基于 Zynq 的目标检测系统软硬协同架构设计(一)
在人工智能快速发展的今天,目标检测已成为计算机视觉领域中至关重要的任务
之一,并正在深刻改变着人类社会的生产生活方式。从自动驾驶车辆的环境感知[1, 2]到
工业质检的缺陷识别[3, 4],从卫星遥感的地表监测[5, 6]到医疗影像的病灶分析[7],目标检
测技术已成为推动人工智能发展的重要引擎。
然而,随着深度学习技术的演进,基于卷积神经网络(CNN)的目标检测算法呈现
出网络层数指数级增长的趋势,使其运算过程越来越复杂,参数也已突破千万量级。网
络层数的增加虽然在一定程度上提高了模型的检测精度,这对硬件平台的计算和存储
资源提出了严峻挑战。这种算法复杂度与硬件性能间的矛盾在工业检测、车载系统等
低功耗实时场景中尤为突出。为了应对这一难题,研究人员不仅要致力于网络架构的
优化,还需在硬件领域探索有效的解决方法。
传统平台 CPU 作为核心处理器受限于其串行架构设计,无法满足卷积神经网络中
密集矩阵运算的并行化需求,导致计算效率难以提升。目前,图形处理器(GPU)、专
用集成电路芯片(ASIC)和现场可编程逻辑门阵列(FPGA)是用于部署并实现神经网
络加速的主要平台[8]。GPU 凭借其大规模并行计算单元,在深度学习训练阶段展现出
显著优势,也成为加速卷积神经网络的一种常用选择[9-11]。由于 GPU 主要追求高性能
计算,其能耗和散热需求也相应增加,这就使得其体积往往比较大。因此,在嵌入式系
统、高温环境或对功耗有严格要求的场景中,GPU 的大功耗和较大尺寸可能会引发部
署难题和过热风险。ASIC 通过定制化设计实现算法与硬件的高度匹配[12-14],在能效比
和推理速度上表现优异,但因为高度定制的原因,导致其灵活性极低,一旦算法迭代或应用场景变更,芯片需重新流片,开发周期长且成本高昂。
目标检测系统的硬件设计必须兼顾控制灵活性与计算性能,既要满足传统嵌入式
应用的实时性要求,又需为复杂算法提供硬件加速能力,Zynq 平台以异构计算架构和
高速数据传输技术的优势能够满足这些需求。系统总体架构硬件设计采用“自顶向下”
的思维进行,首先进行软硬件协同功能划分与数据流设计,然后再分别实现 PS 端和 PL
端中各个模块的设计。
3.1 Zynq 平台架构及关键技术
3.1.1 Zynq 平台介绍
Zynq 是 Xilinx 推出的全可编程片上系统(SoC),将 ARM 处理器与 FPGA 集成
在同一芯片内,并通过 AXI 总线互联,实现了软件与硬件的协同设计[67]。其结构示意
图如图 3-1 所示。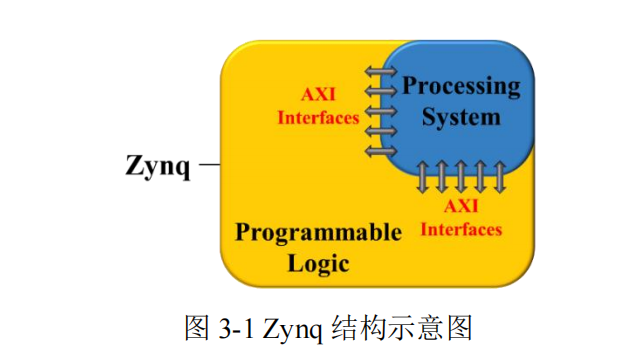
3.2.2 系统级架构实现与控制流程设计
