多模态大模型真的需要原生分辨率吗?
最近(2025年10月)发布的多模态大模型基本采用原生分辨率的图像配置,例如Kimi-VL、Qwen3-VL、Seed1.5-VL等。以Qwen3-VL为例,采用原生分辨率输入,保证输入图像的无损高清。
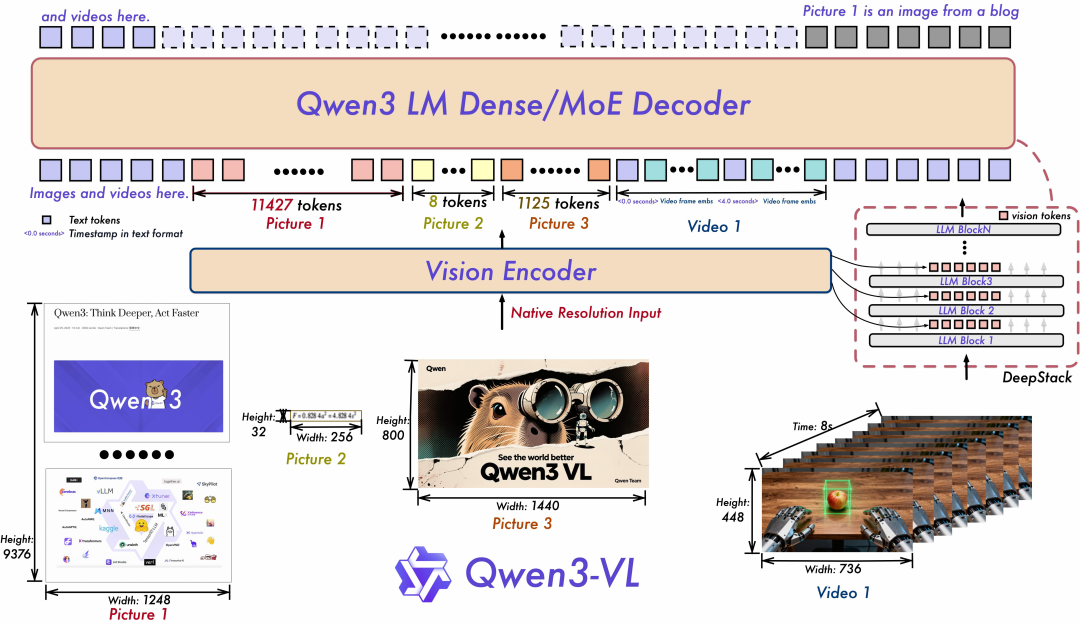
然而,鲜有研究工作去分析图像分辨率、图像宽高比对多模态大模型的影响。
北大、上海人工智能实验室等机构的研究人员构建评测集RC-Bench(Resolution-Centric)、原生分辨率多模态大模型NativeRes-LLaVA,来分析图像分辨率、比例对多模态大模型的影响。
-
论文标题:Native Visual Understanding: Resolving Resolution Dilemmas in Vision-Language Models
-
论文地址:https://arxiv.org/pdf/2506.12776
-
论文代码:https://github.com/Niujunbo2002/NativeRes-LLaVA
1. 已有benchmark分析
已有benchmark是否真正考虑了分辨率因素?
为了深入探讨这一点,从数据分布角度分析图像分辨率和宽高比。
-
图像分辨率:将图像分为七个不同的区间,以 384×384 像素为基本单位,从小到大是 A 到 G。
-
图像宽高比:将宽高比(定义为宽度与高度的比值)分为五个区间:中等(NM:2:1~1:2)、宽(AW:4:1~2:1)、非常宽(BW:>4:1)、高(AH:1:2~1:4)和非常高(BH:<1:4)。 分析结果如下图所示
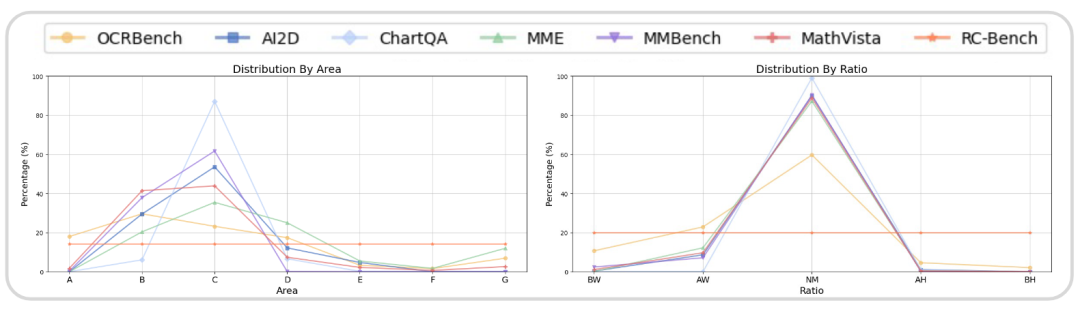
有如下观察:
-
大多数benchmark(如 MME、MMBench等)主要由相对单一分辨率的图像组成。同样,它们的宽高比分布也相对集中。因此,难以覆盖真实场景的视觉多样性。
-
评估方法侧重于对图像内容的整体理解(例如,判断模型对图像内容的答案是否正确),缺乏对特定图像属性(如分辨率分布、宽高比)如何影响 VLM 准确性的详细探索。
自然要自己构建数据集!
