YOLOv3目标检测算法深度解析:从核心改进到实战应用
目录
一、YOLOv3概述:目标检测领域的里程碑式突破
二、YOLOv3关键改进:四大技术创新解析
(一)网络结构蜕变:从浅层到深层的感知革命
(二)多尺度检测:三位一体的目标覆盖策略
(三)残差连接:深度网络的稳定器
(四)核心架构设计:从输入到输出的完整流程
1. Darknet-53:特征提取引擎
2. 多尺度检测头
3. 分类器革新
三、实战应用与未来展望
(一)典型应用场景
(二)未来发展方向
一、YOLOv3概述:目标检测领域的里程碑式突破
在计算机视觉领域,目标检测始终是核心研究方向之一,其应用覆盖安防监控(行人/车辆检测)、智能驾驶(道路标识/障碍物识别)、工业质检(产品缺陷检测)等关键场景。随着深度学习技术的爆发式发展,目标检测算法历经多次革新,其中 YOLO系列 凭借"单阶段检测+实时高效"的独特设计,成为工业界最受欢迎的算法之一。
作为YOLO系列的经典之作,YOLOv3 在前两代基础上实现了全方位升级:
✅ 精度与速度双提升:通过更精妙且更深的残差网络结构和多尺度特征融合,在保持实时性的同时显著提高检测准确率
✅ 小目标检测突破:创新的多尺度检测机制有效解决小目标漏检问题