根据任务划分策略,搭建整体的系统框架,如图 3-6 所示。
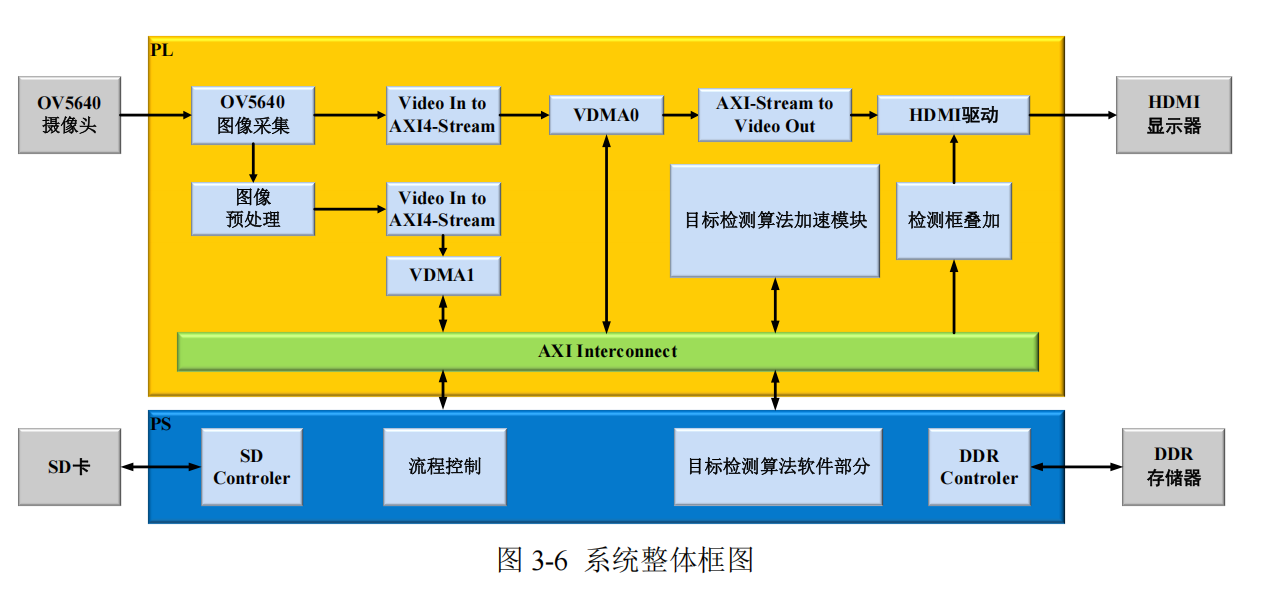
控制实流程如下:
(1)初始化阶段
Zynq 嵌入式开发板上电后,PS 端将训练好的目标检测模型的权重和偏置参数从
SD 卡中加载到 DDR 中存储,为后续计算做好数据准备。
(2)图像采集
通过 OV5640 图像采集模块对 OV5640 进行初始化,并驱动其进行图像数据的采
集作为系统的输入,然后数据经过 VDMA0 保存至 DDR 存储器中。
(3)图像预处理
图像预处理模块主要将摄像头采集过来的图像做下采样操作,将图片压缩至
416×416,随后通过 VDMA1 传入 DDR 中,作为目标检测模型的输入。
(4)目标检测算法前向推理计算
将预处理完的图像数据通过 VDMA1 输入进目标检测算法加速模块做推理运算,
通过 PS 端来控制计算流程,在 PL 端中的目标检测算法加速模块中完成每层的卷积、
池化等计算。
(5)目标检测算法后处理计算
在 PS 端中,首先对目标检测算法加速模块所输出的特征图进行处理,将其解码为
边界框坐标、置信度以及类别信息。随后,运用非极大值抑制技术,剔除那些冗余的检
测框,仅保留针对每个物体最有可能的检测结果。最终,将这些检测结果框的坐标重新
映射回原始图像中。
(6)检测结果输出
将检测结果保存回 SD 卡,以便后续在 PC 上处理,并通过检测框叠加模块将检测
框的坐标传输进 HDMI 驱动模块中,最终通过 HDMI 在显示器上输出结果。至此一轮
检测流程结束,准备进行下一轮检测。
3.3 PS 端模块设计
PS 端作为系统的控制核心,承担全局任务调度、数据管理和复杂逻辑处理功能。
其设计围绕系统流程控制、图像拼接优化与目标检测后处理三个核心模块展开,通过
软硬件协同实现高效推理与资源优化。
3.3.1 系统数据与流程控制
在系统架构中,PS 端承担着硬件系统数据以及流程管控的重要职责。系统的数据
流和控制流通过各自独立的接口实现分别传递 ,如图 3-8 所示,PS 端通过
M_AXI_HPM0_LPD 接口对 PL 端部分进行控制,该接口通过 AXI Interconnect 与 FPGA
内部的各个模块相连,主要用于控制数据在 FPGA 内部的流动以及与其他模块之间的
交互。它可以控制数据从 VDMA0、VDMA1 以及目标检测算法加速模块等之间的流转,
协调这些模块之间的数据处理和传输顺序。同时,它还与 AXI4_Lite_box 相连,通过该 
接口将相关的控制信息传递给检测框坐标传输模块,确保检测框坐标等信息能够按照
正确的流程进行传输和处理。在数据交互方面,PS 端主要通过 S_AXI_HP 接口与 PL
