Linux线程互斥(三)
引入
线程互斥用于解决多个线程同时访问共享资源时可能出现的冲突问题。当多个线程需要操作同一共享资源(如全局变量、文件、数据库等)时,如果不加以控制,可能会导致数据不一致、逻辑错误等问题。
抢票系统
以一个抢票系统举例
#include<iostream>
#include<vector>
#include<unistd.h>
#include"Thread.hpp"using namespace ThreadModule;int g_tickets = 10000;
class ThreadData
{
public:ThreadData(int &tickets, const std::string &name): _tickets(tickets), _name(name), total(0){}~ThreadData(){}public:int &_tickets;//必须在构造函数的初始化列表中初始化std::string _name;int total;
};
void route(ThreadData *td)
{while(true){if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;td->total++;}else{break;}}
}const int num = 4;
int main()
{std::vector<Thread<ThreadData*>> threads;std::vector<ThreadData*> datas;//1.创建一批线程for(int i=0;i<num;i++){std::string name = "thread-" + std::to_string(i+1);ThreadData *td = new ThreadData(g_tickets, name);datas.push_back(td);threads.emplace_back(route, td, name);//将线程对象加入到线程容器中}//2.启动一批线程for(auto &th : threads){th.start();}//3.等待一批线程结束for(auto &th : threads){th.join();//std::cout << "wait thread done, thread is: " << th.name() << std::endl;}//4.输出统计数据for(auto &data : datas){std::cout << data->_name << " : " << data->total << std::endl;delete data;}return 0;
}
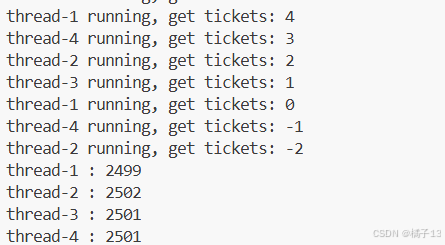
结果是每一个线程几乎均匀抢票,但是有线程抢到了负数的票。
为什么余票是负数?有些线程抢到多余的票
int g_tickets = 10000;//共享资源,没有保护的,对全局的tickets的判断不是原子的
void route(ThreadData *td)
{while(true){if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;td->total++;}else{break;}}
}
共享资源在被多个线程访问的时候,没有被保护,并且本身操作不具有原子性。
可能tickets==1但是判断的时候,让很多线程进入了抢票逻辑。
if(td->_tickets > 0) // 步骤1:判断票是否大于0
{usleep(1000); // 步骤2:休眠(放大并发问题)td->_tickets--; // 步骤3:票减1
}
这三步操作不是一个整体,多线程环境下会出现 “交错执行”,导致逻辑漏洞(以两个线程为例):
- 假设当前
g_tickets = 1,线程 A 和线程 B 同时执行到 步骤 1,都判断 “1 > 0” 为真,进入分支。 - 线程 A 先执行 步骤 3,g_tickets 变为 0。
- 线程 B 随后执行 步骤 3,此时 g_tickets 从 0 减为 -1,最终出现负数。(因为它们都判断进入了分支!)
