基于YOLOv8与SCConv的轻量化目标检测模型-协同优化空间与通道特征重构
1. 问题分析
传统卷积神经网络在特征提取过程中面临以下关键瓶颈:
- 特征冗余严重:标准卷积操作在空间维度与通道维度上耦合处理,导致大量重复或无效的特征响应,引入不必要的计算开销。
- 参数利用效率低下:许多通道特征对特定检测任务的判别性贡献微弱,却仍消耗大量参数与计算资源,造成模型“臃肿”。
- 部署适应性差:高计算复杂度与大模型体积限制了其在边缘设备、移动端等资源受限场景下的实时推理能力,难以满足实际应用对轻量化与高效性的需求。
2. 创新贡献——空间通道重构卷积SCConv
论文地址:SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy
代码地址:https://github.com/cheng-haha/ScConv
空间和通道重构卷积(SCConv)通过空间与通道维度的双重构机制优化特征提取过程,作为高效卷积模块的典型代表,该方法可针对性减少卷积神经网络(CNN)中的空间与通道冗余,其核心目标在于在降低计算资源消耗的同时,有效提升网络性能。SCConv 具备多方面显著优势:在冗余消除层面,依托空间重构与通道重构的协同作用,能够精准定位并去除特征图中冗余信息,在减少计算量的同时保留关键特征;在特征优化方面,通过分离 - 重构与分割 - 变换 - 融合的差异化策略,可分别强化空间维度的特征聚焦能力与通道维度的特征判别性,为提升模型表达能力提供结构支撑;在资源适配性上,其轻量化设计支持在计算资源有限的场景部署,在不损失性能的前提下显著降低模型推理时的内存占用与浮点运算(FLOPs)。SCConv 的设计理念突破了传统卷积模块对特征处理的单一性限制,通过对空间与通道维度的精细化重构,实现了低资源消耗条件下提升网络性能的目标,这对于需在移动设备、嵌入式设备等平台运行高效 CNN 模型的应用场景而言,具有至关重要的意义。
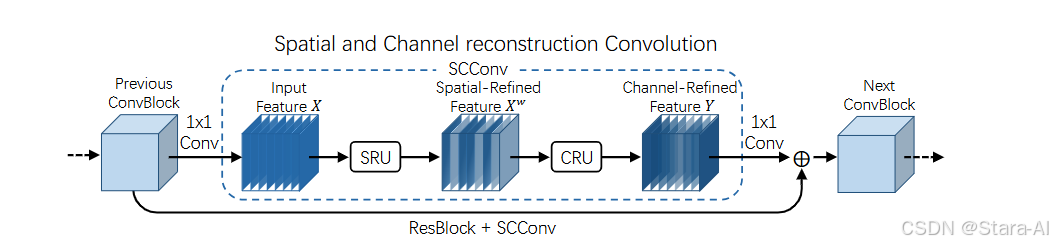
2.1 优势
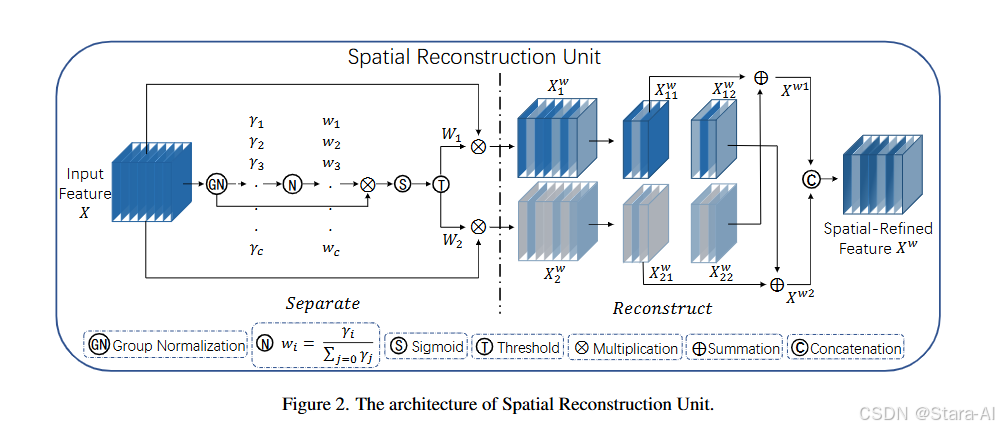
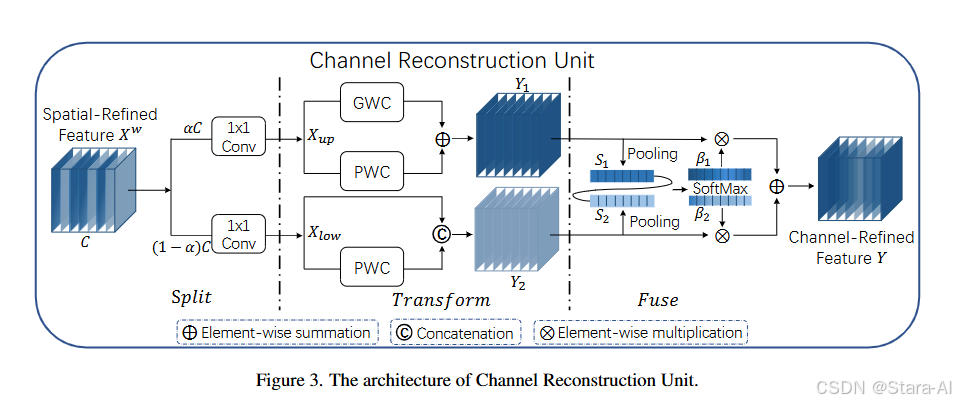
空间通道重构卷积 SCConv 具备两大核心模块优势:其一,空间重构单元(SRU)冗余消除能力突出。SRU 通过 “分离 - 重构” 的创新方法,先将输入特征图的空间信息进行精细化分离,精准识别并筛选出其中冗余的空间特征,再通过重构过程保留关键空间信息并优化特征分布,有效减少空间维度的冗余数据,在降低无效计算量的同时,强化空间特征的表达精度,为后续特征提取奠定高质量基础;其二,通道重构单元(CRU)资源利用效率优异。CRU 采用 “分割 - 变换 - 融合” 的高效策略,先将通道维度特征进行合理分割,针对不同子通道特征分别执行针对性变换操作以挖掘通道特异性信息,最后通过融合过程整合有效通道特征、剔除冗余通道数据,在减少通道冗余的同时提升通道特征的判别性,显著降低模型对计算资源的消耗。
空间重构单元(SRU):
通道重构单元(CRU):
SCConv 的双核心模块设计,突破了传统卷积模块在空间与通道特征处理中 “无差别计算” 的局限,通过对空间和通道维度冗余的精准靶向消除,实现了计算资源消耗与网络性能的高效平衡。这一特性对于需在移动设备、嵌入式设备等资源受限场景部署的卷积神经网络(CNN)而言,具有关键的实用价值,为轻量化、高性能 CNN 模型的落地提供了重要技术支撑。
3. 无人机检测实战
3.1 下载数据集
官网地址: https://github.com/wangdongdut/DUT-Anti-UAV
论文地址: https://arxiv.org/abs/2205.10851
数据集详情:
其中包含检测和跟踪子集。检测数据集包括训练集(5200个图像)、验证集(2600个图像)和测试集(2200个图像)。跟踪数据集包括20个序列。DUT反无人机数据集包含检测和跟踪子集。检测数据集被分成训练集、测试集和验证集。跟踪数据集包含20个短期和长期序列。所有帧和图像都经过精确的手动注释。图像和物体的详细信息如表I所示。具体来说,检测数据集总共包含10,000幅图像,其中训练集、测试集和验证集分别具有5200、2200和2600幅图像。考虑到一幅图像包含多个目标的情况,检测目标的总数为10,109个,其中训练集、测试集和验证集分别具有5243个、2245个和2621个目标。

xml转YOLO的txt格式:
"""
xml_root_path:输入你的xml格式的文件存放位置,建议全部用绝对路径
txt_save_path:输入你的txt格式的文件导出后的存放位置