2. RC-Bench
在构造评测集之前,需要回答一个问题,是否真的有必要针对图像分辨率、宽高比构建评测集?
本文认为,视觉任务分为两种类型,分别是以语义为中心和以像素为中心。
以语义为中心侧重语义等高层信息,例如下图识别狗,近视眼看得模糊也能识别出狗,可以不需要高清的分辨率。
以像素为中心侧重像素等底层细节信息,例如下图识别详细数字,近视眼需要戴眼镜,才能看清黑板上的字,一定需要清晰的图像分辨率。
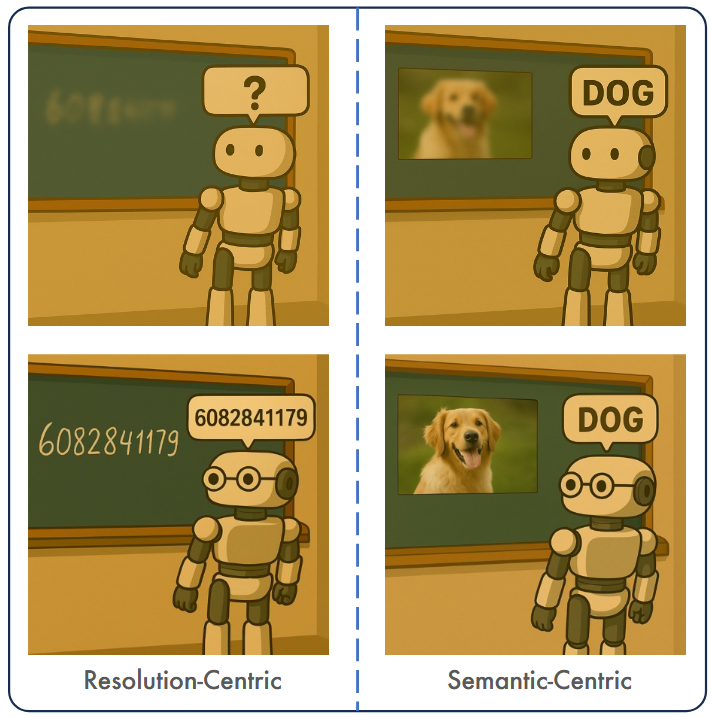
本文希望构建一个对SC任务无感、RC任务敏感的评测集,提出了 RC-Bench,专注于衡量真实场景中复杂的图像分辨率、图像宽高比对多模态大模型的影响。
数据构建。整合现有的公开数据集和私有数据集,构建了一个在面积、宽高比方面分布均衡的数据集。构建流程如下图:
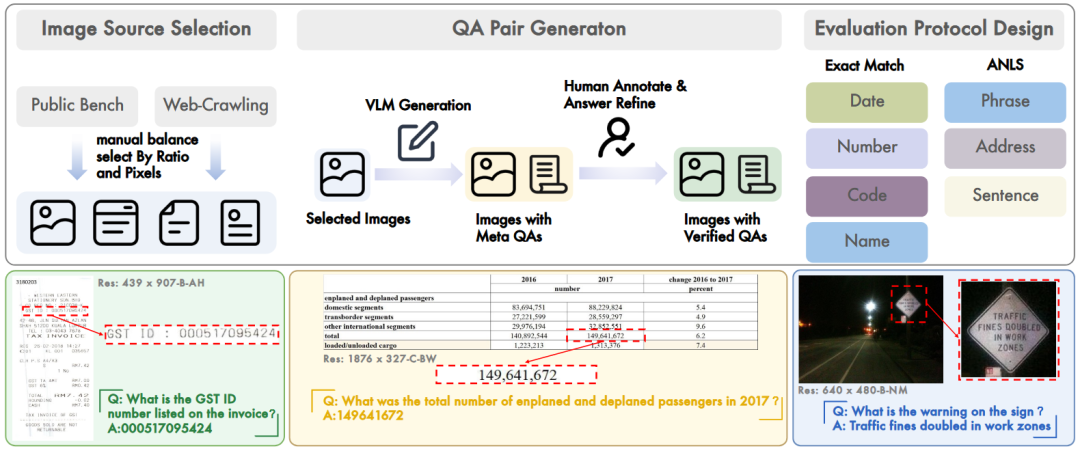
(1)从公开数据集中选择高质量图像,经人工验证确保其可读性和内容复杂性。
(2)为进一步提升多样性,添加私有数据。
(3)采用图像填充和调整大小技术来增强极端宽高比或尺寸
(4)产生 1750 张高质量、视觉丰富的图像,均匀分布在七个预定义的分辨率级别和五个宽高比类别中。
问答对生成。采用了一种混合策略——结合自动生成和手动筛选。
(1)使用GPT-4o从图像生成候选问答对。
(2)人工审核,确保问题清晰明确。
(3)问题类型主要侧重于要求模型识别图像中的文本内容并提供准确答案。这些图像涵盖了多种类别,包括发票、图表、自然场景、手写文件、海报和界面截图。相应的答案类型包括数字、日期、姓名、短语和完整的句子。
评估方法。针对不同类型采用了不同的评估指标。
-
