FACT-AUDIT
[论文笔记•(智能体)]FACT-AUDIT: An Adaptive Multi-Agent Framework for Dynamic
Fact-Checking Evaluation of Large Language Models
一、一句话总结
为解决现有大语言模型(LLMs)事实核查评估依赖静态数据集、无法自动评估论证生成且难以揭示细微局限性的问题,Lin 等学者提出FACT-AUDIT—— 一个自适应多智能体框架,该框架基于重要性采样原理和多智能体协作,通过原型模拟、事实验证与论证评估、自适应更新三阶段,动态生成测试数据(覆盖复杂声明、假新闻、社交谣言三大场景及 [claim]、[evidence]、[wisdom of crowds] 三种测试模式),引入Insight Mastery Rate(IMR)、Justification Flaw Rate(JFR)、Grade三大指标,对 13 个主流 LLMs(含 10 个开源模型、3 个闭源模型)进行评估,结果显示GPT-4o(IMR=12.02%)、Qwen2.5-72B(IMR=16.00%)等表现最优,且 LLMs 在假新闻场景表现较好但在复杂声明场景存在明显短板,该框架实现了超越传统准确率评估的动态、全面事实核查能力审计。

二、论文基本信息
单位:香港浸会大学
会议:ACL2025
阅读时间:2025.10.18
论文地址:FACT-AUDIT: An Adaptive Multi-Agent Framework for Dynamic Fact-Checking Evaluation of Large Language Models - ACL Anthology
**代码:**无代码
测试
三、研究的核心问题和背景
-
LLMs 事实核查现状
- 优势:LLMs 可存储事实知识(如 Petroni 等 2019 年研究证实),能作为知识库辅助事实核查任务(Pan 等 2023 年研究),在自然语言处理(NLP)领域推动事实核查技术进步。
- 不足:LLMs 仍存在事实错误识别能力弱、推理易出错的问题(Lin 等 2022b;Bubeck 等 2023),知识存储误差或推理能力缺陷会降低其事实核查可信度,因此需系统揭示 LLMs 事实核查能力边界。
四、现有方法面临的挑战
现有评估方法的三大局限
- 静态数据集依赖:人工标注测试场景成本高、难扩展(如 Yang 等 2024b 的方法),且静态数据集(如 Chen 和 Shu 2024 的数据集)存在数据泄露、排行榜饱和风险,无法动态暴露 LLMs 局限性。
- 评估维度单一:多将评估简化为分类任务(仅关注准确率),忽视事实核查关键的论证生成能力(Eldifrawi 等 2024 指出论证对裁决预测至关重要)。
- 场景适配性差:难以覆盖真实世界复杂场景(如多步骤推理的复杂声明、语境依赖的社交谣言),评估结果缺乏实用性。
五、框架及具体实现
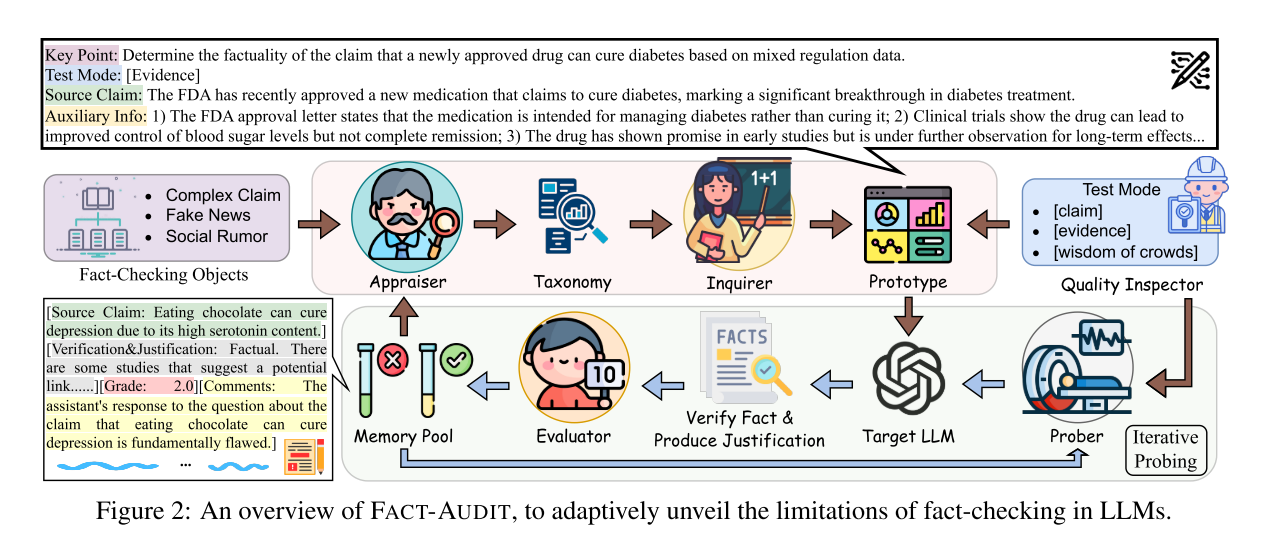
1. 核心理念与理论基础
-
设计目标:构建自动化、自适应的多智能体框架,实现对 LLMs 事实核查能力的动态、全面审计,同时评估裁决预测与论证生成双维度能力。
2. 多智能体角色与职责
