网站托管如何收费合肥公司
背景意义
研究背景与意义
随着全球气候变化和农业生产方式的转变,植物病害的发生频率和种类日益增加,给农业生产带来了严峻的挑战。植物病害不仅影响作物的生长和产量,还可能导致经济损失和食品安全问题。因此,开发高效、准确的植物病害检测系统显得尤为重要。近年来,深度学习技术在计算机视觉领域取得了显著进展,尤其是目标检测和图像分割方面的应用,为植物病害的自动识别提供了新的解决方案。
YOLO(You Only Look Once)系列模型因其高效的实时检测能力和较好的检测精度,成为了植物病害检测研究中的热门选择。YOLOv11作为该系列的最新版本,结合了更为先进的网络结构和优化算法,能够在复杂背景下实现更高的检测精度和速度。通过对YOLOv11的改进,我们可以进一步提升其在植物病害检测中的表现,尤其是在对不同病害类型的准确识别和分类方面。
本研究将基于CocoAID数据集,重点关注“灰叶斑”和“叶腐病”这两种常见的植物病害。该数据集包含3710张经过标注的图像,涵盖了多种植物病害的表现特征,为模型的训练和评估提供了丰富的样本。通过对YOLOv11的改进,我们旨在提高模型对这两种病害的检测能力,从而为农业生产提供有效的技术支持。
此外,植物病害的早期检测和准确识别不仅能够帮助农民及时采取防治措施,还能为农业管理提供数据支持,推动精准农业的发展。因此,基于改进YOLOv11的植物病害检测系统的研究,不仅具有重要的学术价值,也对实际农业生产具有深远的影响。通过这一研究,我们希望能够为植物病害的监测和管理提供新的思路和方法,促进农业的可持续发展。
图片效果
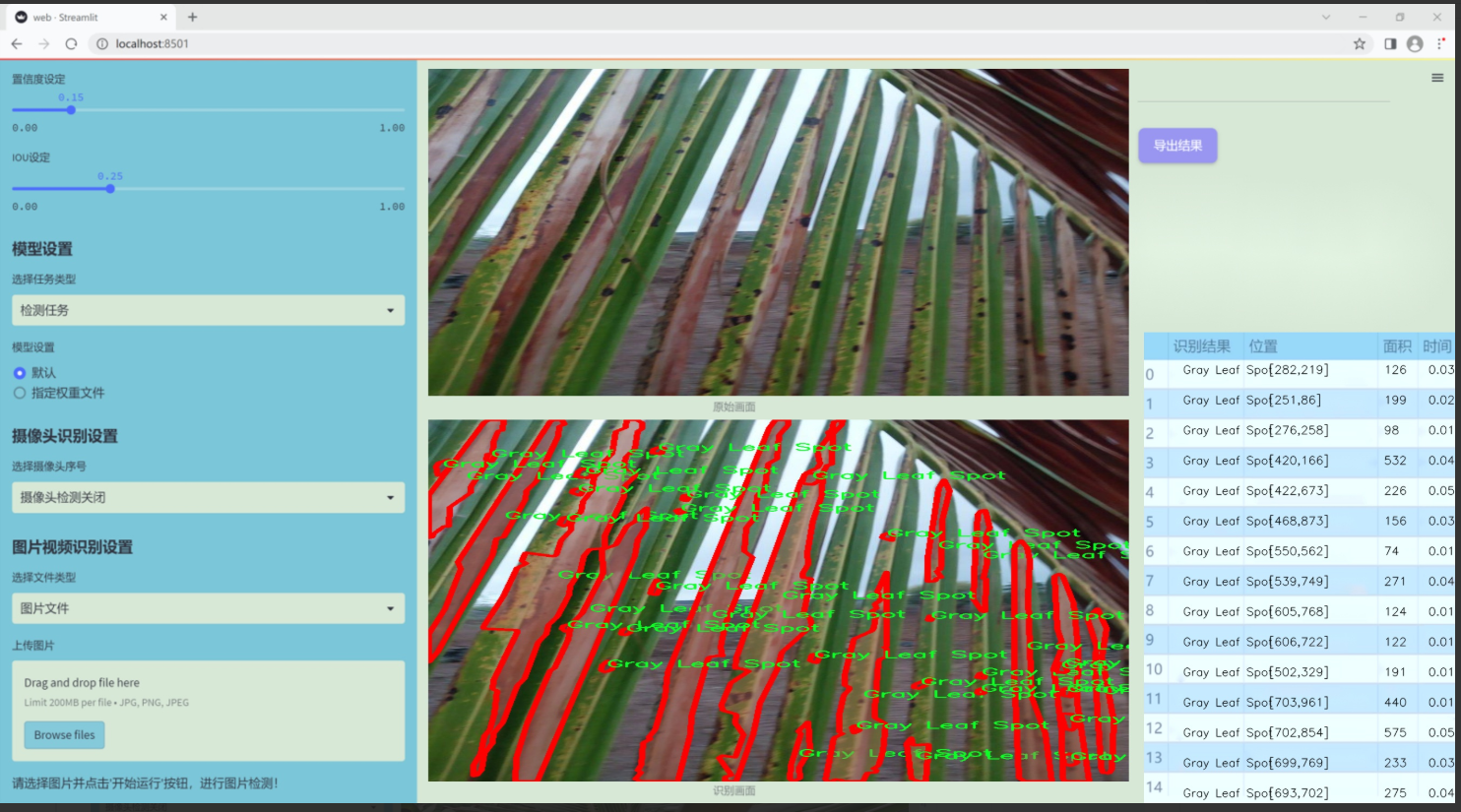
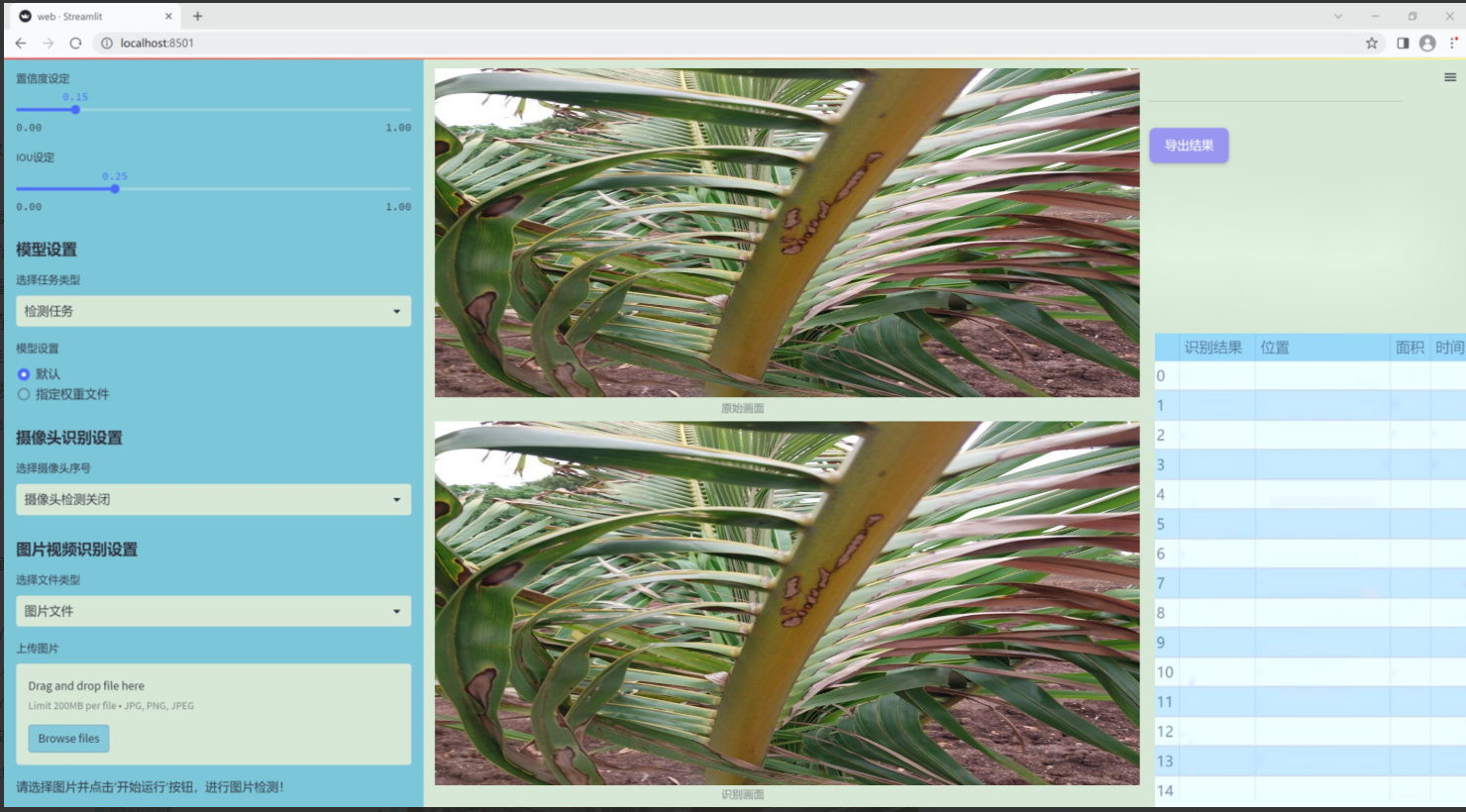
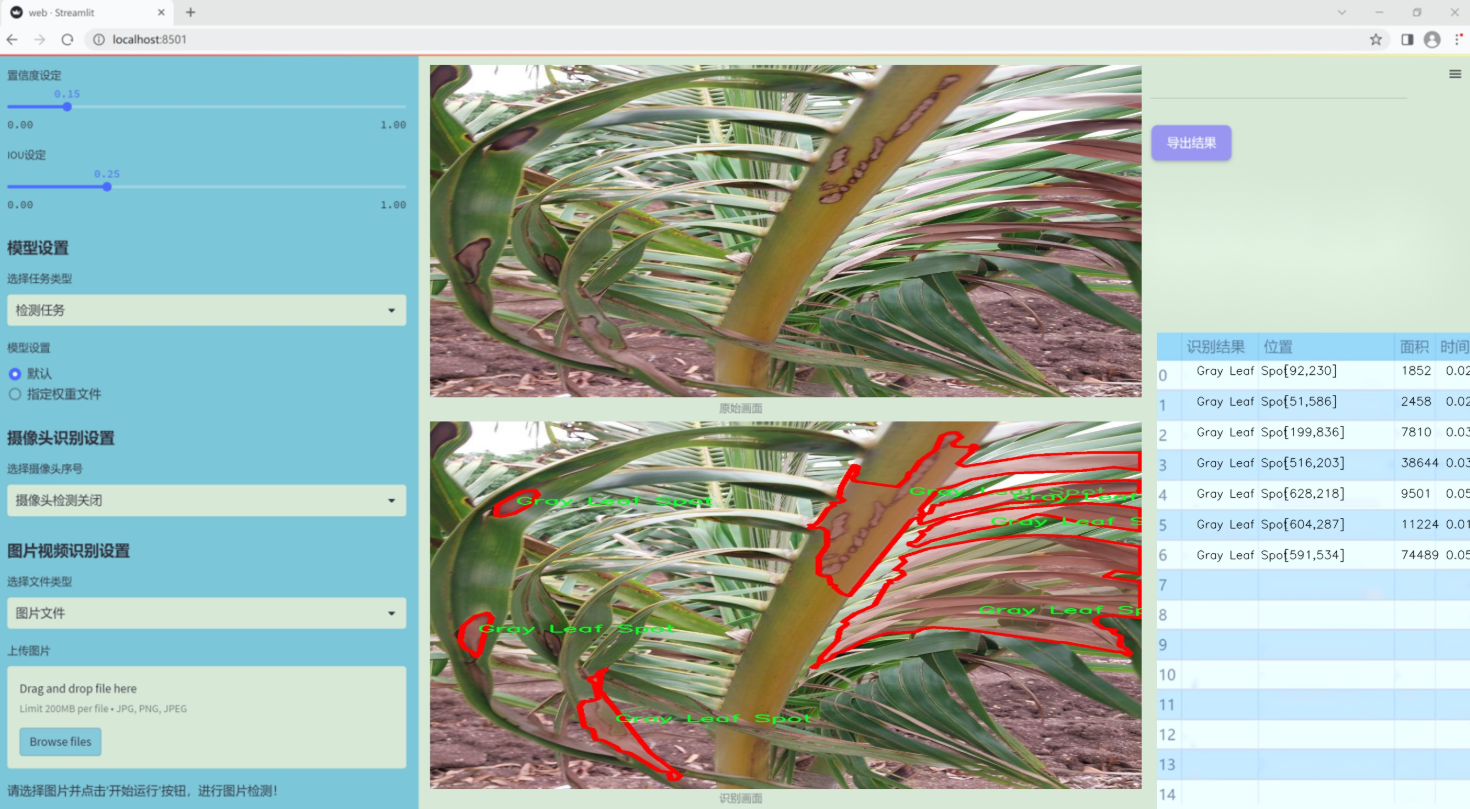