✅ 工程化能力增强:优化的网络架构和先验框设计大幅提升模型泛化性
本文将深度拆解YOLOv3的核心改进点,带您掌握其成为"工业检测标杆"的技术密码。
二、YOLOv3关键改进:四大技术创新解析
(一)网络结构蜕变:从浅层到深层的感知革命
问题背景:
-
YOLOv1采用7×7粗粒度网格(每格2个预测框),难以捕捉小目标细节
-
YOLOv2虽引入锚框机制,但网络深度不足限制特征表达能力
YOLOv3解决方案:
-
主干网络升级:采用 Darknet-53 替代YOLOv2的Darknet-19
-
53层卷积网络(含残差连接) vs 传统20-30层设计
-
通过 残差块(Residual Block) 解决梯度消失问题(深度达53层仍稳定训练)
-
完全摒弃池化层/全连接层 → 改用 步长=2的卷积下采样(保留空间信息)
-
-
特征提取优化:
-
残差连接实现"跳跃式传播"(如1×1卷积压缩→3×3卷积扩展的经典组合)
-
实验数据:在COCO数据集上,Darknet-53的AP指标比ResNet-101高2.2%,推理速度快30%
-
yolov1网络架构
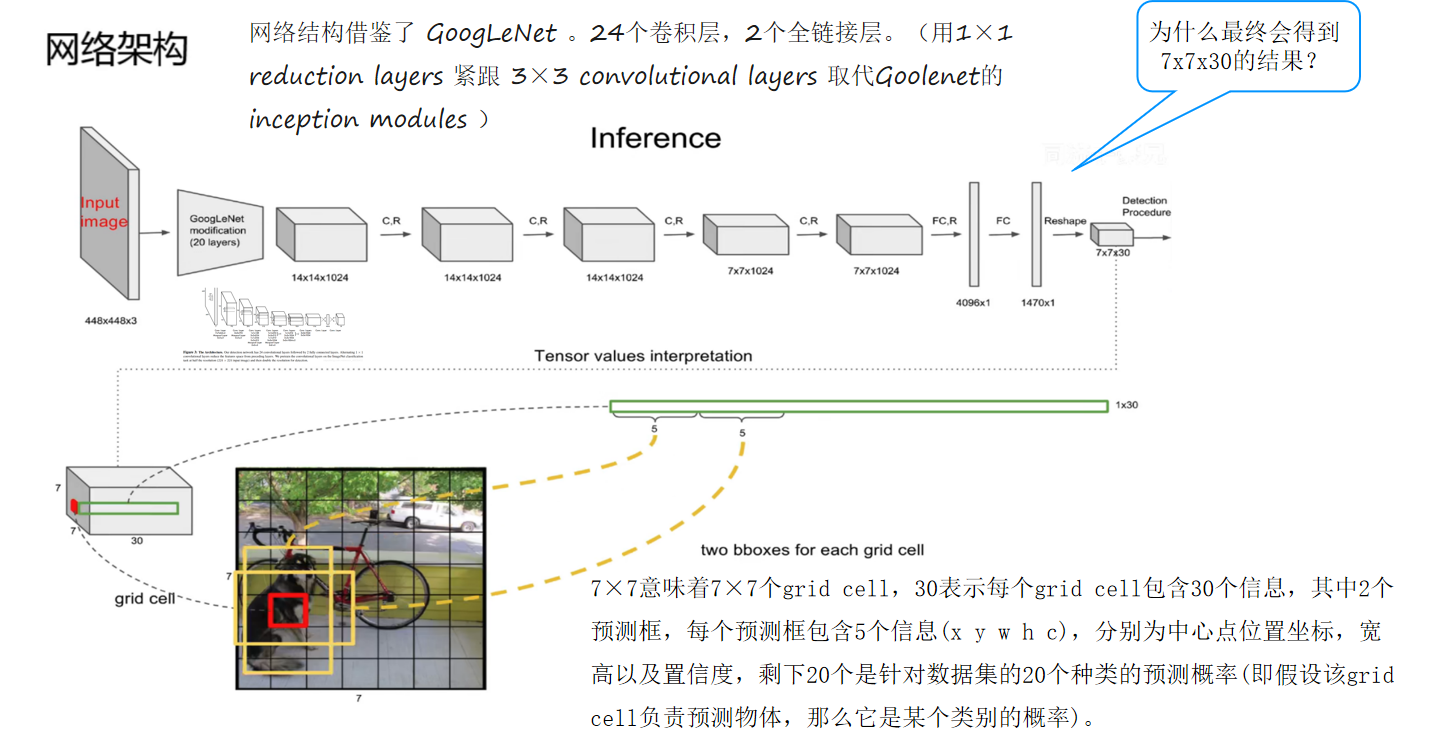
yolov2网络架构