端中的 VDMA0、VDMA1 和目标检测算法加速模块进行高速数据传输。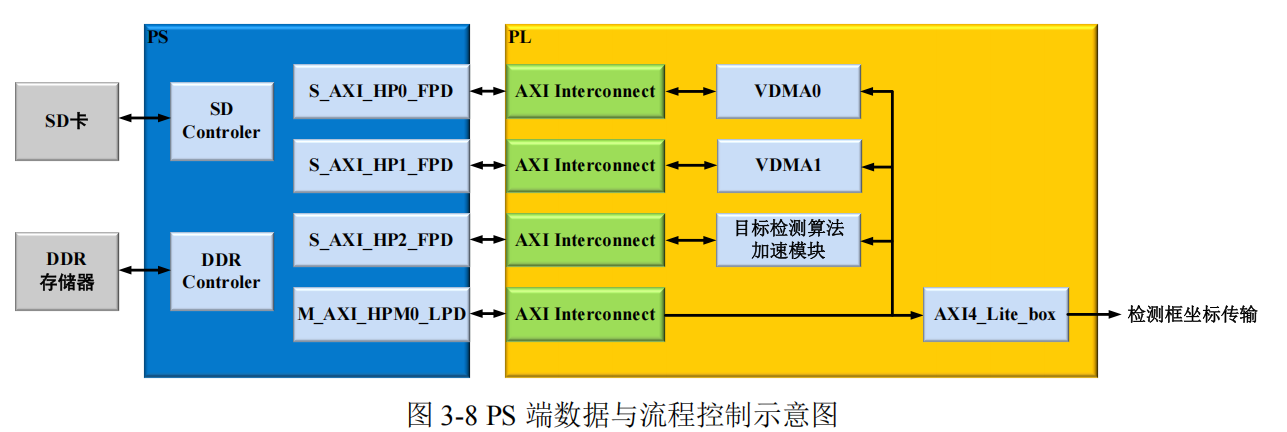
3.3.2 图像拼接
在 YOLOv4-tiny 模型中,concat 层出现在 Resblock_Body 和 FPN 中,总共有 7 次
操作,该层的功能是实现两个不同层次的特征图拼接,保留各个特征图的空间结构信
息,同时叠加更多的语义信息,实现多尺度信息融合,从而提升检测效果。在本设计中,
这部分的操作交给 PS 端来负责实现。PS 端不需要读取已存储的数据进行处理,只需
在 PL 端请求缓存要拼接的数据时计算偏移量将各输入特征图的数据按通道顺序复制
到目标数组中即可完成图像拼接。
3.3.3 目标检测后处理
目标检测后处理是将神经网络输出的特征图转化为最终检测结果的核心流程,如
图 3-9 所示,主要包含以下模块:
(1)边界框解码:将特征图的坐标偏移量映射到原图空间,使用预设锚点参数完
成几何变换。
(2)置信度过滤:通过阈值筛选消除低质量候选框,保留置信度>0.5 的预测结果。
(3)非极大值抑制(NMS):基于 IoU 的重叠框消除,采用类别感知的迭代抑制
策略。
(4)坐标修正:将归一化坐标映射到原图分辨率,并进行边界裁剪防止越界。
(5)多尺度融合:整合 13×13 和 26×26 双尺度特征图的检测结果。
其中,目标检测后处理中的 Sigmoid、指数运算和 NMS 等操作因依赖动态数据流
和复杂浮点计算,难以高效映射到 FPGA 的固定流水线架构。同时,非极大值抑制的
迭代比较和排序操作会引发硬件资源利用率低下及并行化困难,导致在 PL 端上实现复
杂度。因此,本文将利用 PS 端灵活的软件编程来实现这部分功能。
3.4 PL 端模块设计
本节将介绍 PL 端关键模块的硬件实现方案,包括图像采集、图像预处理、显示和
数据传输存储模块。对于目标检测算法加速模块这一核心部分,本文将在第四章进行
详细介绍。
3.4.1 图像采集与显示模块
1. 图像采集模块
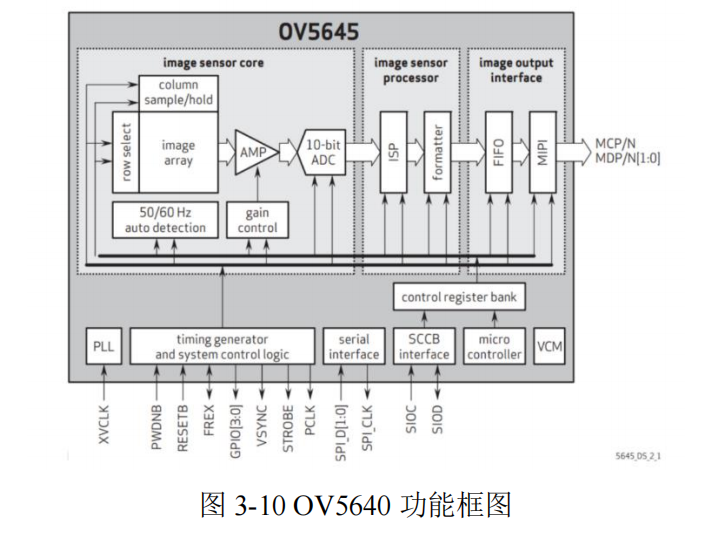
摄像头接口设计是图像采集模块的核心部分,其主要任务是实现摄像头与 Zynq 平
台的高效连接和数据传输。本系统选用 OV5640 摄像头,OV5640 摄像头采用先进的
CMOS 工艺,专为嵌入式与便携应用打造。它不仅能输出高达 500 万像素的图像,还
内置了许多智能图像处理功能,确保在不同环境下都能捕捉到清晰、准确的图像。与此
同时,该传感器支持灵活的接口模式,能够实现与 Zynq 平台等主控芯片的高效数据传
输。