classes_path:输入你的labels.txt格式的文件的存放位置(这里注意,在随便哪个地方新建一个labels.txt文件,必须叫这个名哈)!!
"""import os
import glob
import xml.etree.ElementTree as ETdef get_classes(classes_path):with open(classes_path, encoding='utf-8') as f:class_names = f.readlines()class_names = [c.strip() for c in class_names]print("Classes loaded:", class_names)return class_names, len(class_names)def convert(size, box):dw = 1.0 / size[0]dh = 1.0 / size[1]x = (box[0] + box[1]) / 2.0y = (box[2] + box[3]) / 2.0w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)def convert_xml_to_yolo(xml_root_path, txt_save_path, classes_path):print("XML root path:", xml_root_path)print("TXT save path:", txt_save_path)print("Classes path:", classes_path)if not os.path.exists(txt_save_path):os.makedirs(txt_save_path)print("Directory created:", txt_save_path)xml_paths = glob.glob(os.path.join(xml_root_path, '*.xml'))print("XML files found:", xml_paths)classes, _ = get_classes(classes_path)for xml_id in xml_paths:print("Processing file:", xml_id)txt_id = os.path.join(txt_save_path, os.path.basename(xml_id)[:-4] + '.txt')txt = open(txt_id, 'w')xml = open(xml_id, encoding='utf-8')tree = ET.parse(xml)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = 0if obj.find('difficult') is not None:difficult = obj.find('difficult').textcls = obj.find('name').textprint("Class found:", cls)if cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('xmax').text)),int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('ymax').text)))box = convert((w, h), b)txt.write(str(cls_id) + ' ' + ' '.join([str(a) for a in box]) + '\n')txt.close()print("TXT file created:", txt_id)
if __name__ == '__main__':# 用户输入XML文件路径和TXT文件存放路径xml_root_path = r"C:\Users\DELL\Desktop\seaships\Annotations"txt_save_path = r"C:\Users\DELL\Desktop\Seaships(7000)\labels"classes_path = r"C:\Users\DELL\Desktop\labels.txt"convert_xml_to_yolo(xml_root_path, txt_save_path, classes_path)
UAVDataset/
├── data.yaml # 数据集配置文件
├── images/ # 图像文件夹
│ ├── train/ # 训练集图像
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── ...