补充1:以下是这两个线程竞争的时间线表格(关于i--类型的汇编过程向下看)
| 时间点 | 当前线程 | 操作 | 线程A寄存器(eax) | 线程B寄存器(eax) | 共享资源(g_tickets) | 说明 |
|---|---|---|---|---|---|---|
| T0 | - | 初始状态 | 无(未初始化) | 无(未初始化) | 1 | 内存中仅剩1张票,线程A、B待启动 |
| T1 | 线程A | 1. 判断:if(g_tickets>0) | 无 | 无 | 1 | 线程A读内存1,1>0成立,判断通过 |
| T2 | 线程A | 【操作系统线程切换】 usleep增大了间隔使得切换更容易发生! | 无(未读内存) | 无 | 1 | 线程A刚通过判断,正要执行“读内存”,被CPU暂停切换 |
| T3 | 线程B | 1. 判断:if(g_tickets>0) | 无 | 无 | 1 | 线程B读内存1,1>0成立,判断通过 |
| T4 | 线程B | 2. 读内存:mov eax, [g_tickets] | 无 | 1(加载内存值1) | 1 | 线程B将内存的1读到自己的eax寄存器 |
| T5 | 线程B | 3. 改寄存器:dec eax | 无 | 0(1-1) | 1 | 线程B仅修改自身eax,内存仍为1 |
| T6 | 线程B | 4. 写内存:mov [g_tickets], eax | 无 | 0 | 0 | 线程B将eax=0写回内存,内存首次变为0 |
| T7 | - | 【操作系统线程切换】 | 无(恢复执行) | 0(保存状态) | 0 | CPU暂停线程B,切回线程A,恢复A的执行流程 |
| T8 | 线程A | 2. 读内存:mov eax, [g_tickets] | 0(加载内存值0) | 0 | 0 | 线程A恢复后,执行被中断的“读内存”,此时内存已为0 |
| T9 | 线程A | 3. 改寄存器:dec eax | -1(0-1) | 0 | 0 | 线程A对读到的0执行自减,eax变为-1 |
| T10 | 线程A | 4. 写内存:mov [g_tickets], eax | -1 | 0 | -1 | 线程A将eax=-1写回内存,最终内存变为负数 |
注意:这里使用usleep(1000)是为了放大这种错误,会让线程在 “判断” 和 “自减” 之间休眠 1 毫秒,极大增加了这种 “多线程同时通过判断” 的概率,直接放大了问题。
即使去掉 usleep(1000),td->_tickets-- 本身也不是原子操作(会拆成 “读 - 改 - 写” 三条汇编指令),可能出现另一种数据竞争。
上面的语句改成汇编会是三条语句。
1.从内存读取到CPU 2.CPU内部进行-- 3.写回内存
如下(这里;是注释的意思)
; 步骤1:从内存读取 _tickets 的值到寄存器
mov eax, [td + _tickets] ; eax = td->_tickets; 步骤2:在寄存器中执行减1操作(修改)
dec eax ; eax = eax - 1; 步骤3:将寄存器中的结果写回内存
mov [td + _tickets], eax ; td->_tickets = eax
正因为td->_tickets--被拆成三个独立的汇编指令,多线程环境下,CPU 可能在执行完第 1 条(读)、第 2 条(改)后,突然切换到另一个线程 —— 此时原线程还没执行第 3 条(写回内存),新线程读取到的就是 “旧值”,最终导致数据竞争。
如下表,是两个线程竞争的一种情况(在没有usleep(1000)的理想情况下)(理想是指判断与读取内存直接没有时间间隔)
| 时间点 | 当前线程 | 操作 | 线程A寄存器(eax) | 线程B寄存器(eax) | 共享资源(g_tickets) | 说明 |
|---|---|---|---|---|---|---|
| T0 | - | 初始状态 | 无(未初始化) | 无(未初始化) | 1 | 内存中仅剩1张票,线程A、B待启动 |
| T1 | 线程A | 1. 判断:if(g_tickets>0) | 无 | 无 | 1 | 线程A读内存判断“1>0”,通过 |
| T2 | 线程A | 2. 读内存:mov eax, [g_tickets] | 1(加载内存值) | 无 | 1 | 线程A将内存的1读到自己的eax |
| T3 | - | 【操作系统线程切换】 | 1(保存状态) | 无 | 1 | CPU暂停线程A,切换到线程B(A的eax值被保存) |
| T4 | 线程B | 1. 判断:if(g_tickets>0) | 1(已保存) | 无 | 1 | 线程B读内存判断“1>0”,通过(此时内存仍为1) |
| T5 | 线程B | 2. 读内存:mov eax, [g_tickets] | 1 | 1(加载内存值) | 1 | 线程B将内存的1读到自己的eax |
| T6 | 线程B | 3. 改寄存器:dec eax | 1 | 0(1-1) | 1 | 线程B仅修改自己的eax,内存未变 |
| T7 | 线程B | 4. 写内存:mov [g_tickets], eax | 1 | 0 | 0 (B:1→0) | 线程B将eax=0写回内存,内存变0 |
| T8 | - | 【操作系统线程切换】 | 1(恢复状态) | 0(保存状态) | 0 | CPU暂停线程B,切回线程A(恢复A的eax=1) |
| T9 | 线程A | 3. 改寄存器:dec eax | 0(1-1) | 0 | 0 | 线程A基于之前保存的eax=1,减1得0 |
