mysql数据库、iptables、Ivs服务和keepalived服务
Mysql数据库
1. MySQL 的四个隔离原理及其事务日志
概念:MySQL 的事务隔离级别一共有四个,分别是 读未提交、读已提交、可重复读 以及 可串行化。MySQL的隔离级别的作用就是让事务之间互相隔离,互不影响,这样可以保证事务的一致性。
读未提交
定义: 这是最低的隔离级别。在此级别下,一个事务可以读取到其他事务尚未提交的修改
解决的并发问题: 它不能解决任何并发问题。
可能发生的并发问题:
脏读 : 事务 A 读取了事务 B 修改但未提交的数据。如果事务 B 最终回滚,那么事务 A 读取到的数据就是无效的(“脏”数据)。
不可重复读
幻读
工作原理: 几乎不加锁(除了写操作会加排他锁直到事务结束)。读取操作直接读取数据页(或缓存)中的最新值,无论该值是否已提交。性能最高,但数据一致性风险最大。
读已提交
定义: 这是许多数据库的默认级别。在此级别下,一个事务只能读取到其他事务已经提交的修改。它解决了脏读问题。
解决的并发问题:脏读
可能发生的并发问题:
不可重复读
幻读
工作原理: 通常通过 MVCC实现(在 InnoDB 中)。每个 SELECT语句在执行时,会创建一个新的“读视图”,该视图基于语句开始执行时刻(或事务开始时刻,取决于配置)已提交的数据快照。写操作(UPDATE/DELETE)会对修改的行加排他锁直到事务结束。读取操作不会阻塞其他事务的读取(因为读的是快照),但可能被未提交的写操作阻塞(需要等待写锁释放)。
可重复读
定义: MySQL InnoDB 存储引擎的默认隔离级别。在此级别下,一个事务在整个执行过程中多次读取同一行数据,结果总是一致的)。它解决了脏读和不可重复读问题。
解决的并发问题:
脏读 ,不可重复读
可能发生的并发问题:
幻读
工作原理: 主要依赖 MVCC。在事务开始时(执行第一个 SELECT语句时),会创建一个一致性读视图。在整个事务期间,所有的普通 SELECT操作都基于这个同一个视图来读取数据快照,因此看到的数据是一致的。写操作(UPDATE/DELETE)会对修改的行加排他锁直到事务结束。对于加锁的读(SELECT ... FOR UPDATE/SHARE)或写操作,会使用 Next-Key Locks来锁定索引记录和间隙,防止其他事务插入或修改,从而在 InnoDB 中解决了幻读。
串行化
定义: 这是最高的隔离级别。它强制所有事务串行执行,完全避免了并发问题。它通过强制事务排序,使其不可能相互冲突。
解决的并发问题:
脏读 ,不可重复读 ,幻读
可能发生的并发问题: 无。
工作原理: 在此级别下,InnoDB 会将所有的普通 SELECT语句隐式转换为 SELECT ... FOR SHARE。这意味着读取操作也会对读取的行加锁。如果另一个事务已经持有这些行的排他锁,或者事务本身尝试修改被其他事务加了共享锁的行,则会发生锁等待甚至死锁。这大大增加了锁争用,显著降低了并发性能。
MySQL 事务日志
Redo Log (重做日志)
作用:保证持久性 ,提高写入性能
工作原理:
nnoDB 引擎对数据更新时,先将更新记录写入到 redo log 的 buffer 中,而后在系统空闲的时候
或者是按照设定的更新策略再将日志中的内容更新到磁盘之中。然后再将 commit 的事务的相关数据落盘。也就是说,先写日志,再去修改对应的 MySQL 中的数据文件,这就是所谓的预写式技术。如果事务在 commit 之后数据落盘时失败,则下次启动 MySQL 时,可以根据己经保存的 redo log。再次进行操作,保证 commit 提交成功。当然,如果 redo log 也写失败了,那么这段时间内的 commit就丢失了。
Undo Log (回滚日志)
作用:保证原子性,支持 MVCC
工作原理:
保存与执行的操作相反的操作,即记录某数据被修改前的值,可以用来在事务失败时进行回滚到某行记录的某个版本,其具体流程与 redo log 相似,也要先于 commit 数据落盘,更改对应的MySQL 数据文件之前保存。
2. MySQL 数据备份的分类及其原理和操作
数据备份的分类
一、按备份时数据库的运行状态分类
冷备份
指数据库完全关闭(停止 MySQL 服务)时进行的备份。
原理:直接复制数据库的数据文件(如ibdata1、表空间文件.ibd、日志文件等)和配置文件。
特点:操作简单(如用cp/tar命令),备份文件体积小,恢复速度快;但需停机,影响业务可用性,适合非核心业务或维护窗口。
热备份
指数据库正常运行(可读写)时进行的备份,不中断业务。
原理:通过工具捕获数据变化并记录(如利用 redo 日志、binlog),确保备份数据的一致性。
特点:不影响业务,适合核心生产环境;需专用工具(如 Percona XtraBackup、MySQL Enterprise Backup),配置较复杂。
温备份
指数据库运行但只读(禁止写入)时进行的备份。
原理:备份期间通过FLUSH TABLES WITH READ LOCK锁定所有表,仅允许读操作,完成后解锁。
特点:避免了停机,但会阻塞写入,影响写业务;常见于中小型业务,工具如mysqldump(加锁模式)。
二、按备份的内容范围分类
完全备份
备份全部数据(包括数据库、表结构、索引、数据等)。
特点:备份文件完整,恢复简单(直接恢复即可);但备份体积大,耗时久,适合周期性全量备份(如每日 / 每周)。
增量备份
仅备份上次备份(无论完全还是增量)后新增或修改的数据。
原理:基于二进制日志(binlog)或变更跟踪,记录两次备份之间的变化。
特点:备份体积小,速度快;但恢复复杂(需先恢复完全备份,再依次恢复各增量备份),适合高频次备份(如每小时)。
差异备份
备份上次完全备份后新增或修改的数据(与增量备份的区别:增量基于 “上一次备份”,差异基于 “上一次完全备份”)。
特点:备份体积介于完全和增量之间,恢复时只需恢复完全备份 + 最新差异备份,比增量更简单;适合中等频率备份(如每半天)。
三、按备份的数据形式分类
物理备份
直接备份 MySQL 的底层数据文件(如 InnoDB 的表空间文件、MyISAM 的.MYD/.MYI文件、日志文件等)。
工具:cp、tar、Percona XtraBackup 等。
特点:备份 / 恢复速度快(基于文件系统操作),适合大数据量;但与数据库版本、存储引擎强相关,跨版本恢复可能有兼容问题。
逻辑备份
备份SQL 语句形式的数据(如CREATE TABLE、INSERT语句),本质是导出数据的逻辑结构和内容。
工具:mysqldump、mysqlpump、SELECT ... INTO OUTFILE等。
特点:备份文件是文本,可读性强,跨版本 / 跨存储引擎兼容性好;但备份 / 恢复速度慢(需执行 SQL),适合小数据量或需要灵活处理的场景(如迁移表结构)。
重点对比冷备份与 mysqldump 工具备份
特性 | 冷备 | mysqldump |
|---|---|---|
备份类型 | 物理备份:直接拷贝数据库的物理文件(数据文件、日志文件等)。 | 逻辑备份:将数据库中的结构和数据导出为 SQL 语句(CREATE, INSERT 等)。 |
备份过程 | 数据库服务必须关闭。 | 数据库服务必须运行。 |
业务影响 | 停服,业务中断。 | 温备模式:会加锁,阻塞写入。热备模式:使用 |
备份速度 | 快。因为是文件级别的复制。 | 慢。因为需要执行 SQL 查询并将结果转换为文本。 |
恢复速度 | 快。直接替换物理文件即可。 | 慢。需要逐条执行 SQL 语句,重建数据库、表并插入数据。 |
备份粒度 | 粗。通常只能备份整个实例或整个数据库。 | 细。可以灵活备份单个数据库、单张表,甚至表中符合条件的数据。 |
可移植性 | 差。与操作系统、MySQL 版本、存储引擎强相关,不易迁移。 | 好。SQL 是标准语言,易于在不同版本、甚至不同数据库系统间迁移。 |
文件大小 | 大致等于数据文件大小。 | 通常比物理备份小,尤其是纯文本易于压缩。 |
冷备适用场景:
有固定的、可接受的维护窗口。数据库非常大,且需要快速恢复。对备份恢复操作简单性要求极高。
mysqldump 适用场景:
数据库规模不大。需要高度的灵活性和可移植性。需要备份部分数据。没有专业的物理备份工具
mysqldump 工具进行全量备份、增量备份(结合二进制日志)的基本原理和操作流程。
基本原理:mysqldump是 MySQL 官方提供的客户端备份工具,通过 mysql 协议连接至 mysql 服务器进行备份,mysqldump 命令是将数据库中的数据备份成一个文本文件,数据表的结构和数据都存储在生成的文本文件中。
实践操作:
数据准备
创建库和表
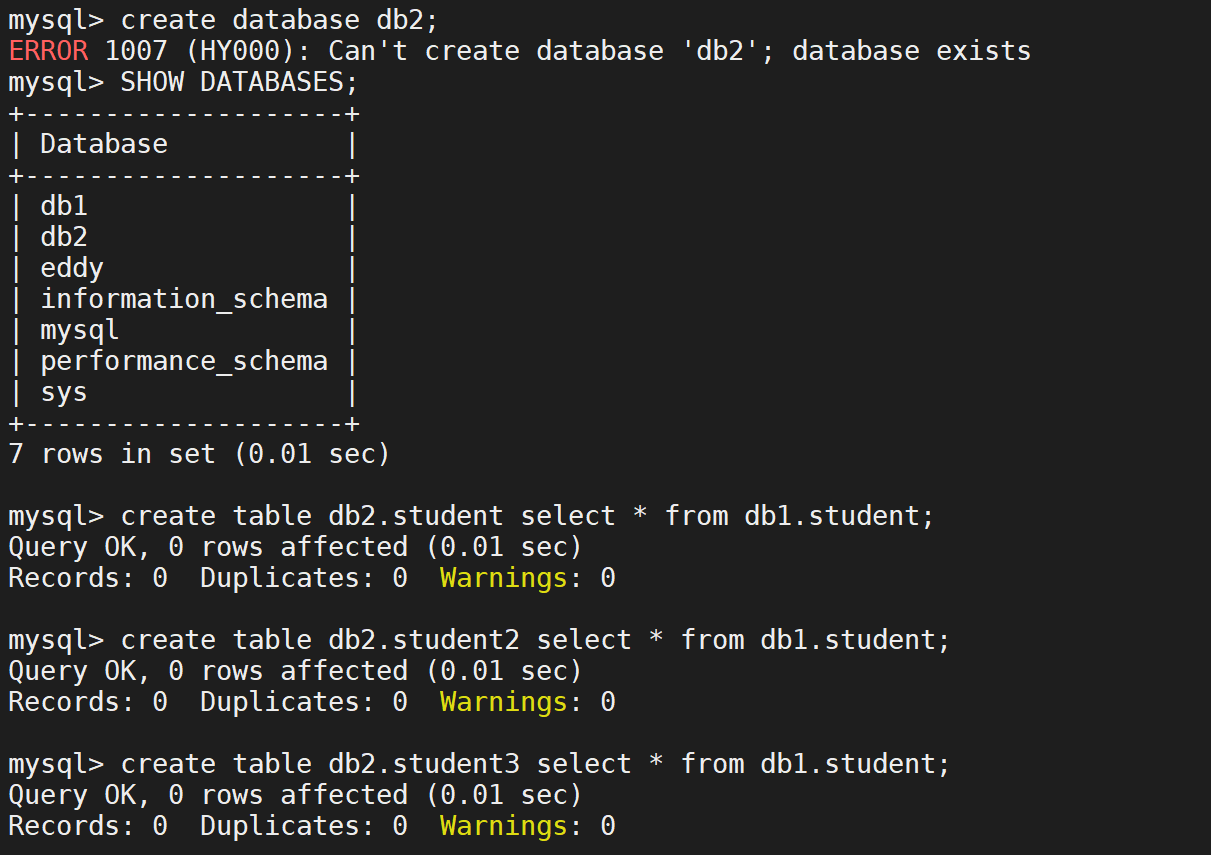
在表中添加数据
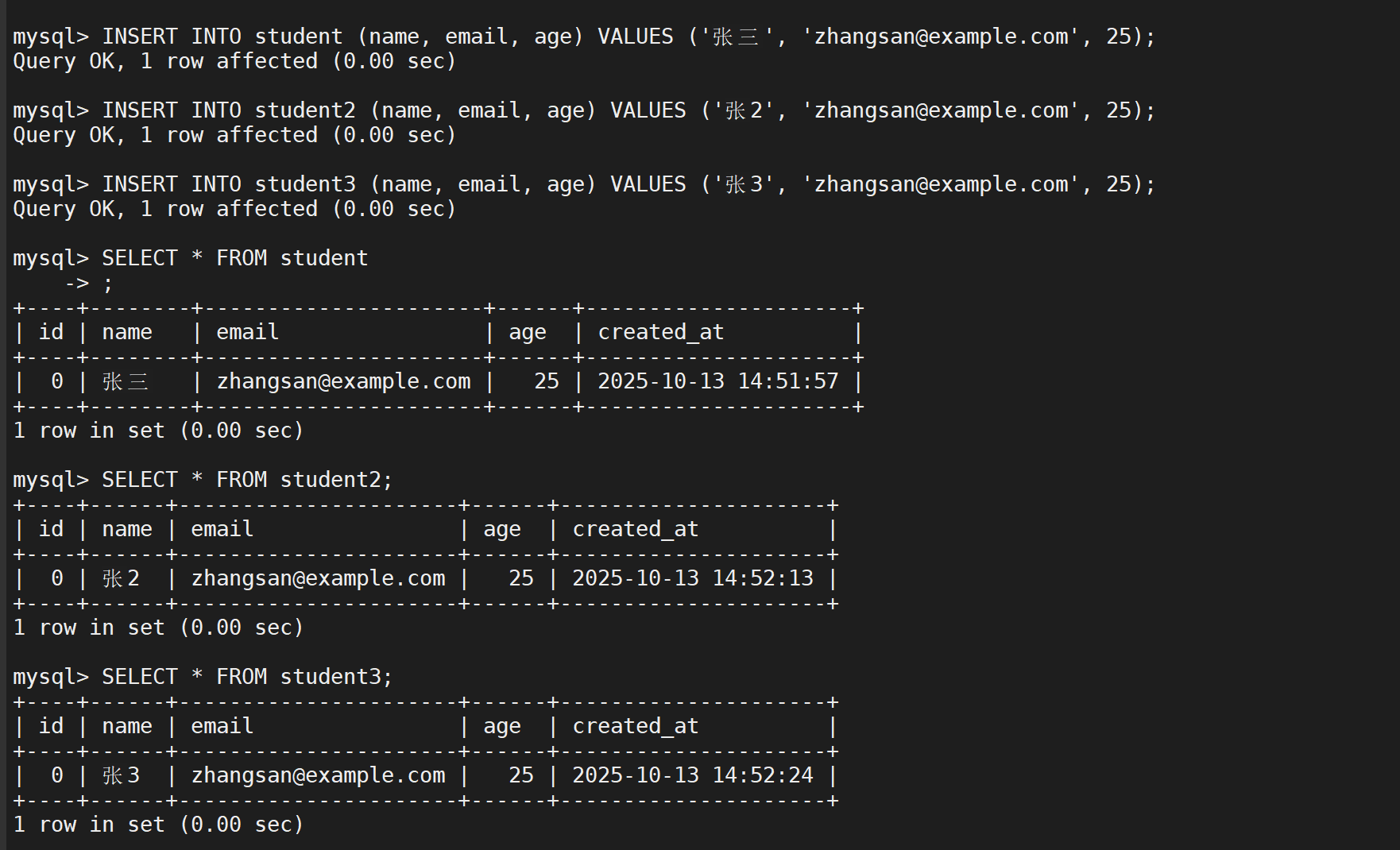
清理或创建备份文件夹


进行备份

确认效果

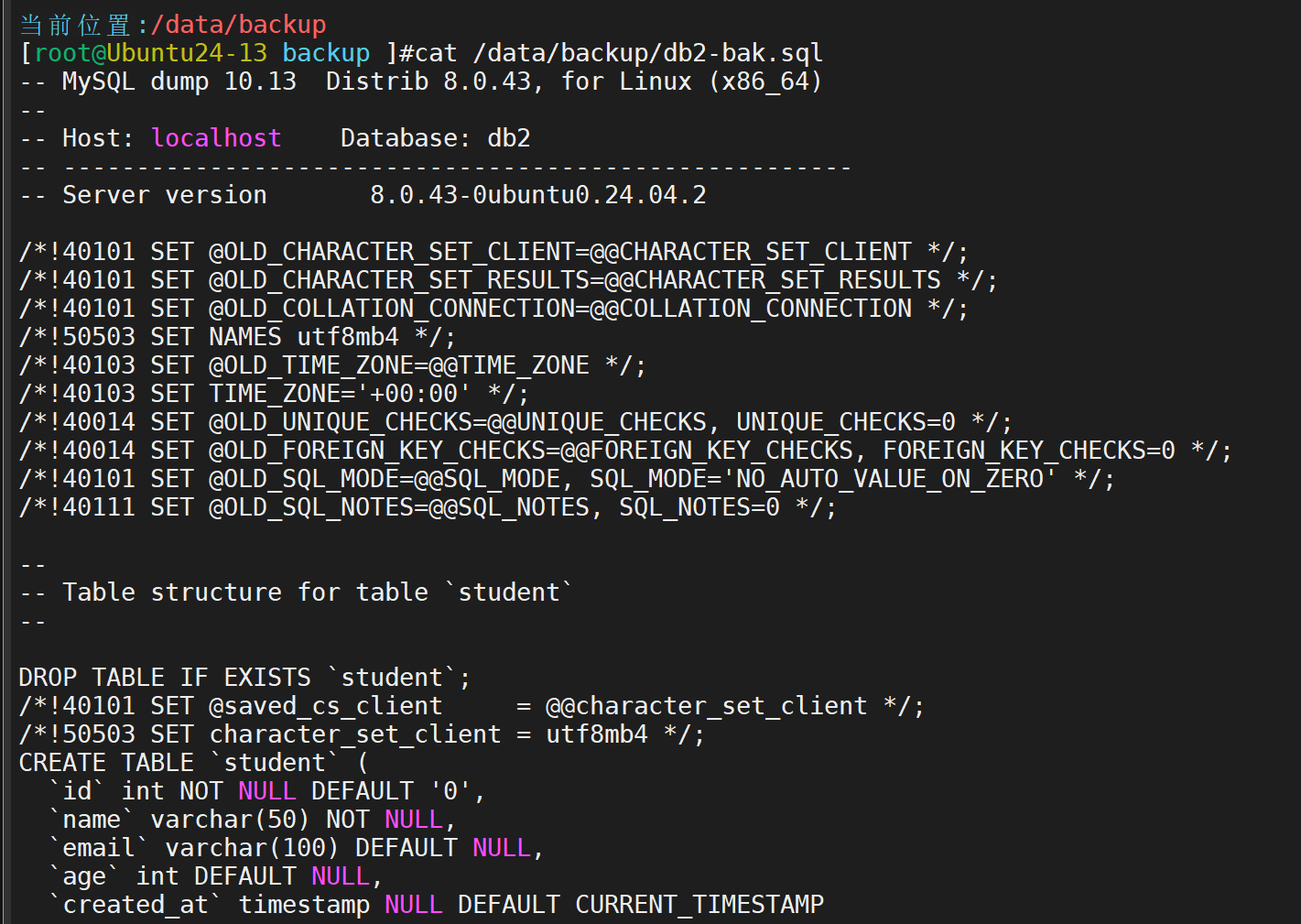
测试还原
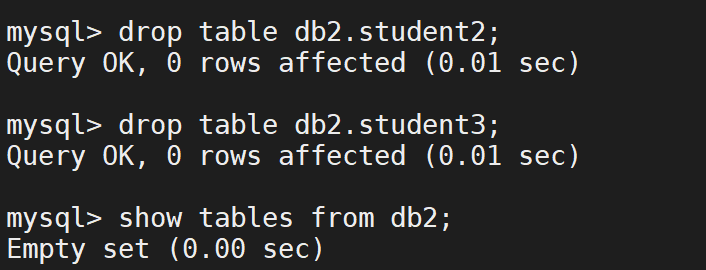
还原数据表

