开源项目分析:wan2.1 VACE 关键设计与实现代码解读
论文阅读:VACE: All-in-One Video Creation and Editing
源码地址:https://github.com/Wan-Video/Wan2.1 或 https://github.com/ali-vilab/VACE
wan2.1代码阅读:Wan2.1 模型文生视频、图生视频、首尾帧生视频推理代码分析
VACE是阿里团队基于wan2.1设计的统一视频编辑模型,与wan2.1的文生视频、图生视频能力相比,VACE统一了多种视频编辑与生成软件的设计,将重绘、编辑、可控生成、帧参考生成和基于ID的视频合成等能力整合到一个统一的逻辑,称为视频条件单元,通过利用上下文适配器结构,使用时间维度和空间维度的正式表示将不同的任务概念注入到模型。
如下图展示的能力有,参考图生视频、视频(pose、depth、gary、运动)生视频、mask编辑视频(物体替换、物体移除、视频扩展、视频时序延长);还可以实现组合任务如下图的最后一行,根据参考形象替换视频目标。

1、VACE模型设计
1.1 任务分类
VACE发现它们的大部分输入都可以通过四种模态完全表示:文本(T)、图像(参考图,R)、视频(控制,V)和mask(M)。总体而言,如图2所示,我们根据这四种多模态输入的需求将这些视频任务分为五类。
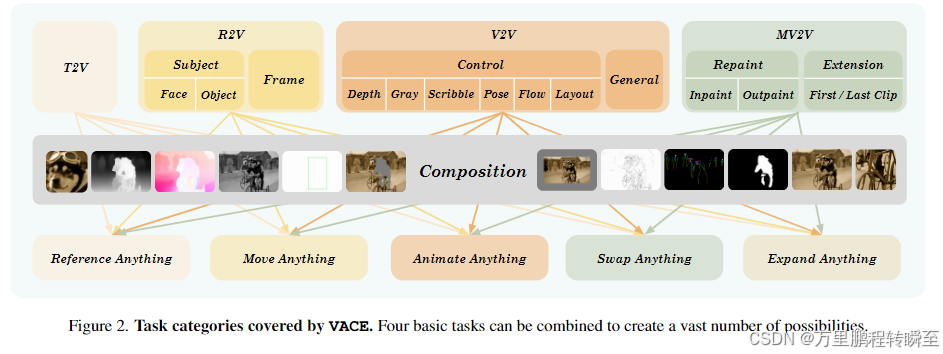
文本到视频生成(T2V)是一种基本的视频创建任务,文本是唯一的输入。
参考到视频生成(R2V)需要额外的图像作为参考输入,确保指定的内容,如人脸、动物和其他物体或视频帧,在生成的视频中出现。