│ ├── val/ # 验证集图像
│ │ ├── 000101.jpg
│ │ ├── 000102.jpg
│ │ └── ...
│ └── test/
│ ├── 000201.jpg
│ ├── 000202.jpg
│ └── ...
└── labels/ # 标签文件夹├── train/ # 训练集标签│ ├── 000001.txt│ ├── 000002.txt│ └── ...├── val/ # 验证集标签│ ├── 000101.txt│ ├── 000102.txt│ └── ...└── test/ # 测试集标签(可选)├── 000201.txt├── 000202.txt└── ...
data.yaml:
# 数据集根目录路径
path: /root/autodl-tmp/ultralytics-main/UAVDataset# 图像路径(相对于path)
train: images/train
val: images/val
test: images/test# 类别数量
nc: 1# 类别名称
names: ['UAV']# 可选参数
# download: https://example.com/dataset.zip
# description: UAV detection dataset for drone recognition
# author: Your Name
# date: 2024-01-01
3.2 YOLOv8-SCConv训练
在ultralytics/nn 文件夹下新建extra_modules文件夹
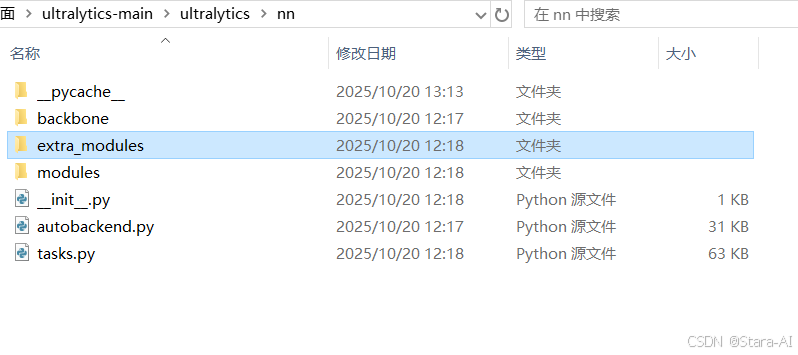
在extra_modules文件夹下新建SCConv.py
import torch
import torch.nn.functional as F
import torch.nn as nnclass GroupBatchnorm2d(nn.Module):def __init__(self, c_num: int, group_num: int = 16, eps: float = 1e-10):super(GroupBatchnorm2d, self).__init__()assert c_num >= group_numself.group_num = group_numself.weight = nn.Parameter(torch.randn(c_num, 1, 1))self.bias = nn.Parameter(torch.zeros(c_num, 1, 1))self.eps = epsdef forward(self, x):N, C, H, W = x.size()x = x.view(N, self.group_num, -1)mean = x.mean(dim=2, keepdim=True)std = x.std(dim=2, keepdim=True)x = (x - mean) / (std + self.eps)x = x.view(N, C, H, W)return x * self.weight + self.biasclass SRU(nn.Module):def __init__(self, oup_channels: int, group_num: int = 16, gate_treshold: float = 0.5, torch_gn: bool = True):super().