查看效果
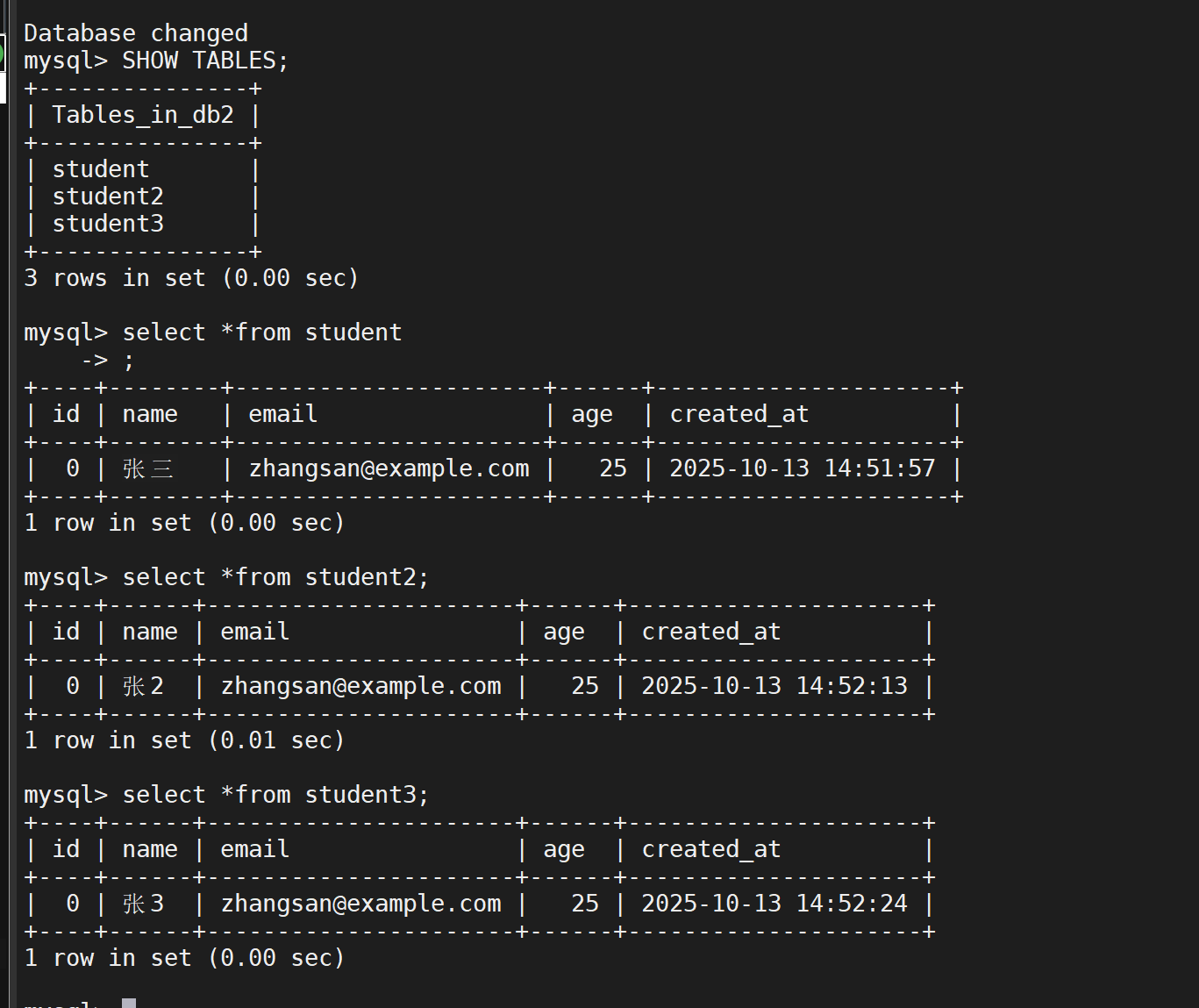
恢复完成,内容如初
但我们可以注意到这种备份方法必须指定数据库,倘若没有这个库,还需要进行手动创建。所以我们接下来演示可以复制一切的全量备份
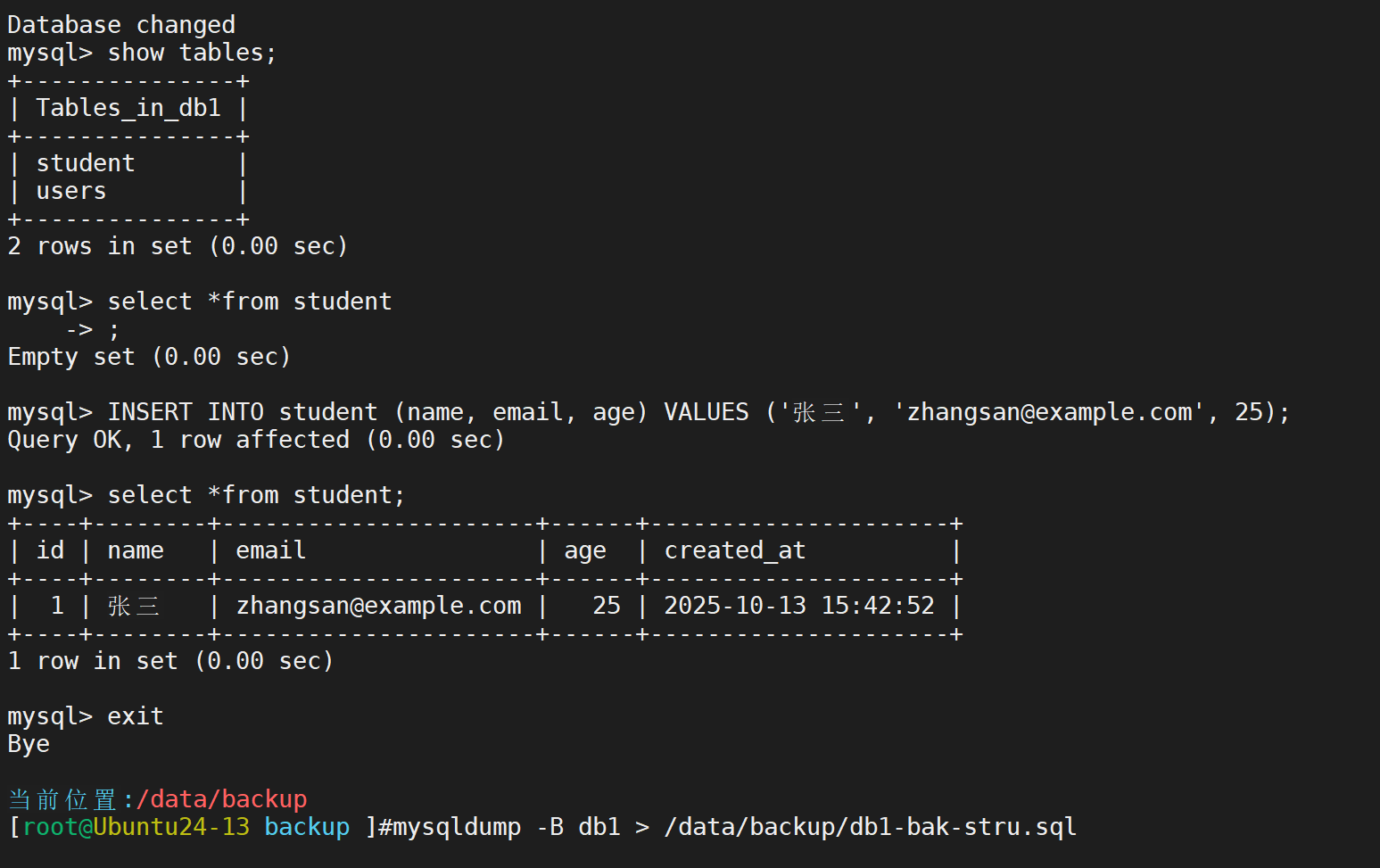
删除数据库

进行还原
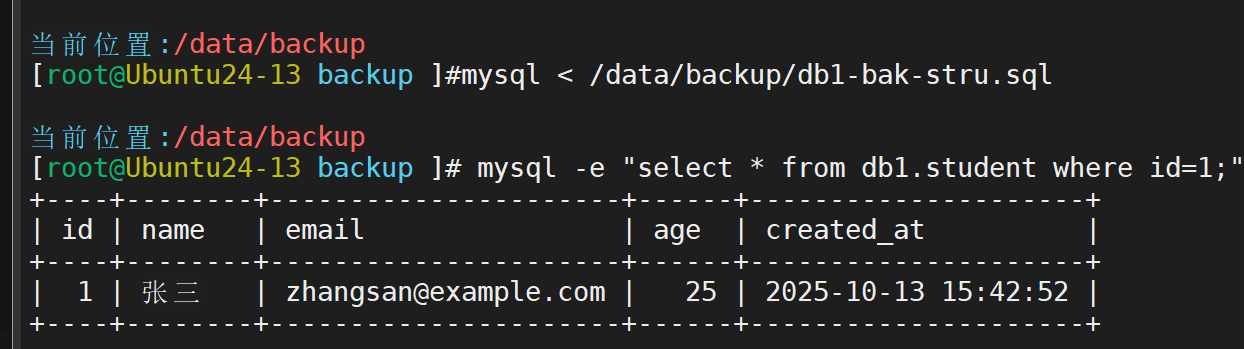
接下来进行增量备份
首先检查一下二进制日志是否打开(ON为打开,OFF为关闭)所有的数据库操作在二进制文件中保存,所以要实现增量备份必须通过二进制文件
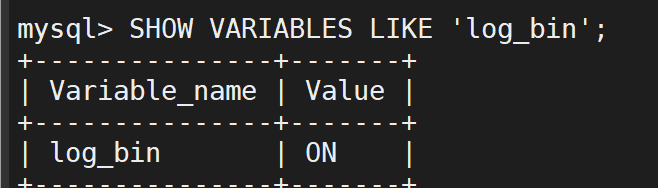
查看此时的数据库
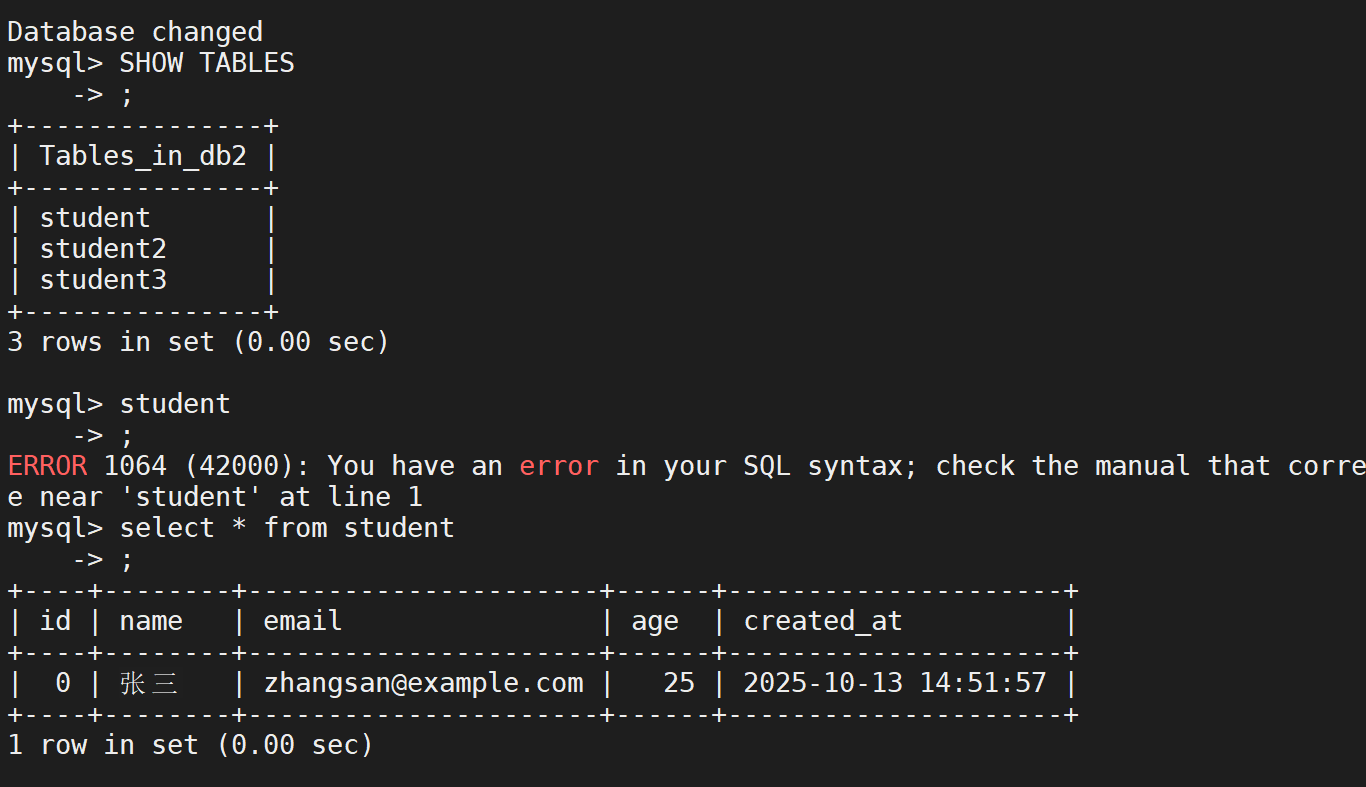
先进行一次备份

然后进行修改表

增加了一条记录,此时在刚才的备份文件中不存在我们这个操作,所以要到二进制日志文件中寻找
先寻找到二进制文件的位置,再进行操作
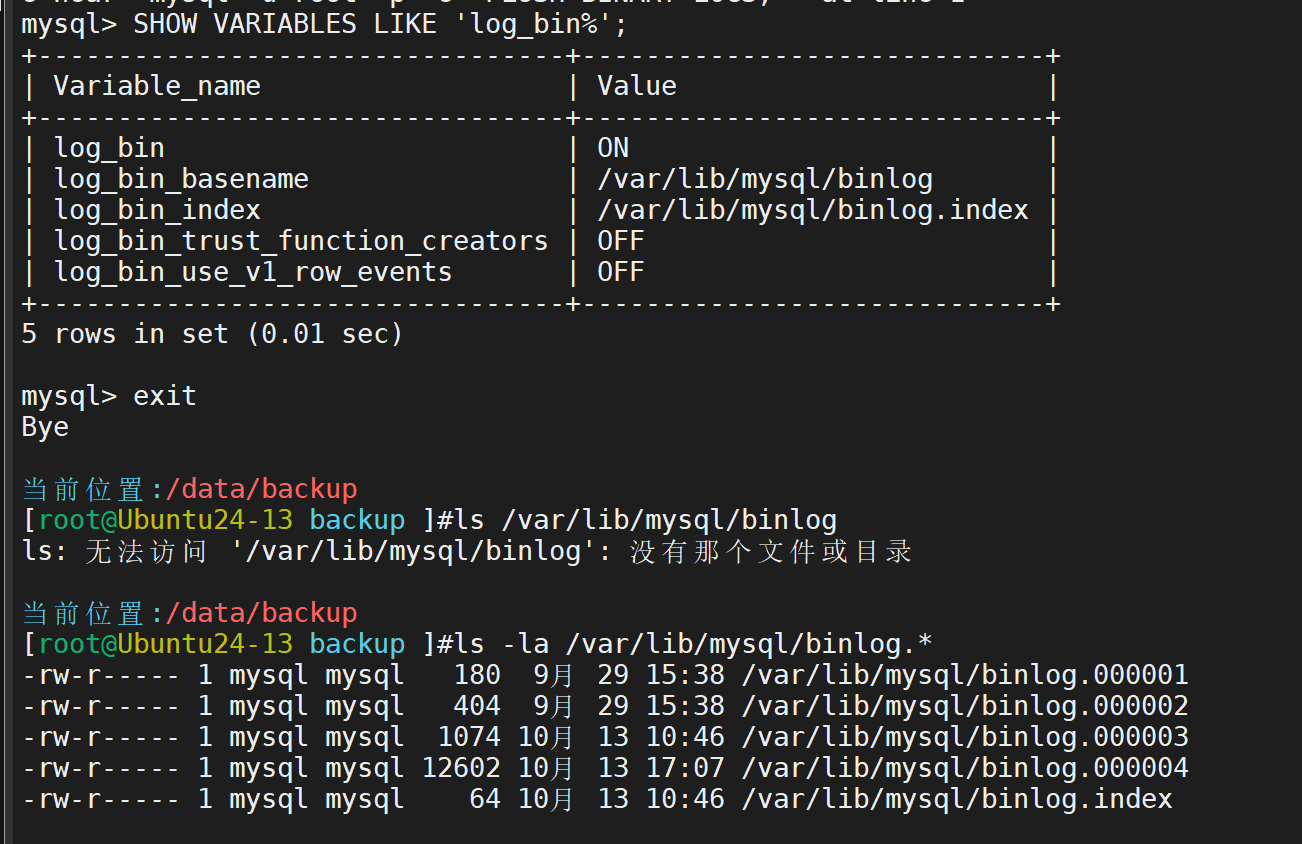

