机器学习基础入门(第六篇):深度学习的兴起与神经网络基础
机器学习基础入门(第六篇):深度学习的兴起与神经网络基础
一、前言:深度学习的崛起
如果说机器学习是人工智能的“骨架”,那么**深度学习(Deep Learning)**就是它的“灵魂”。
深度学习的出现,使人工智能从“会识别”走向“会思考”,推动了图像识别、语音识别、自然语言处理等领域的突破性进展。
回顾人工智能的发展历程,我们大致可以分为三个阶段:
- 早期 AI(1950s–1980s):以逻辑推理和专家系统为主;
- 机器学习时代(1990s–2010s):以统计学习和特征工程为核心;
- 深度学习时代(2010s–至今):以多层神经网络为代表的“端到端”智能。
特别是在 2012 年,AlexNet 在 ImageNet 图像识别竞赛中一举夺冠,识别错误率比传统方法降低了近 10%。
从此,深度学习掀起了人工智能的新革命。

二、神经网络的起源与思想
1. 从生物神经元说起
神经网络(Neural Network)的灵感来自于人脑的神经元结构。
在生物学上,一个神经元(Neuron)接收来自其他神经元的输入信号,通过突触传递并进行加权求和,当信号强度超过某个阈值时就会“激活”,输出信号。
用数学形式表示,可以简化为:
y=f(∑iwixi+b)y = f(\sum_i w_i x_i + b) y=f(i∑wixi+b)
其中:
-−(xi):输入信号−(wi):连接权重−(b):偏置项−(f):激活函数(如Sigmoid、ReLU)−(y):输出结果−- (x_i):输入信号 - (w_i):连接权重 - (b):偏置项 - (f):激活函数(如 Sigmoid、ReLU) - (y):输出结果 - −(xi):输入信号−(wi):连接权重−(b):偏置项−(f):激活函数(如Sigmoid、ReLU)−(y):输出结果−
这种简单的结构,就是人工神经网络的基本单元——感知机(Perceptron)。
2. 单层感知机模型
感知机是由 Frank Rosenblatt 于 1958 年提出的,是最早的神经网络模型。
它的工作原理很简单:对输入特征进行加权求和,然后通过激活函数输出结果。
可以用来解决线性可分问题,比如判断一个点是否在某个平面的一侧。
感知机的学习过程,就是不断调整权重 (w_i),以最小化预测输出与真实标签之间的误差。
训练目标:
wi←wi+η(y−y^)xiw_i \leftarrow w_i + \eta (y - \hat{y})x_i wi←wi+η(y−y^)xi
其中 η 是学习率(learning rate)。
但感知机有一个重大局限:它只能处理线性问题。例如,著名的 XOR(异或)问题是非线性的,单层感知机无法解决。
3. 多层感知机(MLP)的出现
为了解决线性不可分问题,研究者引入了多层神经网络(Multi-Layer Perceptron, MLP)。
在输入层与输出层之间加入一个或多个隐藏层(Hidden Layer),通过非线性激活函数的组合,使得模型能够逼近任意复杂函数。
这就引出了一个重要定理:
通用逼近定理(Universal Approximation Theorem)
任意一个连续函数,都可以用一个足够大的两层神经网络近似表示。
这意味着——神经网络理论上可以拟合任何复杂关系。
三、神经网络的结构与原理
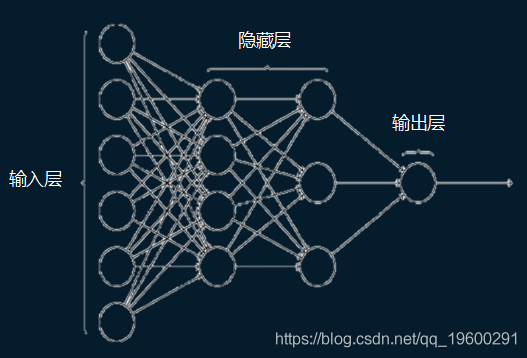
一个典型的前馈神经网络(Feedforward Neural Network)由三部分组成:
- 输入层(Input Layer):接收原始数据;
- 隐藏层(Hidden Layer):通过权重与激活函数提取特征;
- 输出层(Output Layer):输出最终预测结果。
数据从输入层流向输出层,不存在反馈连接,这就是“前馈”结构。
1. 前向传播(Forward Propagation)
模型接收输入数据 (x),逐层进行加权求和与激活运算,直到输出结果 ( \hat{y} )。
a(l)=f(W(l)a(l−1)+b(l))a^{(l)} = f(W^{(l)} a^{(l-1)} + b^{(l)}) a(l)=f(W(l)a(l−1)+b(l))
其中:
-
(a(l)):第l层的输出;(a^{(l)}):第 l 层的输出; (a(l)):第l层的输出;
-
(W(l))、(b(l)):第l层的权重与偏置;(W^{(l)})、(b^{(l)}):第 l 层的权重与偏置; (W(l))、(b(l)):第l层的权重与偏置;
-
(f):激活函数。(f):激活函数。 (f):激活函数。
2. 反向传播(Backpropagation, BP)
反向传播算法由 Rumelhart 等人在 1986 年提出,是训练深度神经网络的核心算法。
它的思想类似链式法则:从输出层向前计算每层参数的梯度,并利用梯度下降法更新权重。
核心目标:最小化损失函数(Loss Function)
L=1n∑(y−y^)2L = \frac{1}{n}\sum (y - \hat{y})^2 L=n1∑(y−y^)2
更新公式:
w←w−η∂L∂ww \leftarrow w - \eta \frac{\partial L}{\partial w} w←w−η∂w∂L
这样,网络不断调整参数,使得预测结果逐渐接近真实值。
四、激活函数的作用
如果神经网络中不使用激活函数,那么无论多少层,整个模型都相当于一个线性变换。
激活函数的作用就是引入非线性,让神经网络能够学习复杂关系。
常见激活函数包括:

其中 ReLU(Rectified Linear Unit) 几乎成为深度学习的“默认选择”,因为它能有效缓解梯度消失问题。
五、深度学习的兴起:从 MLP 到 CNN 与 RNN
1. 深度学习为何能崛起?
20 世纪 80–90 年代,神经网络一度陷入低谷(称为“AI 冬天”),主要原因是:
- 计算能力不足;
- 数据规模有限;
- 理论不成熟。
然而在 2010 年后,这些瓶颈被依次突破:
- GPU 并行计算能力的提升;
- 海量互联网数据的出现;
- 更高效的优化算法(如 Adam、Dropout、BatchNorm)。
于是,深度学习重新焕发了活力。
2. 卷积神经网络(CNN)
CNN(Convolutional Neural Network)是图像处理领域的核心模型。
它通过卷积层自动提取局部特征,代替了人工特征工程。
主要结构:
- 卷积层(Convolution Layer):提取局部特征;
- 池化层(Pooling Layer):降维、减少计算;
- 全连接层(Fully Connected Layer):进行分类或回归。
代表模型:
- LeNet(1998)
- AlexNet(2012)
- VGG、ResNet(2015+)
CNN 使机器在视觉任务上达到了接近人类的水平。
3. 循环神经网络(RNN)
RNN(Recurrent Neural Network)用于处理序列数据,如文本、语音、时间序列。
与前馈网络不同,RNN 的隐藏层之间存在“时间上的连接”,能保留上下文信息。
RNN 的变体:
- LSTM(长短期记忆网络):解决长期依赖问题;
- GRU(门控循环单元):结构更简洁,性能相近。
这些模型广泛用于机器翻译、语音识别、情感分析等任务。

六、现代深度学习的代表:Transformer 与大模型
2017 年,Google 提出了 Transformer 架构,论文题为《Attention is All You Need》。
Transformer 完全抛弃了循环结构,用 自注意力机制(Self-Attention) 建立序列中任意位置的依赖关系。
这使得模型在理解上下文和捕捉全局关系方面能力极强。
基于 Transformer 的模型包括:
- BERT(双向编码器表示)
- GPT 系列(生成式预训练模型)
- ViT(视觉 Transformer)
如今,大模型(如 GPT、Claude、Gemini)正是基于 Transformer 的架构发展而来。

七、深度学习的应用领域
深度学习几乎无处不在:
| 领域 | 应用示例 |
|---|---|
| 计算机视觉 | 图像识别、人脸检测、自动驾驶感知 |
| 自然语言处理 | 机器翻译、聊天机器人、情感分析 |
| 语音识别 | 智能助手、语音输入系统 |
| 医疗健康 | 疾病诊断、药物发现 |
| 金融科技 | 风控模型、欺诈检测 |
| 推荐系统 | 个性化推荐、广告优化 |
八、深度学习的挑战与未来
尽管深度学习已取得辉煌成就,但仍面临诸多挑战:
- 可解释性不足:模型复杂,难以解释预测原因;
- 数据依赖性强:需要大量高质量样本;
- 训练成本高:大模型训练耗时长、能耗大;
- 泛化能力问题:在分布外数据上表现不稳定。
未来的研究方向包括:
- 小样本学习(Few-shot Learning)
- 自监督学习(Self-supervised Learning)
- 多模态智能(Multimodal AI)
- 可解释人工智能(XAI)
- 神经符号融合(Neuro-Symbolic AI)
这些方向将推动人工智能向“理解与推理”层面迈进。

九、总结
本文系统介绍了深度学习的起源、神经网络的基本原理、关键结构、典型算法以及发展趋势。
深度学习的成功,不仅来源于模型结构的创新,更得益于计算力与数据的爆发。
从感知机到 Transformer,人工智能正在从“识别世界”走向“理解世界”。
多模态智能(Multimodal AI)*
- 可解释人工智能(XAI)
- 神经符号融合(Neuro-Symbolic AI)
这些方向将推动人工智能向“理解与推理”层面迈进。
九、总结
本文系统介绍了深度学习的起源、神经网络的基本原理、关键结构、典型算法以及发展趋势。
深度学习的成功,不仅来源于模型结构的创新,更得益于计算力与数据的爆发。
从感知机到 Transformer,人工智能正在从“识别世界”走向“理解世界”。
而对于我们而言,理解这些核心思想,就是走向真正的 AI 专业之路的第一步。