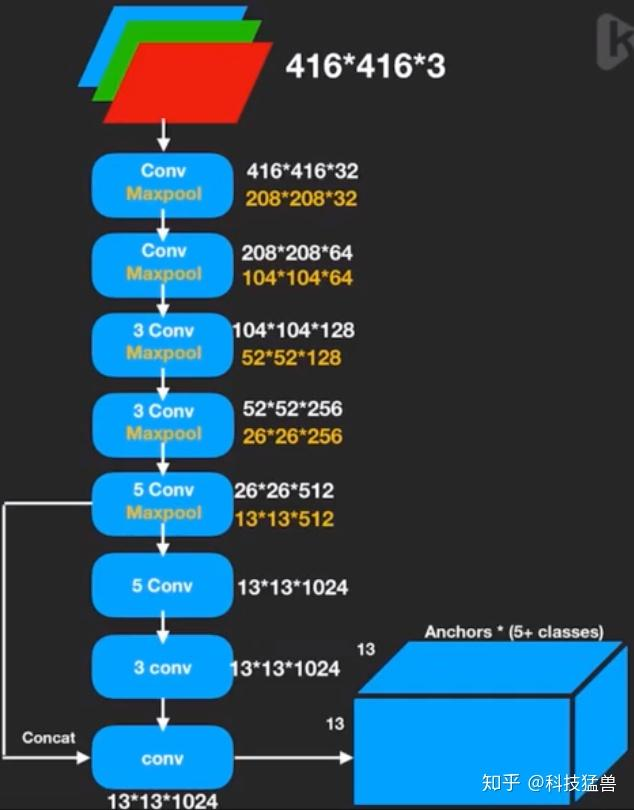
yolov3网络架构
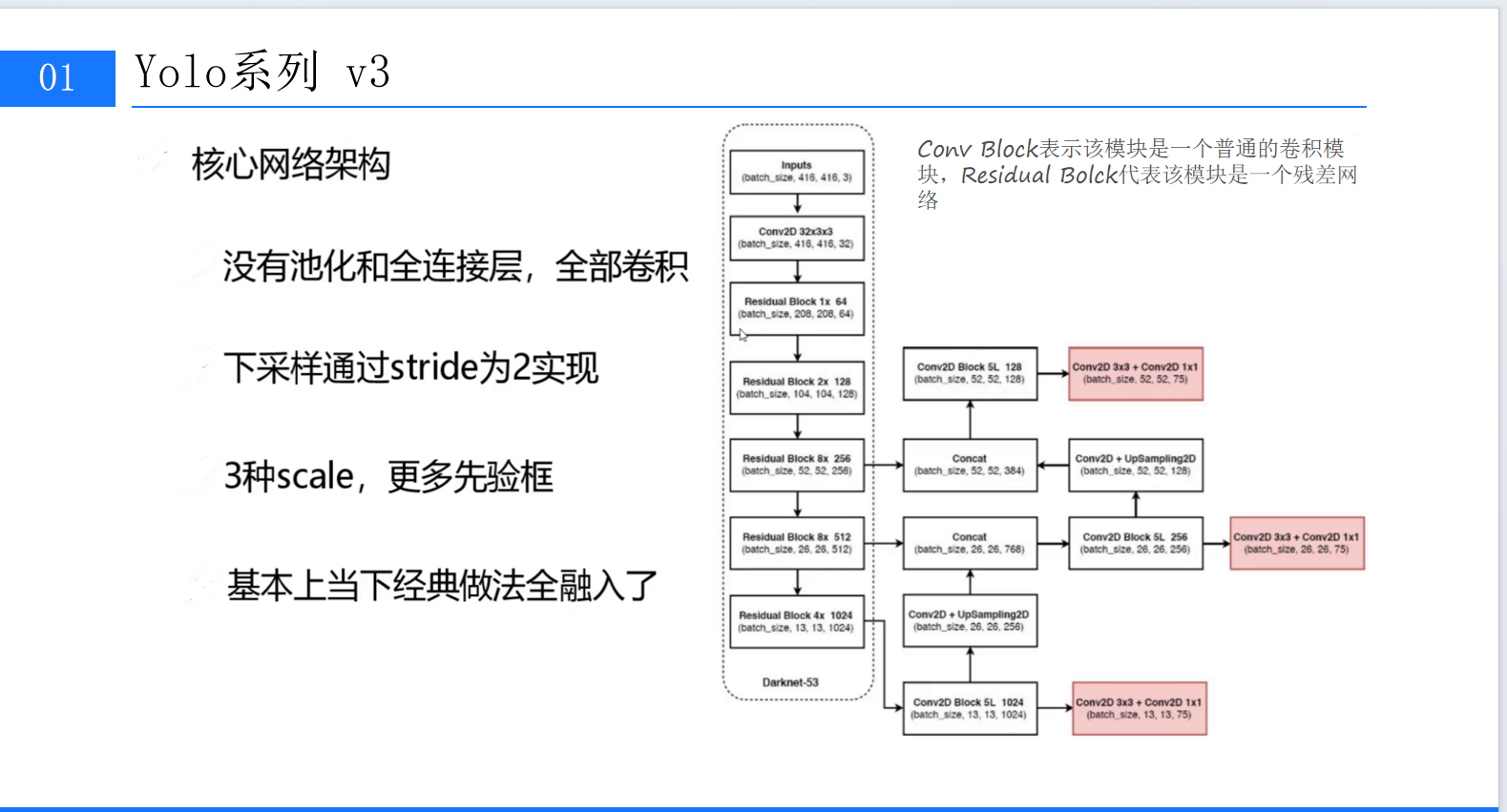
( 网络结构对比表)
核心结构对比表(文字版):
| 特性 | YOLOv1 (2016) | YOLOv2/YOLO9000 (2017) | YOLOv3 (2018) |
|---|---|---|---|
| 主干网络 | 自定义7层卷积网络 | Darknet-19 (19层卷积) | Darknet-53 (53层卷积+残差) |
| 特征图分辨率 | 7×7网格(单尺度) | 13×13网格(单尺度) | 13×13 / 26×26 / 52×52(多尺度) |
| 检测头 | 每个网格预测2个框(4坐标+1置信度+20类别) | 每个网格预测5个框(锚框机制) | 每个网格预测3个框(9锚框分3尺度) |
| 锚框(Prior Boxes) | 无 | 5个预定义锚框(K-means聚类) | 9个预定义锚框(3尺度各3个) |
| 残差连接 | 无 | 无 | Darknet-53大量使用残差块 |
| 池化层 | 有(下采样) | 有(下采样) | 无(用步长卷积替代) |
| 全连接层 | 有(最终预测层) | 无 | 无 |