在导出的二进制备份文件中找到删除行,将其注释掉

转移到我们事先准备好的主机上
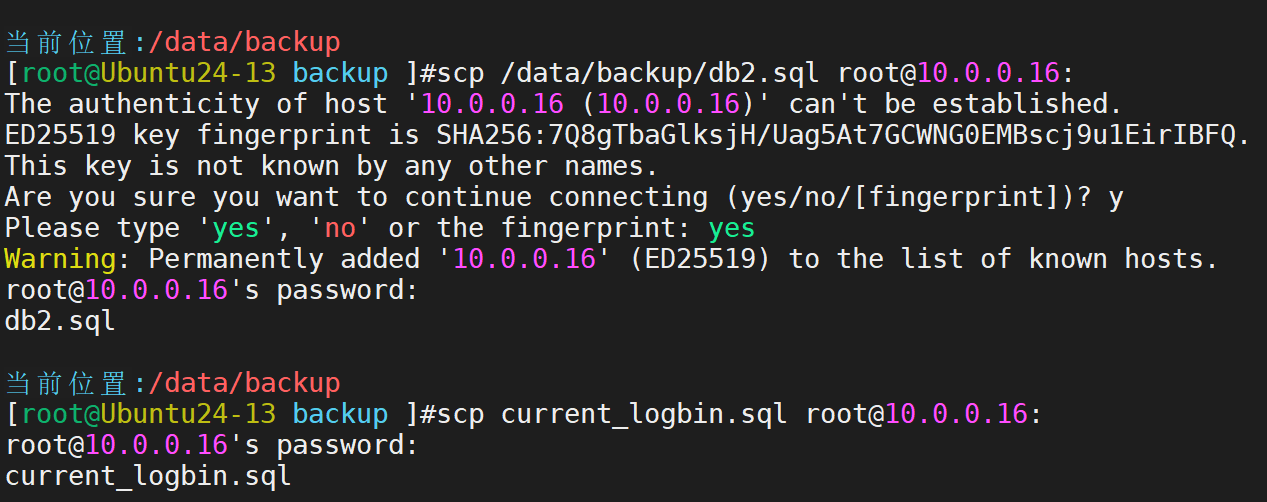
导入其数据库
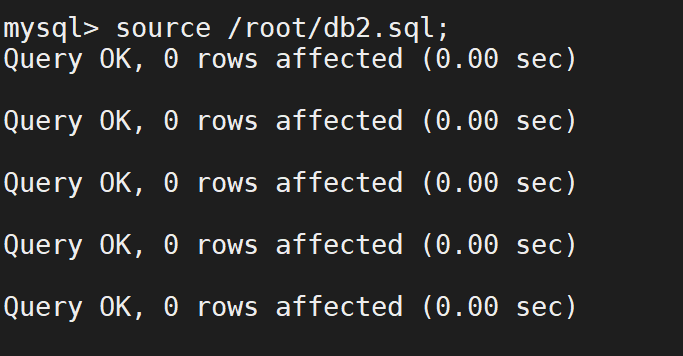
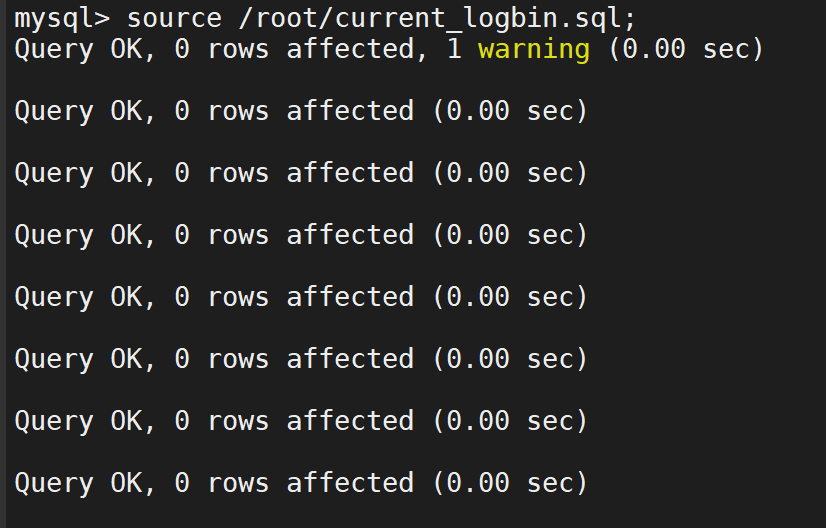
确认其效果
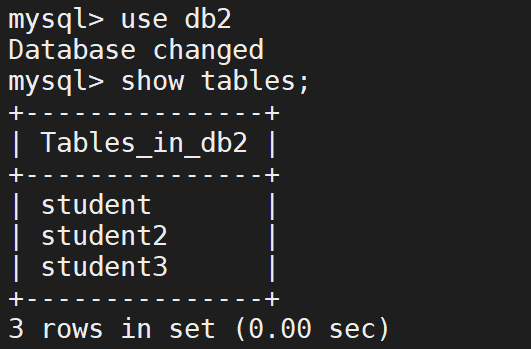
将其数据导出

再将导出数据传输给需要修复的主机
再在主机上进行修复
之后数据便修复如初
3. MySQL复制的原理特点与不足
一、MySQL 主从复制原理
1. 主库写入二进制日志(Binary Log)
关键进程:主库的 Binlog Dump Thread
步骤:事务提交时,主库将数据变更按顺序写入二进制日志(binlog)。
Binlog Dump Thread监听从库的连接请求,推送 binlog 事件。
核心文件:mysql-bin.00000X(二进制日志文件)
mysql-bin.index(索引文件,记录所有 binlog 文件名)
2. 从库 IO 线程复制日志到中继日志
关键进程:从库的 I/O Thread
步骤:I/O Thread 连接主库,请求 binlog 变更。
主库通过 Binlog Dump Thread推送 binlog 事件。
从库 I/O Thread 将接收到的数据写入中继日志(Relay Log)。
核心文件:relay-log.00000X(中继日志文件)
relay-log.index(中继日志索引文件)
3. 从库 SQL 线程执行中继日志
关键进程:从库的 SQL Thread
步骤:SQL Thread 读取中继日志中的事件。
解析并执行 SQL 语句(或重放行变更),应用数据到从库。
执行完成后更新 relay-log.info记录当前位置。
关键文件:relay-log.info(记录 SQL Thread 执行进度)
二、不同复制架构对比
1. 多从复制
架构:1 个主库 → N 个从库
特点:读请求分摊到多个从库,提升读性能。
减少主库单点故障风险。
适用场景:读多写少的业务(如电商、内容平台)。
2. 级联复制(主-从-从)
架构:主库 → 一级从库 → 二级从库
特点:减少主库推送 binlog 的压力。
数据同步延迟层级叠加(二级从库延迟更高)。
适用场景:超大规模集群,需分散主库负载。
3. 多主复制(双主/环状复制)
架构:多个主库互相复制
特点:无单点故障,写请求可分摊。
需解决数据冲突(如自增ID冲突、同时更新同一行)。
适用场景:多数据中心容灾,写负载均衡(需业务层规避冲突)。
4. 半同步复制
原理:主库提交事务前,需确保至少一个从库已接收 binlog。
流程:主库执行事务 → 写入 binlog。
主库等待至少一个从库返回 ACK(确认收到 binlog)。
主库提交事务,返回客户端成功。
优势:数据一致性更强:避免主库宕机导致数据丢失(对比异步复制)。
故障切换更安全:从库数据至少包含主库已提交的事务。
不足:
性能损耗:主库需等待从库 ACK,增加延迟(通常 1~100ms)。
退化风险:从库超时未响应时,自动退化为异步复制。
适用场景:金融交易、订单系统等对数据一致性要求高的场景。
三、半同步 vs 异步复制
特性 | 异步复制 | 半同步复制 |
|---|---|---|
数据安全性 | 低(主库提交即返回,数据可能丢失) | 高(至少一个从库确认接收) |
性能 | 高(无等待) | 中(受网络延迟影响) |
故障切换风险 | 高(从库可能缺失最新数据) | 低(从库数据与主库一致) |
适用场景 | 日志分析、读扩展场景 | 金融、支付等高一致性场景 |
iptables 防火墙
4.iptables 防火墙的基本框架和使用
四表
filte:默认表,负责数据包过滤(允许/拒绝);
nat:网络地址转换,用于IP/端口映射
mangle:修改数据包元数据(如 TTL、TOS 标记),用于高级路由或 QoS
raw:绕过连接追踪,用于高性能场景或自定义连接状态处理
五链
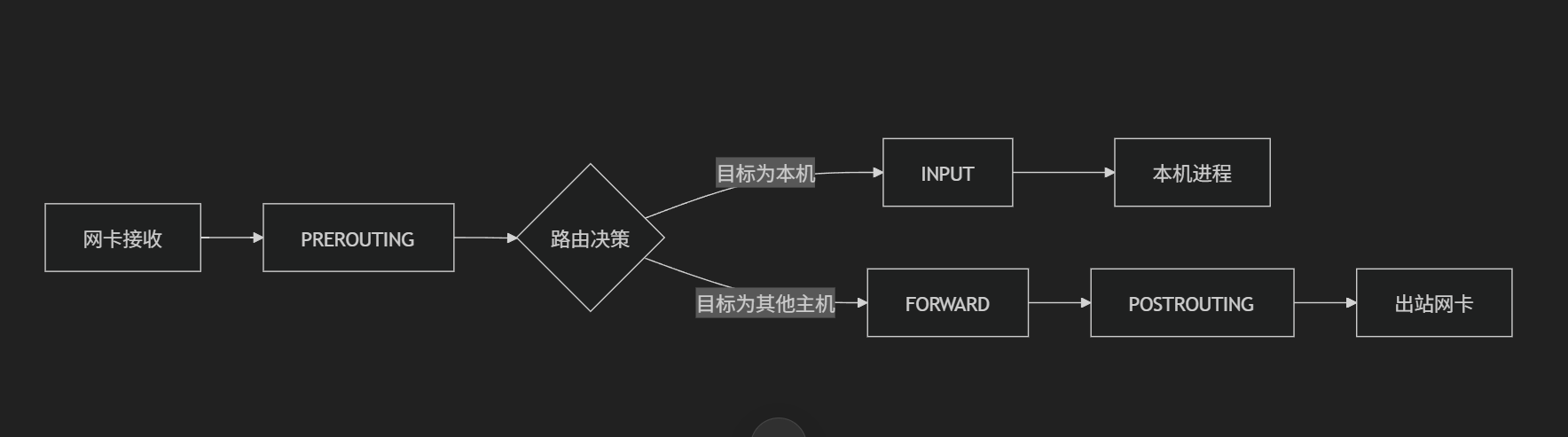
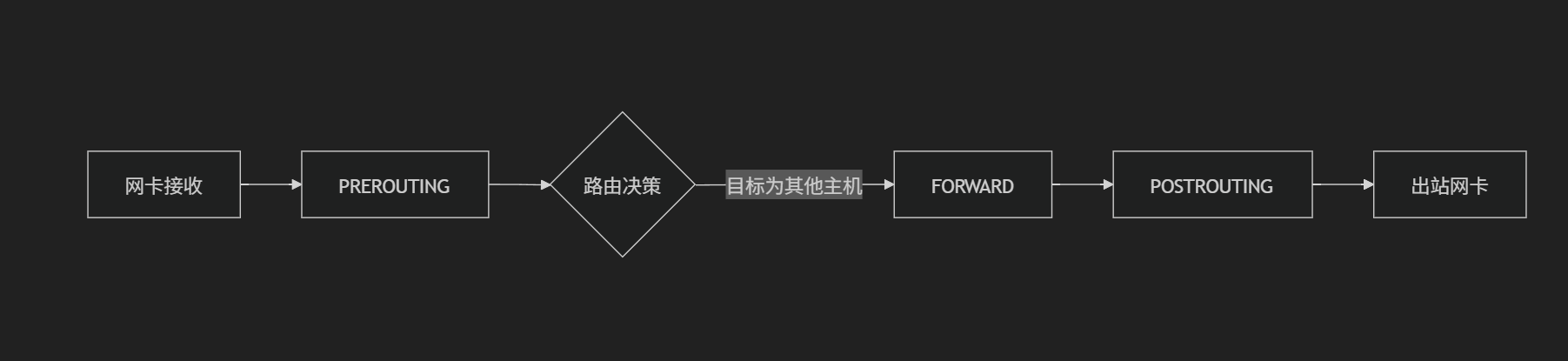
PREROUTING:数据包进入网卡后、路由决策前
INPUT:数据包路由后目标是本机
FORWARD:数据包路由后目标是其他主机
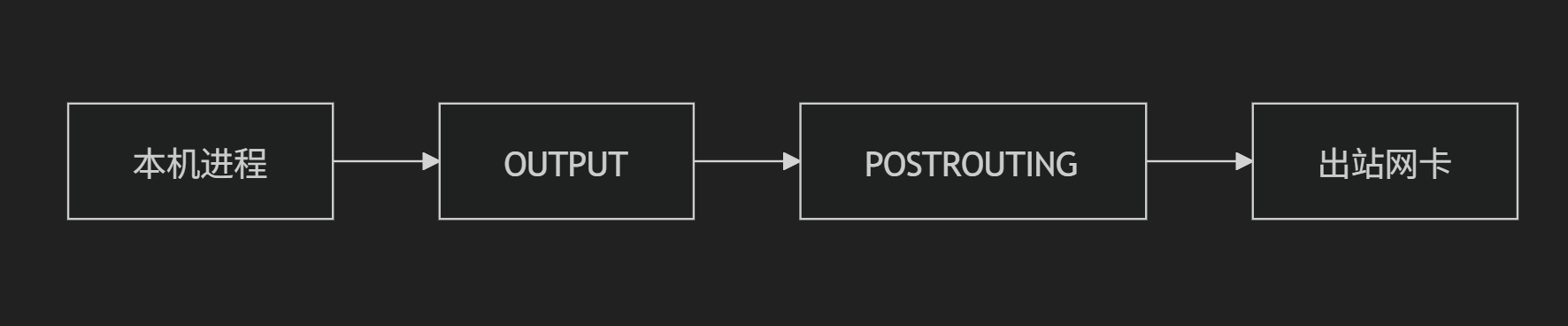
OUTPUT:本机生成的数据包发出前
POSTROUTING:数据包离开网卡前
流程示意图
入站流量(外部 → 本机)
出站流量(本机 → 外部)
转发流量(外部 → 本机 → 外部)
三、规则匹配顺序与默认策略
1. 规则匹配顺序
链内规则:从上到下逐条匹配,第一条匹配的规则生效(后续规则跳过)。
默认策略:当所有规则均不匹配时,执行链的默认策略(ACCEPT 或 DROP)。
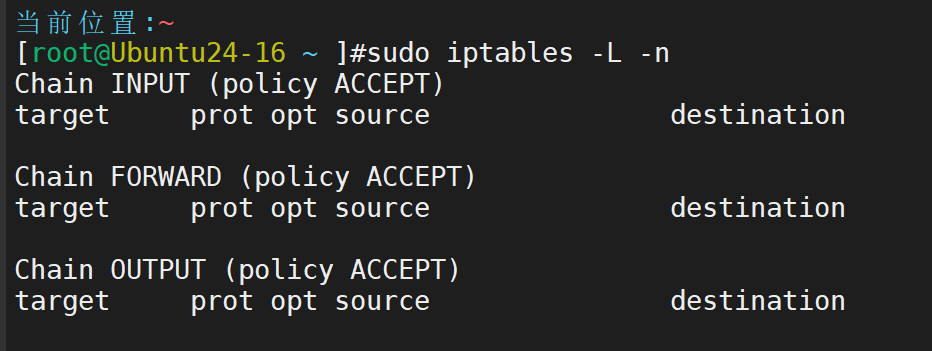
2.查看默认策略
可以看到我们目前默认表的INPUT,FORWARD,OUTPUT位置的全部都是允许通过,我们目前还没有为这台主机的访问与被访问进行限制
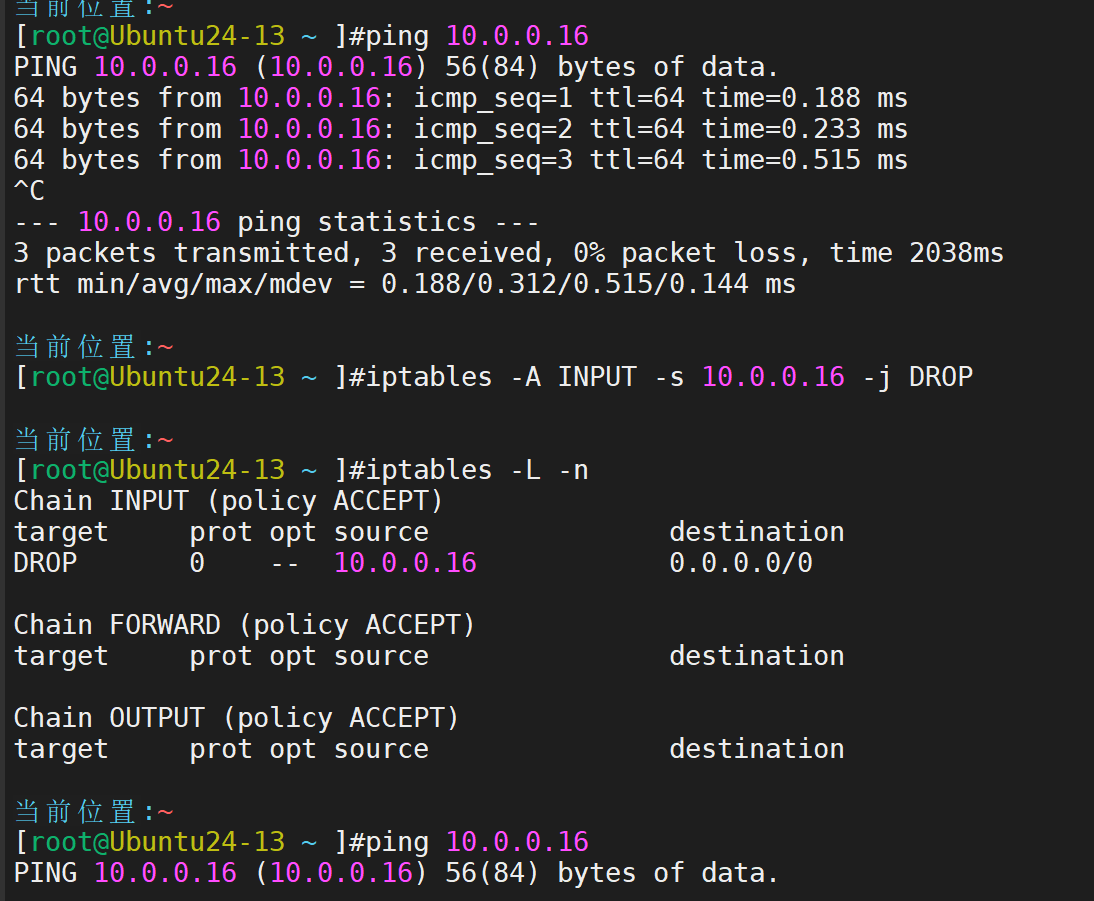
我们尝试添加一条策略,禁止10.0.0.16访问
iptables -A INPUT -s 10.0.0.16 -j DROP
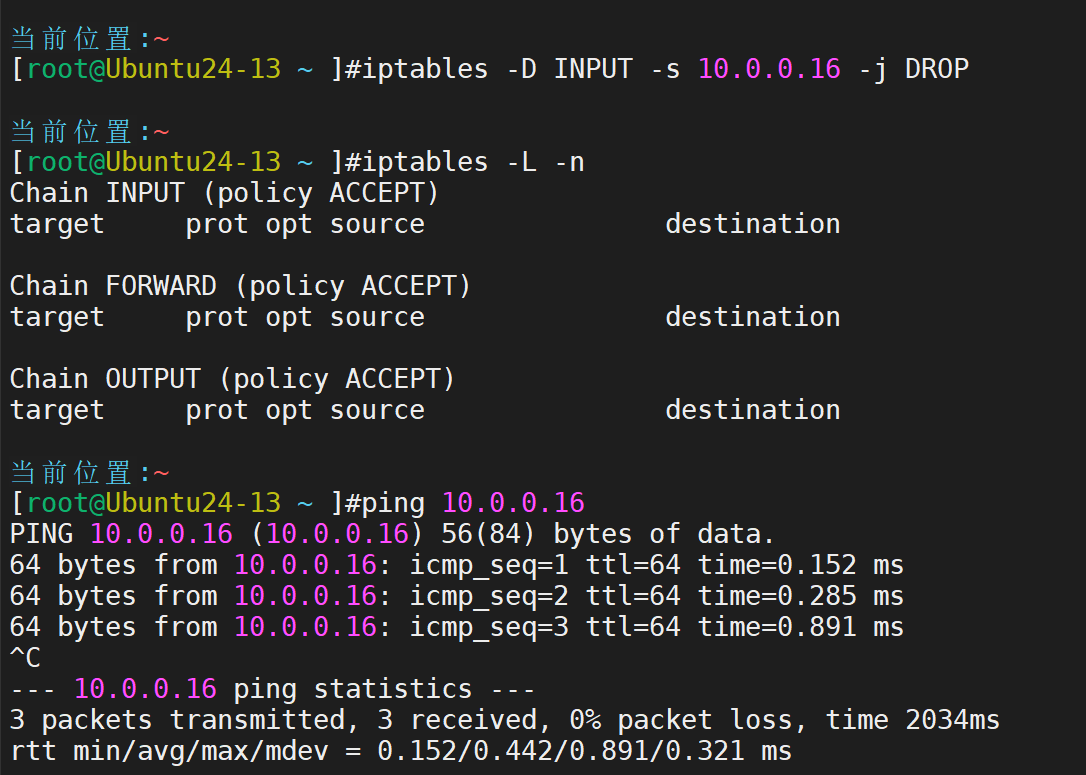
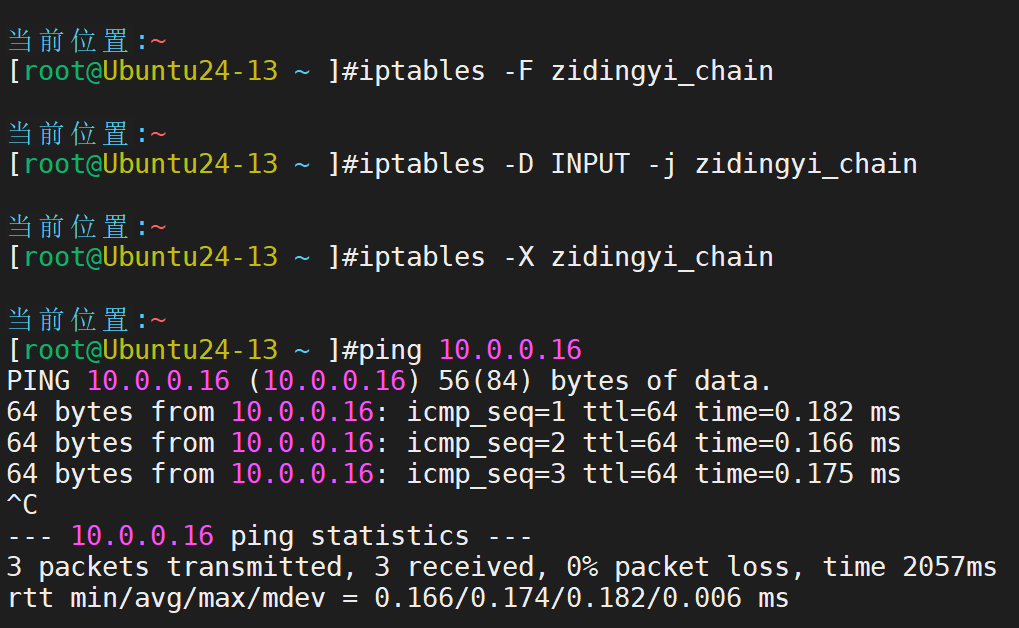
规则删除,访问恢复
自定义链的创建、使用和删除方法
iptables 中除了系统自带的五个链之外,还可以自定义链,来实现将规则进行分组,重复调用的目的。自定义链添加规则之后,要作为系统链的 target 与之关联,才能起到作用
添加(名称可以根据其负责的具体任务来命名)
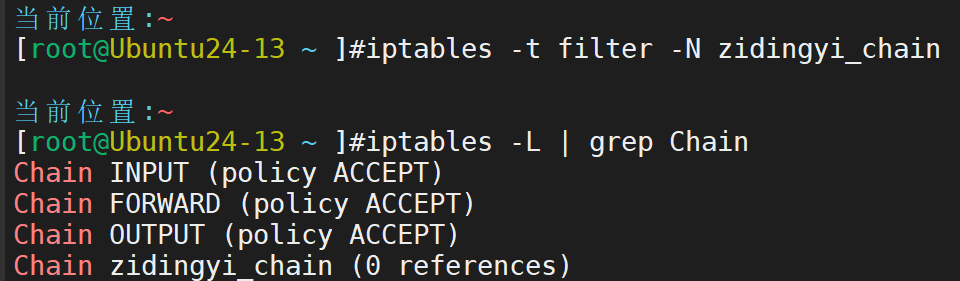
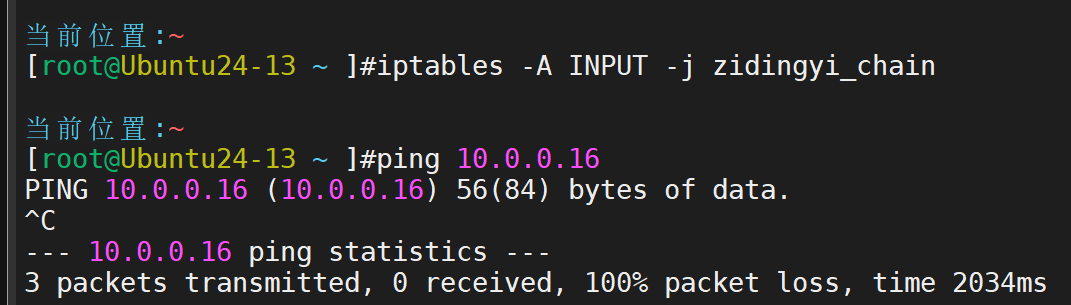
接下来添加规则


