALUES (?, ?, ?, ?)", enrollments_data)conn.commit()print("测试数据插入成功!")# 创建并填充数据库
conn = create_school_database("schools.db")
insert_test_data(conn)# 连接 Vanna
vn.connect_to_sqlite("./schools.db")# 完整训练
def full_train():client = MilvusClient(uri="http://127.0.0.1:19530")collection_name = "vanna_collection"if client.has_collection(collection_name):client.drop_collection(collection_name)print("已清理 Milvus 向量集合")# 训练 DDLsql = "SELECT sql FROM sqlite_master WHERE type='table' AND name NOT LIKE 'sqlite_%'"tables = vn.run_sql(sql)for ddl in tables["sql"].tolist():vn.train(ddl=ddl)vn.train(ddl="CREATE TABLE student (id INTEGER PRIMARY KEY, name TEXT NOT NULL COMMENT '学生姓名', age INTEGER NOT NULL COMMENT '学生年龄') COMMENT '学生表'")# 训练真实问法vn.train(question="张三的年龄是多少?", sql="SELECT age FROM student WHERE name = '张三'")vn.train(question="学生有哪些名字?", sql="SELECT name FROM student")print("Vanna 训练完成!")full_train()
time.sleep(2)# 测试
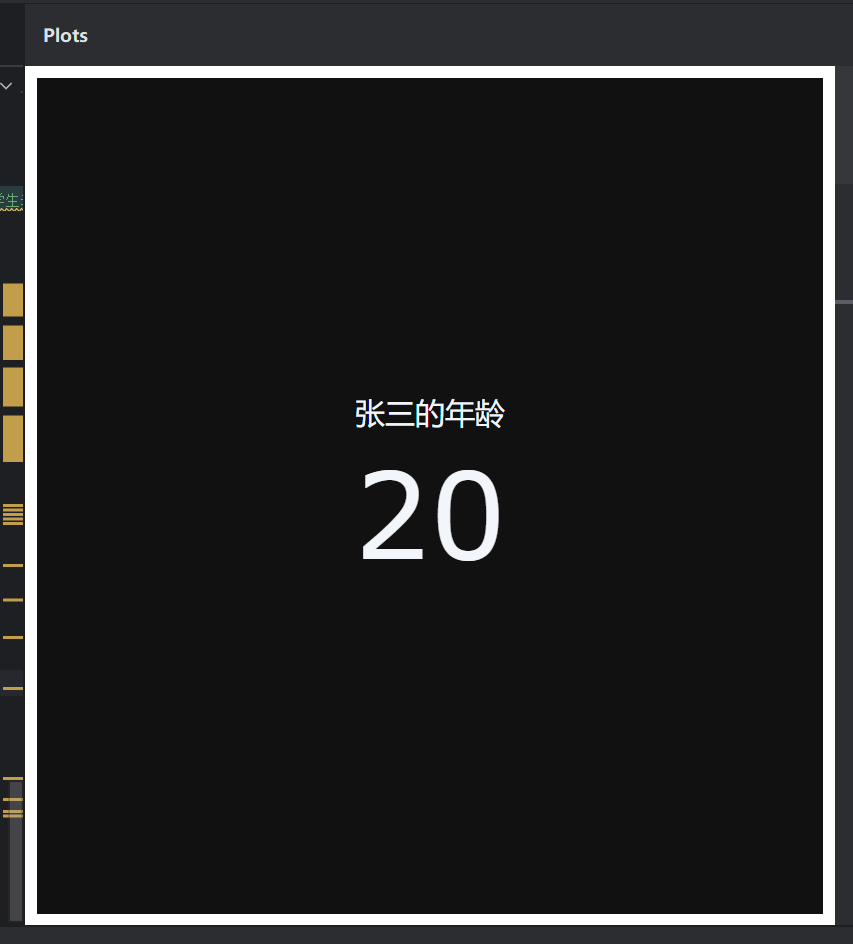
try:sql, df, fig = vn.ask("张三今年几岁?")if sql and df is not None:print("LLM 生成的 SQL:", sql)print("张三的年龄是:", df.iloc[0, 0])# 展示图表fig.show()else:print("LLM 未生成 SQL")
except Exception as e:print("ask 失败:", e)conn.close()运行结果:
生成的图表:
六、总结与进阶建议
通过本文的讲解,你已掌握 Vanna 框架的核心原理、训练流程与实战方法。总结来说,Vanna 的核心价值在于 “用 RAG 链接业务知识与 LLM 能力”,而训练的关键在于 “全面覆盖表结构、业务规则、查询案例”—— 三者结合,才能让模型生成准确、符合业务需求的 SQL。
进阶优化建议:
- 扩充训练数据:定期将新的正确 SQL 案例加入训练,尤其覆盖复杂场景(如窗口函数、子查询);
- 选择更优模型:若中文场景准确性不足,可替换为 “通义千问”“文心一言” 等中文 LLM;
- 优化向量模型:若检索效率低,可更换更大的嵌入模型(如
BAAI/bge-large-zh); - 搭建前端界面:结合 Streamlit 或 Gradio,开发可视化前端,让非技术人员直接在浏览器中提问。
无论是日常数据查询、业务报表生成,还是数据驱动决策,Vanna 都能大幅提升效率。动手试试吧,让你的数据库真正 “开口说话”!