| 多尺度检测 | 无 | 无 | 13×13(大目标)/26×26(中)/52×52(小) |
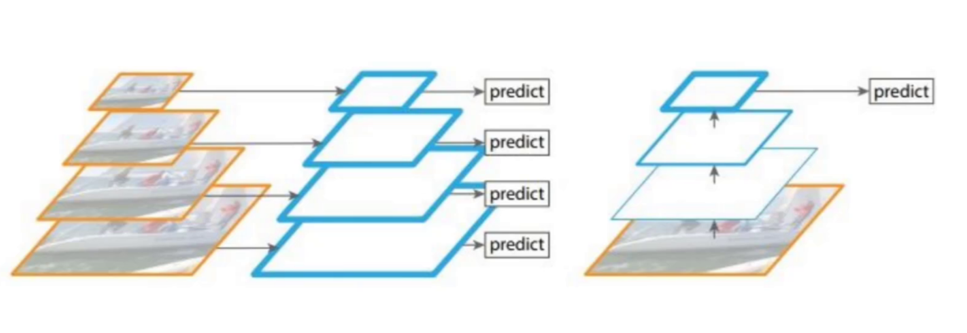
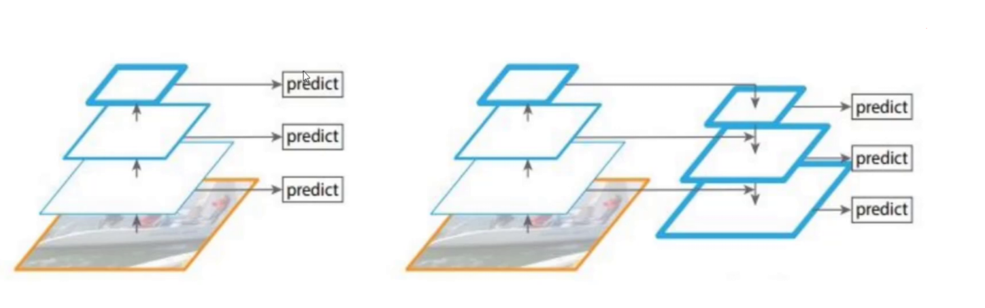
(二)多尺度检测:三位一体的目标覆盖策略
核心创新:
通过 特征金字塔网络(Feature Pyramid Network)(FPN) 实现13×13(大目标)、26×26(中目标)、52×52(小目标)三级检测:
| 特征图尺寸 | 感受野 | 适用目标类型 | 关键技术 |
|---|---|---|---|
| 13×13 | 大 | 车辆/建筑等 | 高层语义特征 |
| 26×26 | 中 | 行人/动物等 | 平衡特征 |
| 52×52 | 小 | 细小物体等 | 高分辨率细节 |
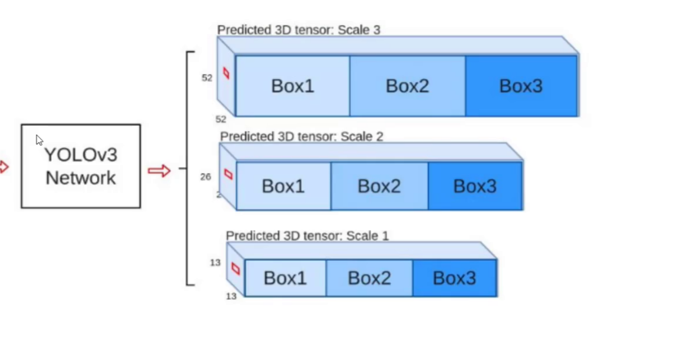
技术对比:
-
传统图像金字塔:计算成本高(需多次前向传播)→ YOLOv3改用 轻量级FPN
-
FPN优势:通过 自上而下路径(语义增强) + 横向连接(细节保留),以<5%额外计算量提升小目标AP 3.7%