此时依旧可以ping通,是因为还没有跳转到自定义链上,跳转后,即可禁止
然后:先清空,再移除,再删除,再进行验证
LVS
5.简述 LVS(Linux Virtual Server)的三种工作模式
1. NAT 模式
工作原理
负载均衡器(Director)作为客户端和 RS 的 “中间人”:客户端请求数据包先到 Director,Director 修改数据包的目标 IP(改为 RS 的 IP)后转发给 RS;RS 处理后将响应数据包发回 Director,Director 再修改响应包的源 IP(改为自己的 IP)后返回给客户端。
所有进出流量均经过 Director,RS 的网关必须指向 Director。
网络拓扑

优缺点
优点:RS 无需公网 IP,安全性高;网络配置简单,RS 可使用任意操作系统。
缺点:Director 成为流量瓶颈,并发能力有限;仅支持 TCP/UDP 协议。
适用场景
小规模集群、对安全性要求较高的场景,如小型企业内部服务负载均衡。
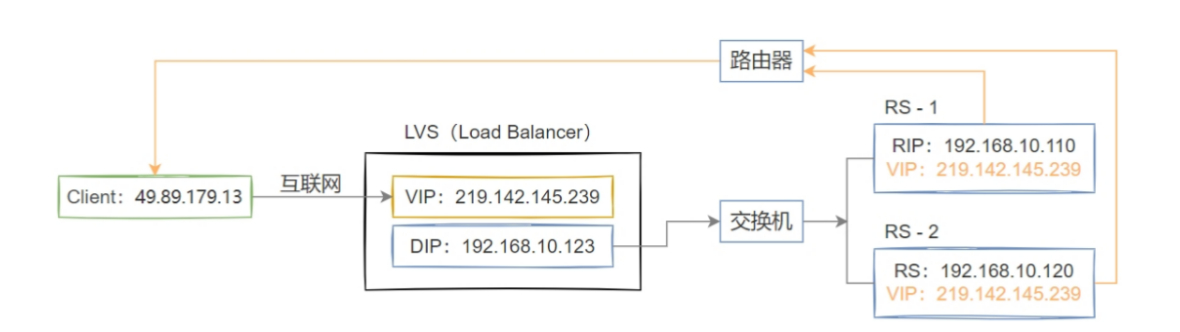
2. DR 模式
工作原理
Director 仅处理 “请求流量”,响应流量直接从 RS 返回客户端:客户端请求到 Director 后,Director 不修改 IP,仅修改数据包的目标 MAC 地址(改为目标 RS 的 MAC),将包转发给 RS;RS 识别到目标 IP 是 VIP(需在本地配置 VIP 的回环地址),处理后直接将响应包发给客户端(源 IP 为 VIP,目标 IP 为客户端 IP)。
网络拓扑
优缺点
优点:Director 仅转发请求,无流量瓶颈,并发能力极强;响应速度快。
缺点:RS 需与 Director 在同一二层网络;RS 需特殊配置,且需与 Director 同操作系统。
适用场景
高并发、高性能需求的场景,如大型网站、电商平台的前端负载均衡。
3. TUN 模式
工作原理
基于 IP 隧道技术转发数据包:Director 收到客户端请求后,将原数据包封装在一个新的 IP 数据包中(外层 IP 的目标地址为 RS 的 IP),转发给 RS;RS 解封装后处理请求,直接将响应包发给客户端(无需经过 Director,源 IP 为 VIP)。
RS 需支持 IP 隧道协议,且需配置 VIP。
网络拓扑

优缺点
优点:RS 可跨网段部署,无流量瓶颈,并发能力强。
缺点:RS 需支持 IP 隧道协议,配置复杂;隧道封装会增加数据包开销,降低部分性能。
适用场景
大规模集群、RS 分布在不同地域 / 网段的场景,如跨机房的负载均衡服务。
ipvsadm
ipvsadm是 LVS (Linux Virtual Server) 的核心管理工具主要作用有定义虚拟服务、添加真实服务器、设置调度算法等
1. 虚拟服务管理
命令 | 作用 |
|---|---|
| 添加 TCP 虚拟服务(如 |
| 添加 UDP 虚拟服务 |
| 删除虚拟服务 |
2. 真实服务器管理
命令 | 作用 |
|---|---|
| 添加真实服务器(DR 模式) |
| 添加真实服务器(NAT 模式) |
| 添加真实服务器(TUN 模式) |
| 删除指定真实服务器 |
| 修改服务器权重(如 |
3. 调度算法配置
命令 | 算法 | 适用场景 |
|---|---|---|
| 轮询 (Round Robin) | 服务器性能均等时 |
| 加权轮询 | 服务器性能不均(需配合 |
| 最少连接 (Least Conn) | 处理时间差异大的服务(如数据库) |
| 加权最少连接 | 高性能服务器分配更多请求 |
| 源地址哈希 (Source Hash) | 会话保持(同一客户端固定访问同一服务器) |
7.LVS NAT 模式和 DR 模式实验(ip可自行配置)
实验环境:至少三台 Linux 服务器(可使用虚拟机),其中一台作为 LVS 负载均衡器(Director Server,如 IP:10.0.0.13),两台作为后端真实服务器(Real Server,如 RS1:192.168.8.14,RS2:192.168.8.15,均安装 Web 服务,且 Web 页面内容略有不同以区分),客户端主机一台(如 IP:10.0.0.12)。
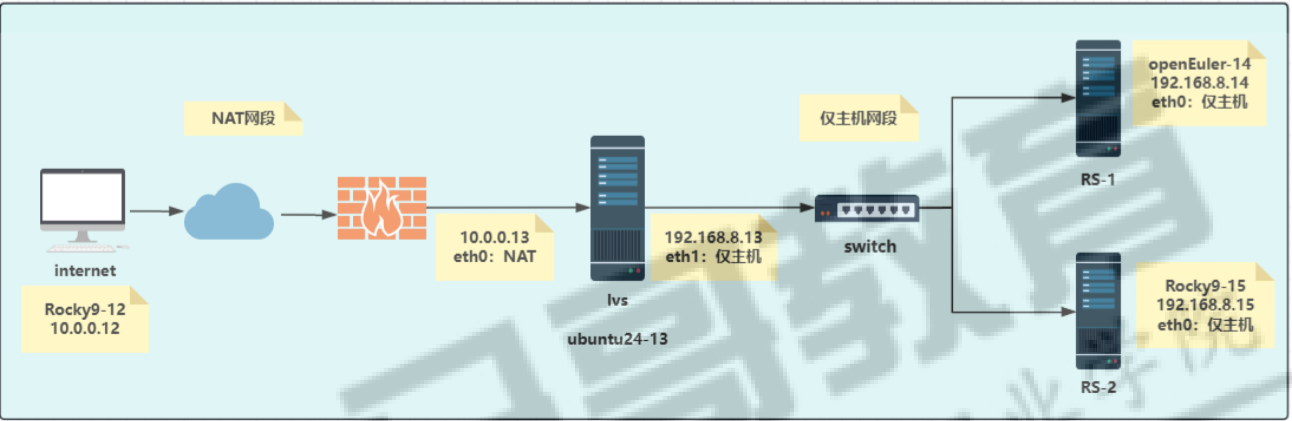
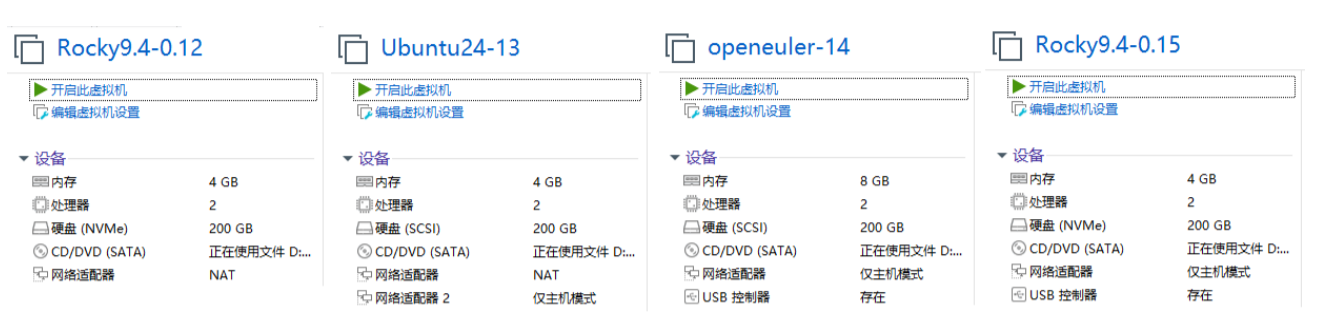
实验要求:
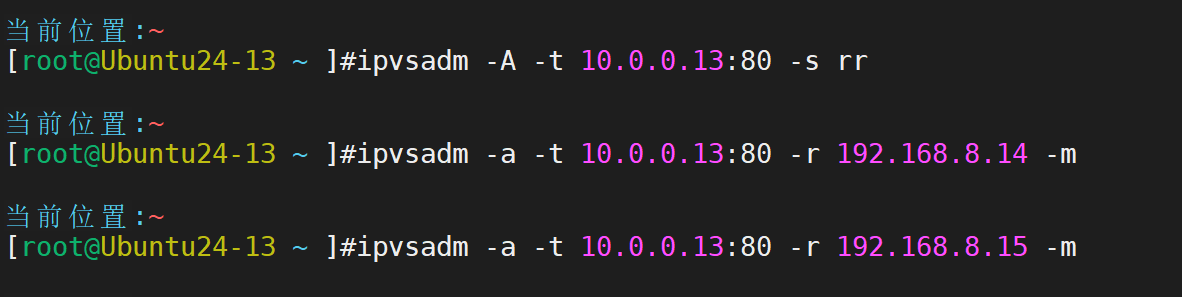
1.配置 LVS NAT 模式:在 Director Server 上安装 ipvsadm 工具,开启路由转发功能,配置 LVS 虚拟服务(如虚拟 IP:10.0.0.13,端口 80,调度算法为轮询),添加后端 Real Server(RS1 和 RS2)。在客户端主机上多次访问虚拟 IP 10.0.0.13,观察是否能交替访问到 RS1 和 RS2 的 Web 页面,验证负载均衡效果,并记录配置步骤(包括 ipvsadm 命令、路由转发开启命令等)
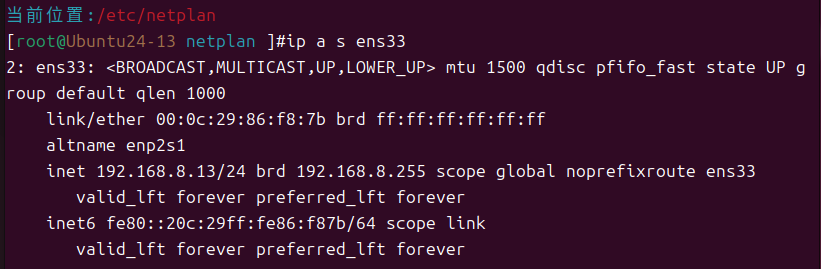
第一步,定制主机ip
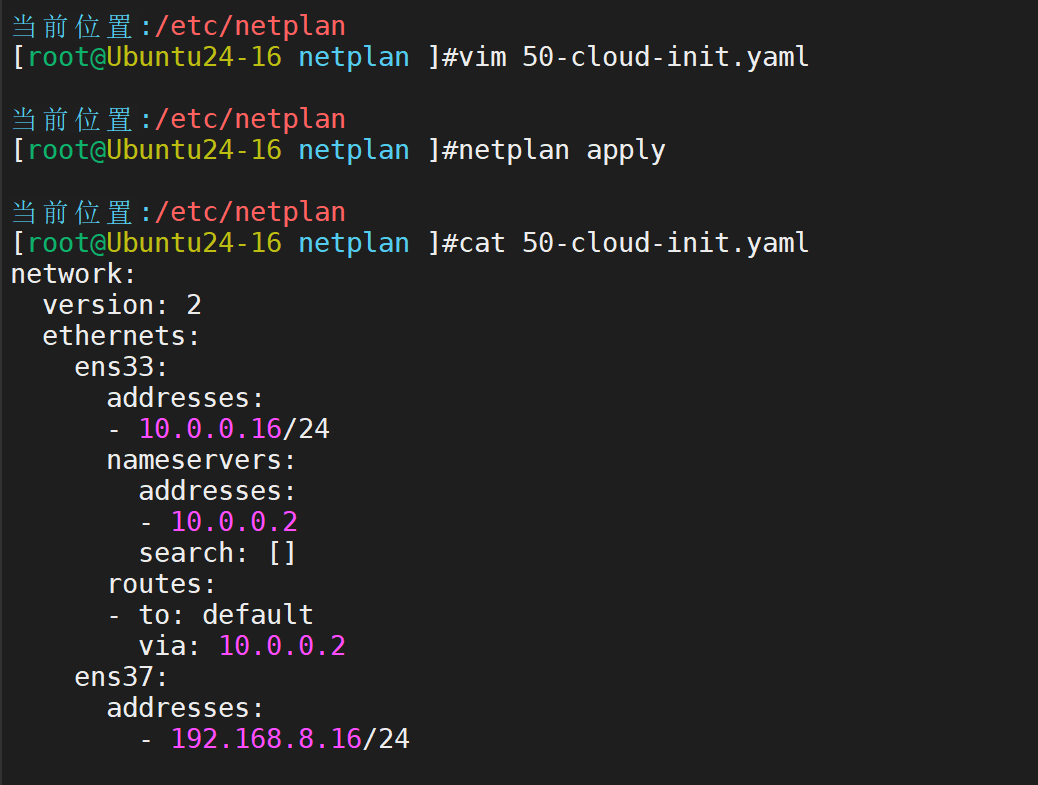
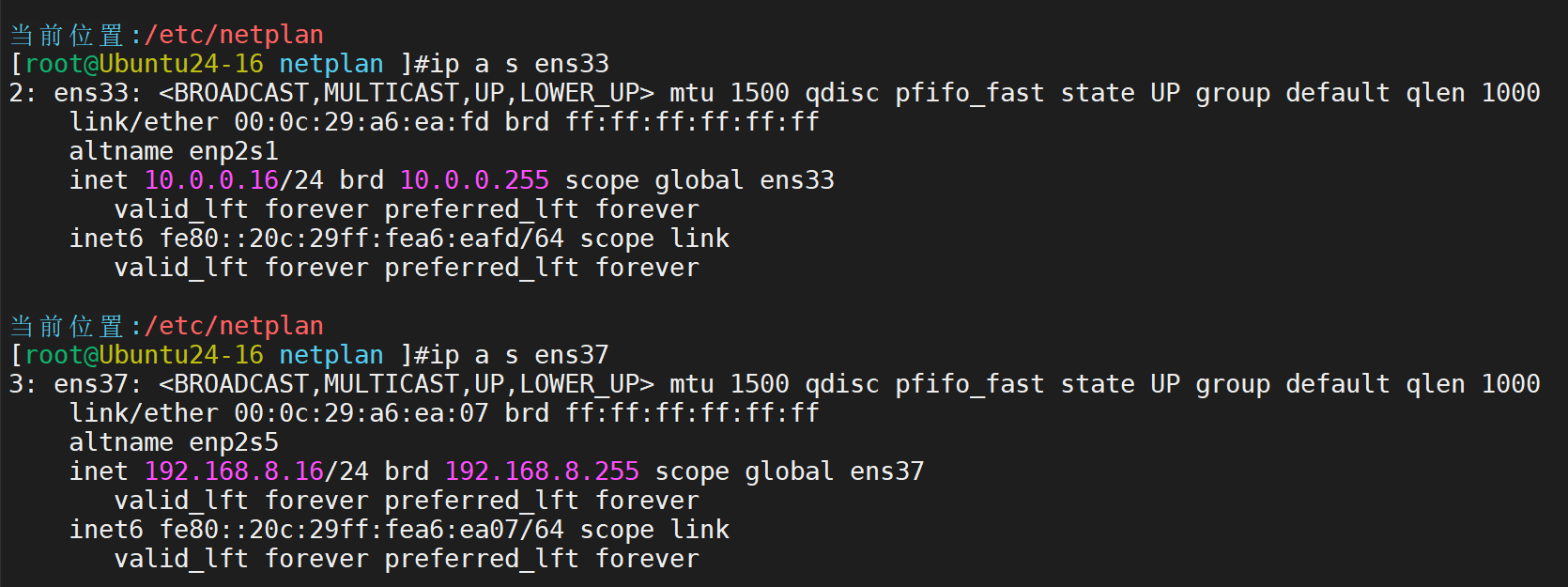
定制网卡配置,ens33是NAT模式,ens37是仅主机模式,仅主机模式不用配置网关
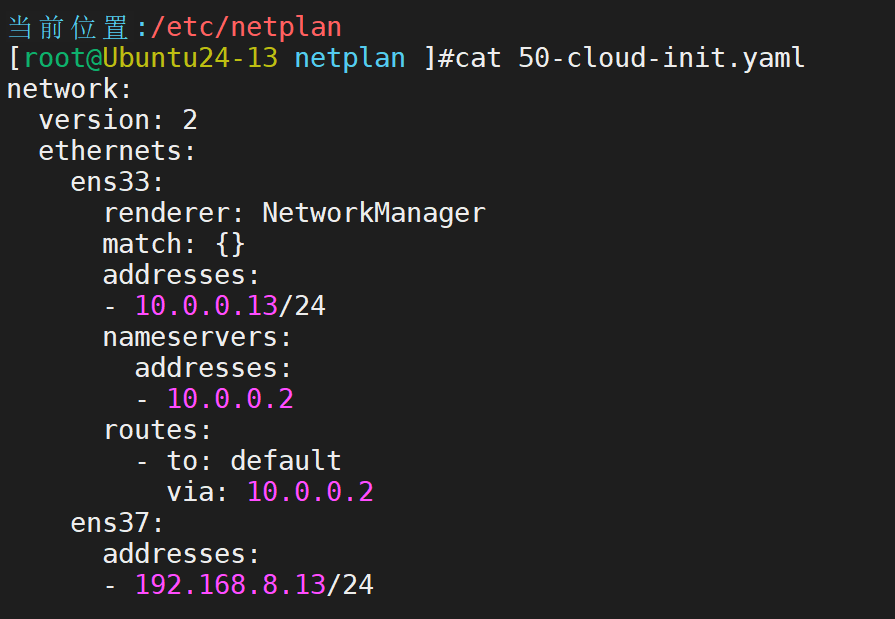
应用(注意:如果只有一块网卡,ens37会添加失败)


