深度学习YOLO实战:7、摄像头实时目标检测完整实践
前言
目标检测作为计算机视觉的核心任务,正在安防监控、自动驾驶、工业质检等众多领域发挥着关键作用。YOLOv11作为YOLO系列的最新迭代版本,延续了该系列高精度、高效率的技术优势,并进一步优化了模型结构与训练策略。本文将通过一个完整的摄像头实时目标检测案例,系统介绍YOLOv11的核心原理与应用方法。
学习路径将从构建最小可运行代码开始,逐步深入到实际部署中的关键技术细节。每个技术方案都配有可直接运行的代码示例,同时辅以清晰的原理剖析,阐明代码背后的设计思路与工作机制。例如,在讲解设备节点配置时,不仅说明如何设置参数,还会解析Linux系统下视频设备的管理机制;在讨论内存优化时,将深入分析视频流数据的处理流程与内存分配策略。
无论是刚接触计算机视觉的初学者,还是需要快速搭建演示系统的工程师,都能从本文获得实用参考。文中提供的代码模板均经过实际环境验证,总结的排错方法源于实战经验,可有效缩短项目前期的探索周期。现在,让我们一同开启实时目标检测的实践之旅。
程序模板
为了帮助读者快速搭建可用的目标检测环境,本节提供一个经过验证的基础代码模板。该模板基于Ultralytics框架实现,具有依赖简单、部署便捷的特点,适合用于功能验证和原型开发。
from ultralytics import YOLO
# 加载预训练的YOLOv11纳米尺度模型(yolo11n.pt)
model = YOLO("yolo11n.pt")
# 执行预测任务
model.predict(source=?, # 视频流输入源,需指定摄像头设备节点save=False, # 设置为False时不保存推理结果文件show=True, # 设置为True时实时显示检测画面
)
关键参数说明:
- 模型选择:示例中使用yolo11n.pt为最轻量版本,适合实时检测。可根据需求替换为"yolo11s.pt"(更精确)等其他变体。
- source参数:这是连接摄像头的关键
- Linux系统:通常为
/dev/video0、/dev/video1等设备号 - Windows系统:使用数字索引,如0、1、2等
- 也可接受视频文件路径或RTSP流地址
- Linux系统:通常为
- 显示与存储:
show=True会弹出实时检测窗口,直观展示识别效果save=True将检测结果视频保存至运行目录- 两者可同时启用,满足演示与存档的不同需求
如何确定设备节点号
了解设备节点的概念后,接下来要解决的就是如何找到正确的节点编号。这里提供两种实用的方法,从快速验证到精确定位,适合不同的使用需求。
方法一:顺序尝试法 - 适合快速验证
对于大多数简单场景,最直接的方法就是按照常见规律逐个尝试。操作系统为摄像头分配节点时通常遵循以下模式:
-
节点 0:通常是笔记本电脑的内置摄像头
-
节点 2:往往是第一个外接的USB摄像头
-
节点 4:可能是第二个外接USB摄像头
实际操作时,建议从 source=0 开始尝试。如果运行代码后没有看到摄像头画面,就依次尝试 1、2、3 等相邻数字。这种方法虽然需要一些耐心,但在单摄像头环境或快速测试时通常能很快找到可用的设备节点。
方法二:系统查询法 - 精确定位(Linux系统)
当环境中有多个摄像头,或者需要准确知道每个节点的详细信息时,就需要借助系统命令来进行精确查找。
首先,通过以下命令查看系统中所有的视频设备节点:
ls /dev/video*
这个命令会列出所有视频设备,输出类似于:
/dev/video0 /dev/video1 /dev/video2 /dev/video3
不过,仅仅知道有哪些节点还不够,我们需要了解每个节点对应哪个物理设备。这时候可以使用更详细的查询命令:
v4l2-ctl --list-devices
这个命令的输出会清晰显示设备与节点的对应关系:
USB3.0 Capture: USB3.0 Capture (usb-0000:00:14.0-5.1.2):/dev/video0/dev/video1/dev/media0FF-Camera: FF-Camera (usb-0000:00:14.0-5.1.3):/dev/video2/dev/video3/dev/media1
从输出结果可以清晰地看到:
- 一个名为 “USB3.0 Capture” 的设备,占据了
/dev/video0和/dev/video1两个节点。 - 另一个名为 “FF-Camera” 的物理摄像头,则被分配到了
/dev/video2和/dev/video3节点。
你可能会好奇:为什么一个摄像头需要两个节点?这是因为同一个物理设备可能提供不同类型的数据流。为了找到真正用于视频捕获的节点,我们需要进一步检查每个节点的功能。
通过以下命令检查具体功能:
- 检查
/dev/video2的功能:
v4l2-ctl --device=/dev/video2 --all | grep "Device Caps" -A 2