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的植物病害检测系统,专注于植物叶片病害的识别与分类。数据集的主题围绕“CocoAID Model”构建,专注于两种主要的植物病害类型:灰叶斑病(Gray Leaf Spot)和叶腐病(Leaf Rot)。这两种病害在农业生产中具有广泛的影响,能够显著降低作物的产量和质量,因此对其进行准确的检测和分类显得尤为重要。
数据集中包含丰富的图像样本,涵盖了不同生长阶段、不同光照条件和不同病害严重程度的植物叶片。这些样本不仅提供了多样化的视觉信息,还考虑到了自然环境中植物的多样性,使得模型在实际应用中能够具备更强的适应性和鲁棒性。每个样本都经过精心标注,确保在训练过程中能够有效地学习到病害的特征和模式。
通过使用该数据集,改进后的YOLOv11模型将能够在更短的时间内实现高效的病害检测,并提高检测的准确率。这对于农民和农业工作者来说,能够及时发现病害并采取相应的防治措施,从而有效减少经济损失。此外,数据集的设计也为后续的研究提供了基础,促进了植物病害检测领域的进一步发展。
总之,本项目的数据集不仅是对YOLOv11模型的有力支持,也是推动农业智能化和精准化的重要一步,期待其在实际应用中能够发挥出更大的价值。





核心代码
以下是经过简化和注释的核心代码部分,主要集中在几个重要的注意力机制类上:
import torch
from torch import nn
import torch.nn.functional as F
class EMA(nn.Module):
“”"
Exponential Moving Average (EMA) module for enhancing feature representation.