视频到视频编辑(V2V)对提供的视频进行全面更改,例如上色、风格化、可控生成等。我们使用视频控制类型,其控制信号可以表示并存储为RGB视频,包括深度、灰度、姿势、涂鸦、光流和布局;然而,该方法本身不限于这些。
mask视频到视频编辑(MV2V)只在提供的3D感兴趣区域(3D ROI)内对输入视频进行更改,与未更改的其他区域无缝融合,如填补、扩展、视频扩展等。我们使用额外的时空掩码来表示3D ROI。任务组合包括上述4种视频任务的所有组合可能性。
1.2 视频条件单元(VCU)设计
视频条件单元(VCU),将不同的输入条件统一为文本输入、帧序列和掩码序列。一个VCU可以表示为
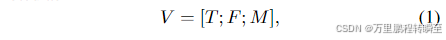
其中,T 是一个文本提示,而 F 和 M 分别是上下文视频帧序列 {u1, u2, …, un} 和掩码序列 {m1, m2, …, mn}。这里,u 在 RGB 空间中,归一化到 [-1, 1],m 是二进制的,其中“1”和“0”分别表示编辑或不编辑的位置。F 和 M 在空间尺寸 h × w 和时间尺寸 n 上对齐。在 T2V 中,不需要上下文帧或掩码。为了保持通用性,我们将每个 u 的默认值设为 0h×w0_{h×w}0h×w,表示空输入,并将每个 m 设为 1h×w1_{h×w}1h×w,意味着所有这些 0 值像素即将重新生成。
对于T2V,输入与常规wan2.1文生视频类型,F为全0数据,M为全1数据;
对于R2V,额外的参考帧ri被插入到默认帧序列之前,而全零掩码 0h×w0_{h×w}0h×w被插入到掩码序列之前。这些全零掩码意味着相应的帧应保持不变。【即对于R2V任务,参考帧信息被放在上下文最前面,】