对于数字、名称和代码片段等简洁答案,使用精确匹配(EM)。
-
对于包含单位的数值答案,标准化了多种等效表达方式,增强 EM 评估的鲁棒性。
-
对于更复杂答案,如长地址或完整句子,使用Average Normalized Levenshtein Similarity(ANLS)指标进行部分匹配评估。
3. 已有多模态大模型分析
现在已经有很多原生分辨率的多模态大模型,例如Kimi-VL、Qwen3-VL、Seed1.5-VL,大多数来自商业公司,关键的代码细节没有开源,如下
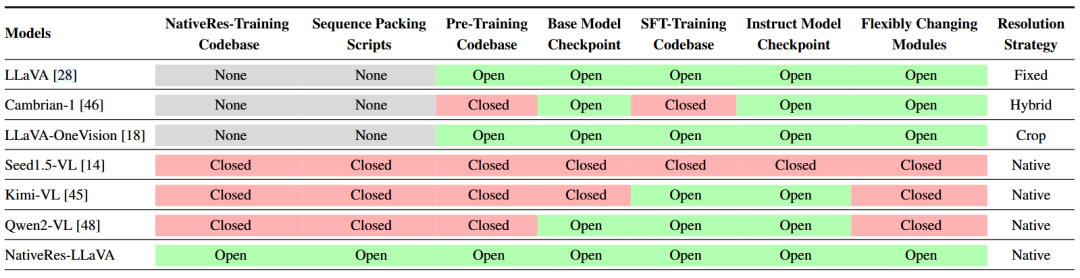
因此很难直接基于他们代码做图像分辨率、图像宽高比的实验效果验证。
自然要自己开源算法!
4. NativeRes-LLaVA
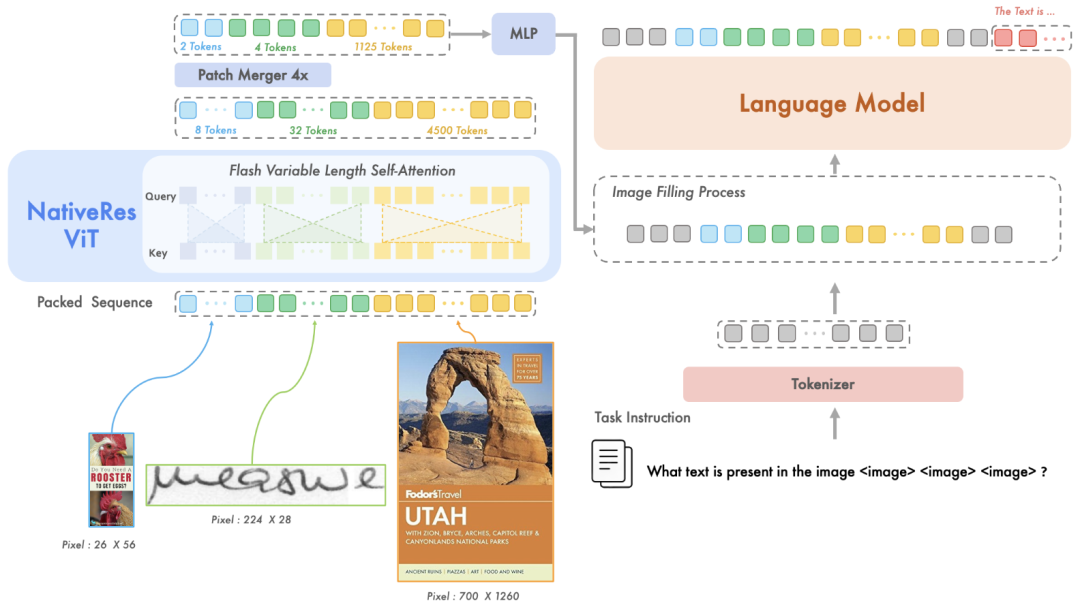
NativeRes-LLaVA 包含四个主要模块:(1)支持 2D 旋转位置编码(RoPE)的原生分辨率视觉编码器,能够有效处理各种分辨率和宽高比的图像;(2)压缩模块,用于进一步压缩视觉编码器产生的视觉标记;(3)两层的多层感知机(MLP);(4)大语言模型。
4.1 原生分辨率视觉编码
受 Qwen2-VL 的启发,在 NativeRes-LLaVA 中引入了一种原生分辨率编码机制,可以处理任意分辨率的图像
视觉编码器原生支持动态图像分辨率,并采用 2D RoPE 进行位置编码,能够灵活适应不同尺寸的图像。
为了提高计算效率,对相邻的 2×2 特征块应用平均池化。
完整的输入流是这样的:一个分辨率为 336×336 的图像,当通过一个patch size为 14 的 ViT 时,首先会被转换为 576 个视觉token。然后,经过一个 2×2 的patch merger后,压缩为 144 个视觉token,经MLP做维度对齐,输入到大语言模型中。
