建筑网站知名度法与家国建设征文网站
文章目录
- scikit-learn 开源框架介绍
- 1. 框架概述
- 1.1 基本介绍
- 1.2 版本信息
- 2. 核心功能模块
- 2.1 监督学习
- 2.2 无监督学习
- 2.3 数据处理
- 3. 关键设计理念
- 3.1 统一API设计
- 3.2 流水线(Pipeline)
- 4. 重要辅助功能
- 4.1 模型选择
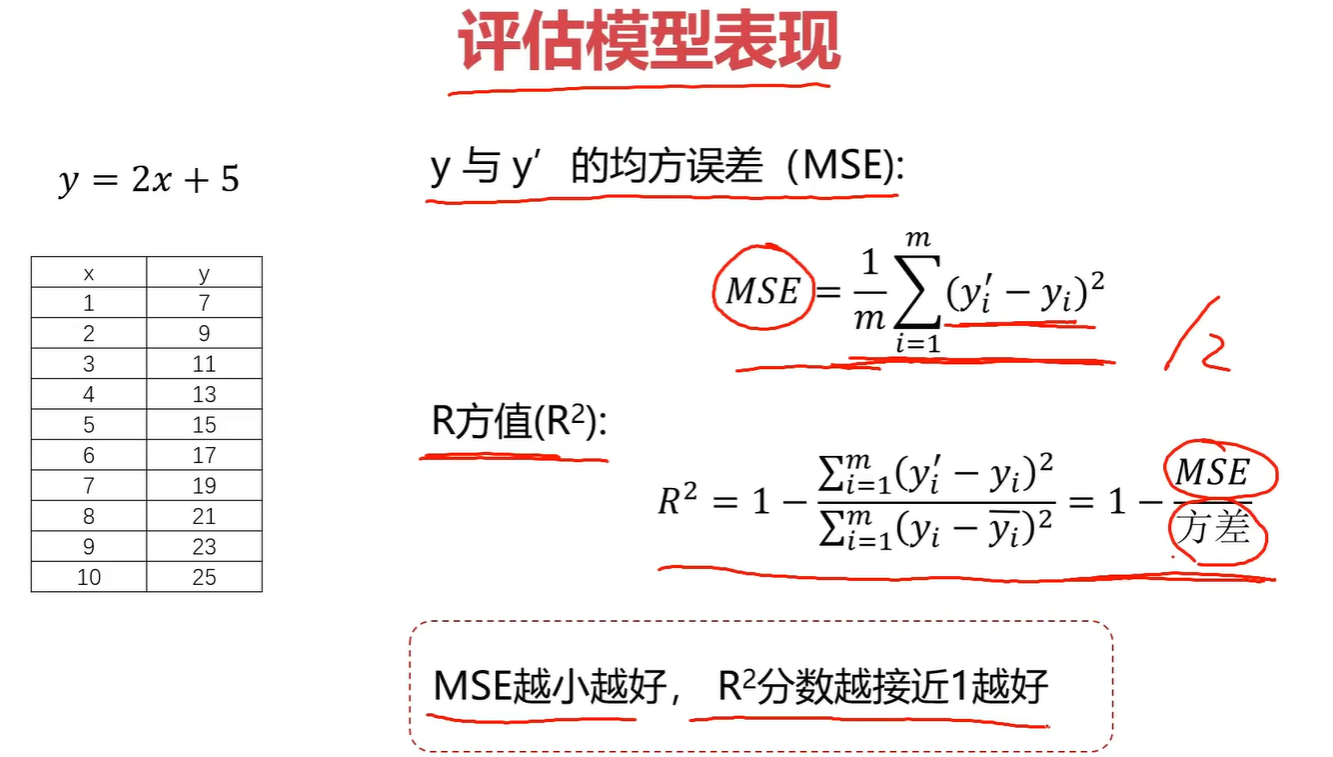
- 4.2 评估指标
- 5. 性能优化技巧
- 5.1 并行计算
- 5.2 内存优化
- 6. 行业应用案例
- 6.1 金融风控
- 6.2 医疗诊断
- 7. 学习资源推荐
- 实验
- 准备
- 1.线性回归实验结果:
- 2.逻辑回归训练结果
- 逻辑回归的代码示例如下:
scikit-learn 开源框架介绍
用于自己复习,好记性不如懒笔头
1. 框架概述
1.1 基本介绍
scikit-learn (简称sklearn) 是Python最流行的机器学习开源库,具有以下核心特点:
- 基于NumPy/SciPy构建的算法实现
- 统一的API设计(fit/predict/transform)
- 完善的文档和社区支持
- BSD开源协议(可商用)
1.2 版本信息
import sklearn
print("当前版本:", sklearn.__version__) # 要求≥1.0版本
2. 核心功能模块
2.1 监督学习
| 算法类别 | 典型算法 | 导入方式 |
|---|---|---|
| 线性模型 | LinearRegression, LogisticRegression | from sklearn.linear_model import ... |
| 树模型 | DecisionTree, RandomForest | from sklearn.ensemble import ... |
| SVM | SVC, SVR | from sklearn.svm import ... |
线性回归的调用方法:


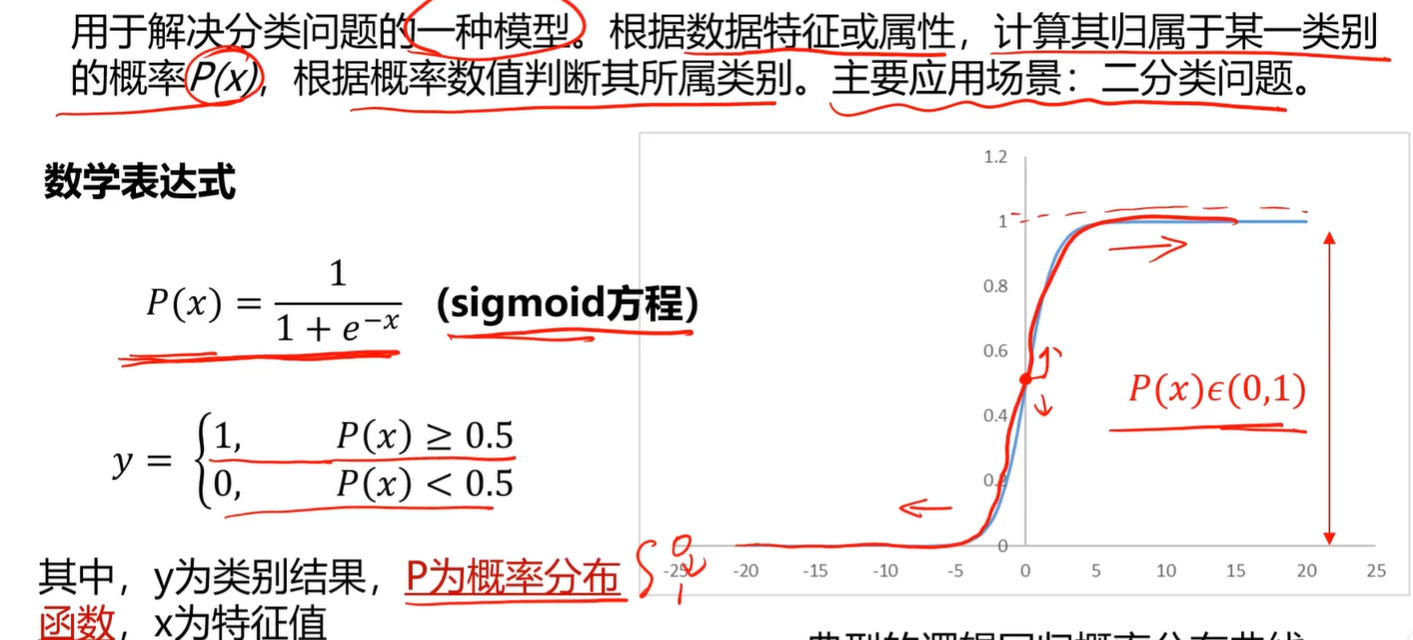
逻辑回归的说明:
2.2 无监督学习
from sklearn.cluster import KMeans # 聚类
from sklearn.decomposition import PCA # 降维
2.3 数据处理
| 功能 | 类/函数 | 示例 |
|---|---|---|
| 标准化 | StandardScaler | scaler.fit_transform(X) |
| 特征编码 | OneHotEncoder | encoder.fit_transform(cat_features) |
| 缺失值处理 | SimpleImputer | imputer.fit_transform(X_missing) |
3. 关键设计理念
3.1 统一API设计