在V2V中,上下文帧序列是输入视频帧,上下文掩码是一系列 1h×w1_{h×w}1h×w。
对于MV2V,需要同时提供上下文视频和掩码。正式的数学表示如表1所示。M为1的时空区域,则表示为要生成的区域。

VCU还可以支持任务组合。例如,参考图像填充任务的上下文帧为{r1, r2, …, rl, u1, u2, …, un},上下文掩码为0h×w0_{h×w}0h×w× l + {m1, m2, …, mn}【前面的r描述参考帧,对应的mask为全0;后面的u为要修改的视频帧,对应m用于描述要修改的区域】。在这种情况下,用户可以修改视频中的l个对象,并根据提供的参考图像重新生成。
另一个例子是,用户只有一张涂鸦图像,希望生成一个以该涂鸦图像描述的内容开始的视频,这是一个基于涂鸦的视频扩展任务。上下文帧为{u} + 0h×w0_{h×w}0h×w× (n − 1),上下文掩码为1h×w1_{h×w}1h×w× n。通过这种方式,可以实现对视频的多条件和参考控制生成。
2 架构设计
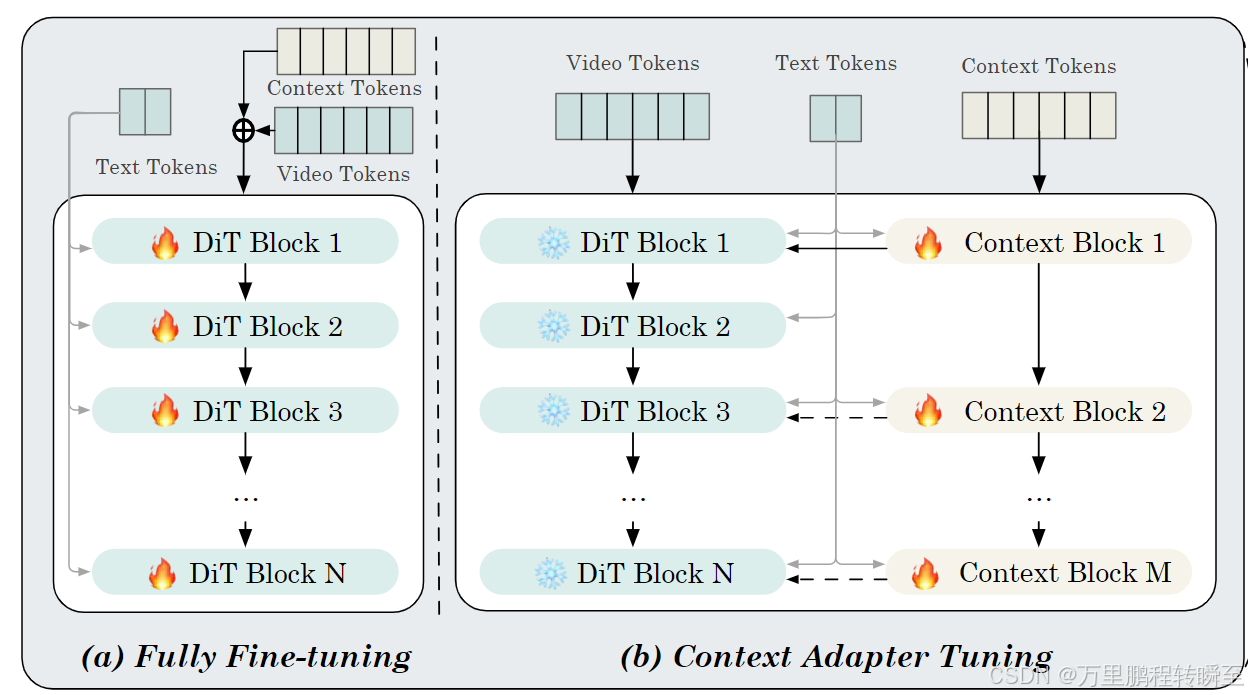
VACE团队重新设计了DiT模型以支持VACE,如图3所示,旨在支持多模态VCU输入。由于已有文本tokenization ,只考虑适配重新设计的上下文帧和掩码的tokenization 。tokenization 后,将上下文标记与噪声视频token结合,并对DiT模型进行微调。与之不同的是,我们还提出了一种上下文适配器微调策略,允许上下文token通过上下文块并重新添加到原始DiT块中。

2.1 Context Tokenization