| T10 | 线程A | 4. 写内存:mov [g_tickets], eax | 0 | 0 | 0 | 线程A将eax=0写回内存,内存还是0 |
这里即使只剩一张票,也被线程A,线程B抢了两次,这是不合法的。(同理推广到多个线程最后抢票也有这种结果)
这种情况是假设判断与读取内存之间几乎没有时间间隔情况(就视为没有间隔),然而实际上判断与读取内存之间也是可以被操作系统切换到其他线程的!(见补充1的图)
什么是原子的,原子性的概念:要么完全执行,要么完全不执行,不会处于中间状态,也不会被其他操作中断。
简单的理解:语句转换成汇编,只有一条汇编,那么只有一次执行完或者不执行。
总结:核心问题是共享资源g_tickets的访问无保护,“判断 + 自减” 操作非原子化,usleep放大问题,使得多线程交错执行导致逻辑漏洞。
解决方式—加锁
一些互斥锁的接口
pthread_mutex_init函数
用于初始化互斥锁(mutex) 的函数,用于解决多线程对共享资源的并发访问冲突。
#include <pthread.h>int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
参数说明
mutex:指向 pthread_mutex_t 类型的互斥锁对象的指针,用于存储初始化后的锁状态。
attr:指向互斥锁属性对象(pthread_mutexattr_t)的指针,用于指定锁的属性(如类型、共享范围等)。若为 NULL,则使用默认属性。
返回值
成功:返回 0。
失败:返回非零错误码(如 EINVAL 表示属性无效,ENOMEM 表示内存不足)。
若互斥锁是全局或静态变量,可直接用宏初始化(无需调用 pthread_mutex_init):
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER; // 等价于默认属性初始化
pthread_mutex_destroy函数
用于销毁互斥锁(mutex) 的函数,用于释放互斥锁占用的资源,避免内存泄漏。
#include <pthread.h>int pthread_mutex_destroy(pthread_mutex_t *mutex);
参数说明
mutex:指向已初始化的 pthread_mutex_t 类型互斥锁对象的指针,需要被销毁。
返回值
成功:返回 0。
失败:返回非零错误码(如 EBUSY 表示互斥锁正在被使用,EINVAL 表示传入的互斥锁无效)。
pthread_mutex_lock函数与pthread_mutex_unlock函数
pthread_mutex_lock函数:用于获取互斥锁(加锁) 的函数,其作用是保证同一时间只有一个线程能访问共享资源。
#include <pthread.h>int pthread_mutex_lock(pthread_mutex_t *mutex);
参数说明
mutex:指向已初始化的 pthread_mutex_t 类型互斥锁对象的指针。
返回值
成功:返回 0(表示当前线程已成功获取锁)。
失败:返回非零错误码(如 EDEADLK 表示线程已持有该锁,可能导致死锁;EINVAL 表示锁未初始化)。
申请锁成功:函数就会返回,允许某一个线程继续向后运行。
申请锁失败:函数就会阻塞,不允许线程继续向后运行。
pthread_mutex_unlock函数:用于释放互斥锁(解锁) 的函数,作用是将已锁定的互斥锁恢复为未锁定状态,让其他阻塞等待该锁的线程有机会获取锁并访问共享资源。
#include <pthread.h>int pthread_mutex_unlock(pthread_mutex_t *mutex);
参数说明
mutex:指向已被当前线程锁定的 pthread_mutex_t 类型互斥锁对象的指针,需要释放该锁。
返回值
成功:返回 0(锁已释放,状态变为未锁定)。
失败:返回非零错误码(如 EPERM 表示当前线程未持有该锁,EINVAL 表示锁未初始化或已销毁)。
锁的使用
出现的并发访问的问题,本质是因为多个执行流执行访问全局数据的代码导致的。
保护全局共享资源,本质是通过保护临界区完成的。临界区:访问临界资源的代码。
加锁本质是把线程并行执行变成串行执行,所以加锁的粒度越细越好。
竞争锁是自由竞争的,竞争锁的能力太强的线程,会导致其他线程抢不到锁——造成了其他线程的饥饿问题。
方法1全局锁
主要是用pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;//定义一把锁
int g_tickets = 10000;//共享资源,没有保护的,对全局的tickets的判断不是原子的→临界资源
pthread_mutex_t gmutex = PTHREAD_MUTEX_INITIALIZER;//定义一把锁void route(ThreadData *td)
{while(true){//访问临界资源的代码,叫做临界区---加锁本质是把线程并行执行变成串行执行,所以加锁的粒度越细越好pthread_mutex_lock(&gmutex);//加锁//临界区------------------------------------------------------------------------if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;//临界区------------------------------------------------------------------------pthread_mutex_unlock(&gmutex);//解锁td->total++;}else{pthread_mutex_unlock(&gmutex);//解锁break;}}