“”"
def init(self, channels, factor=8):
super(EMA, self).init()
self.groups = factor # 将通道分成多个组
assert channels // self.groups > 0 # 确保每组有通道
self.softmax = nn.Softmax(-1) # Softmax用于权重计算
self.agp = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化
self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # 针对高度的池化
self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # 针对宽度的池化
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 组归一化
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1) # 1x1卷积
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, padding=1) # 3x3卷积
def forward(self, x):b, c, h, w = x.size() # 获取输入的尺寸group_x = x.reshape(b * self.groups, -1, h, w) # 将输入重塑为多个组x_h = self.pool_h(group_x) # 对高度进行池化x_w = self.pool_w(group_x).permute(0, 1, 3, 2) # 对宽度进行池化并转置hw = self.conv1x1(torch.cat([x_h, x_w], dim=2)) # 连接并通过1x1卷积x_h, x_w = torch.split(hw, [h, w], dim=2) # 分割为高度和宽度x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid()) # 计算特征增强x2 = self.conv3x3(group_x) # 通过3x3卷积计算特征x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 计算权重x12 = x2.reshape(b * self.groups, c // self.groups, -1) # 重塑特征x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 计算权重x22 = x1.reshape(b * self.groups, c // self.groups, -1) # 重塑特征weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w) # 计算最终权重return (group_x * weights.sigmoid()).reshape(b, c, h, w) # 返回增强后的特征
class SimAM(nn.Module):
“”"
Similarity Attention Module (SimAM) for enhancing feature representation.
“”"
def init(self, e_lambda=1e-4):
super(SimAM, self).init()
self.activaton = nn.Sigmoid() # 激活函数
self.e_lambda = e_lambda # 正则化参数
def forward(self, x):b, c, h, w = x.size() # 获取输入的尺寸n = w * h - 1 # 计算总的像素数减去1x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2) # 计算每个像素与均值的平方差y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5 # 计算注意力权重return x * self.activaton(y) # 返回加权后的特征
class SpatialGroupEnhance(nn.Module):
“”"
Spatial Group Enhancement module for enhancing spatial features.
“”"
def init(self, groups=8):
super().init()
self.groups = groups # 组数
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化
self.weight = nn.Parameter(torch.zeros(1, groups, 1, 1)) # 权重参数
self.bias = nn.Parameter(torch.zeros(1, groups, 1, 1)) # 偏置参数
self.sig = nn.Sigmoid() # Sigmoid激活函数
self.init_weights() # 初始化权重
def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out') # Kaiming初始化if m.bias is not None:nn.init.constant_(m.bias, 0) # 偏置初始化为0def forward(self, x):b, c, h, w = x.shape # 获取输入的尺寸x = x.view(b * self.groups, -1, h, w) # 重塑为多个组xn = x * self.avg_pool(x) # 计算增强特征xn = xn.sum(dim=1, keepdim=True) # 按组求和t = xn.view(b * self.groups, -1) # 重塑t = t - t.mean(dim=1, keepdim=True) # 去均值std = t.std(dim=1, keepdim=True) + 1e-5 # 计算标准差t = t / std # 归一化t = t.view(b, self.groups, h, w) # 重塑t = t * self.weight + self.bias # 加权和偏置t = t.view(b * self.groups, 1, h, w) # 重塑x = x * self.sig(t) # 应用注意力return x.view(b, c, h, w) # 返回增强后的特征