4.2 多模态序列打包
原生分辨率方法对每一条数据生成变长的序列,难以组成batch做并行计算。传统做法通过padding将序列长度统一。该方法会填充短序列,填充的token对计算无影响,但需要消耗资源,造成资源浪费。
为了解决这个问题,使用了 NaViT 的 Patch n'Pack ,将不同图像的patch 序列打包成一个长序列。
在训练过程中,对于batch中的每个不同分辨率的图像 ,将其预处理为一个batch序列 ,并直接将所有图像的序列连接起来,得到一个打包序列 ,并且使用flash-attention来优化。
4.3 模型训练
大语言模型采用Qwen2-7B-Instruct,视觉编码器采用Qwen2-VL-2B初始化的NaViT。
所有实验在 8 块 NVIDIA A100-80G GPU 上进行。
训练过程包含两个阶段。
阶段 1:VLM 预训练。冻结了 LLM 和视觉编码器,仅微调视觉投影器MLP参数。
阶段 2:视觉指令微调。使用了两种配置,首先冻结视觉编码器,同时微调 MLP 投影器和 LLM。最后微调所有参数。
5. 实验
5.1 原生分辨率对RC、SC benchmark的影响
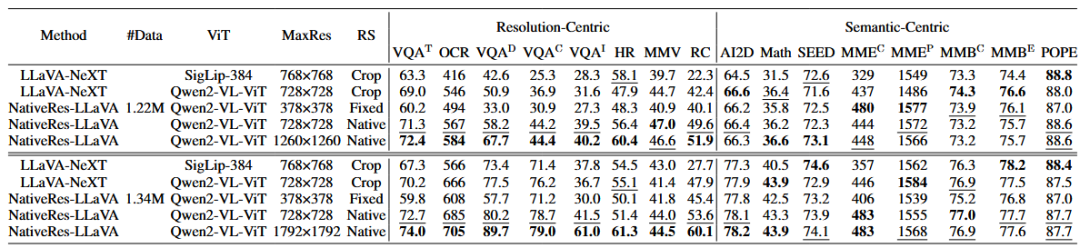
从消融实验上看,有以下结论:
-
在RC类数据集上,Crop、Fixed、Native等图像分辨率处理方法中,Native效果最好。
-
在SC类数据集上,有意思的是,Crop、Fixed、Native方法不影响最终效果。
结果验证了:(1)Native对RC类数据集友好;(2)SC类数据集可以不需要原生分辨率编码方式。