概念解耦。常规视频和控制信号(如深度、姿态)的两种不同视觉概念在F中同时编码。VACE团队认为,明确分离这些不同模式和分布的数据对于模型收敛至关重要。概念解耦基于掩码,产生两个形状相同的帧序列:Fc = F × M 和 Fk = F × (1 − M),其中Fc被称为反应帧,包含所有要改变的像素,而所有要保留的像素存储在Fk中,称为非活动帧。具体来说,参考图像和V2V以及MV2V中未改变的部分进入Fk,而控制信号和即将改变的像素(如灰度像素)被收集到Fc中。
上下文潜在编码 一个典型的DiT处理带有噪声的视频潜在变量X∈Rn′×h′×w′×dX ∈ R^{n′×h′×w′×d}X∈Rn′×h′×w′×d,其中n′、h′和w′是潜在空间的时空形状。类似于X,Fc、Fk和M需要被编码到一个高维特征空间中,以确保显著的时空相关性。因此,我们将它们与X一起重新组织成具有时空对齐的分层视觉特征。Fc、Fk通过视频VAE处理并映射到与X相同的潜在空间中,保持其时空一致性。为了避免任何意外的图像和视频混杂,参考图像分别由VAE编码器编码,并沿时间维度连接回去,而在解码过程中需要移除对应的部分。M 直接重新塑形和插值。之后,Fc、Fk 和 M 都映射到潜在空间,并与形状为 n′ × h′ × w′ 的 X 在时空上对齐。
上下文嵌入器 我们通过在通道维度上连接Fc、Fk和M,并将它们标记为上下文标记来扩展嵌入层,这被称为上下文嵌入器。用于标记Fc和Fk的权重直接从原始视频嵌入器中复制,而用于标记M的权重初始化为零。
2.2 Fully Fine-Tuning and Context Adapter Tuning
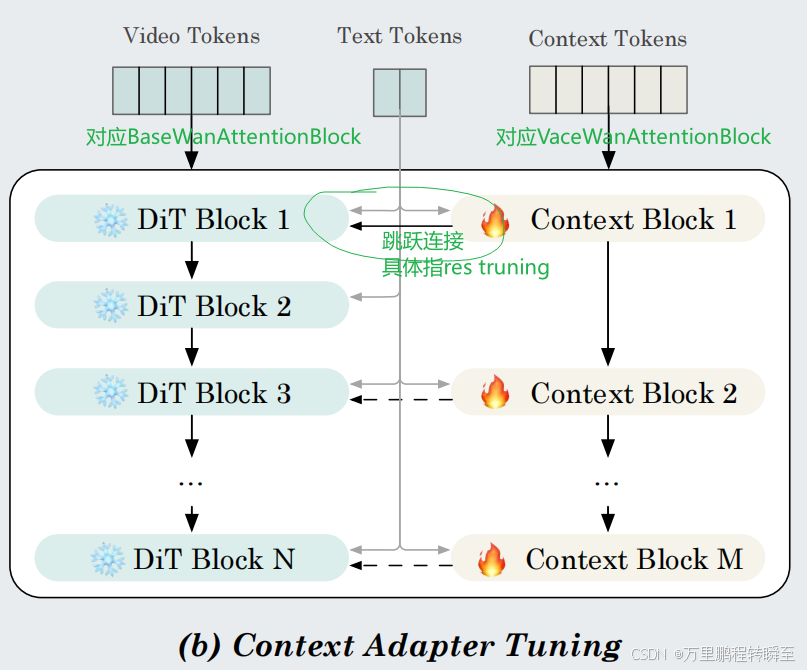