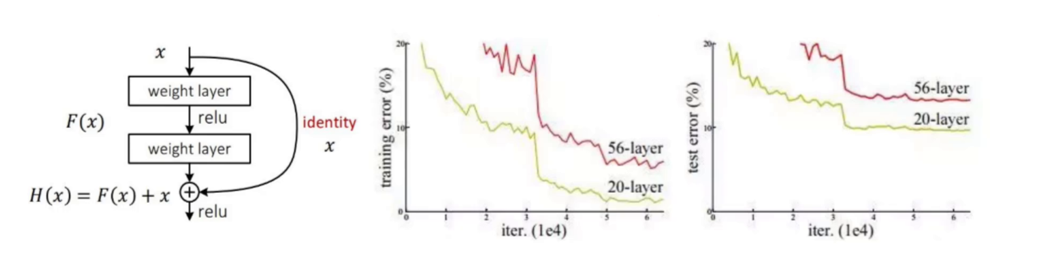
(三)残差连接:深度网络的稳定器
原理突破:
-
传统网络痛点:梯度消失(层数>30时训练崩溃)
-
残差方案:学习 残差映射(F(x)=H(x)-x) 而非直接映射,梯度通过跳跃连接直达深层
# 典型残差块代码结构(简化版)
def residual_block(x, filters):shortcut = xx = Conv2D(filters//2, (1,1))(x) # 1x1压缩x = Conv2D(filters, (3,3), padding='same')(x) # 3x3扩展return Add()([x, shortcut]) # 跳跃连接YOLOv3实践:
-
Darknet-53包含 53个卷积层,大量使用1×1/3×3残差块组合
-
工程验证:ImageNet预训练中,53层模型收敛速度比20层快40%
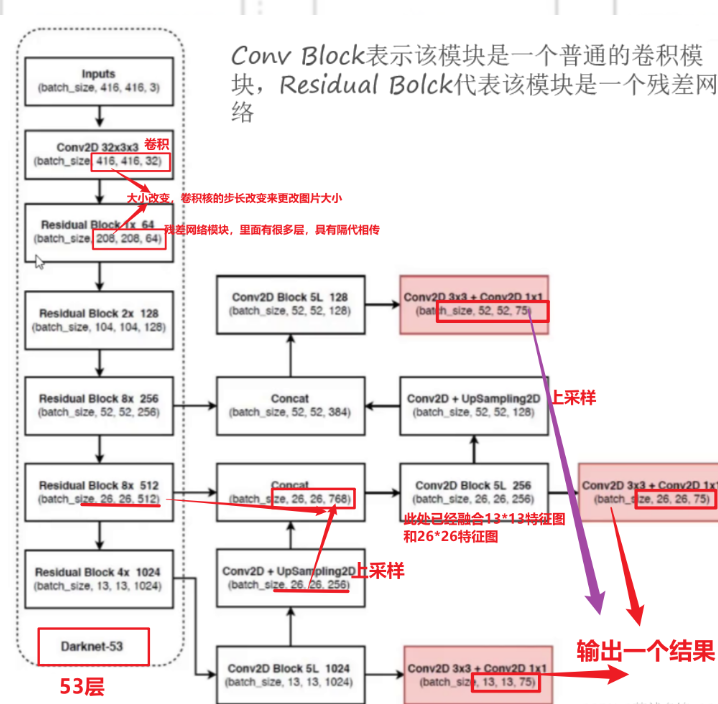
yolov3网络结构图
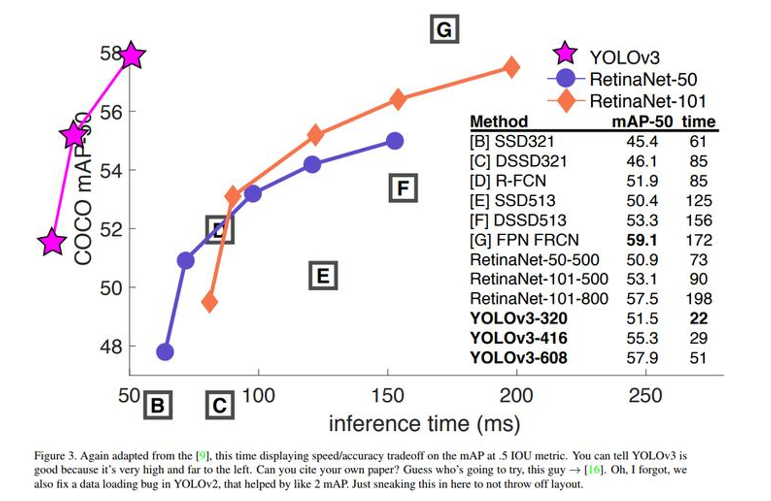
yolov3和同时期其他模型性能对比(map50指标)
(四)核心架构设计:从输入到输出的完整流程