}
方法2局部锁
这里把锁也传到类中了,必须要借助类对象进入函数,从而使用锁。
class ThreadData
{
public:ThreadData(int &tickets, const std::string &name, pthread_mutex_t &pmutex): _tickets(tickets), _name(name), total(0), mutex(pmutex)//*****{}~ThreadData(){}public:int &_tickets;std::string _name;int total;pthread_mutex_t &mutex;//*****
};
int g_tickets = 10000;
const int num = 4;
void route(ThreadData *td)
{while(true){//pthread_mutex_lock(&gmutex);//加锁pthread_mutex_lock(&td->mutex);//加锁//临界区------------------------------------------------------------------------if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;//临界区------------------------------------------------------------------------//pthread_mutex_unlock(&gmutex);//解锁pthread_mutex_unlock(&td->mutex);//解锁td->total++;}else{//pthread_mutex_unlock(&gmutex);//解锁pthread_mutex_unlock(&td->mutex);//解锁break;}}
}
int main()
{pthread_mutex_t gmutex;//定义一把局部锁pthread_mutex_init(&gmutex, nullptr);//初始化锁std::vector<Thread<ThreadData*>> threads;std::vector<ThreadData*> datas;//1.创建一批线程for(int i=0;i<num;i++){std::string name = "thread-" + std::to_string(i+1);ThreadData *td = new ThreadData(g_tickets, name, gmutex);//锁传到类中datas.push_back(td);threads.emplace_back(route, td, name);}//2.启动一批线程for(auto &th : threads){th.start();}//3.等待一批线程结束for(auto &th : threads){th.join();//std::cout << "wait thread done, thread is: " << th.name() << std::endl;}//4.输出统计数据for(auto &data : datas){std::cout << data->_name << " : " << data->total << std::endl;delete data;}pthread_mutex_destroy(&gmutex);//销毁锁return 0;
}
方法3封装锁
LockGuard.hpp
#ifndef __LOCK_GUARD_HPP__
#define __LOCK_GUARD_HPP__#include<pthread.h>
#include<iostream>
class LockGuard
{
public:LockGuard(pthread_mutex_t *mutex):_mutex(mutex){pthread_mutex_lock(_mutex);//构造加锁}~LockGuard(){pthread_mutex_unlock(_mutex);//析构解锁}
private:pthread_mutex_t *_mutex;
};
#endif // __LOCK_GUARD_HPP__
void route(ThreadData *td)
{while(true){LockGuard guard(&td->mutex);//加锁,临时对象,RAII风格的加锁和解锁,出来作用域自动析构解锁//临界区------------------------------------------------------------------------if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;//临界区------------------------------------------------------------------------td->total++;}else{break;}}
}
方法4 C++11互斥锁
C++11互斥锁本质上底层封装了原生线程库的互斥锁,类似方法3中那样封装的。
......