为了使用VCU作为输入进行训练,一种简单的方法是完全微调整个DiT模型,如图3a所示。上下文标记与噪声标记X一起添加,并且在训练过程中DiT和新引入的上下文嵌入器的所有参数都将被更新。为了避免完全微调,实现更快的收敛,并建立一个可插拔的特征与基础模型,我们还提出另一种方法,以Res-Tuning[29]方式处理上下文标记,如图3b所示。特别地,我们从原始DiT中选择并复制几个Transformer块,形成分布式和级联类型的上下文块。原始DiT处理视频标记和文本标记,而新添加的Transformer块处理上下文标记和文本标记。 每个上下文块的输出被插入回DiT块作为附加信号,以协助主分支执行生成和编辑任务。通过这种方式,DiT的参数被冻结。只有上下文嵌入器和上下文块是可训练的。
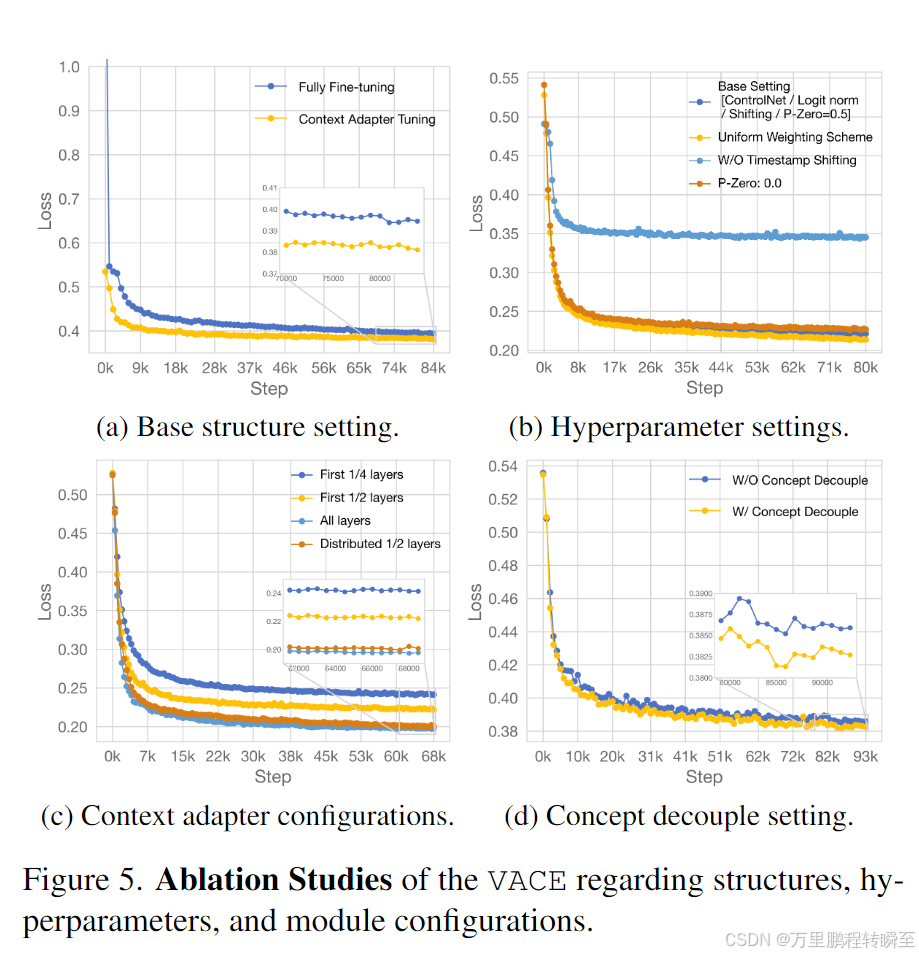
在VACE的消融实验中,基于Res-Tuning方式实现的Context Adapter Tuning收敛更快,具体见图5a;此外,均匀分布的选择1/2的blcok进行注入,可以接近全量训练的效果,这样可以降低训练资源依赖;最后就是关于2.1中提到的概念解耦,可以发现解耦后有微弱的效果提升;
3、主体推理代码
3.1 推理流程直接代码
基于WanVace实例的具体推理代码如下,具体包含两步,prepare_source函数用于进行数据处理,generate进行具体的推理步骤。src_video为驱动视频、src_mask为指定修改视频区域的mask、src_ref_images为参考图片输入。
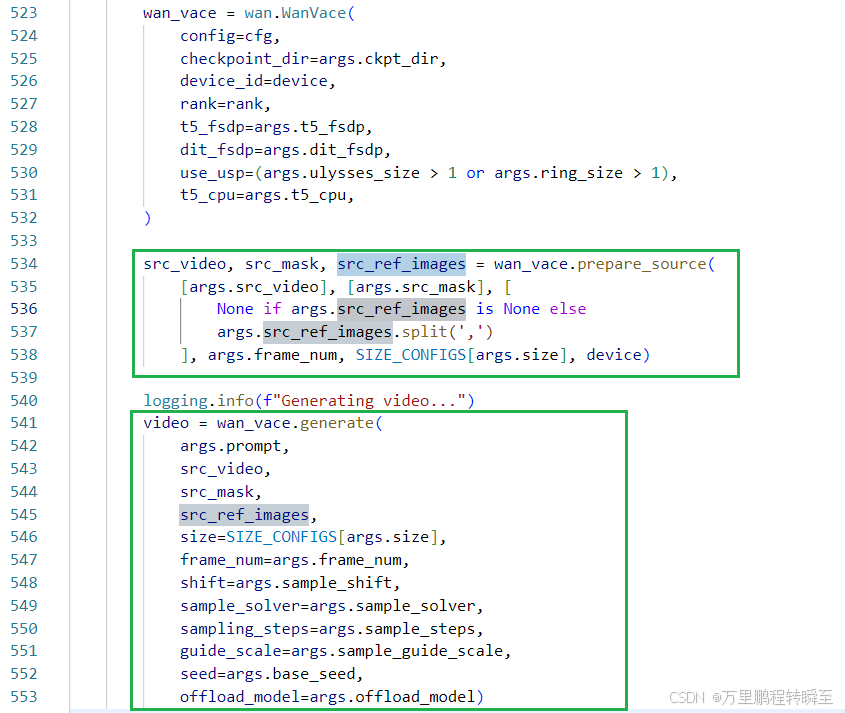