RC-Bench上的实验结果,进一步验证了上述观点:
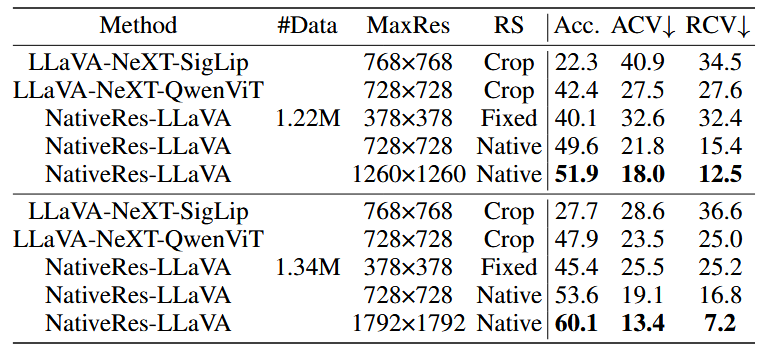
5.2 原生分辨率 VS Cropping-based
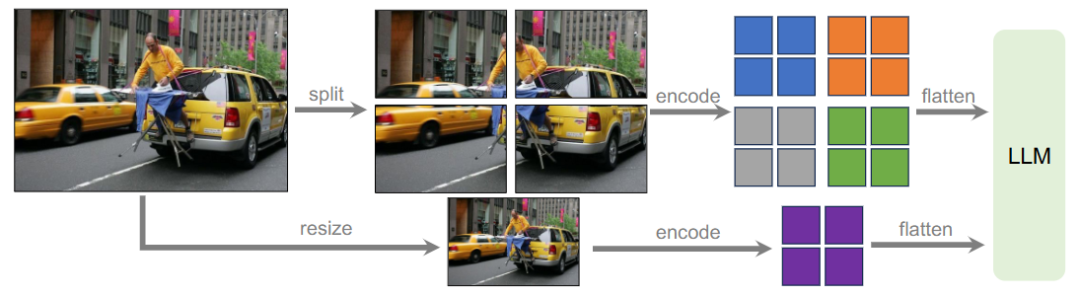
除了原生分辨率的图像处理方式之外,Cropping-based是更为常见的一种策略,例如LLaVA-NeXT把大图片切成四份,每份送到ViT中提取patch embedding,合并起来送到LM中,如下图
统计NativeRes-LLaVA在图像分辨率、图像宽高比的不同维度的指标,如下图:
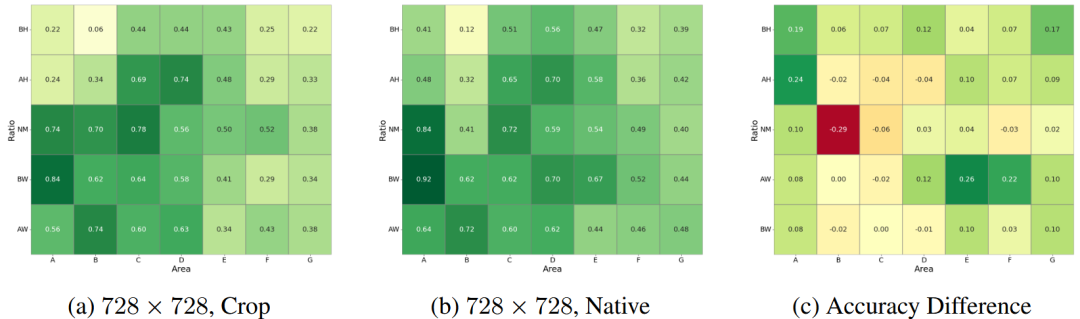
第三幅图表示(b)-(a)的结果,有以下观察:
-
图(c)中间部分代表普遍情况,该部分Native和Crop效果接近。
-
图(c)四边表示极端情况,例如图片面积大、图像宽高比极端,该部分Native比Crop效果更好。
-
在(NM, B)情况下,Crop更好,分析原因是该部分图像尺寸和预训练阶段的图像尺寸一致,训练-推理间的gap更低。
6. 一些思考
(1)原生分辨率在RC场景非常有用,但是在SC场景基本用处不大。
在性能层面,从本文的结果上看,原生分辨率是完全替代其他方法的。作者能比较原生分辨率方法和其他方法在推理性能上的差异就更好了,如果推理性能差不多,那工业场景使用的图像分辨率处理方法就基本收敛了。
(2)个人感觉,RC-Bench构建的意义不是很大。
RC-Bench是RC类型的benchmark,很多公开数据集也是这个类型的。RC-Bench的意义在于分布均衡,便于做图像分辨率、图像宽高比维度上的数据分析,但是直接分析已有benchmark也是可以的。