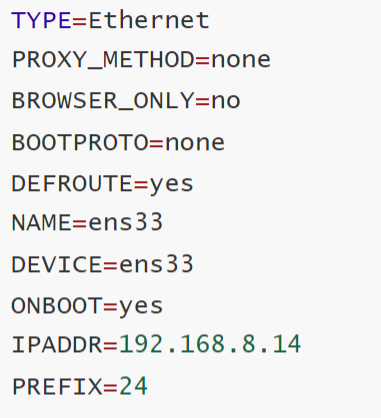
接下来定制两台后端
对于192.168.8.14
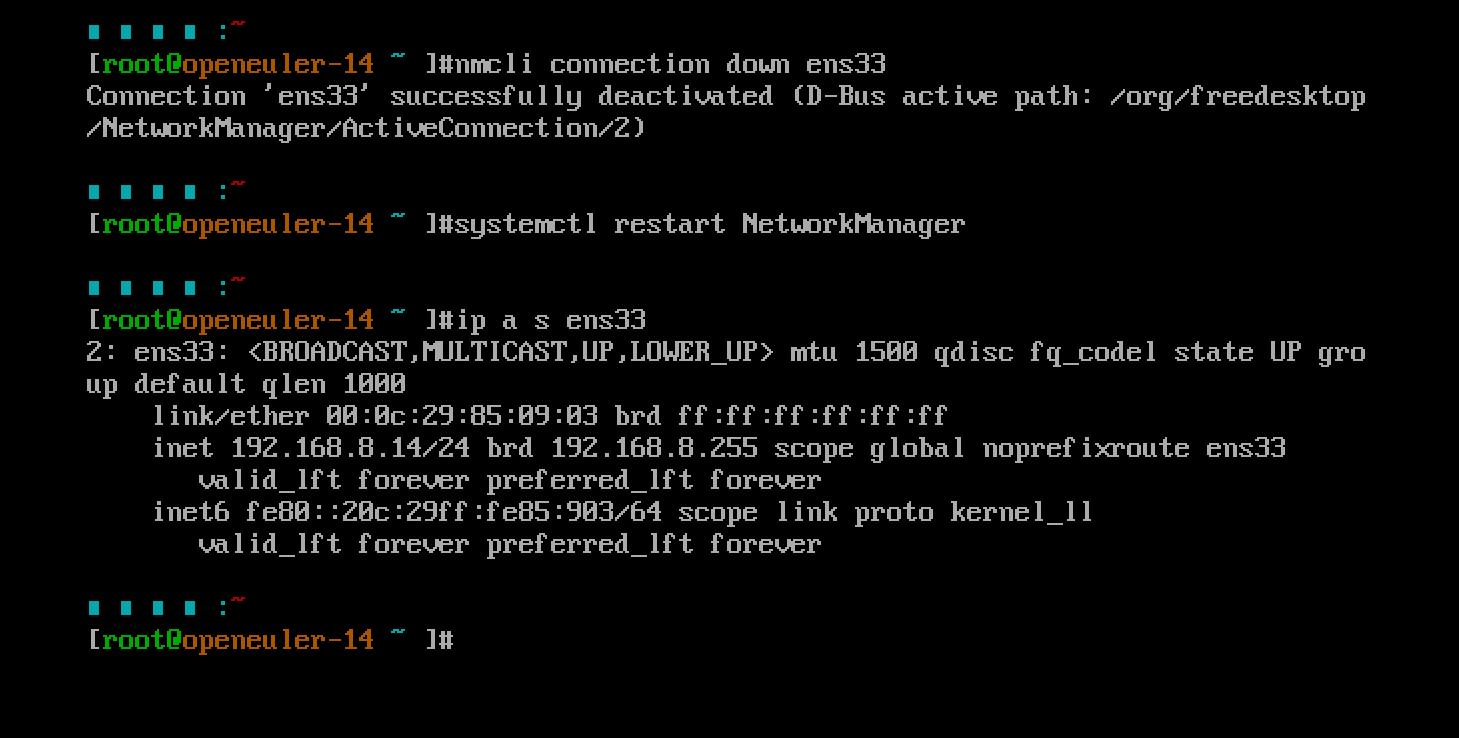
对于192.168.8.15
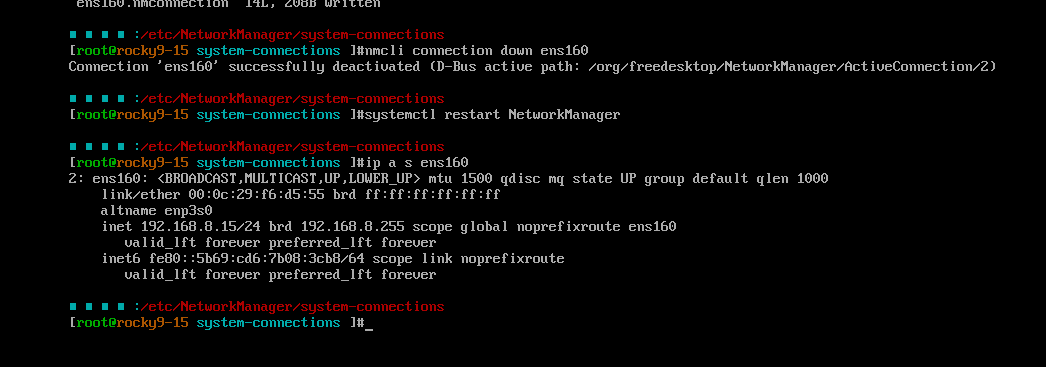
第二步:配置各个主机
lvs

RS1主机定制网关

RS2主机定制网关
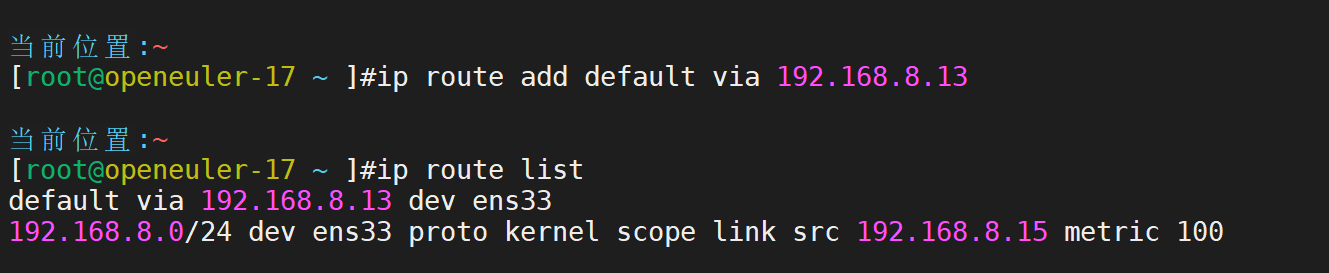
lvs-rs1部署web服务
定制本地镜像服务
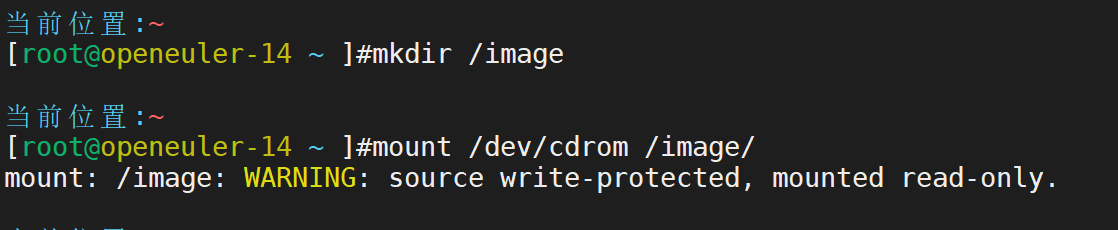
关闭防火墙服务和selinux

部署httpd服务
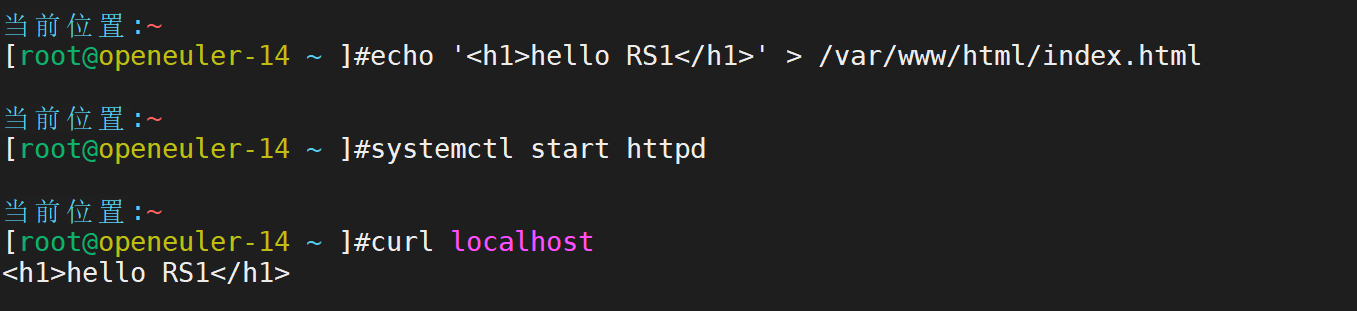
lvs-rs2部署web服务,和rs1一样只需要更换数字
lvs-server主机定制集群
安装服务

定制lvs集群服务,增加主机
查看集群主机效果
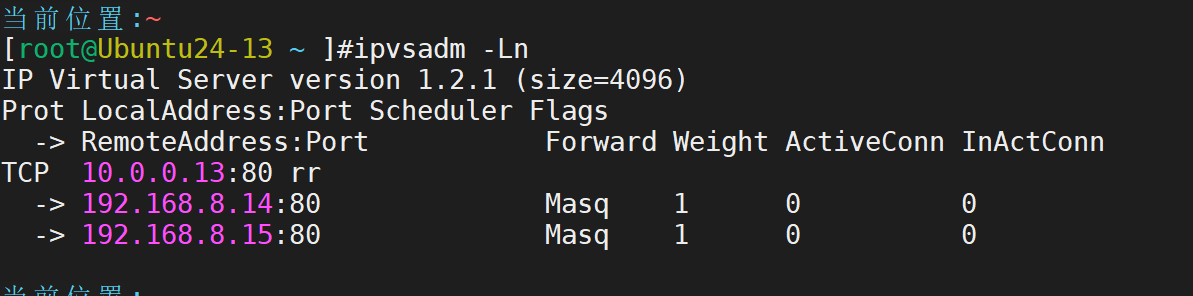
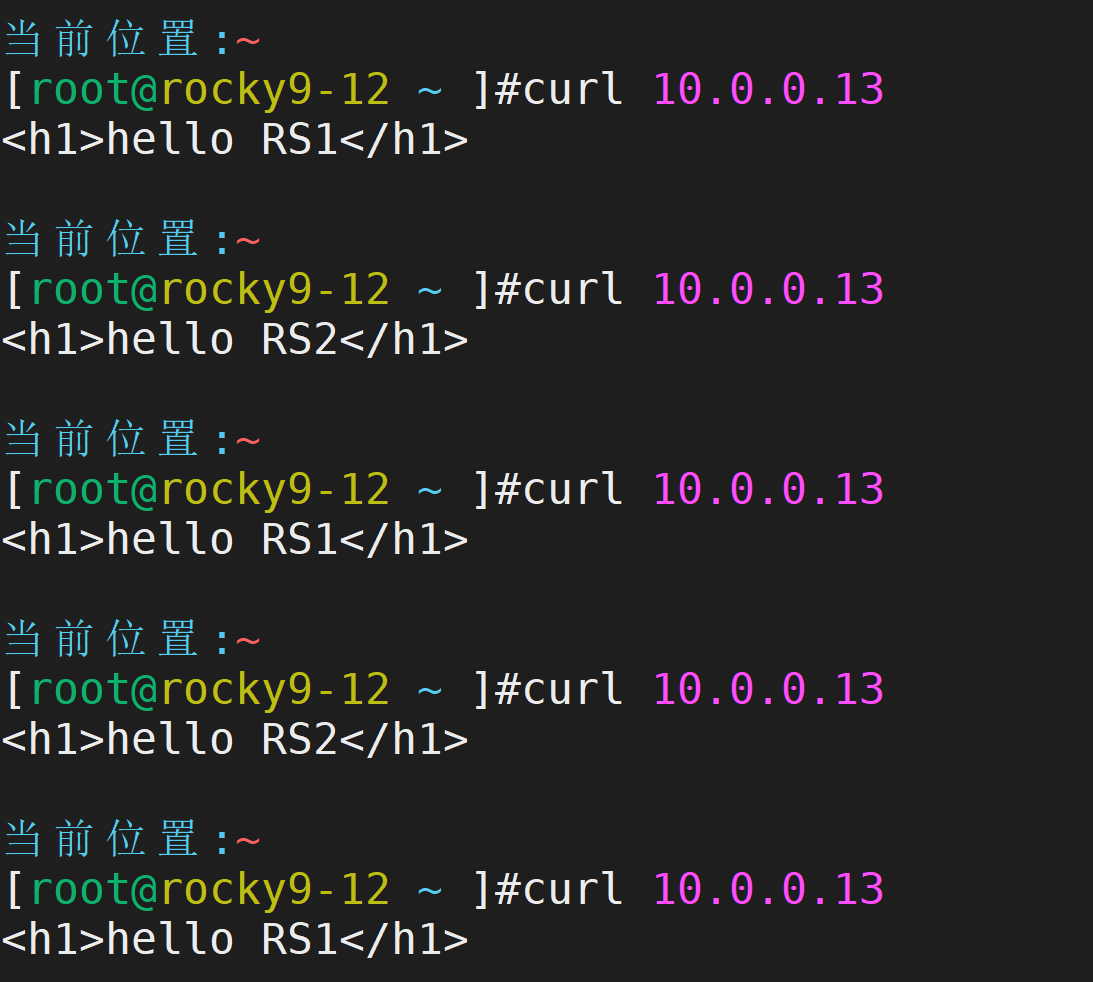
测试
2.清理 LVS NAT 模式的配置,然后配置 LVS DR 模式:在 Director Server 上配置虚拟 IP(VIP:192.168.1.200),安装 ipvsadm 工具,配置 LVS 虚拟服务(调度算法为加权轮询,给 RS1 和 RS2 设置不同的权重,如 RS1 权重 2,RS2 权重 1),添加后端 Real Server(注意 DR 模式下 Real Server 的配置,如在回环接口上配置 VIP、抑制 ARP 响应等)。在客户端主机上多次访问 VIP 192.168.1.200,观察访问情况,验证负载均衡是否按照权重分配请求,记录配置步骤、测试结果和 DR 模式与 NAT 模式配置的差异。
DR实验需要的机器比较多
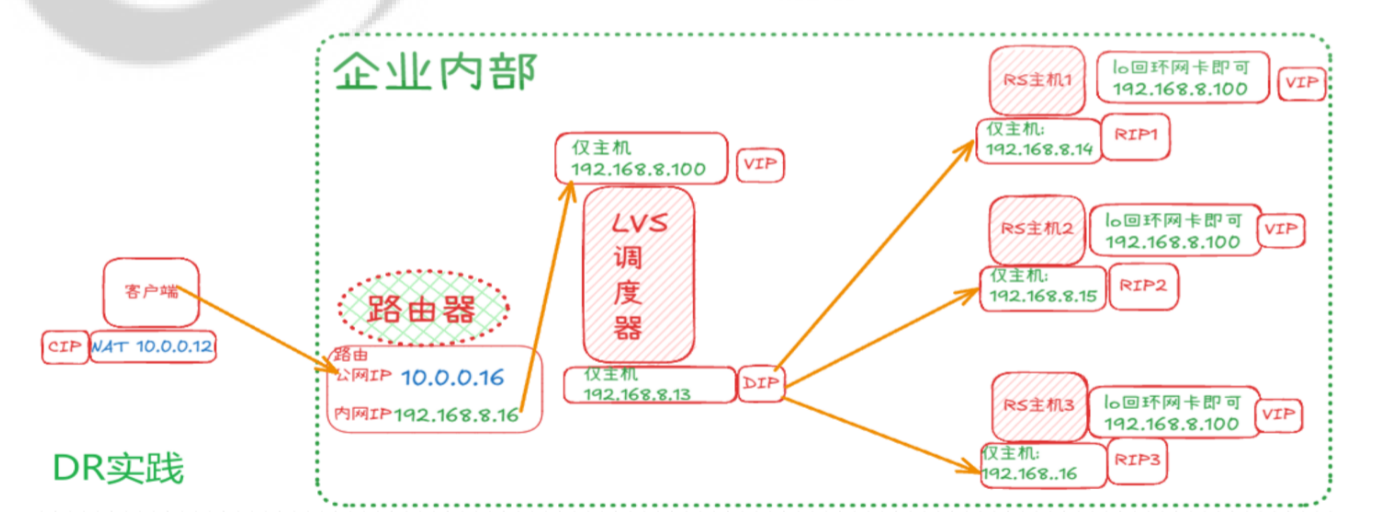
定制lvs-route主机ip
查看
定制lvs-server主机ip,仅主机模式下,不用配置网关