#include<mutex>//c++11引入的互斥锁头文件class ThreadData
{
public:ThreadData(int &tickets, const std::string &name, std::mutex &pmutex): _tickets(tickets), _name(name), total(0), mutex(pmutex){}~ThreadData(){}public:int &_tickets;std::string _name;int total;//pthread_mutex_t &mutex;std::mutex &mutex;
};
void route(ThreadData *td)
{while(true){td->mutex.lock();//加锁//临界区------------------------------------------------------------------------if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;//临界区------------------------------------------------------------------------td->mutex.unlock();//解锁td->total++;}else{td->mutex.unlock();//解锁break;}}
}const int num = 4;
int main()
{std::mutex mtx;//c++11引入的互斥锁对象std::vector<Thread<ThreadData*>> threads;std::vector<ThreadData*> datas;//1.创建一批线程for(int i=0;i<num;i++){std::string name = "thread-" + std::to_string(i+1);ThreadData *td = new ThreadData(g_tickets, name, mtx);//C++11的锁datas.push_back(td);threads.emplace_back(route, td, name);}//2.启动一批线程for(auto &th : threads){th.start();}//3.等待一批线程结束for(auto &th : threads){th.join();//std::cout << "wait thread done, thread is: " << th.name() << std::endl;}//4.输出统计数据for(auto &data : datas){std::cout << data->_name << " : " << data->total << std::endl;delete data;}return 0;
}
互斥锁的底层实现
经过上面的例子,单纯的i++或者++i操作都不是原子的,有可能有数据的一致性问题。
为了实现互斥锁操作,大多数体系结构提供了 swap 或 exchange 指令,该指令的作用是把寄存器和内存单元的数据相互交换,在汇编中只有一条指令,具有了原子性。
前提知识:
- CPU寄存器硬件只有一套,物理寄存器仅能存储当前运行线程的数据,其他线程的寄存器数据暂存于内存,需通过调度切换才能加载到物理寄存器。
- 每个线程都有专属的硬件上下文(存储于内存),操作系统通过 “保存当前线程上下文→加载新线程上下文” 的操作,实现线程在同一套物理寄存器上的切换执行。
- 数据在内存里,所有线程都能访问,属于共享的。但是如果转移到CPU内部寄存器中,就属于一个线程独占了。
总结:线程切换的本质是 “硬件上下文的切换”:当操作系统决定切换线程时,会执行两个关键步骤:
- 保存上下文:将当前线程的物理寄存器值全部写入该线程的内存;
- 恢复上下文:从新线程的内存中,读取其之前保存的寄存器值,逐一写入物理寄存器;
完成后,CPU 继续执行时,物理寄存器中已是新线程的数据,相当于 “新线程独占了物理寄存器”。
线程争锁的本质,不是争夺‘数据拷贝到寄存器’的权利,而是争夺‘对锁状态的修改权’—— 锁的状态只有‘0(未持有)’和‘1(已持有)’两种,‘1’代表‘独占访问共享资源的唯一权限’,所有线程竞争的核心就是‘谁能成功将锁状态从 0 改为 1’,最终只有一个线程能拿到这个‘1’,其他线程则阻塞等待。
这是一段加锁与解锁的伪代码
lock:movb $0, %al //al寄存器中设置为0(表示占用) //1.xchgb %al, mutex //2.if(al寄存器内容 > 0){ //3.return 0;//加锁成功,跳出函数,继续往后走}else 挂起等待;//申请锁失败,锁被占用goto lock;unlock:movb $1, mutex //al寄存器中设置为1(表示空闲) //4.唤醒等待mutex的线程; //5.return 0;
注意:这里xchgb是交换的意思,只有一条汇编,是原子的。