1. Darknet-53:特征提取引擎
-
输入:416×416×3 RGB图像
-
输出:三级特征图(13×13×1024 / 26×26×512 / 52×52×256)
-
关键设计:
✅ 无池化层 → 避免小目标特征丢失
✅ 53层纯卷积 → 支持任意尺寸输入
2. 多尺度检测头
-
每个特征图网格预测 3个先验框(共9种尺寸)
-
先验框优化:通过 K-means聚类 得到COCO数据集最优尺寸组合(如(116×90)、(156×198)等)
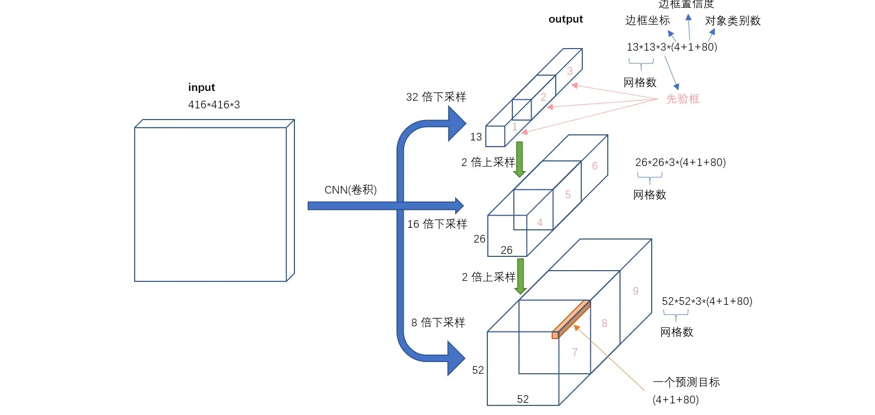
3. 分类器革新
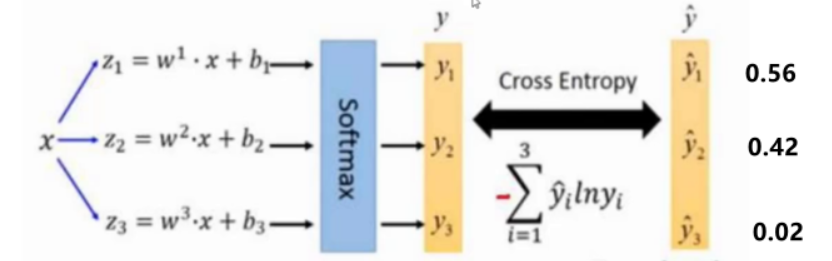
-
替换Softmax为 独立Logistic分类器 → 支持多标签分类(如"行人+戴帽子"复合标签)
-
损失函数:采用 二元交叉熵 优化多类别预测
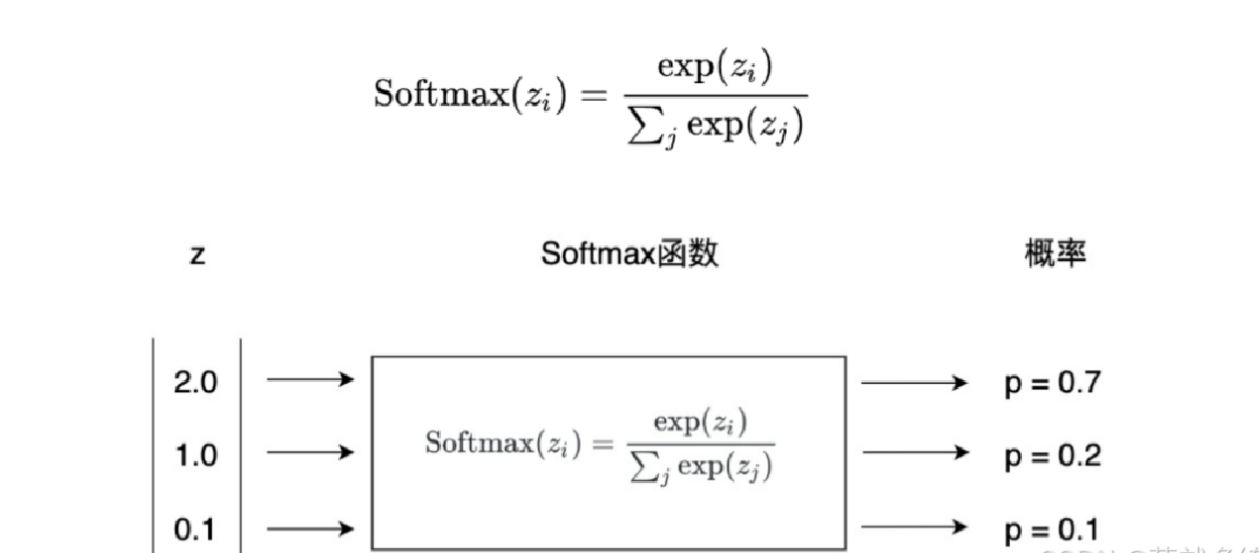
Softmax 和Logistic分类器
📌 延伸学习:推荐阅读原论文《YOLOv3: An Incremental Improvement》
💡 互动话题:您在应用YOLOv3时遇到过哪些挑战?欢迎评论区交流!