prepare_source函数为预处理src_video, src_mask, src_ref_images。
先加载视频、mask数据对【这是必要数据】,这里默认视频的帧与预期生成的num_frames是相同的。
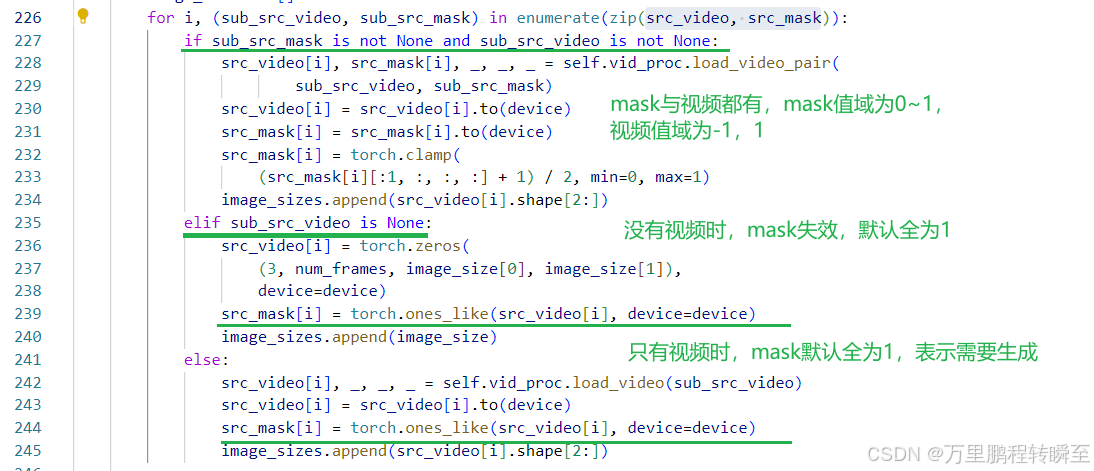
对于参考帧,为非必要输入。当输入参考帧时,将图片在保持宽高比条件下填充全1数据。

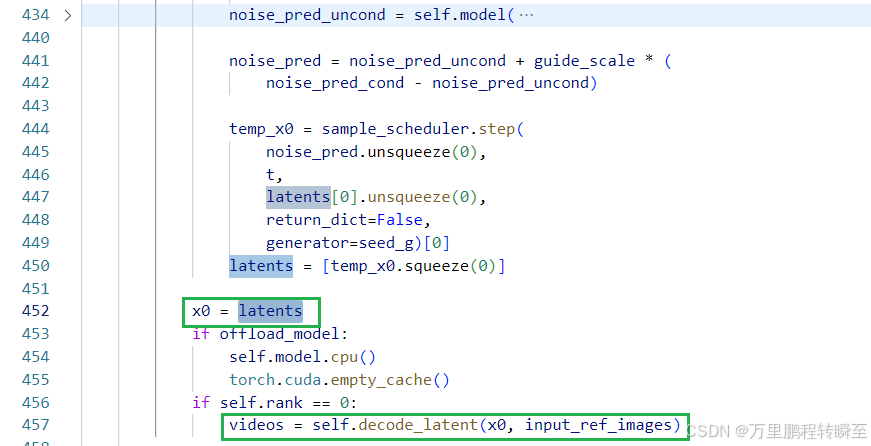
generate函数为对规整后输入的生成过程代码。 先进行常规的text_encoder操作。然后就是基于vace_encode_frames、vace_encode_masks、vace_latent函数根据输入数据input_frames, input_ref_images, masks生成z。最后在vacemodel进行一个扩散过程,对应参数 vace_context=z,vace_context_scale=context_scale
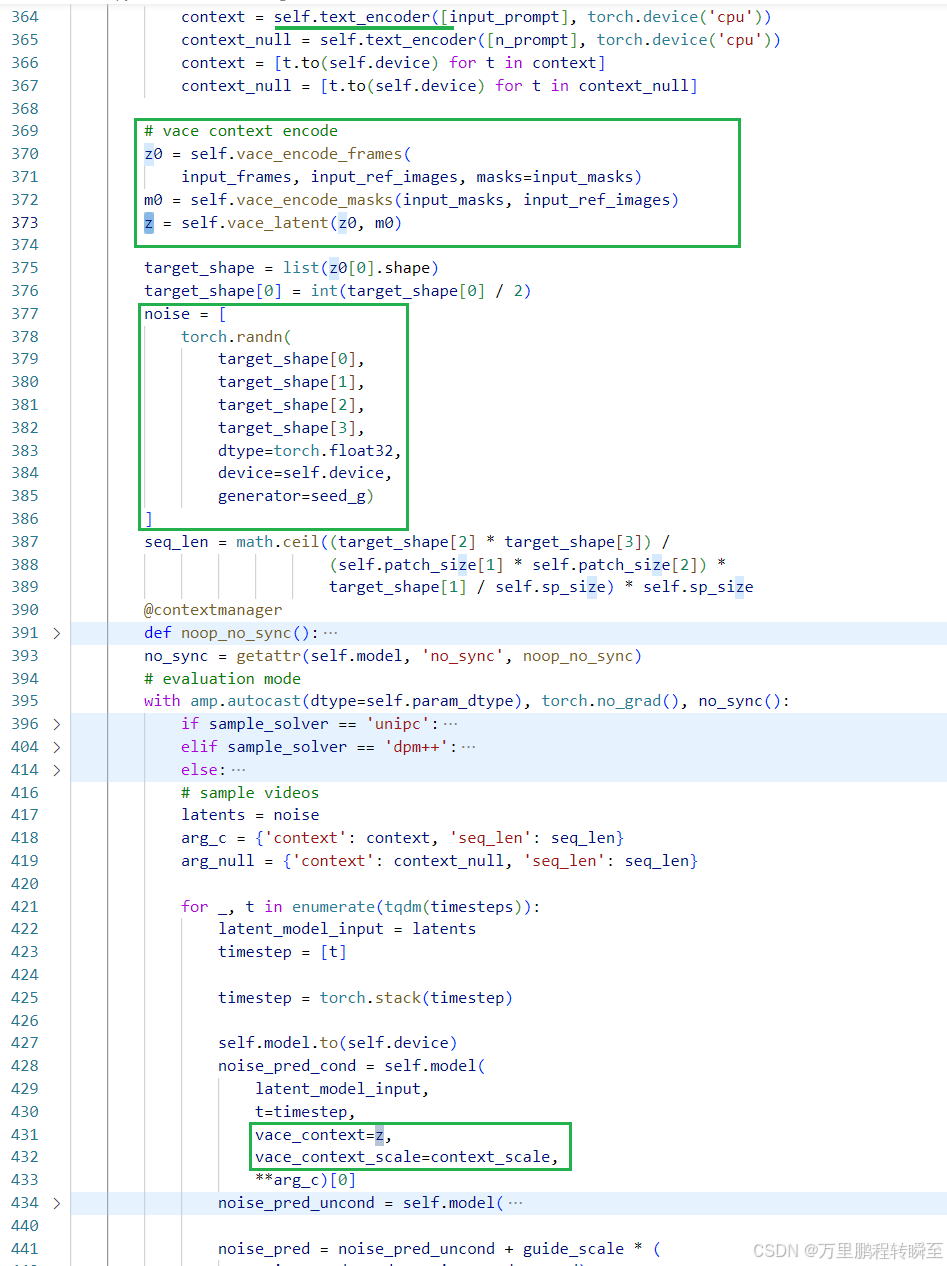
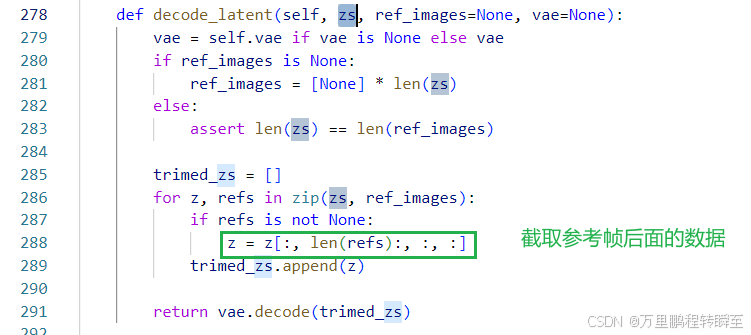
最后扩散的latents基于decode_latent函数进行解码;这里针对参考帧输入进行了截取,对应着1.2 视频条件单元(VCU)r2f设计中提到到参考帧放在F的最前面。
3.2 WanVace定义代码