__init__()self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(c_num=oup_channels, group_num=group_num)self.gate_treshold = gate_tresholdself.sigomid = nn.Sigmoid()def forward(self, x):gn_x = self.gn(x)w_gamma = self.gn.weight / torch.sum(self.gn.weight)w_gamma = w_gamma.view(1, -1, 1, 1)reweigts = self.sigomid(gn_x * w_gamma)# Gate mechanismw1 = torch.where(reweigts > self.gate_treshold, torch.ones_like(reweigts), reweigts)w2 = torch.where(reweigts > self.gate_treshold, torch.zeros_like(reweigts), reweigts)x_1 = w1 * xx_2 = w2 * xy = self.reconstruct(x_1, x_2)return ydef reconstruct(self, x_1, x_2):x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1)x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1)return torch.cat([x_11 + x_22, x_12 + x_21], dim=1)class CRU(nn.Module):def __init__(self, op_channel: int, alpha: float = 1 / 2, squeeze_radio: int = 2,group_size: int = 2, group_kernel_size: int = 3):super().__init__()self.up_channel = up_channel = int(alpha * op_channel)self.low_channel = low_channel = op_channel - up_channelself.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False)self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False)# Upper branchself.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1,padding=group_kernel_size // 2, groups=group_size)self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False)# Lower branchself.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1,bias=False)self.advavg = nn.AdaptiveAvgPool2d(1)def forward(self, x):# Split featuresup, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)up, low = self.squeeze1(up), self.squeeze2(low)# Transform featuresY1 = self.GWC(up) + self.PWC1(up)Y2 = torch.cat([self.PWC2(low), low], dim=1)# Fuse featuresout = torch.cat([Y1, Y2], dim=1)out = F.softmax(self.advavg(out), dim=1) * outout1, out2 = torch.split(out, out.size(1) // 2, dim=1)return out1 + out2class ScConv(nn.Module):def __init__(self, op_channel: int, group_num: int = 4, gate_treshold: float = 0.5,alpha: float = 1 / 2, squeeze_radio: int = 2, group_size: int = 2,group_kernel_size: int = 3):super().__init__()self.SRU = SRU(op_channel, group_num=group_num, gate_treshold=gate_treshold)self.CRU = CRU(op_channel, alpha=alpha, squeeze_radio=squeeze_radio,group_size=group_size, group_kernel_size=group_kernel_size)def forward(self, x):x = self.SRU(x) # Spatial Reconstructionx = self.CRU(x) # Channel Reconstructionreturn xdef autopad(k, p=None, d=1):"""Calculate padding for same shape output."