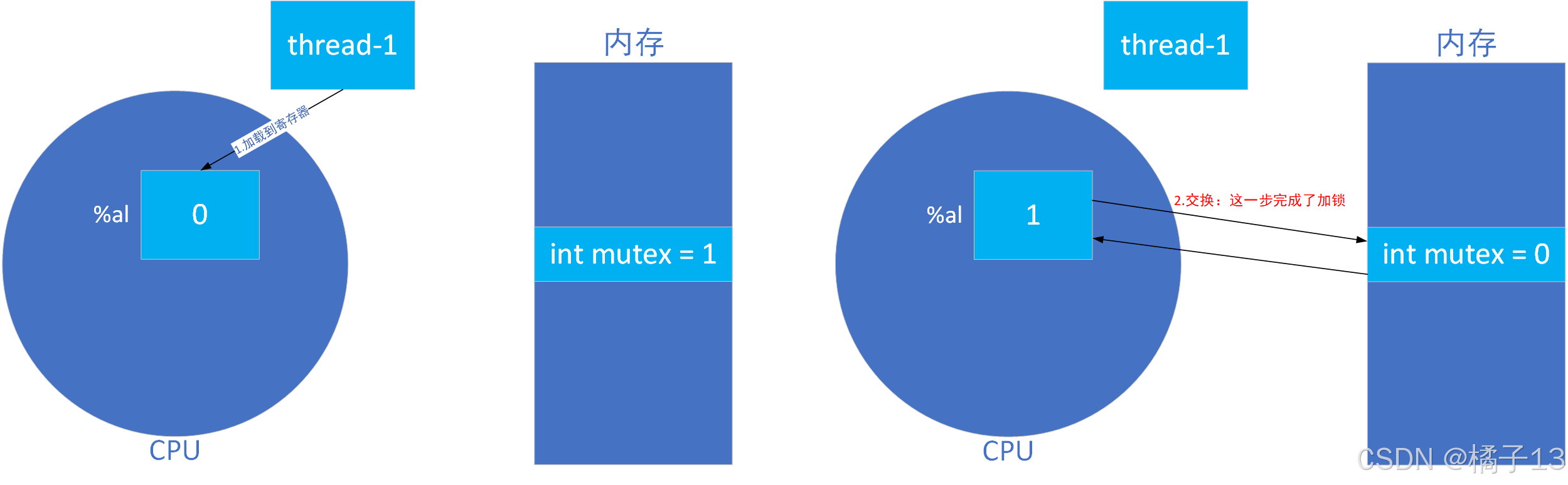
以下是一个争锁的场景
首先是把CPU寄存器中设置为0(1.),然后去与mutex进行交换(2.),这时thread-1拿到1,竞争锁成功。
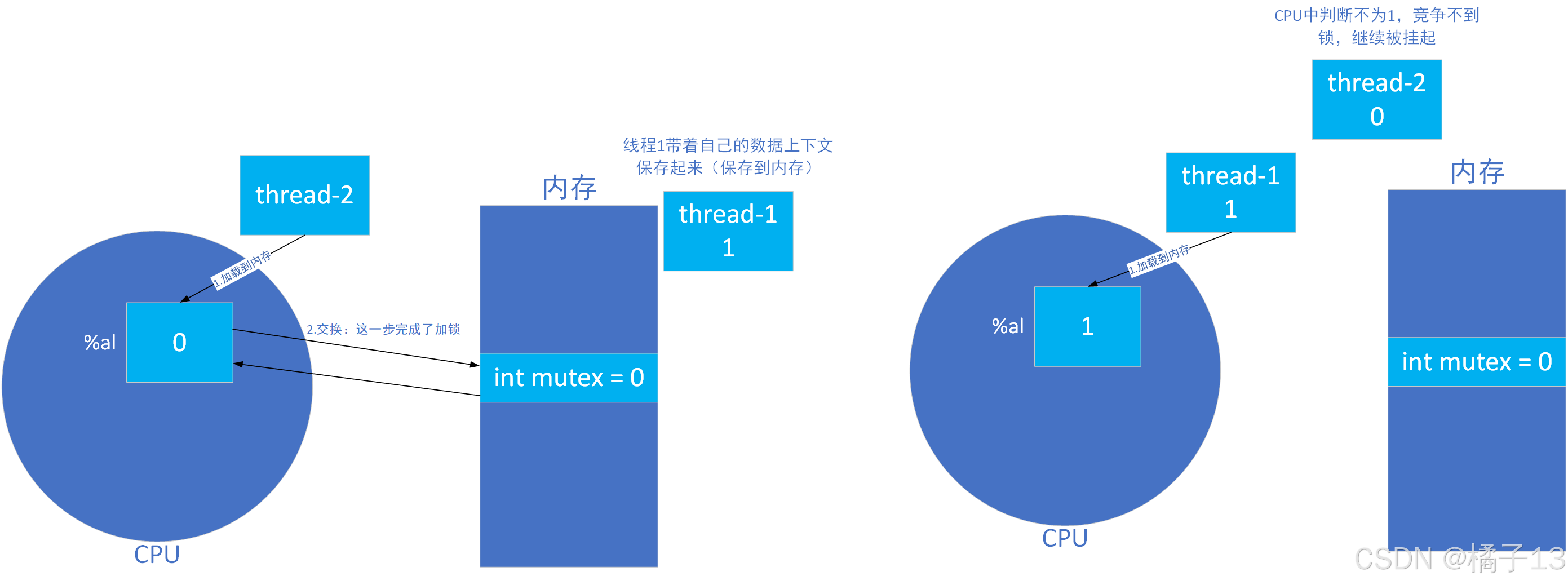
这个时候线程被切换,thread-1暂时被挂起,其数据暂时被保存到内存中,thread-2这时要申请锁,同样的流程,但是thread-2只交换到了0,经过CPU中判断(3.)后被挂起,然后继续执行thread-1(上下文加载进CPU寄存器,判断(3.)不为0后,唤醒等待队列,允许thread-1执行)。
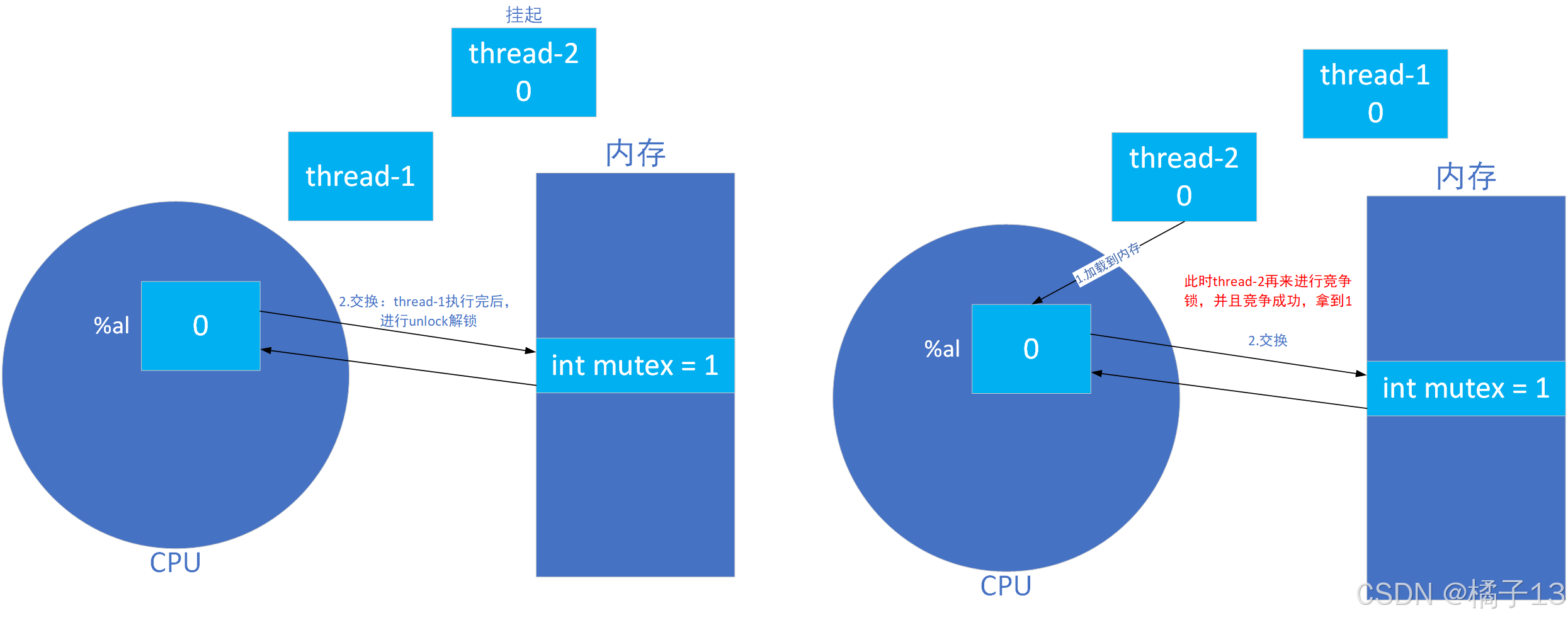
thread-1执行完后解锁,这时进行交换(2.),mutex又变成了1(说明有锁可以竞争),挂起的thead-2被切换进来竞争锁,若竞争成功,像上面一样,其他线程再次切换进来竞争不到锁也无法继续执行,只有把thread-2加锁区域执行完后,解锁后,才允许其他线程争锁来执行代码。
一个问题
在临界区内部,正在访问临界区的线程,可以不可以被OS切换调度?
可以被切换。
锁的作用是 “阻止其他线程进入临界区”,而非 “阻止当前线程被切换”。
虽然可以被切换,但是其他线程依然进入不了临界区,当到临界区前,通过上面一系列流程(判断其他线程没有锁,都被挂起),重新轮到带锁的线程执行临界区的代码,直到解锁后,其他线程考虑去竞争锁来访问临界区。
void route(ThreadData *td)
{while(true){pthread_mutex_lock(&gmutex);//加锁//临界区------------------------------------------------------------------------if(td->_tickets > 0){usleep(1000);printf("%s running, get tickets: %d\n", td->_name.c_str(), td->_tickets);td->_tickets--;//临界区------------------------------------------------------------------------pthread_mutex_unlock(&gmutex);//解锁td->total++;}else{pthread_mutex_unlock(&gmutex);//解锁break;}}
}