3.1中提到的推理流程直接代码对应中WanVace类,定义在 Wan2.1-main\wan\vace.py 中,包含了vace的相关模型与数据处理代码。与wan2.1 t2v模型相比,T5EncoderModel、WanVAE是复用原来的;dit模型被替换为VaceWanModel、同时新增了一个VaceVideoProcessor实例(进行视频编解码,如将视频解码为固定fps、分辨率像素乘积的视频)。
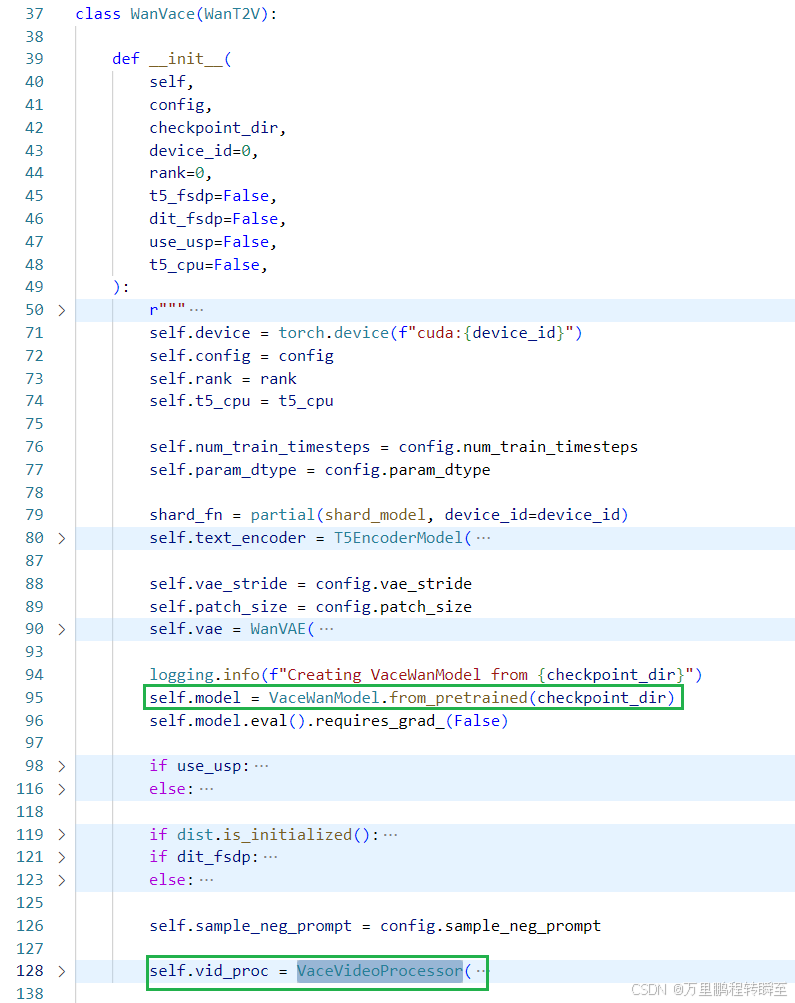
除了成员属性外,最为重要的就是处理输入数据(input_frames, input_ref_images, masks)的函数vace_encode_frames、vace_encode_masks、vace_latent。
vace_encode_frames函数的处理逻辑如下所示,这里可以看到input_frames与masks的对应关系,masks可以为空。
但input_ref_images在input_frames有mask时,其也有一个全为0的隐mask【对应位置mask为0表示不需要生成】。这里最终生成的视频上下文信息。

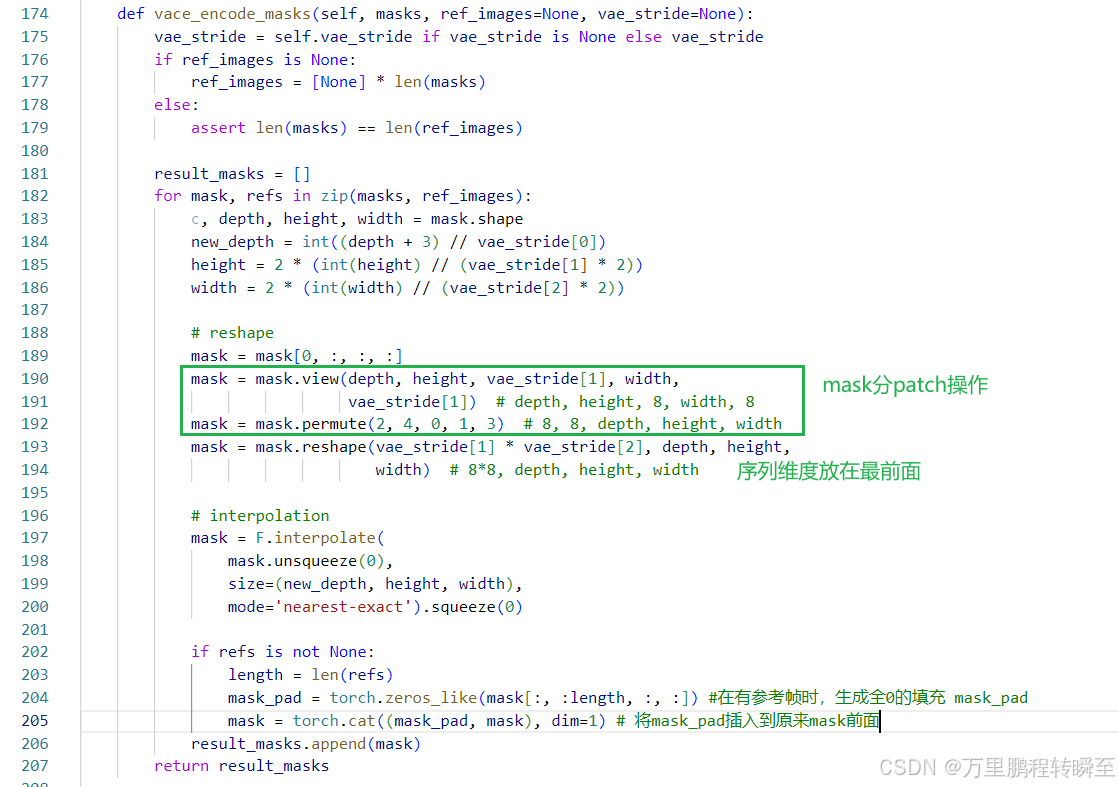
vace_encode_masks函数 主要主要生成上下文对应的mask生成,当存在参考帧时,将参考帧对应的mask_pad插入到默认mask的最前面。
vace_latent函数 主要将 视频上下文信息、mask信息融合在一起。

3.3 VaceWanModel定义代码
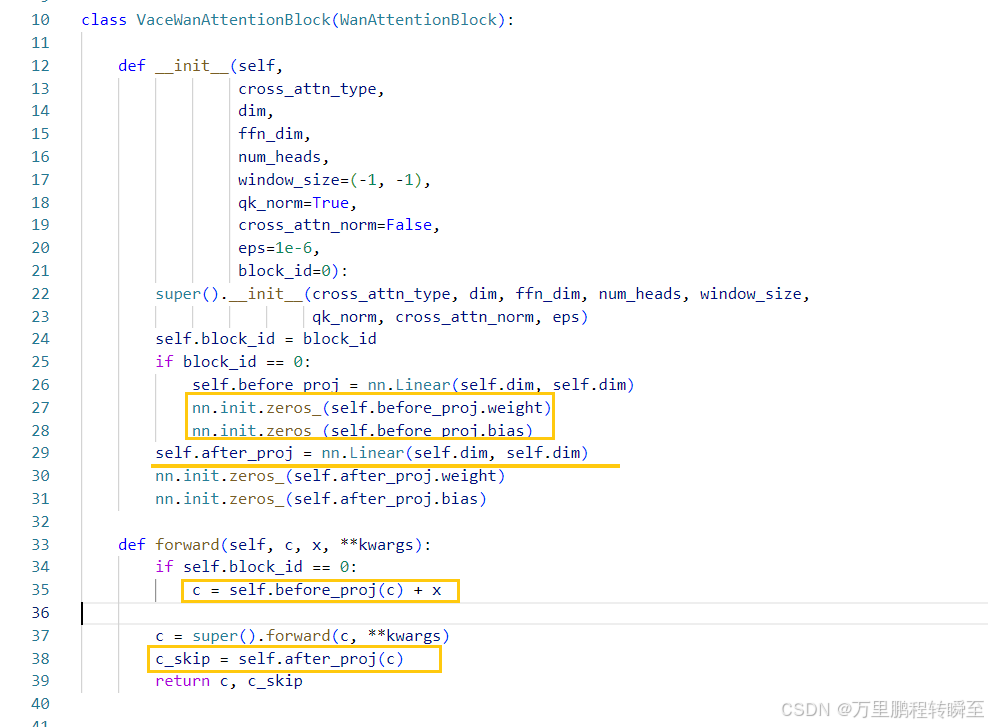