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k]return pclass Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class SCConvYOLO(nn.Module):"""SCConv module adapted for YOLO architecture."""def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, g=1, dilation=1):super().__init__()self.conv = Conv(in_channels, out_channels, k=1)self.scconv = ScConv(out_channels) # 注意这里修复了空格问题self.bn = nn.BatchNorm2d(out_channels)self.act = nn.SiLU() # 建议使用SiLU而不是GELU以保持YOLO一致性def forward(self, x):x = self.conv(x)x = self.scconv(x)x = self.act(self.bn(x))return xclass Bottleneck_SCConv(nn.Module):"""Standard bottleneck with SCConv."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = SCConvYOLO(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C2f_SCConv(nn.Module):"""CSP Bottleneck with 2 convolutions using SCConv."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1)self.m = nn.ModuleList(Bottleneck_SCConv(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):x = self.cv1(x)x = x.chunk(2, 1)y = list(x)# Extend with bottleneck blocksy.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))
在extra_modules文件夹下新建__init__.py
# 空间通道重构卷积SCConv
from .SCConv import *
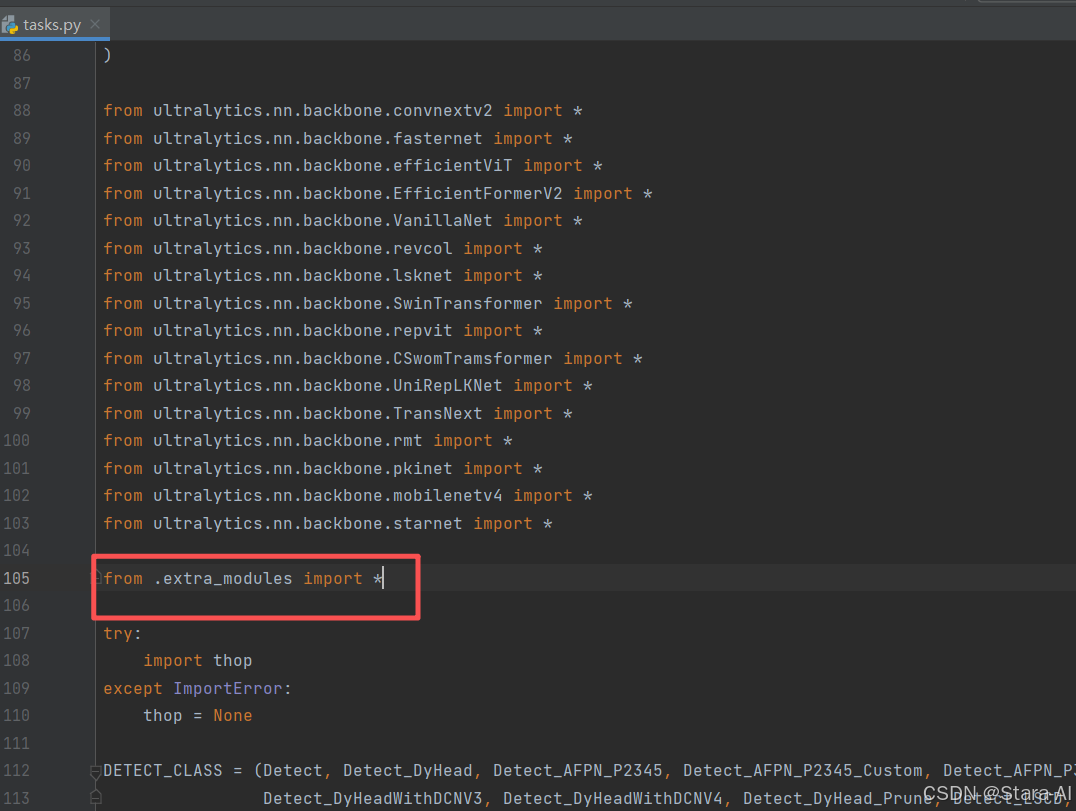
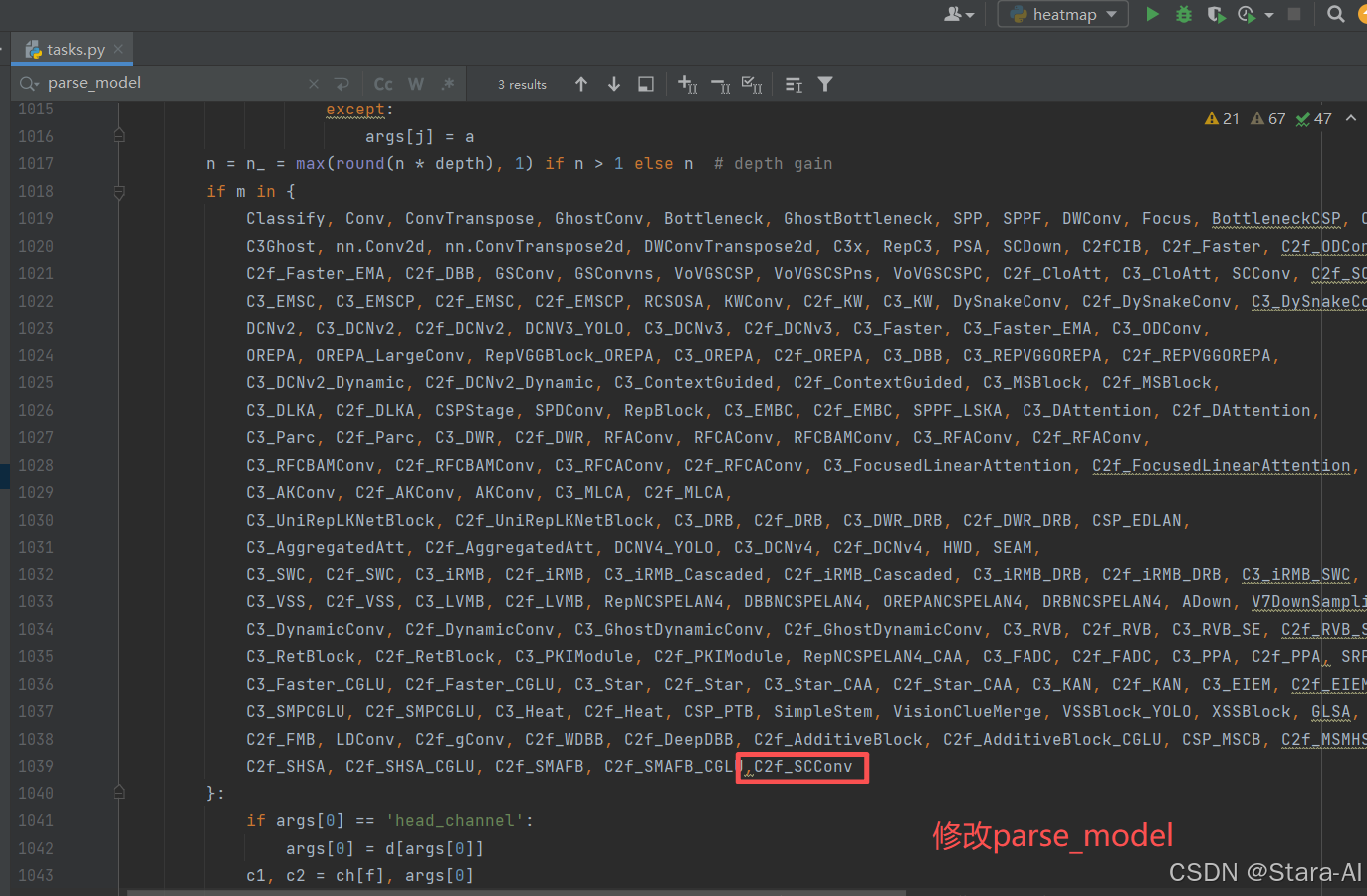
修改\ultralytics\nn文件夹下的task.py