所有算法类都实现以下核心方法:
model.fit(X_train, y_train) # 训练
model.predict(X_test) # 预测
model.score(X_test, y_test) # 评估
3.2 流水线(Pipeline)
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(StandardScaler(),PCA(n_components=2),LogisticRegression()
)
pipe.fit(X_train, y_train)
4. 重要辅助功能
4.1 模型选择
from sklearn.model_selection import (train_test_split,GridSearchCV,cross_val_score
)
4.2 评估指标
from sklearn.metrics import (accuracy_score, # 分类准确率mean_squared_error, # 回归MSEconfusion_matrix # 混淆矩阵
)
5. 性能优化技巧
5.1 并行计算
RandomForestClassifier(n_jobs=-1) # 使用所有CPU核心
5.2 内存优化
PCA(svd_solver='randomized') # 大数据集降维
6. 行业应用案例
6.1 金融风控
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier() # 用于信用评分
6.2 医疗诊断
from sklearn.svm import SVC
clf = SVC(kernel='rbf', probability=True) # 疾病预测
7. 学习资源推荐
- 官方文档:scikit-learn.org
- 代码示例库:
sklearn.datasets.load_* - 交互式学习:scikit-learn教程
实验
准备
本人随机生成了两组数据,余额50元以上的,结果是购买电影票;50元以下的,结果是不够买电影票。
我将用线性回归和逻辑回归根据账号余额预测是否会购买电影票进行模型训练
1.线性回归实验结果:
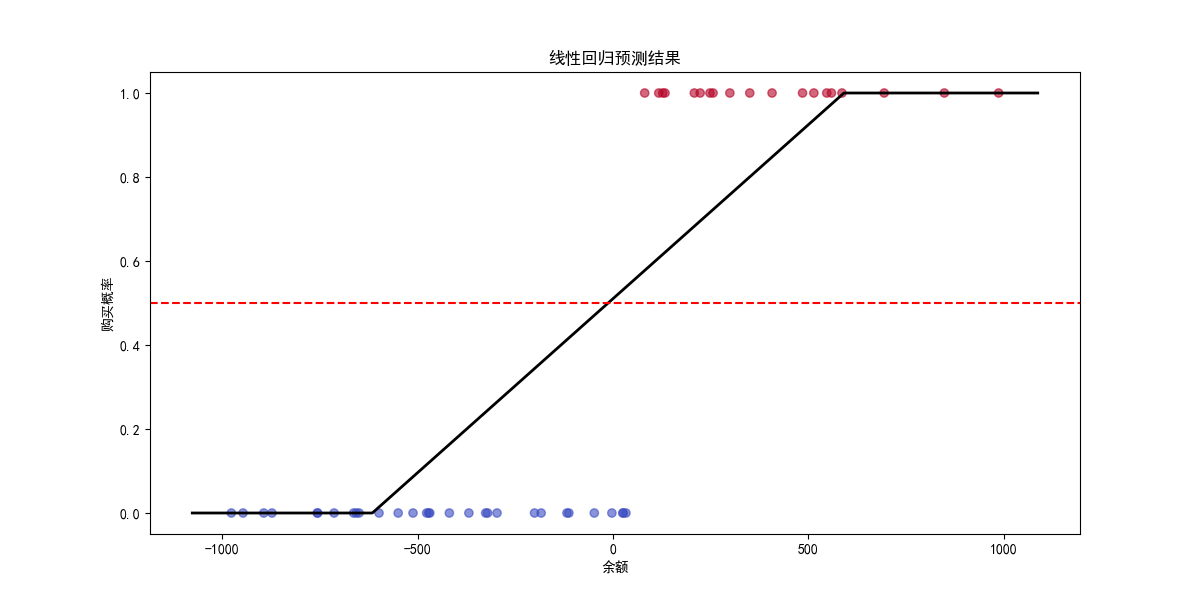
标准化后的线性回归方程
y ^ = 0.4155 + 0.4152 × x 标准化 \hat{y} = 0.4155 + 0.4152 \times x_{标准化} y^=0.4155+0.4152×x标准化
其中:
y ^ \hat{y} y^ 是预测的购买概率
x 标准化 x_{标准化} x标准化 是标准化后的余额值
0.4155 是截距
0.4152 是标准化余额的系数
原始数据的线性回归方程
由于我们使用了StandardScaler进行标准化,原始数据的方程可以表示为:
y ^ = 0.4155 + 0.4152 × ( x − μ σ ) \hat{y} = 0.4155 + 0.4152 \times \left(\frac{x - \mu}{\sigma}\right) y^=0.4155+0.4152×(σx−μ)
其中:
x x x 是原始余额值
μ = − 114.57 \mu = -114.57 μ=−114.57 是原始数据的均值
σ = 506.39 \sigma = 506.39 σ=506.39 是原始数据的标准差
预测阈值
当 y ^ = 0.5 \hat{y} = 0.5 y^=0.5 时,对应的余额阈值为:
x = 0.5 − 0.4155 0.4152 × σ + μ = − 12.54 元 x = \frac{0.5 - 0.4155}{0.4152} \times \sigma + \mu = -12.54 \text{元} x=0.41520.5−0.4155×σ+μ=−12.54元
这意味着:
当余额 > -12.54元时,预测购买概率 > 0.5
当余额 < -12.54元时,预测购买概率 < 0.5
2.逻辑回归训练结果
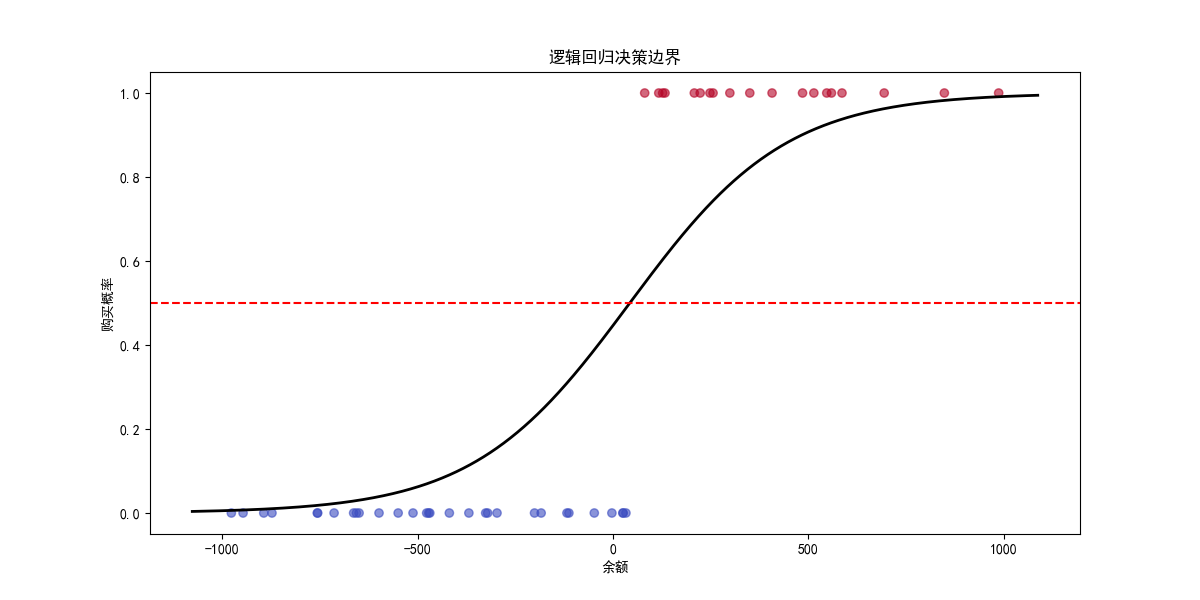
标准化后的逻辑回归方程
P ( y = 1 ∣ x ) = 1 1 + e − ( − 0.7862 + 2.5021 × x 标准化 ) P(y=1|x) = \frac{1}{1 + e^{-(-0.7862 + 2.5021 \times x_{标准化})}} P(y=1∣x)=1+e−(−0.7862+2.5021×x标准化)1
其中:
P ( y = 1 ∣ x ) P(y=1|x) P(y=1∣x) 是购买电影票的概率
x 标准化 x_{标准化} x标准化 是标准化后的余额值
-0.7862 是截距
2.5021 是标准化余额的系数
原始数据的逻辑回归方程
由于我们使用了StandardScaler进行标准化,原始数据的方程可以表示为:
P ( y = 1 ∣ x ) = 1 1 + e − ( − 0.7862 + 2.5021 × x − μ σ ) P(y=1|x) = \frac{1}{1 + e^{-(-0.7862 + 2.5021 \times \frac{x - \mu}{\sigma})}} P(y=1∣x)=1+e−(−0.7862+2.5021×σx−μ)1
其中:
x x x 是原始余额值
μ = − 114.57 \mu = -114.57 μ=−114.57 是原始数据的均值
σ = 506.39 \sigma = 506.39 σ=506.39 是原始数据的标准差
预测阈值
当 P ( y = 1 ∣ x ) = 0.5 P(y=1|x) = 0.5 P(y=1∣x)=0.5 时,对应的余额阈值为:
x = 0.5 − ( − 0.7862 ) 2.5021 × σ + μ = 44.54 元 x = \frac{0.5 - (-0.7862)}{2.5021} \times \sigma + \mu = 44.54 \text{元} x=2.50210.5−(−0.7862)×σ+μ=44.54元