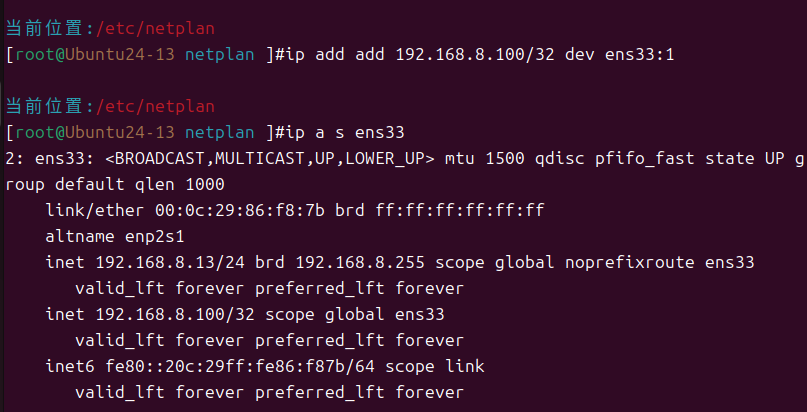
lvs-RS1主机ip
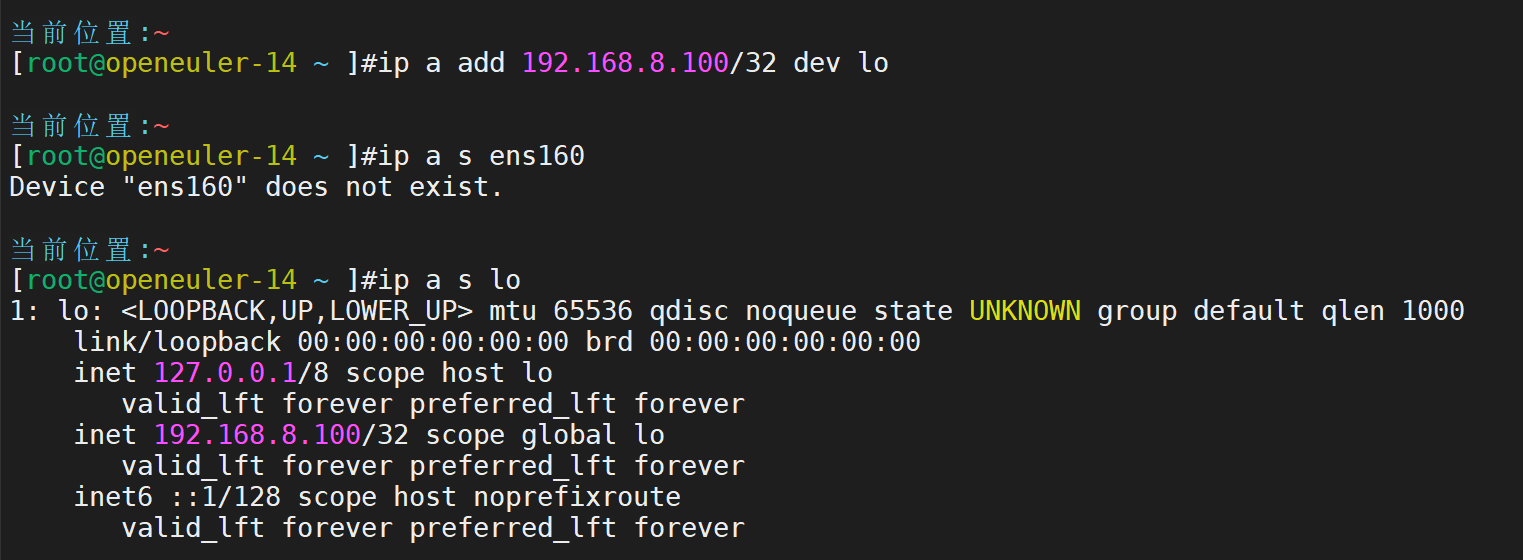
lvs-RS2主机ip
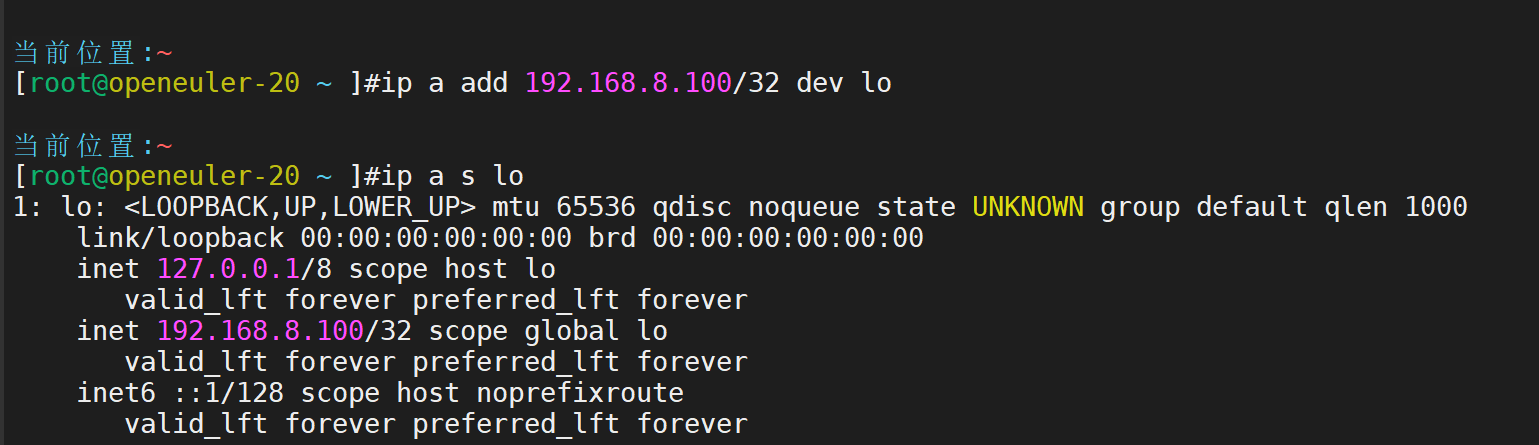
lvs-RS3主机ip
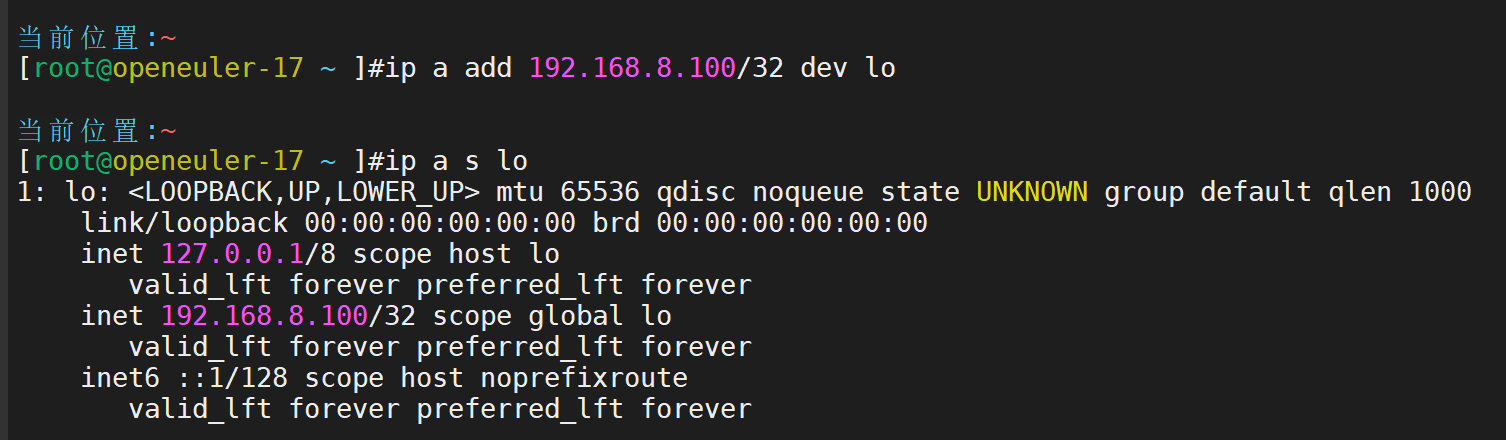
vip地址测试
将客户端的默认路由定为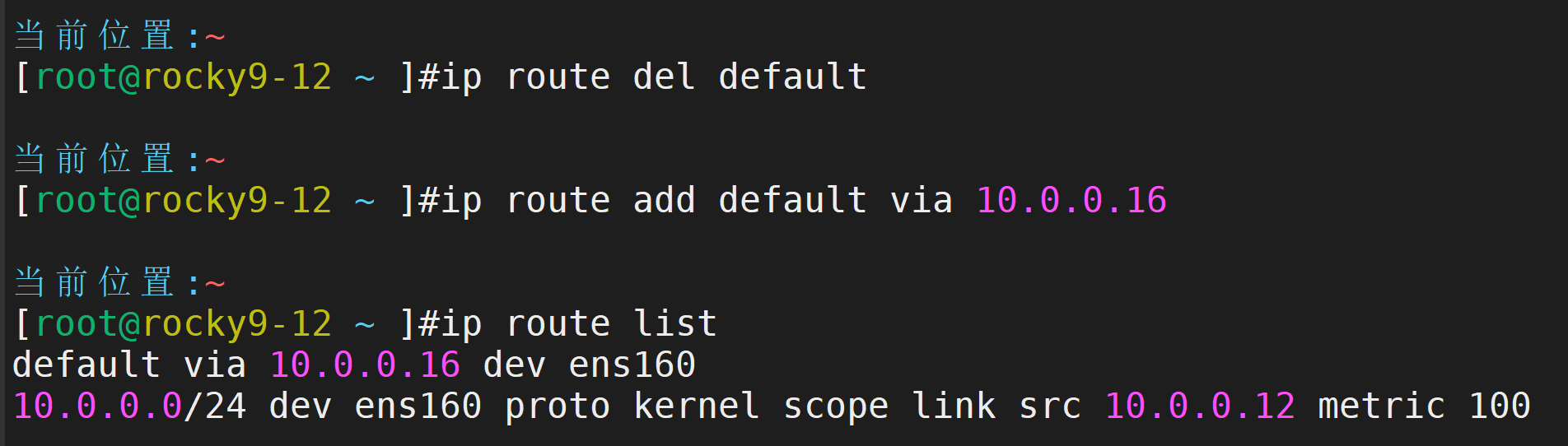
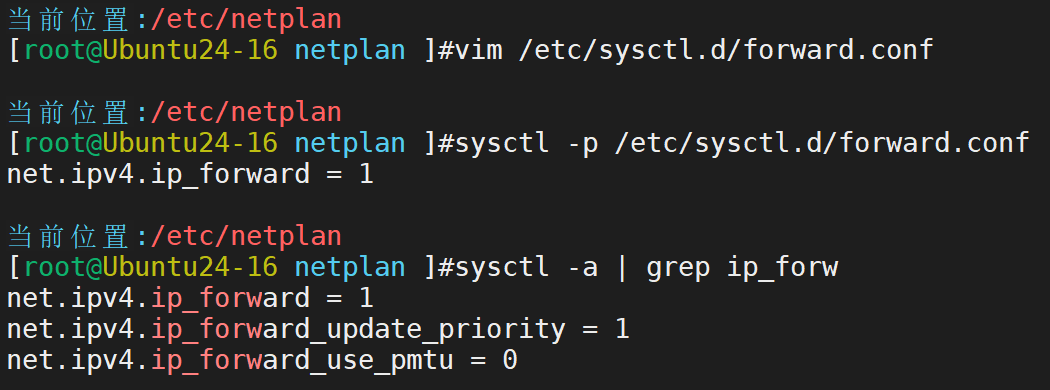
lvs-route主机定制数据包转发
lvs-route定制流向lvs的网关地址

lvs-server主机定制数据包转发-该部分的数据转发能力是非必须的
定制路由策略
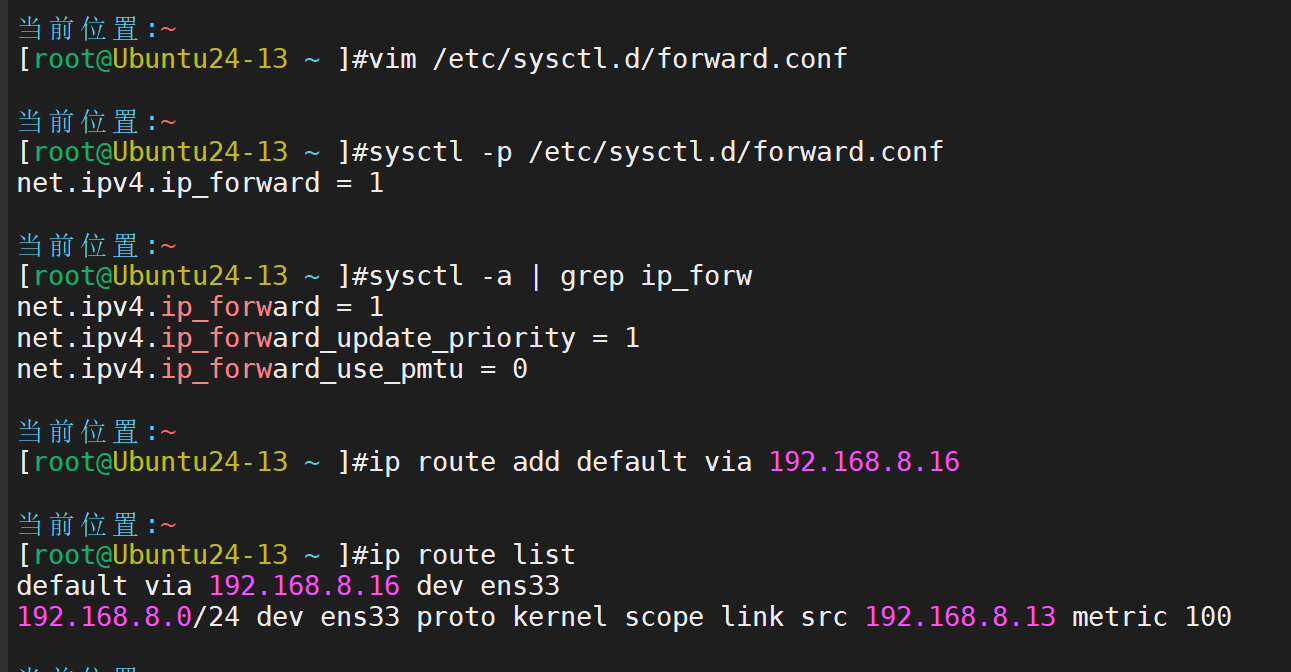
lvs-rs1主机定制默认的网关出口为lvs主机

lvs-rs1主机定制arp策略
lvs-rs2主机定制arp策略
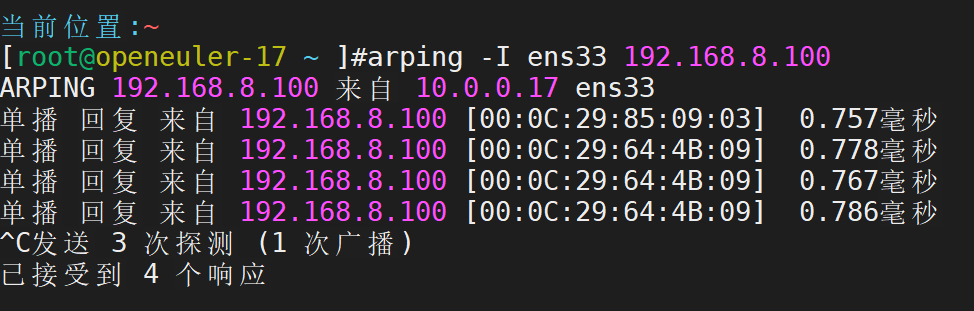
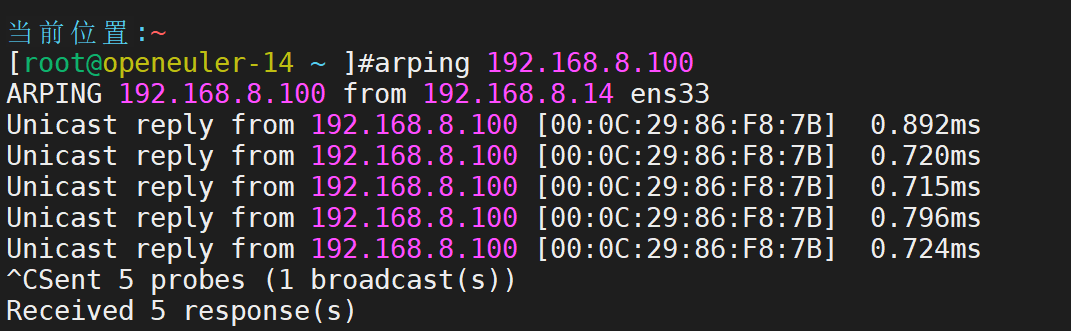
在任意一台 192.168.8.0 网段中,进行arp测试
lvs-server主机定制集群