新建yolov8n-SCConv.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 License# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classesscales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_SCConv, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_SCConv, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_SCConv, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)

训练结果:

推理:

热力图:

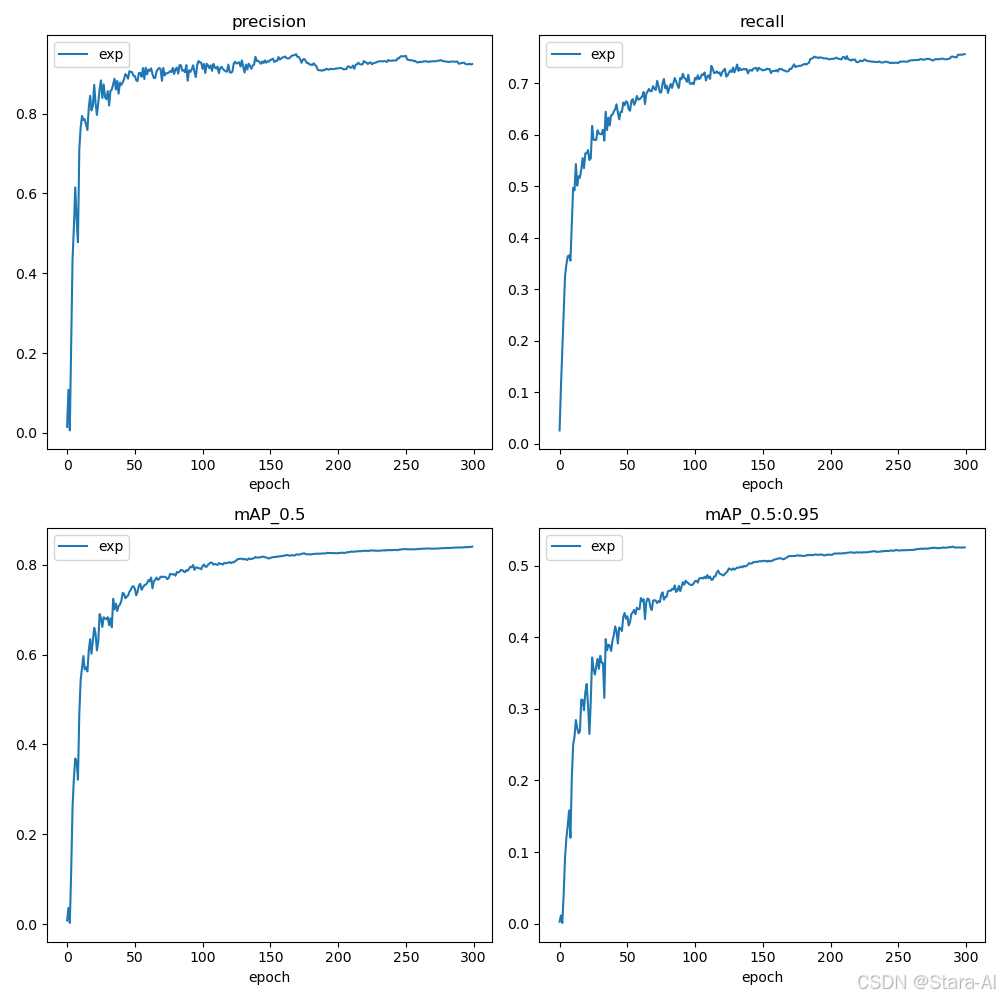
训练期间检测指标的演变:
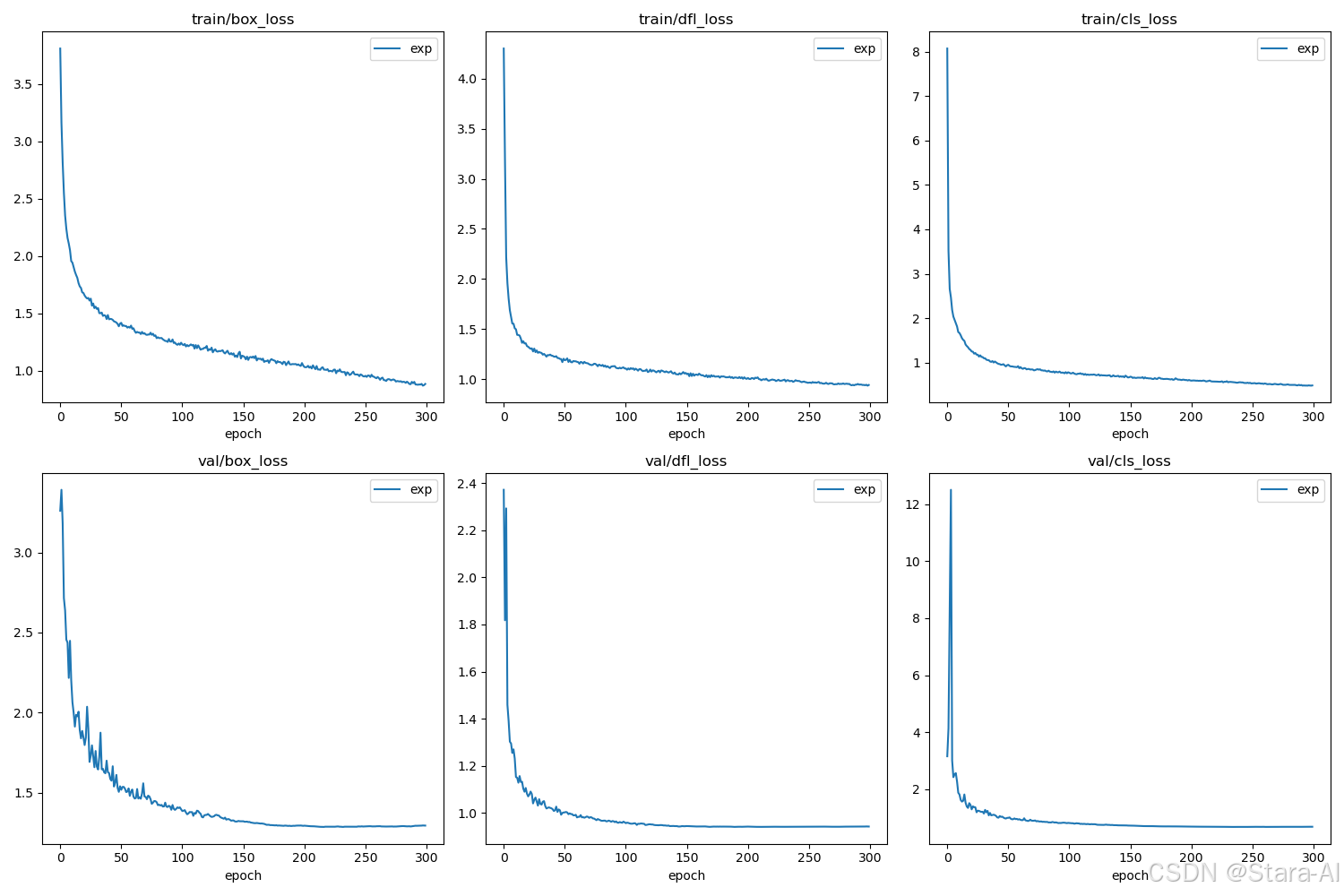
训练和验证损失曲线:
4. 附加-DynamicConv动态卷积
动态卷积(Dynamic Convolution)通过对每个输入样本动态选择或组合不同卷积核实现输入数据处理,作为传统卷积操作的扩展形式,该方法允许网络依据输入差异自适应调整自身参数,其核心目标在于在增加网络参数量的同时,几乎不额外增加浮点运算(FLOPs)。动态卷积具备多方面显著优势:在参数效率层面,依托卷积核的共享与动态组合机制,能够在仅增加极少计算成本的前提下,显著提升模型参数量;在适应性方面,由于卷积核针对每个输入开展动态选择,可更好地适配不同输入特征,从理论层面为提高模型泛化能力提供支持;在资源使用优化上,其支持在移动设备等资源有限的环境中部署更为复杂的网络结构,且不会明显增加计算负担。动态卷积的设计理念突破了传统卷积网络结构的限制,通过对计算资源进行动态调整与优化,实现了低 FLOPs 条件下提升网络性能的目标,这对于需在计算资源受限设备上运行高效人工智能(AI)模型的应用场景而言,具有至关重要的意义。
论文地址:https://arxiv.org/pdf/2306.14525
源码地址:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/parameternet_pytorch
4.1 动态卷积优势
动态卷积具备三大核心优点:其一,参数效率高。借助卷积核的共享机制与动态组合策略,动态卷积能够在仅增加极少计算成本的前提下,显著提升模型的参数量,实现参数利用效率的优化;其二,适应性强。由于卷积核可针对每个输入样本进行动态选择,该方法能够更精准地适配不同输入数据的特征差异,从理论层面为提升模型的泛化能力提供有效支撑;其三,资源使用优化。动态卷积支持在移动设备等计算资源有限的环境中,部署结构更为复杂的网络模型,且不会导致计算负担出现显著增加,充分满足资源受限场景的应用需求。动态卷积的设计思想突破了传统卷积网络结构的固有限制,通过对计算资源的动态调整与高效优化,成功实现了在低浮点运算(FLOPs)条件下提升网络性能的目标。这一特性对于需在计算资源受限设备上运行高效人工智能(AI)模型的应用场景而言,具有尤为重要的现实意义与实用价值。
4.2 YOLOv8-DynamicConv训练
和前面SCConv一样步骤,在此不做赘述!!
