网站建设运营公司推荐龙岩天宫山有几个台阶
在上一章,我们学习了 Paimon 如何保证每一次写入的原子性和一致性。但数据仓库的核心需求不仅是写入,更重要的是更新。想象一个场景:我们需要实时更新用户的最新信息,或者实时累加计算用户的消费总额。传统的 Hive 数据湖对此无能为力,每次更新都需要重写整个分区,成本极高。
Paimon 通过引入主键(Primary Key)和一套精巧的更新机制,完美解决了这个问题。本章,我们将揭秘 Paimon 高效更新背后的两大支柱:LSM-Tree 思想的巧妙运用,以及功能强大的合并引擎。
6.1 实现原理:LSM 树 (Log-Structured Merge-Tree)
Paimon 并没有在本地磁盘上实现一个完整的 LSM-Tree,而是巧妙地借鉴其核心思想,并将其应用在分布式文件系统(如 HDFS, S3)之上来组织数据文件。
6.1.1 Paimon 如何借鉴 LSM 思想
传统 LSM-Tree 有 MemTable、Immutable MemTable 和多层 SSTable。
Paimon 将其映射为:
MemTable (内存表) -> Flink Writer 的内存缓冲区。
SSTable (有序字符串表) -> Paimon 的数据文件 (Data File),如 Parquet。
核心思想是:写入操作非常快,只追加新文件;读取操作需要合并多个文件来获取最新结果;后台任务(Compaction)会不断合并小文件,优化读取性能。
Paimon 将属于同一个 Bucket 的数据文件组织成一个逻辑上的 LSM-Tree,分为多个层级 (Level):
L0 (Level 0): 所有新的写入(来自 Flink 的新数据)都会生成新的数据文件,并被放入 L0。这一层的文件可能很小,并且它们之间的主键范围可能重叠。
Ln (Level n, n > 0): 更高层级的文件。同一层内的文件,其主键范围互不重叠。文件通常更大,数据也更“陈旧”。
6.1.2 原理图解:数据写入与后台合并 (Compaction)
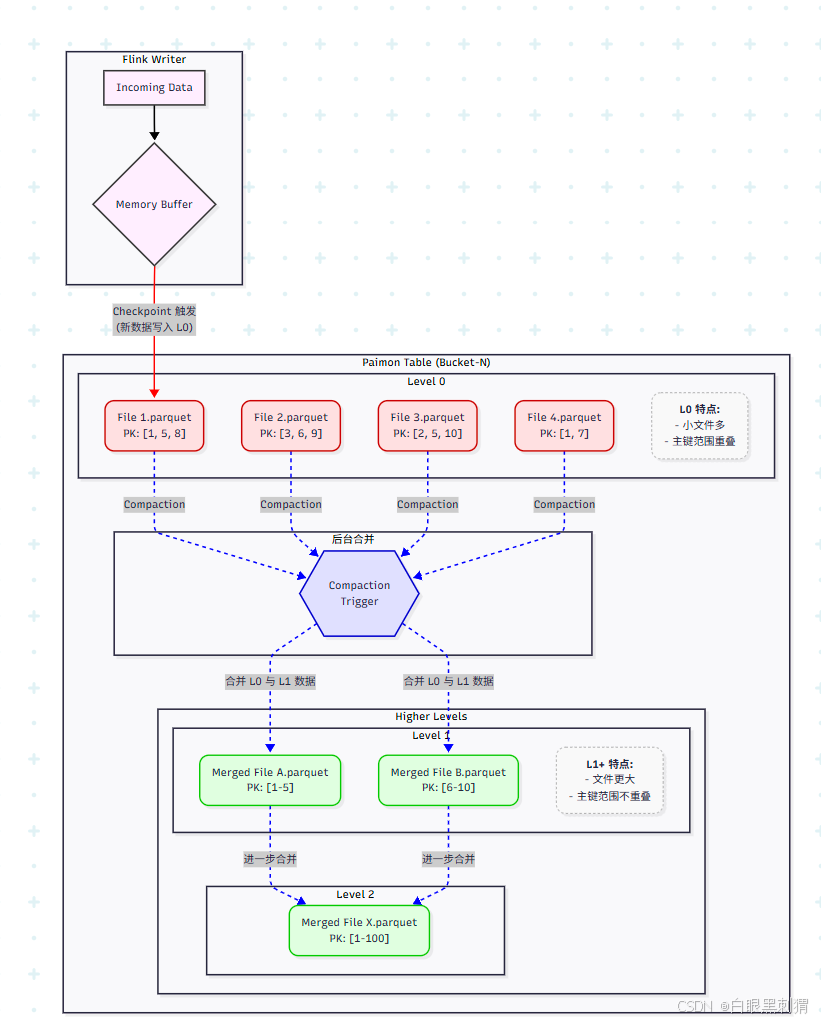
流程讲解:
写入 (Write): Flink 作业持续不断地将数据写入 Paimon 表。每次 Checkpoint 成功后,内存中的数据会被刷写成一个新的数据文件,并放置在 L0。如图中所示,L0 中有多个文件,它们的主键范围是相互重叠的(比如
File 1和File 2都包含主键3和5)。合并 (Compaction):
触发时机:当 L0 的文件数量达到某个阈值(例如
num-sorted-run.compaction-trigger)时,Paimon 会触发一次 Compaction。合并过程:Compaction 任务会选择 L0 中的一些文件,以及 L1 中与这些文件主键范围重叠的文件,将它们一起读出。
数据去重/合并:在读取过程中,Paimon 会应用指定的合并引擎 (Merge Engine) 来处理主键冲突的行(我们将在下一节详述),最终得到每个主键唯一且最新的记录。
生成新文件:合并后的结果被写入到 L1,成为一个或多个新的、更大的、并且在 L1 内部主键不重叠的文件。
级联合并:当 L1 的文件大小或数量也达到阈值时,会触发 L1 到 L2 的合并,以此类推。
读取 (Read): 当用户查询数据时,Paimon 需要同时读取 L0, L1, L2... 中所有与查询条件相关的文件,并在查询时进行合并,以确保返回最新的数据。后台 Compaction 的目的就是减少读取时需要合并的文件数量,从而大幅提升查询性能。