代码在 Wan2.1-main\wan\modules\vace_model.py 中,时vace的dit模型,用于完成具体的扩散过程。其有2种block,BaseWanAttentionBlock与VaceWanAttentionBlock。BaseWanAttentionBlock与VaceWanAttentionBlock是一个并行的设计。

这样的设计对应下图,每隔一个原始block,就插入一个VaceWanAttentionBlock。在实际过程种先走完VaceWanAttentionBlock,再走DiT Blcok流程。
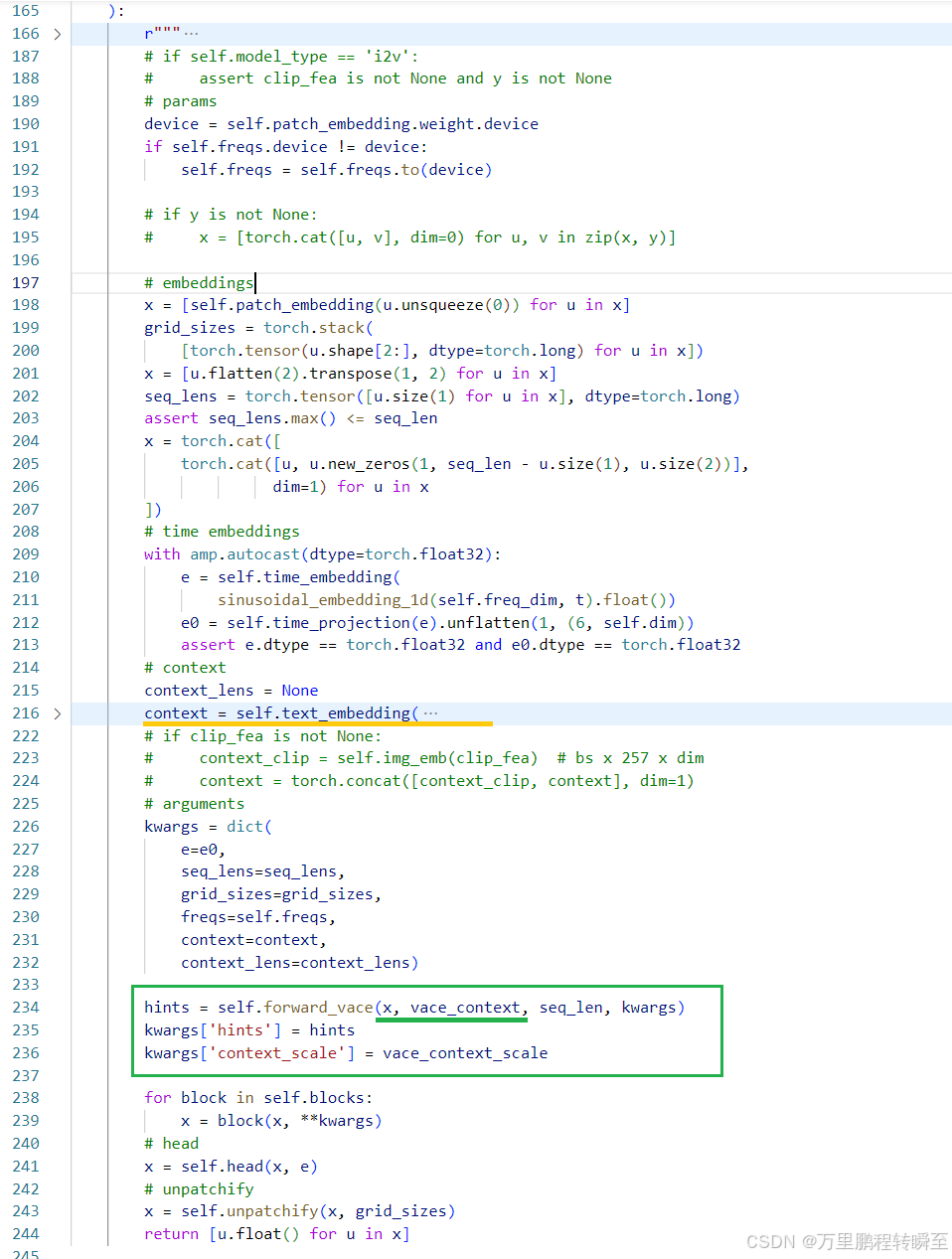
具体的forward流程代码如下,与wan2.1 t2v的流程基本一致,只是多了绿框种forward_vace的部分。同时,这里可以看到,基于文本生成的context与vace_content是没有任何直接交互的。forward_vace函数只是完成latent(x)与vace_latent(vace_context)的交互。这里应该是避免文本信息对视频编辑任务的影响。
3.4 Vace相关AttentionBlock定义代码
Vace中的AttentionBlock都是继承WanAttentionBlock t2v_cross_attn流程实现的。
BaseWanAttentionBlock只是为了实现Res-Tuning训练方式做的封装,即一个带强度(context_scale)的跳跃连接。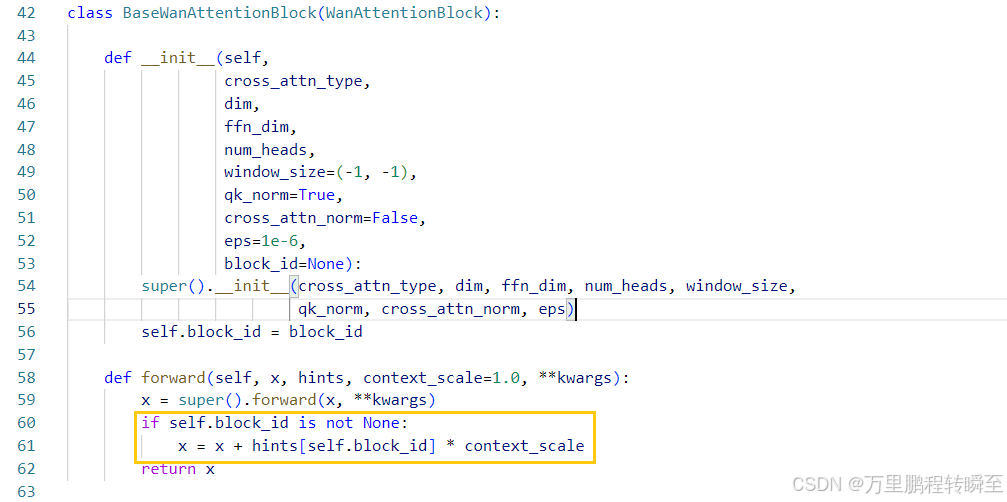
VaceWanAttentionBlock也是基于WanAttentionBlock实现,只是新增了一个Linear操作。同时再第一个block_id时,有额外的before_proj。