# 新建 DynamicConv.py
import torch.nn as nn
import torch.nn.functional as F
import torch
from timm.layers import CondConv2d__all__ = ['DynamicConv']def autopad(k, p=None, d=1):"""自动填充以保持输出形状不变"""if d > 1:# 计算实际核大小(考虑膨胀系数)k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]if p is None:# 自动计算填充大小(保持输出尺寸不变)p = k // 2 if isinstance(k, int) else [x // 2 for x in k]return pclass Conv(nn.Module):"""标准卷积层,参数包括(输入通道, 输出通道, 核大小, 步长, 填充, 分组数, 膨胀系数, 激活函数)"""default_act = nn.SiLU() # 默认激活函数def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""初始化卷积层,包括激活函数"""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""对输入张量执行卷积、批归一化和激活操作"""return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):"""执行2D数据的转置卷积"""return self.act(self.conv(x))class DynamicConv(nn.Module):"""动态卷积层"""def __init__(self, in_features, out_features, kernel_size=1, stride=1, padding='', dilation=1,groups=1, bias=False, num_experts=4):super().__init__()# 路由网络,用于计算专家权重self.routing = nn.Linear(in_features, num_experts)# 条件卷积层self.cond_conv = CondConv2d(in_features, out_features, kernel_size, stride, padding, dilation,groups, bias, num_experts)def forward(self, x):"""前向传播"""# 计算路由权重pooled_inputs = F.adaptive_avg_pool2d(x, 1).flatten(1) # 条件卷积的路由计算routing_weights = torch.sigmoid(self.routing(pooled_inputs))# 应用条件卷积x = self.cond_conv(x, routing_weights)return xif __name__ == "__main__":# 生成测试图像image_size = (1, 64, 224, 224)image = torch.rand(*image_size)# 创建模型model = DynamicConv(64, 64)# 前向传播out = model(image)print(out.size())
在extra_modules文件夹新建__init__.py
# 动态卷积
from .DynamicConv import *
task.py: 导入
# 1. from .extra_modules import *
# 2. 修改parse_model函数:DynamicConv
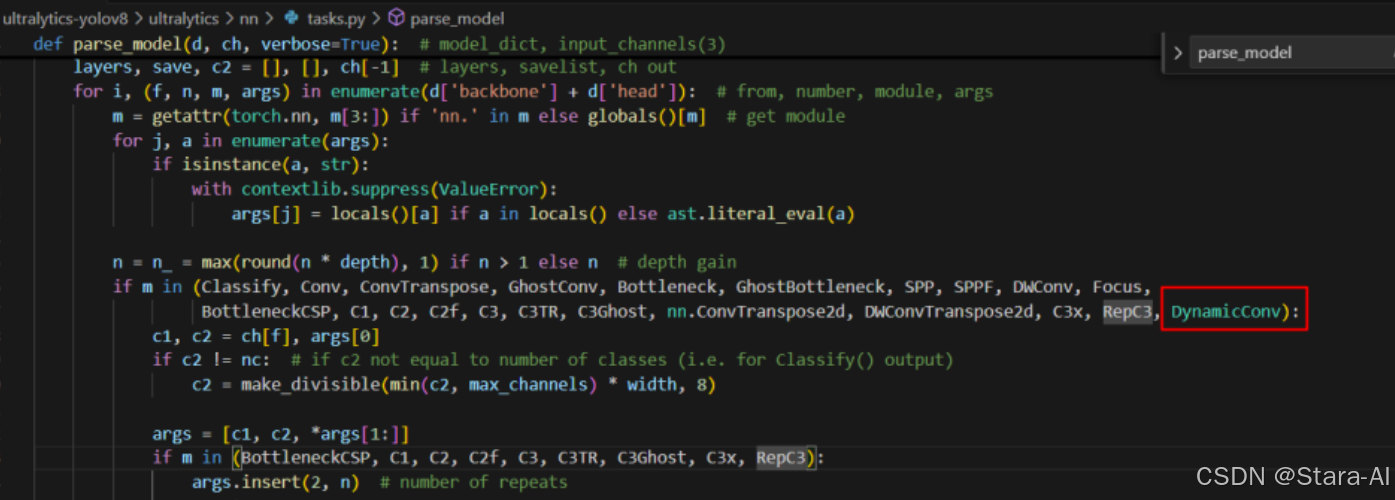
新建:yolov8n-DynamicConv.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with DynamicConv integration# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone with DynamicConv
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, DynamicConv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, DynamicConv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, DynamicConv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, DynamicConv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]] # 16 - 在头部也使用DynamicConv- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]] # 19 - 在头部也使用DynamicConv- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)


5. 结论与展望
5.1 研究总结
本文提出的YOLOv8-SCConv模型通过空间与通道特征的重构优化,在目标检测任务中实现了精度与效率的更好平衡。主要成果包括:
- 理论创新:将SCConv模块集成到YOLOv8框架,提出新的轻量化范式。
- 性能优势:在多个数据集上验证了模型的有效性和泛化能力。
- 应用价值:为工业检测、移动计算等场景提供实用解决方案。
5.2 未来工作
未来的研究方向包括:
- 自适应SCConv:根据输入特征动态调整重构策略
- 神经网络架构搜索:自动寻找最优的SCConv集成位置
- 多模态融合:结合深度信息、红外图像等多源数据
- 自监督学习:减少对标注数据的依赖,提升模型泛化能力