6.2 实现原理:合并引擎 (Merge Engine)
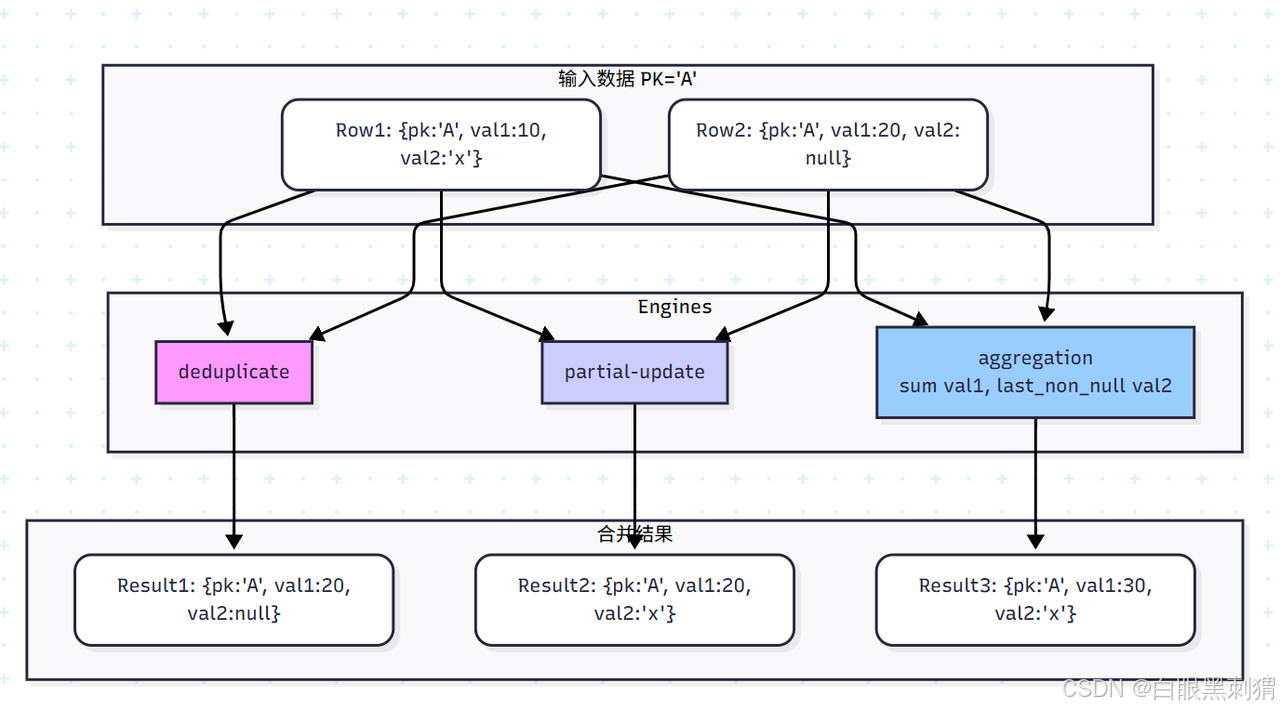
合并引擎定义了当 Compaction 或 Query 时,遇到相同主键的多条记录时应该如何处理。Paimon 提供了三种核心引擎,通过 merge-engine 表属性来指定。
6.2.1 deduplicate: 去重引擎 (默认)
原理:这是最简单的引擎。对于相同主键的多条记录,它只会保留最新的一条。Paimon 内部通过一个序列号来判断新旧,序列号越大表示记录越新。
适用场景:
经典的 CDC (Change Data Capture) 场景,同步业务数据库的
INSERT/UPDATE操作。只需要保留每条记录的最终状态,不需要历史版本。
CREATE TABLE UserProfile (user_id STRING,name STRING,city STRING,PRIMARY KEY (user_id) NOT ENFORCED ) WITH ('merge-engine' = 'deduplicate' -- 默认引擎,可以不写 );-- 写入初始数据 INSERT INTO UserProfile VALUES ('u001', 'Alice', 'New York'); -- 更新数据 (实际上是插入一条新的记录) INSERT INTO UserProfile VALUES ('u001', 'Alice', 'San Francisco');-- 查询结果: -- +---------+-------+-----------------+ -- | user_id | name | city | -- +---------+-------+-----------------+ -- | u001 | Alice | San Francisco | <-- 只保留了最新的城市 -- +---------+-------+-----------------+
6.2.2 partial-update: 部分列更新引擎
原理:一个强大的优化。当新纪录的某些列为
NULL时,它会保留这些列在旧记录中的值,实现“部分更新”。如果新记录的列不为NULL,则会覆盖旧值。优势:避免了“Read-Modify-Write”的模式。更新时,你只需要提供要变更的字段和主键,而不需要先读出整行数据,极大地提升了更新效率。
适用场景:
宽表更新,每次只更新少数几个字段。例如,更新用户画像中的某个标签。
示例代码 (Flink SQL):
CREATE TABLE UserProfile (user_id STRING,name STRING,city STRING,email STRING,PRIMARY KEY (user_id) NOT ENFORCED
) WITH ('merge-engine' = 'partial-update'
);-- 写入初始数据
INSERT INTO UserProfile VALUES ('u002', 'Bob', 'London', 'bob@example.com');-- 只更新城市,其他字段设为 NULL
-- 在 DataStream API 中直接传入 null,在 SQL 中可以用 CAST(NULL AS ...)
INSERT INTO UserProfile VALUES ('u002', NULL, 'Paris', NULL);-- 查询结果:
-- +---------+------+--------+-----------------+
-- | user_id | name | city | email |
-- +---------+------+--------+-----------------+
-- | u002 | Bob | Paris | bob@example.com | <-- name 和 email 被保留,city 被更新
-- +---------+------+--------+-----------------+6.2.3 aggregation: 聚合引擎
原理:当遇到相同主键的记录时,不再是覆盖,而是根据预设的聚合函数进行聚合。每个非主键列都可以指定一种聚合方式。
支持的函数:
sum,max,min,last_non_null_value,last_value,listagg,bool_and,bool_or等。适用场景:
实时指标聚合,如计算每个商品的累计销售额、用户当天的最大消费金额等。
示例代码 (Flink SQL):
CREATE TABLE ProductSales (product_id STRING,sales_count INT,total_revenue DOUBLE,last_sale_time TIMESTAMP(3),PRIMARY KEY (product_id) NOT ENFORCED
) WITH ('merge-engine' = 'aggregation','fields.sales_count.aggregate-function' = 'sum', -- 销量累加'fields.total_revenue.aggregate-function' = 'sum', -- 销售额累加'fields.last_sale_time.aggregate-function' = 'max' -- 保留最新的销售时间
);-- 写入三笔销售记录
INSERT INTO ProductSales VALUES ('p001', 1, 10.5, CAST('2023-10-27 10:00:00' AS TIMESTAMP(3)));
INSERT INTO ProductSales VALUES ('p001', 2, 21.0, CAST('2023-10-27 11:00:00' AS TIMESTAMP(3)));
INSERT INTO ProductSales VALUES ('p001', 1, 9.8, CAST('2023-10-27 10:30:00' AS TIMESTAMP(3)));-- 查询结果:
-- +------------+-------------+---------------+-------------------------+
-- | product_id | sales_count | total_revenue | last_sale_time |
-- +------------+-------------+---------------+-------------------------+
-- | p001 | 4 | 41.3 | 2023-10-27 11:00:00.000 | <-- 所有字段都按规则聚合了
-- +------------+-------------+---------------+-------------------------+合并引擎对比图