这意味着:
当余额 > 44.54元时,预测购买概率 > 0.5
当余额 < 44.54元时,预测购买概率 < 0.5
比较两个结果,显然分类问题,用逻辑回归模型的准确度会更大些
逻辑回归的代码示例如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report, roc_curve, auc
from sklearn.preprocessing import StandardScaler# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsedef load_and_preprocess_data():"""加载并预处理数据"""# 读取数据df = pd.read_excel('balance.xlsx')# 将"是"/"否"转换为1/0df['是否买电影票'] = df['是否买电影票'].map({'是': 1, '否': 0})# 数据标准化scaler = StandardScaler()df['小明的余额_标准化'] = scaler.fit_transform(df[['小明的余额']])return df, scalerdef visualize_data(df):"""数据可视化"""# 1. 余额分布图plt.figure(figsize=(12, 6))sns.histplot(data=df, x='小明的余额', hue='是否买电影票', bins=20)plt.title('余额分布与购买行为')plt.xlabel('余额')plt.ylabel('频次')plt.savefig('余额分布图.png')plt.close()# 2. 箱线图plt.figure(figsize=(12, 6))sns.boxplot(x='是否买电影票', y='小明的余额', data=df)plt.title('不同购买决策下的余额分布')plt.savefig('余额箱线图.png')plt.close()# 3. 散点图plt.figure(figsize=(12, 6))sns.scatterplot(x='小明的余额', y='是否买电影票', data=df)plt.title('余额与购买行为的关系')plt.savefig('余额散点图.png')plt.close()def train_and_evaluate_model(df):"""训练和评估模型"""# 准备数据X = df[['小明的余额_标准化']]y = df['是否买电影票']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型model = LogisticRegression()model.fit(X_train, y_train)# 预测y_pred = model.predict(X_test)y_pred_proba = model.predict_proba(X_test)[:, 1]# 评估模型accuracy = accuracy_score(y_test, y_pred)report = classification_report(y_test, y_pred)# 计算ROC曲线fpr, tpr, _ = roc_curve(y_test, y_pred_proba)roc_auc = auc(fpr, tpr)# 绘制ROC曲线plt.figure(figsize=(10, 6))plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.2f})')plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('假正例率')plt.ylabel('真正例率')plt.title('ROC曲线')plt.legend(loc="lower right")plt.savefig('ROC曲线.png')plt.close()return model, accuracy, report, roc_aucdef plot_decision_boundary(df, model, scaler):"""绘制决策边界"""# 生成测试数据x_min, x_max = df['小明的余额'].min() - 100, df['小明的余额'].max() + 100xx = np.linspace(x_min, x_max, 1000)xx_scaled = scaler.transform(xx.reshape(-1, 1))# 预测概率proba = model.predict_proba(xx_scaled)[:, 1]# 绘制决策边界plt.figure(figsize=(12, 6))plt.scatter(df['小明的余额'], df['是否买电影票'], c=df['是否买电影票'], cmap='coolwarm', alpha=0.6)plt.plot(xx, proba, 'k-', linewidth=2)plt.axhline(y=0.5, color='r', linestyle='--')plt.title('逻辑回归决策边界')plt.xlabel('余额')plt.ylabel('购买概率')plt.savefig('决策边界.png')plt.close()def main():# 加载和预处理数据df, scaler = load_and_preprocess_data()# 数据可视化visualize_data(df)# 训练和评估模型model, accuracy, report, roc_auc = train_and_evaluate_model(df)# 绘制决策边界plot_decision_boundary(df, model, scaler)if __name__ == "__main__":main()