其输出结果显示它支持关键的视频捕获功能:
Device Caps : 0x04200001Video Capture # 视频捕获Streaming
- 再检查
/dev/video3的功能:
v4l2-ctl --device=/dev/video3 --all | grep "Device Caps" -A 2
其输出则表明该节点仅用于元数据捕获,而非图像流:
Device Caps : 0x04a00000Metadata Capture # 元数据捕获Streaming
很明显,我们应该选择支持 Video Capture 功能的节点(这里是 /dev/video2)作为视频输入源,这样才能正常获取摄像头画面进行目标识别。
实验
好了,理论准备和前期排查都已完成,我们现在就动手让代码跑起来,亲眼看看效果。
根据前面的排查,已经确定摄像头在当前电脑上的设备节点是 2。现在,只需要将之前代码模板中的 source 参数修改为这个确定的编号即可:
只需要把代码中的 source 参数改成 2 就可以了:
from ultralytics import YOLO
# 加载YOLOv11模型,这是一个轻量且高效的预训练模型
model = YOLO("yolo11n.pt")
# 启动预测,调用摄像头并实时显示结果
model.predict(source=2, # 关键步骤:填入我们找到的正确设备节点号save=False, # 本次运行暂不保存结果文件,专注于实时体验show=True, # 核心功能:实时打开一个窗口显示检测画面
)
当这段代码成功运行时,终端控制台会开始滚动输出详细的运行日志。一段典型的成功日志如下:
1/1: 2... Success ✅ (inf frames of shape 640x480 at 30.00 FPS)WARNING ⚠️
inference results will accumulate in RAM unless `stream=True` is passed, causing potential out-of-memory
errors for large sources or long-running streams and videos. See https://docs.ultralytics.com/modes/predict/ for help.
source
Example:results = model(source=..., stream=True) # generator of Results objectsfor r in results:boxes = r.boxes # Boxes object for bbox outputsmasks = r.masks # Masks object for segment masks outputsprobs = r.probs # Class probabilities for classification outputs0: 480x640 (no detections), 74.7ms
0: 480x640 (no detections), 53.5ms
0: 480x640 (no detections), 59.5ms
如何理解这些信息呢?
Success ✅是最直接的信号,它告诉我们程序已经成功握手指定了摄像头,并识别出视频流是640x480分辨率、30帧的规格。- 下方持续滚动的行(如
0: 480x640 (no detections), 74.7ms)是模型对每一帧画面的“思考”记录。(no detections)表示此刻画面中没有识别到任何目标,而旁边的74.7ms则反映了处理这一帧所花费的时间,直观地展示了模型的推理速度。
最激动人心的部分在这里! 在日志滚动的同一时间,你的屏幕上会弹出一个新的实时视频窗口。YOLO模型正在幕后默默工作,将它识别出的所有物体在视频画面中用方框和标签精准地标注出来。
下面这个动图捕捉了程序运行时的真实瞬间,你可以感受一下这种实时的分析效果:

当这个窗口成功弹出,并且你能看到流畅的、带有实时标注的摄像头画面时,恭喜你!你的第一个实时目标检测应用已经成功运行起来了。如果过程中遇到窗口未弹出或画面卡住等问题,最常见的排查点就是回头确认一下设备节点号是否准确,或者检查一下摄像头是否被其他软件占用了。
问题:内存泄漏警告
在程序运行过程中,细心的你可能会发现控制台输出中包含了一个关键警告信息:
WARNING ⚠️
inference results will accumulate in RAM unless `stream=True` is passed, causing potential out-of-memory
errors for large sources or long-running streams and videos. See https://docs.ultralytics.com/modes/predict/ for help.