查看
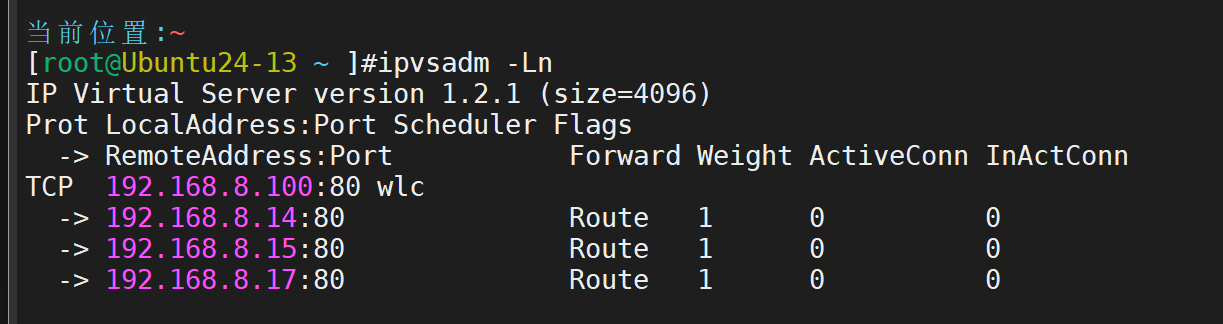
测试
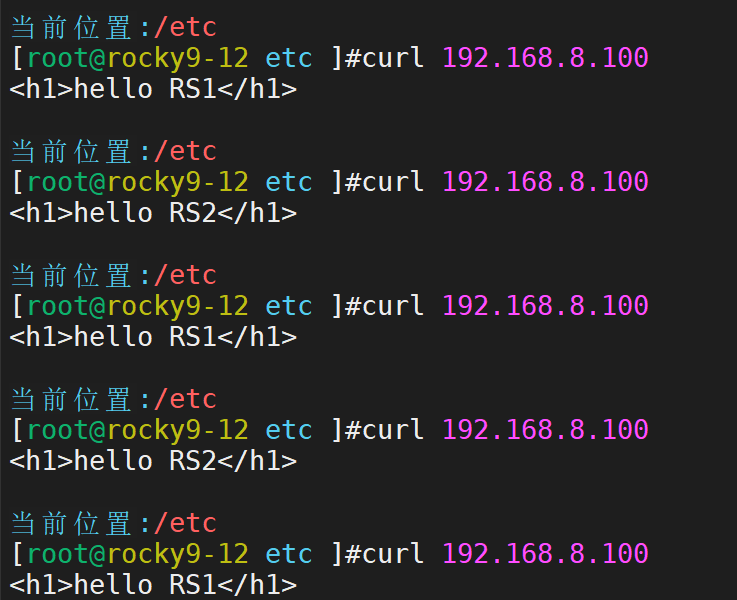
keepalived
6. keepalived 的工作原理和使用方式及 VRRP(虚拟路由冗余协议)的核心机制
keepalived 本质是基于VRRP 协议实现的高可用软件,核心作用是避免网络或服务的单点故障,在 LVS 集群中主要负责调度器(Director)的冗余备份。
一、VRRP(虚拟路由冗余协议)核心机制
角色划分:同一 VRRP 组内有两种角色,MASTER(主节点) 和BACKUP(备节点)。同一时间只有 1 个 MASTER 提供服务,BACKUP 节点处于监听状态。
虚拟 IP(VIP):VRRP 组会对外公布一个共享的虚拟 IP 地址,客户端通过 VIP 访问服务,无需关心具体是哪个节点提供服务。
选举机制:节点通过优先级(0-255,默认 100)竞争 MASTER 角色。优先级最高的节点成为 MASTER;若优先级相同,IP 地址更大的节点胜出。
心跳维护:MASTER 节点会周期性(默认 1 秒)发送VRRP 多播报文(目标地址 224.0.0.18,协议号 112),告知组内其他节点自己的存活状态。BACKUP 节点若超时(默认 3 秒)未收到报文,会认为 MASTER 故障,触发重新选举。
二、keepalived 在 LVS 集群中的高可用实现
LVS 集群中,keepalived 主要为调度器(Director) 提供冗余,确保 LVS 入口不中断,核心实现包括 “故障检测” 和 “自动切换” 两部分。
1. 故障检测(健康检查)
keepalived 的健康检查分两层,确保整个 LVS 集群可用:
第一层:Director 节点自身检测:通过 VRRP 报文监听 MASTER 节点状态,若 MASTER 的 VRRP 报文中断,判定为节点故障。
第二层:后端 Real Server(RS)检测:keepalived 会主动对 LVS 后端的 RS 进行健康探测,支持多种方式:
TCP 端口探测:检测 RS 的指定端口(如 80、443)是否能连通。
HTTP/HTTPS 探测:发送 HTTP 请求(如访问/health接口),根据返回状态码(如 200)判断服务是否正常。
ICMP ping 探测:通过 ping 命令检测 RS 的网络连通性。若检测到 RS 故障,keepalived 会自动将其从 LVS 的路由表(IPVS)中移除,避免流量转发到故障节点。
2. 自动切换(故障转移)
当 MASTER Director 节点故障时,切换流程如下:
BACKUP 节点超时未收到 MASTER 的 VRRP 报文,判定 MASTER 故障。
BACKUP 节点提升自身为新的 MASTER,同时发送免费 ARP(Gratuitous ARP)报文。
免费 ARP 报文会更新局域网内其他设备(如交换机)的 ARP 缓存,将 VIP 与新 MASTER 的 MAC 地址绑定。
新 MASTER 接管 LVS 调度任务,继续转发客户端流量到正常的 RS,整个过程用户无感知。
三、keepalived 的通信方式
keepalived 的通信主要分为两类:VRRP 协议通信和健康检查通信。
1. VRRP 报文通信(主备节点间)
传输方式:多播(Multicast),目标地址固定为224.0.0.18,协议号112。
报文内容:包含 VRRP 版本、组 ID、MASTER 节点 IP、优先级、认证信息等。
认证机制:支持两种认证方式,确保报文不被伪造:
明文认证:报文中携带预设的密码(最多 8 位),节点接收后验证密码一致性。
IPsec 认证:更安全的加密认证,适合对安全性要求高的场景。
2. 健康检查通信(Director 与 RS 间)
传输方式:单播(Unicast),由 Director 节点主动向 RS 发送探测包(TCP SYN、HTTP 请求等)。
通信逻辑:根据配置的探测间隔(如 2 秒)和超时时间(如 5 秒),循环检测 RS 状态,结果直接用于更新 IPVS 路由表。
四、邮件通知功能的配置原理
keepalived 支持在节点状态切换(如 MASTER 变 BACKUP、BACKUP 变 MASTER)时发送邮件告警,核心配置逻辑如下:
依赖基础:需要服务器安装邮件发送工具(如sendmail或postfix),确保能通过 SMTP 协议发送邮件。
核心配置项:在 keepalived 配置文件(/etc/keepalived/keepalived.conf)中定义邮件参数:
smtp_server:指定 SMTP 邮件服务器地址(如smtp.163.com)。
smtp_connect_timeout:SMTP 连接超时时间(如 30 秒)。
from:发件人邮箱(如keepalived_alarm@163.com)。
to:收件人邮箱(如admin@xxx.com)。
触发逻辑:通过notify_master、notify_backup、notify_fault脚本触发邮件发送。例如,当节点切换为 MASTER 时,执行notify_master脚本,脚本内调用mail或sendmail命令发送邮件。
五、脑裂现象的原因与解决方法
“脑裂” 是 keepalived 的致命问题,指主备节点同时认为自己是 MASTER,都持有 VIP,导致客户端流量混乱。
1. 脑裂产生的原因
网络中断:主备节点之间的网络链路断开(如交换机故障、网线松动),备节点收不到主节点的 VRRP 报文,误判主节点故障并抢占 MASTER 角色。
配置错误:备节点的 VRRP 优先级配置高于主节点,导致备节点启动后直接抢占 MASTER。
防火墙拦截:防火墙规则阻止了 VRRP 报文(协议号 112、多播地址 224.0.0.18),备节点无法接收主节点的报文。
主节点资源耗尽:主节点 CPU、内存耗尽或负载过高,导致无法发送 VRRP 报文,备节点误判其故障。
2. 脑裂的解决方法
双线路检测:主备节点之间除了业务网络,额外搭建一条 “心跳专用网络”(如独立的网卡和交换机),避免单网络链路中断导致脑裂。
第三方仲裁:引入第三方节点(如 ZooKeeper、或另一台服务器),主备节点定期向仲裁节点报告状态,只有获得仲裁节点认可的节点才能成为 MASTER。
启用 VRRP 认证:配置明文或 IPsec 认证,防止伪造的 VRRP 报文触发错误切换。
监控与自动恢复:部署监控工具(如 Prometheus+Grafana),监控 VIP 是否在两个节点同时存在。一旦检测到脑裂,自动执行脚本(如关闭备节点的 keepalived 服务)恢复主备状态。
资源限制:为主节点配置资源阈值(如 CPU 使用率不超过 80%),当资源耗尽时主动降低 VRRP 优先级,让备节点平滑接管,避免被动触发脑裂。
8.keepalived 高可用实验(ip可自行配置)
实验环境:两台 Linux 服务器作为 LVS Director Server(Director A:192.168.1.100,Director B:192.168.1.101),两台后端 Real Server(RS1:192.168.1.102,RS2:192.168.1.103,均提供 Web 服务),虚拟 IP(VIP:192.168.1.200)。
实验要求:
1.在两台 Director Server 上安装 keepalived 服务,修改 keepalived 配置文件(设置全局配置、VRRP 实例配置,指定 VIP、优先级(Director A 优先级高于 Director B,如 Director A 优先级 100,Director B 优先级 90)、认证信息等,同时在配置文件中集成 LVS 虚拟服务和后端 Real Server 的配置)。
2.启动两台 Director Server 的 keepalived 服务,查看 keepalived 状态和 VIP 的分配情况(验证 VIP 是否在优先级高的 Director A 上)。在客户端主机上访问 VIP 192.168.1.200,验证能否正常访问 Web 服务且实现负载均衡
3.模拟 Director A 故障(如停止 Director A 的 keepalived 服务或关闭 Director A 服务器),观察 VIP 是否自动漂移到 Director B 上,客户端是否能继续通过 VIP 访问 Web 服务,实现高可用。之后恢复 Director A,观察 VIP 是否漂移回 Director A(根据配置的抢占模式),记录整个实验步骤、配置文件内容。
实践开始
首先准备好两台后端服务器,并安装和配置相关
关闭防火墙,安装好nginx
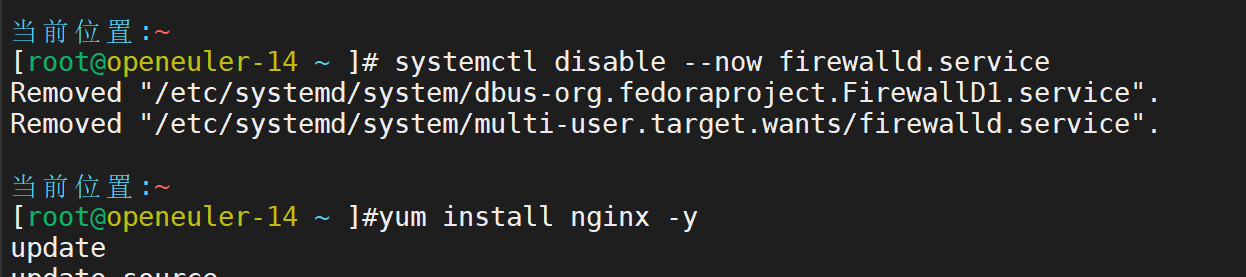

配置首页,启动服务,并配置效果


定制专属脚本,一键设置
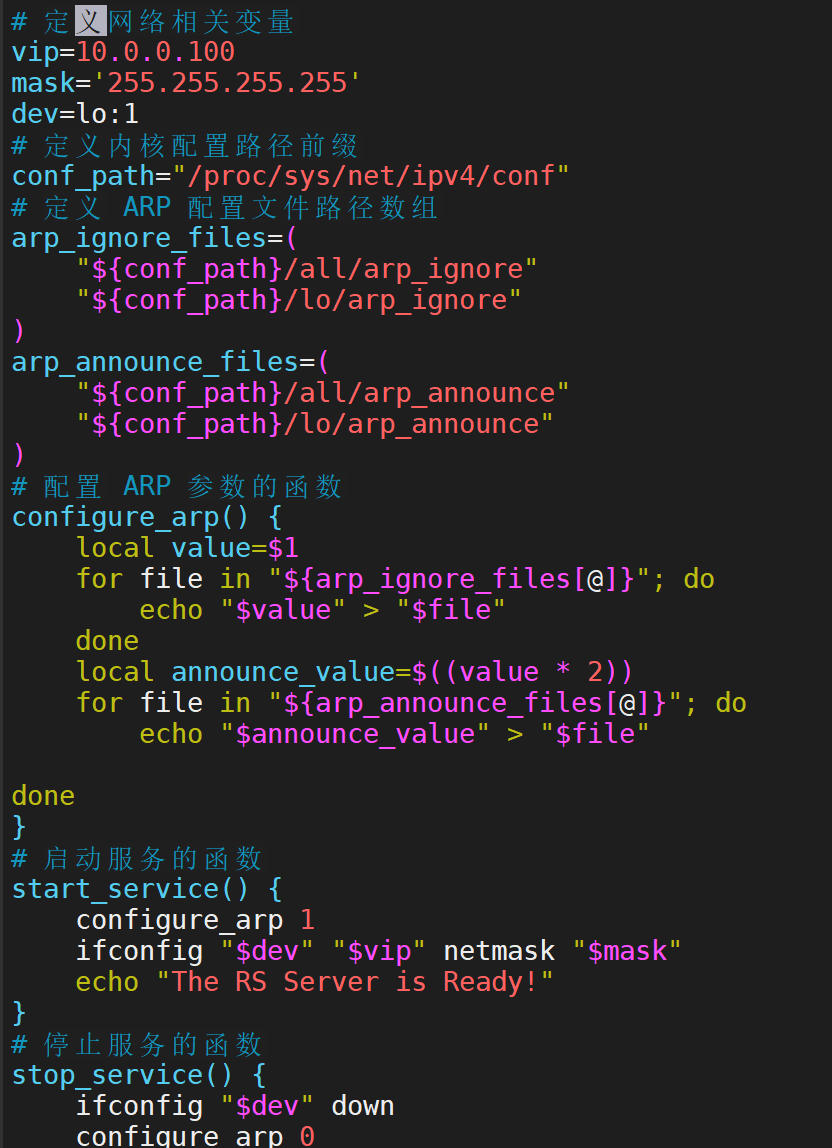
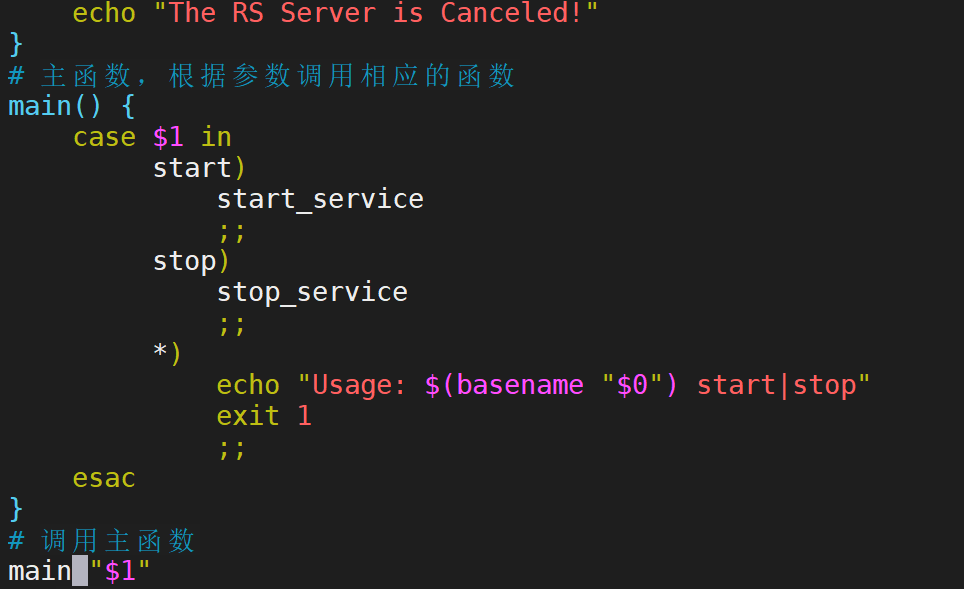
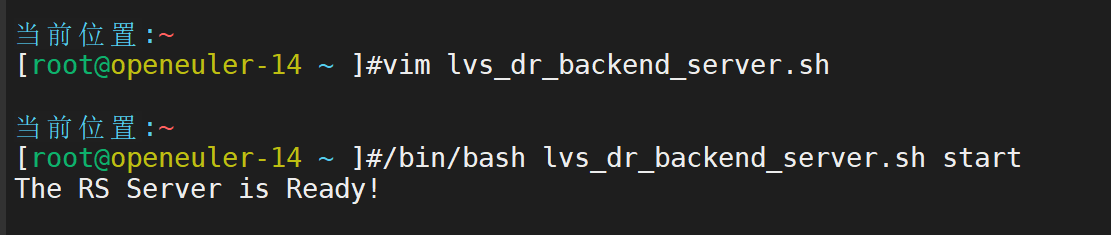
查看效果
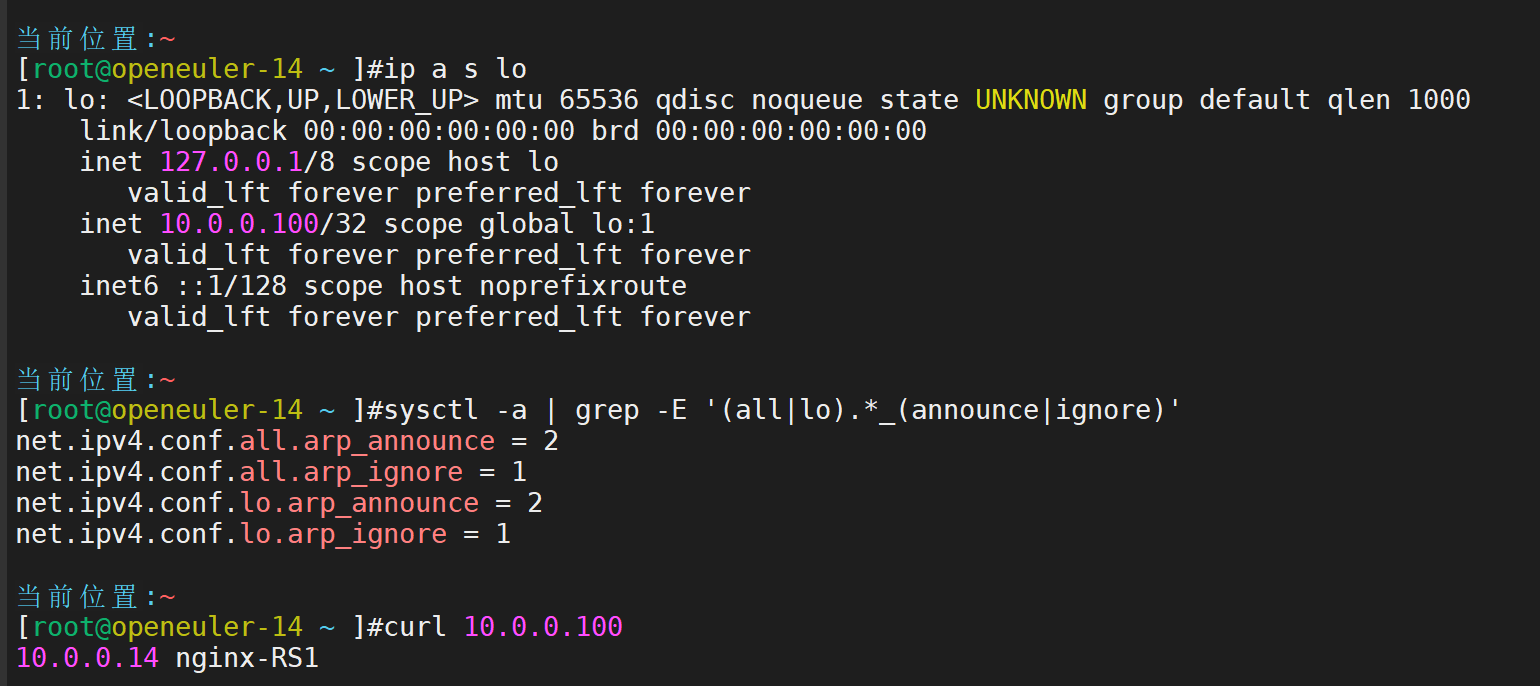
传递给另一台
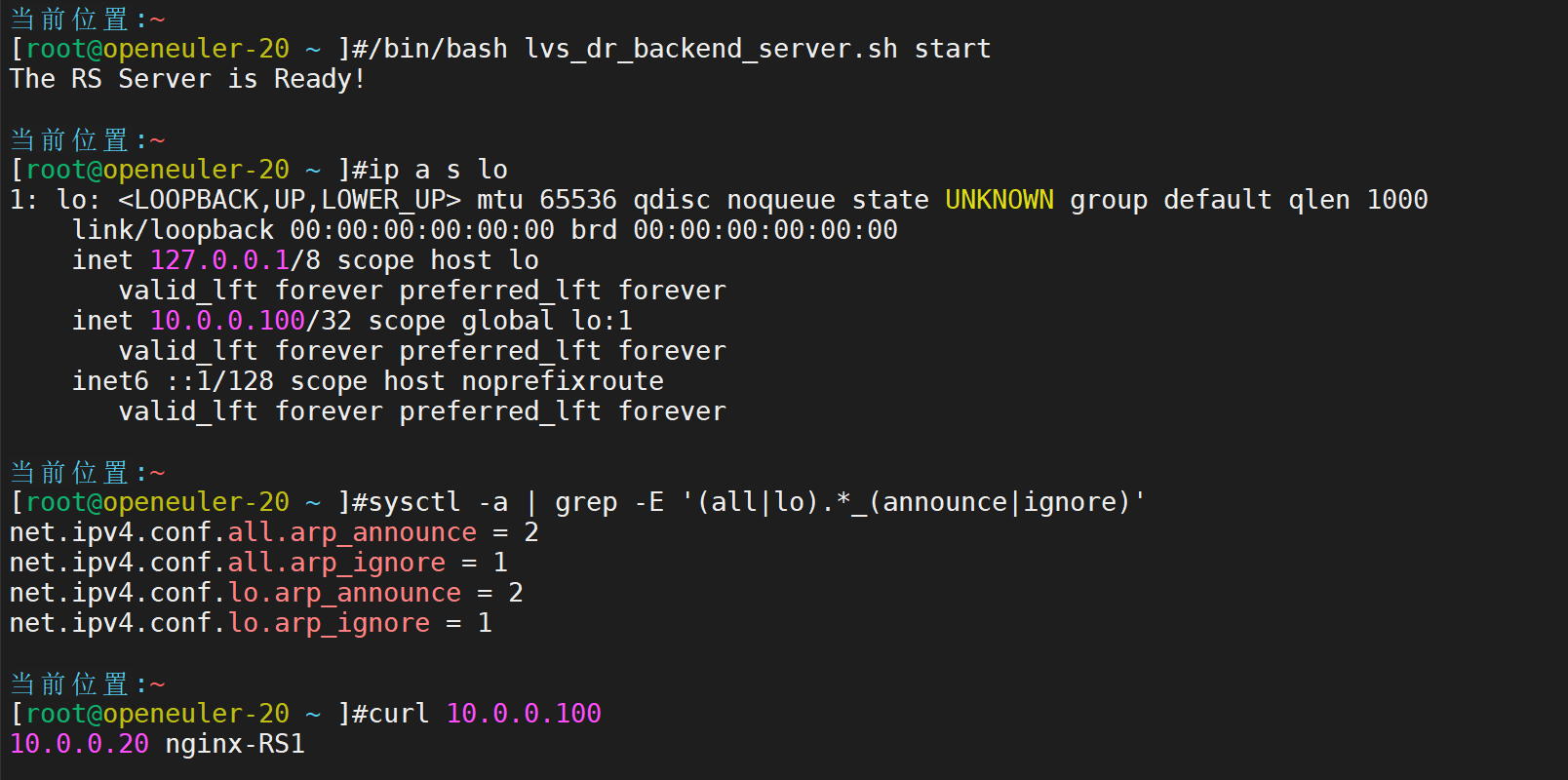
接下来定制虚拟服务
下载keepalived软件,并查询其版本