代码说明
EMA (Exponential Moving Average): 该模块通过对输入特征进行池化和卷积操作,增强特征表示。它使用组归一化和1x1卷积来计算权重,并通过sigmoid激活函数对特征进行加权。
SimAM (Similarity Attention Module): 该模块通过计算每个像素与均值的平方差,生成注意力权重,并将其应用于输入特征。它使用sigmoid激活函数来增强特征。
SpatialGroupEnhance: 该模块通过自适应平均池化和卷积操作,增强空间特征。它将输入特征分成多个组,并对每个组进行加权和偏置处理。
这些模块在特征提取和增强中起着重要作用,尤其是在视觉任务中。
这个程序文件 attention.py 实现了一系列的注意力机制模块,主要用于深度学习中的视觉任务,特别是在图像处理和计算机视觉领域。以下是对代码的详细说明:
首先,文件导入了必要的库,包括 PyTorch 和一些其他的工具库。PyTorch 是一个流行的深度学习框架,提供了张量计算和自动微分的功能。
接下来,文件定义了一些注意力机制的类,这些类都继承自 nn.Module,是 PyTorch 中所有神经网络模块的基类。每个类实现了不同的注意力机制,例如:
EMA (Exponential Moving Average):这个类实现了一种基于指数移动平均的注意力机制,主要用于增强特征图的表示能力。它通过对输入特征图进行分组、池化和卷积操作来计算注意力权重,并对输入进行加权。
SimAM (Similarity Attention Module):这个模块通过计算输入特征图的均值和方差来生成注意力权重,使用 Sigmoid 激活函数来调节输出。
SpatialGroupEnhance:该模块通过对输入特征图进行空间增强,利用分组卷积和自适应平均池化来生成增强的特征图。
TopkRouting:实现了一种可微分的 Top-k 路由机制,允许在特征图中选择最重要的特征进行处理。
KVGather:该模块根据路由索引和权重从键值对中收集特征,支持不同的加权方式(软或硬)。
QKVLinear:用于生成查询、键和值的线性变换。
BiLevelRoutingAttention:实现了一种双层路由注意力机制,结合了全局和局部注意力的优点。
CoordAtt、TripletAttention、BAMBlock、EfficientAttention 等类实现了其他不同的注意力机制,分别关注于不同的特征交互和增强策略。
DeformConv 和 deformable_LKA:实现了可变形卷积,允许模型根据输入特征动态调整卷积核的位置。
EffectiveSEModule、LSKA、SegNext_Attention 等模块则结合了通道注意力和空间注意力的机制,增强了特征图的表达能力。
文件中还包含了一些辅助函数,如 img2windows 和 windows2img,用于将图像分割成窗口和将窗口重组为图像的操作。
最后,文件中定义的所有类和函数都被包含在 all 列表中,表示这些是模块的公共接口,可以被其他模块导入和使用。
总体来说,这个文件实现了多种先进的注意力机制,适用于图像分类、目标检测和语义分割等任务,提供了灵活的特征增强和选择能力。
10.4 SwinTransformer.py
以下是经过简化和注释的代码,保留了最核心的部分,主要是Swin Transformer的结构和功能。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Mlp(nn.Module):
“”" 多层感知机 (MLP) 模块。“”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_features # 输出特征数hidden_features = hidden_features or in_features # 隐藏层特征数self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换self.act = act_layer() # 激活函数self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换self.drop = nn.Dropout(drop) # Dropout层def forward(self, x):""" 前向传播函数。"""x = self.fc1(x) # 线性变换x = self.act(x) # 激活x = self.drop(x) # Dropoutx = self.fc2(x) # 线性变换x = self.drop(x) # Dropoutreturn x
class WindowAttention(nn.Module):
“”" 窗口基础的多头自注意力模块。“”"
def __init__(self, dim, window_size, num_heads):super().__init__()self.dim = dim # 输入通道数self.window_size = window_size # 窗口大小self.num_heads = num_heads # 注意力头数head_dim = dim // num_heads # 每个头的维度self.scale = head_dim ** -0.5 # 缩放因子# 定义相对位置偏置参数self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size - 1) * (2 * window_size - 1), num_heads))# 定义查询、键、值的线性变换self.qkv = nn.Linear(dim, dim * 3)self.softmax = nn.Softmax(dim=-1) # Softmax层self.proj = nn.Linear(dim, dim) # 输出线性变换def forward(self, x):""" 前向传播函数。"""B, N, C = x.shape # B: 批量大小, N: 序列长度, C: 通道数qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # 获取查询、键、值q = q * self.scale # 缩放查询attn = (q @ k.transpose(-2, -1)) # 计算注意力权重attn = self.softmax(attn) # 应用Softmaxx = (attn @ v).transpose(1, 2).reshape(B, N, C) # 计算输出x = self.proj(x) # 线性变换return x