问题本质分析
这个警告揭示了一个重要的内存管理问题。为了更好地理解,可以将其类比为阅读长篇文档:如果要求读者必须记住每一页的详细内容,而不是在阅读后续内容时释放前面的记忆,那么认知负荷会越来越重,最终难以承受。
在技术层面,当未设置 stream=True 参数时,YOLO推理引擎会将每一帧的处理结果完整地保存在内存中。随着视频流的持续运行,这些累积的数据会逐渐占用大量内存空间,最终可能导致系统内存耗尽。
实际内存占用验证
为了直观展示这个问题,我们专门监控了推理过程中的系统内存使用情况。从下面的对比截图中可以清晰看到问题的严重性:
推理运行时的内存占用状态:
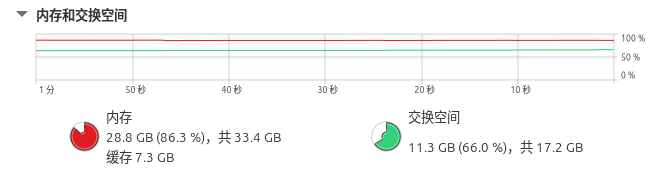
可以看到,在推理过程中,物理内存和交换空间的使用率都达到了较高水平。更重要的是,这种内存占用会随着推理时间的延长呈现持续上升的趋势。
停止推理后的内存释放状态:
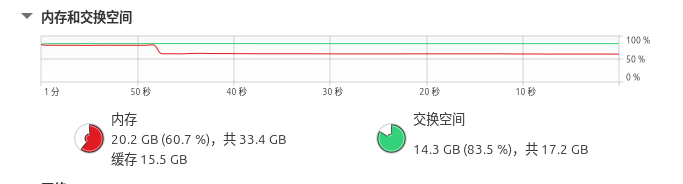
当终止推理程序后,系统内存占用立即出现显著下降。这一鲜明对比证实了警告信息的准确性:长时间运行视频流推理确实会引发内存累积问题。
解决方案
幸运的是,系统在发出警告的同时,也很贴心地给出了解决方案和示例代码。这个示例清楚地展示了如何正确使用流式处理来避免内存泄漏问题:
errors for large sources or long-running streams and videos. See https://docs.ultralytics.com/modes/predict/ for help.
source
Example:results = model(source=..., stream=True) # generator of Results objectsfor r in results:boxes = r.boxes # Boxes object for bbox outputsmasks = r.masks # Masks object for segment masks outputsprobs = r.probs # Class probabilities for classification outputs
参照官方给出的示例,我对代码进行了相应的修改。这样修改后,我们不仅解决了内存泄漏问题,还获得了更好的程序控制能力:
import cv2
from ultralytics import YOLO
model = YOLO("yolo11n.pt")
results = model(source=2, stream=True)
cv2.namedWindow('YOLO Camera', cv2.WINDOW_NORMAL)
try:for r in results:frame = r.plot()cv2.imshow('YOLO Camera', frame)cv2.waitKey(1) # 关键刷新调用
except KeyboardInterrupt:print("程序被用户中断")
finally:cv2.destroyAllWindows()print("资源已清理")
现在问题已经完全解决了!修改后的程序不再产生内存警告,而且无论运行多长时间,内存占用都保持稳定,不会再出现持续增长的情况。从下面的运行日志可以看出,程序运行得很稳定:
1/1: 2... Success ✅ (inf frames of shape 640x480 at 30.00 FPS)0: 480x640 (no detections), 60.6ms
0: 480x640 (no detections), 55.5ms
0: 480x640 (no detections), 60.6ms