查看其状态
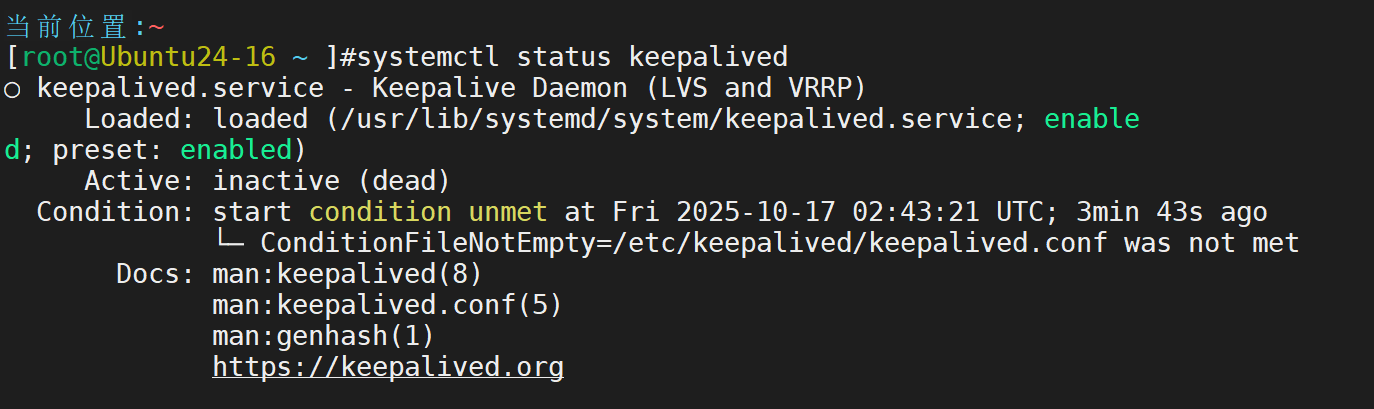
验证服务启动文件
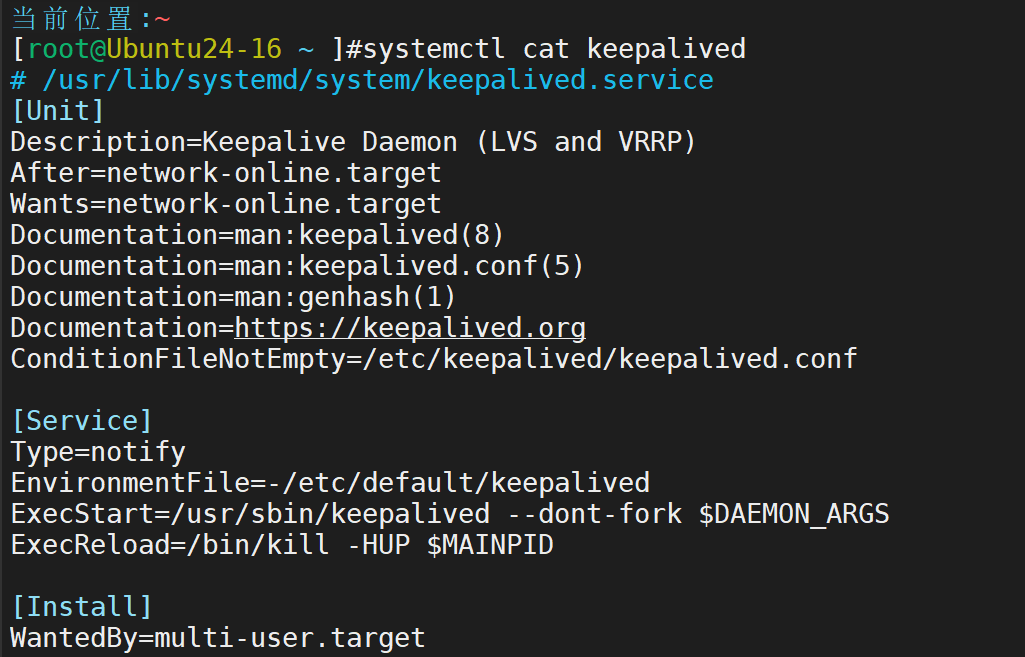
ubuntu默认提供了一个配置文件,但是内容太多,无法正常使用
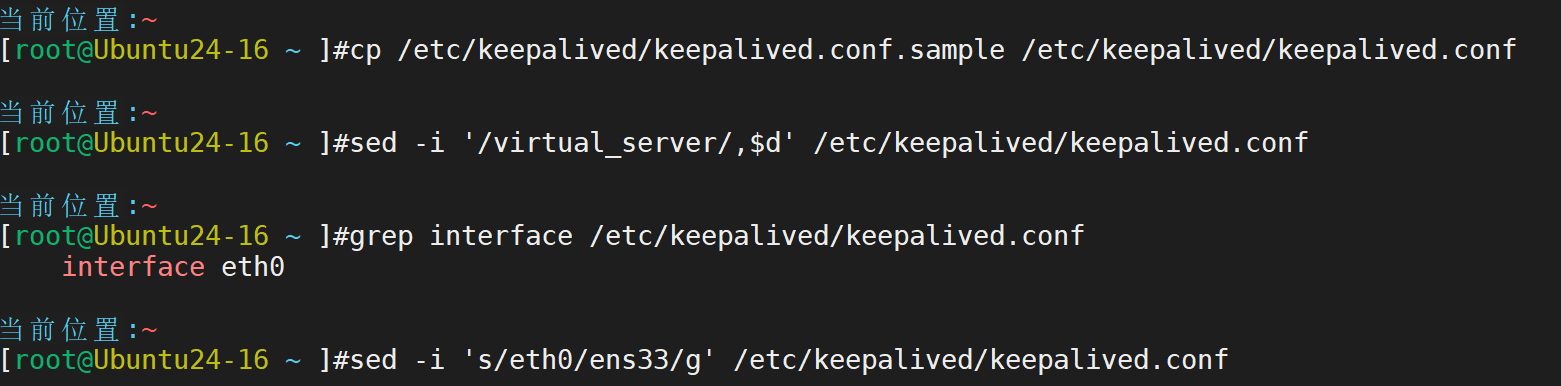
再启动就正常了
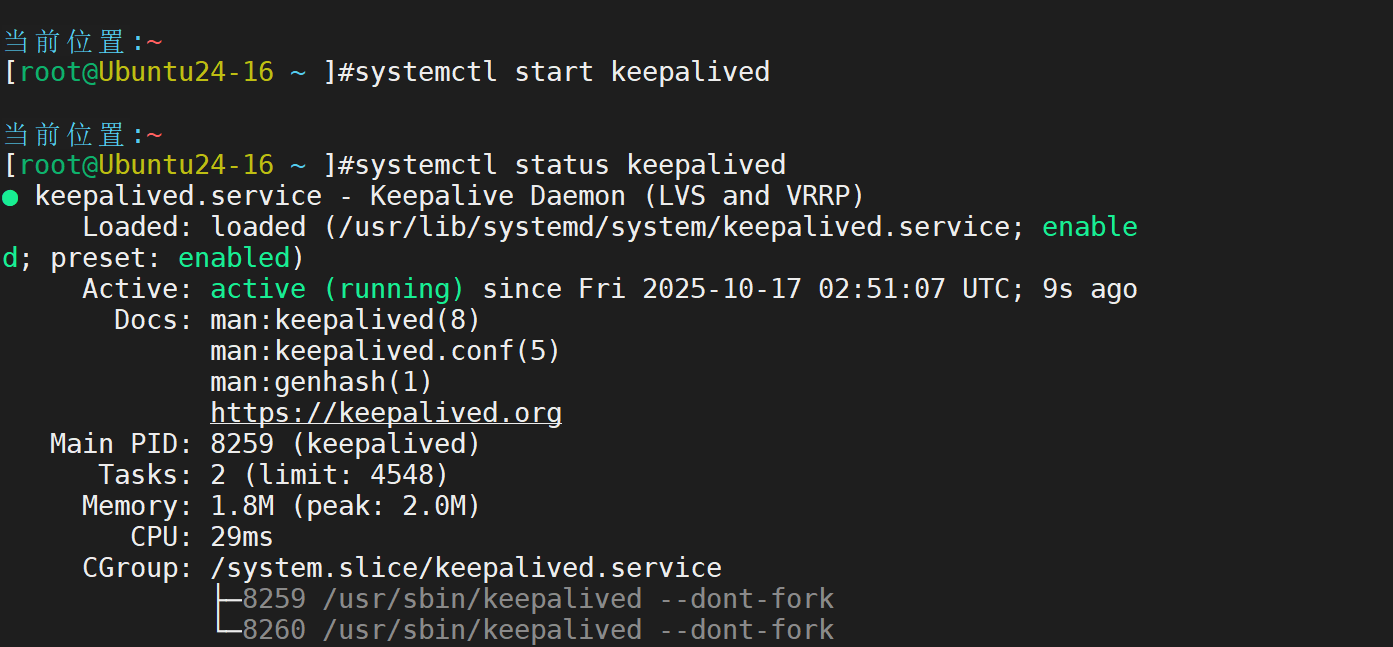
另一台也一样
然后编辑配置文件
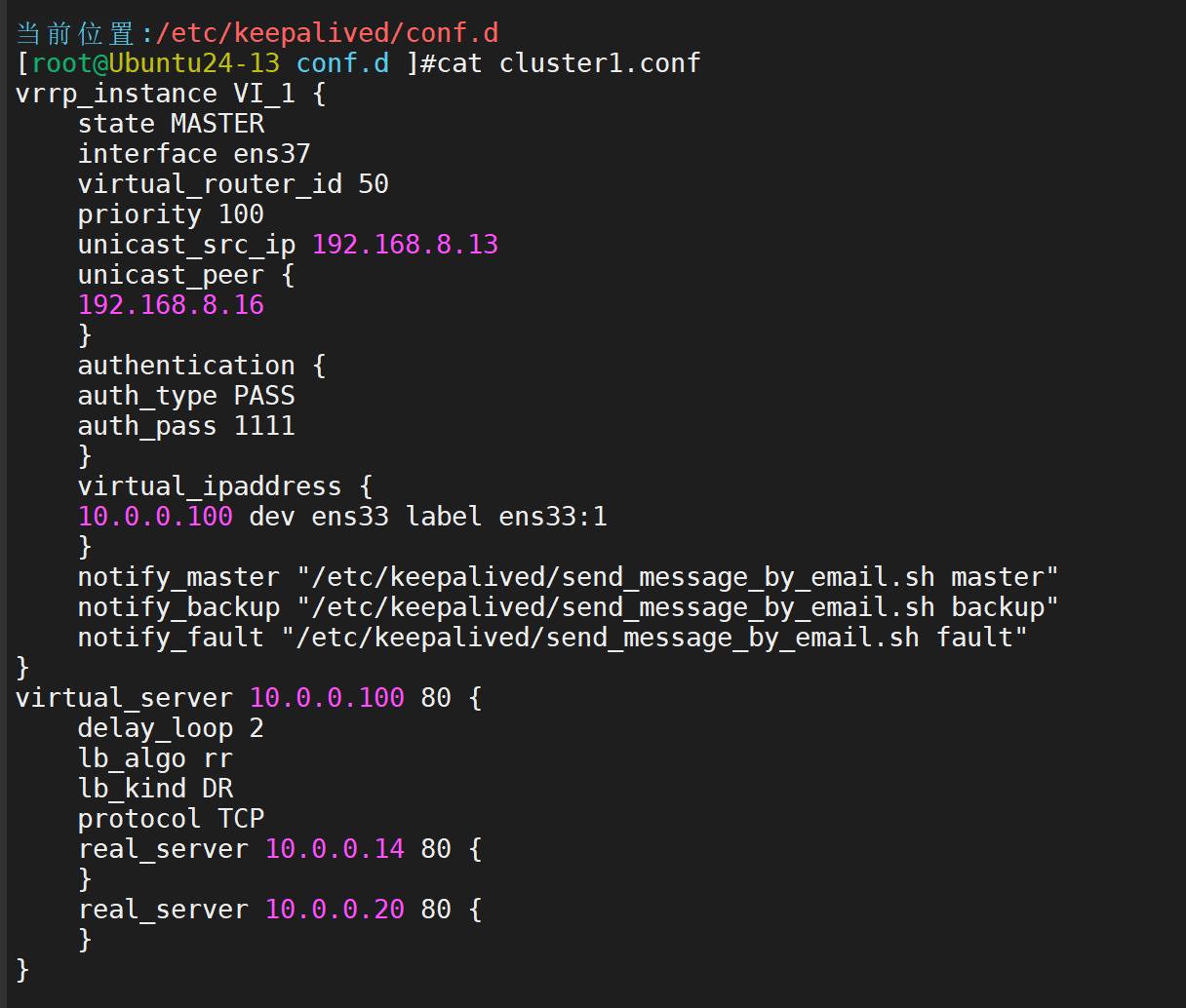
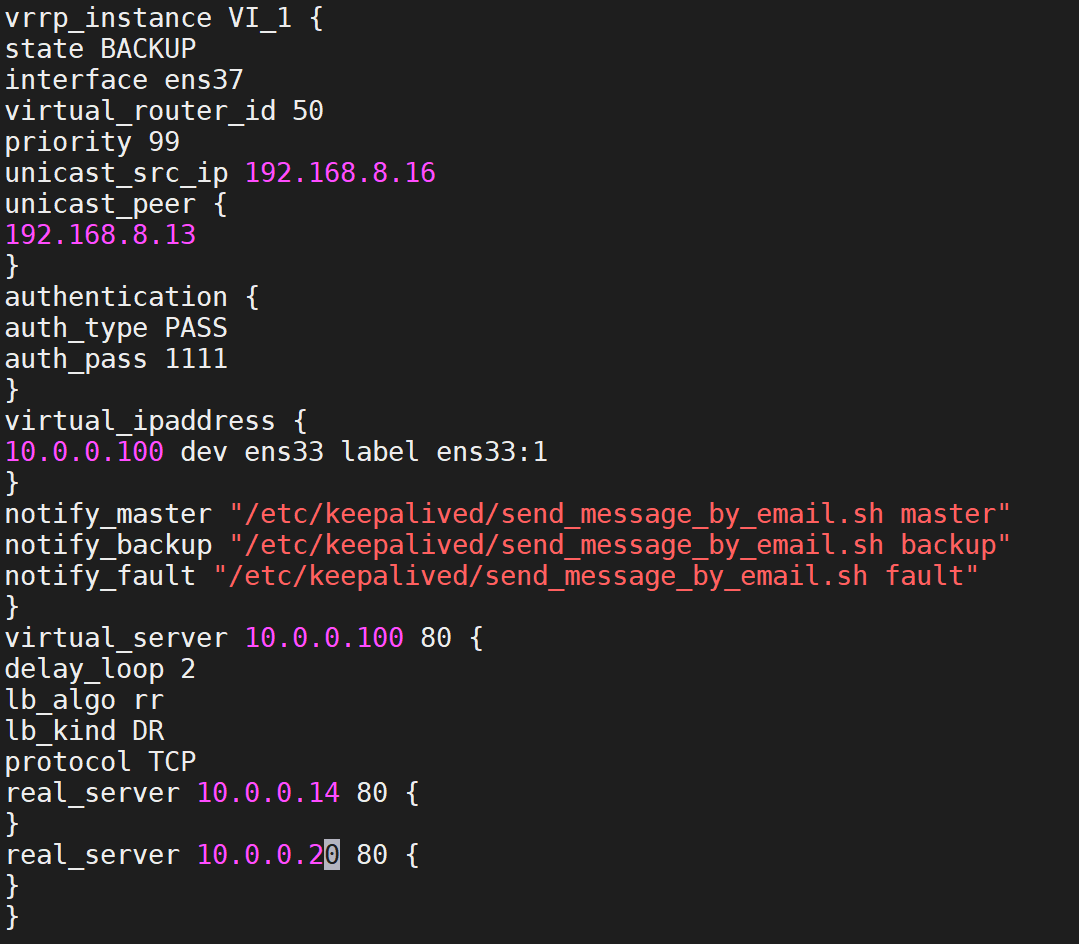
重启服务
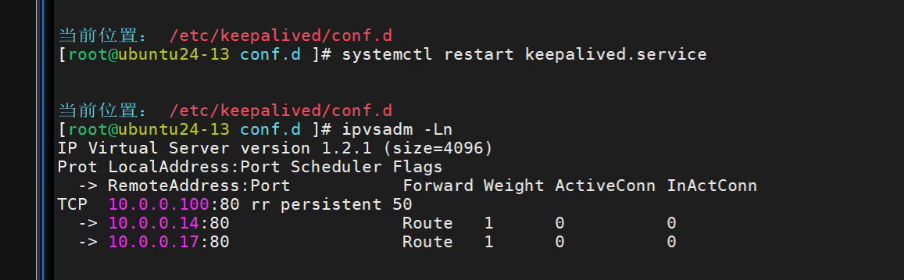
然后用客户端进行curl
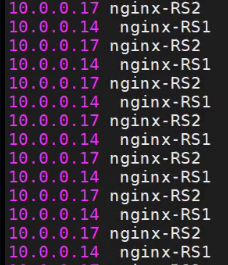
负载均衡效果实现

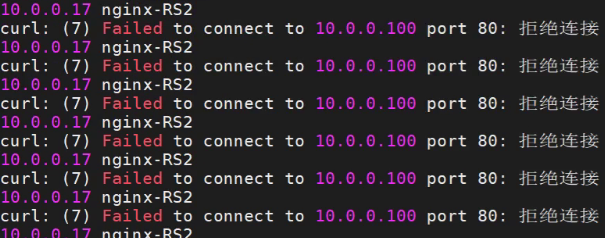
实现漂移