class SwinTransformerBlock(nn.Module):
“”" Swin Transformer块。“”"
def __init__(self, dim, num_heads, window_size=7):super().__init__()self.attn = WindowAttention(dim, window_size, num_heads) # 注意力模块self.mlp = Mlp(in_features=dim) # MLP模块self.norm1 = nn.LayerNorm(dim) # 归一化层self.norm2 = nn.LayerNorm(dim) # 归一化层def forward(self, x):""" 前向传播函数。"""shortcut = x # 残差连接x = self.norm1(x) # 归一化x = self.attn(x) # 注意力计算x = shortcut + x # 残差连接x = self.norm2(x) # 归一化x = self.mlp(x) # MLP计算return x
class SwinTransformer(nn.Module):
“”" Swin Transformer主干网络。“”"
def __init__(self, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], embed_dim=96):super().__init__()self.layers = nn.ModuleList() # 存储每一层for i in range(len(depths)):layer = SwinTransformerBlock(dim=embed_dim * (2 ** i), # 随层数增加通道数num_heads=num_heads[i])self.layers.append(layer) # 添加层def forward(self, x):""" 前向传播函数。"""for layer in self.layers:x = layer(x) # 逐层计算return x
def SwinTransformer_Tiny():
“”" 创建一个小型的Swin Transformer模型。“”"
model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24])
return model
代码说明:
Mlp类:实现了一个简单的多层感知机,包括两个线性层和一个激活函数(GELU)。
WindowAttention类:实现了窗口基础的多头自注意力机制,包含相对位置偏置的计算。
SwinTransformerBlock类:实现了Swin Transformer的基本块,包含注意力层和MLP层。
SwinTransformer类:构建了整个Swin Transformer模型,包含多个Swin Transformer块。
SwinTransformer_Tiny函数:用于创建一个小型的Swin Transformer模型实例。
以上代码为Swin Transformer的核心结构,能够用于图像处理等任务。
该程序文件实现了Swin Transformer模型,这是一个用于计算机视觉任务的深度学习模型。文件中包含多个类和函数,主要构成了Swin Transformer的各个组件。
首先,导入了必要的库,包括PyTorch及其相关模块。接着定义了一个名为Mlp的类,这是一个多层感知机(MLP),用于处理输入特征。它包含两个线性层和一个激活函数(默认为GELU),并在每个线性层后添加了Dropout以防止过拟合。
接下来,定义了window_partition和window_reverse函数,用于将输入特征分割成窗口和将窗口合并回原始特征。这是Swin Transformer的关键步骤之一,利用窗口机制来提高计算效率。
WindowAttention类实现了基于窗口的多头自注意力机制(W-MSA),支持相对位置偏置。它定义了查询、键、值的线性变换,并计算自注意力权重。相对位置偏置通过一个参数表实现,利用相对位置索引来增强模型的表示能力。
SwinTransformerBlock类是Swin Transformer的基本构建块,包含一个窗口注意力层和一个前馈网络(FFN)。它支持循环移位以实现SW-MSA(Shifted Window Multi-Head Self-Attention),并通过残差连接和层归一化来增强模型的稳定性。
PatchMerging类用于将特征图的补丁合并,减少特征图的分辨率,并增加通道数。这个过程是Swin Transformer中下采样的关键步骤。
BasicLayer类构建了一个Swin Transformer的基本层,包含多个Swin Transformer块,并在必要时进行下采样。它还计算了SW-MSA的注意力掩码。
PatchEmbed类负责将输入图像分割成补丁并进行嵌入。它使用卷积层将图像转换为补丁表示,并可选择性地应用归一化。
SwinTransformer类是整个模型的主类,负责构建和组织所有层。它接收输入图像,经过补丁嵌入、多个基本层和归一化层,最终输出特征图。
最后,定义了update_weight函数用于更新模型权重,并提供了SwinTransformer_Tiny函数用于创建一个小型的Swin Transformer模型实例,支持加载预训练权重。
整体而言,该文件实现了Swin Transformer的完整结构,提供了多种可配置参数,适用于不同的计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式