智能体(Agent) 核心职责 关键操作 Appraiser 场景分类体系构建与更新 1. 初始化分类(复杂声明、假新闻、社交谣言三大类,含多级子场景,如图 3);2. 基于评估结果(记忆池低分组数据)挖掘新场景,优化分类体系 Inquirer 原型测试数据生成 按 Appraiser 的场景分类,生成含 4 要素的测试数据:- Key Point(测试核心)、Source Claim(待核查声明)、- Auxiliary Information(辅助信息)、Test Mode(测试模式) Quality Inspector 测试数据质量校验 1. [claim] 模式:确保辅助信息为空;2. [evidence] 模式:通过 Wikipedia API+LLM 校验证据真实性(需≥3 条,含支持 / 反驳 / 中立三类);3. [wisdom of crowds] 模式:校验社交评论树深度≥2 且有事实参考价值 Evaluator LLM 性能评估 1. 以 GPT-4o 为 Judge,对 LLM 输出(裁决 + 论证)评分(1-10 分,≤3 分视为错误);2. 记录评估结果至记忆池M={x,r,s,c}(x = 测试数据,r=LLM 输出,s = 评分,c = 评论) Prober 挑战性数据生成 基于记忆池历史数据,迭代生成未见过的、针对性的测试数据,补充记忆池,深化评估
3. 三大核心阶段(对应 Algorithm 1)
- 阶段 1:原型模拟(Prototype Emulation)
- 流程:Appraiser 抽样场景θ**i→Inquirer 生成数据x∼q(x∣θ**i)→Quality Inspector 校验→生成原型数据集X(直至规模达k)。
- 目的:构建高质量初始测试数据,覆盖基础场景。
- 阶段 2:事实验证与论证评估(Fact Verification with Justification)
- 流程:Evaluator 评估 LLM 在X上的表现,计算Eq**i[F**α(x)q(x∣θ**i)p(x)]→Prober 基于记忆池M生成新数据x∼ρ(M)→补充评估并更新M。
- 核心:同时评估 LLM 的裁决准确性与论证质量,避免 “裁决正确但论证错误” 的片面评估。
- 阶段 3:自适应更新(Adaptive Updating)
- 流程:Appraiser 分析记忆池低评分案例(s<ϵ,ϵ=4.0)→更新场景分类Θi+1∼π(Θi+1∣Θi,M)→重复审计循环。
- 理论保障:更新后分布q**i+1(x)的方差Varq**i+1≤Varq**i,确保评估收敛且效率高于直接采样p(x)。
六、实验
1. 实验基础设置
| 实验要素 | 具体内容 |
|---|---|
| 目标 LLMs | 13 个,含 10 个开源模型(Mistral-7B、Llama2-7B/13B、Llama3-8B、Llama3.1-8B/70B、Qwen2.5-7B/72B、GLM4-9B、Gemma2-9B)和 3 个闭源模型(Gemini-Pro、Claude3.5-Sonnet、GPT-4o) |
| 评估指标 | - IMR(核心):低评分(≤3 分)案例占比,公式的测试数总测试数,值越低能力越强;- JFR:裁决正确但论证差的案例占比,公式案例数总测试数;- Grade:1-10 分评分(LLM-as-a-Judge 给出) |
| 测试场景 | 三大类:复杂声明、假新闻、社交谣言(每类含多级子场景,如图 3) |
| 测试模式 | 三类:- [claim]:无外部知识,依赖 LLM 参数知识;- [evidence]:提供 Wiki 真实证据(≥3 条);- [wisdom of crowds]:提供社交评论树(深度≥2) |
| 实验配置 | 温度 = 0(确保可复现),最大迭代次数 = 30,单模型评估成本≈25 美元 / 6 小时,硬件 = 2×NVIDIA A100 80GiB |
2. 核心实验结果
(1)模型整体性能排名(按 IMR 从小到大,IMR 越低越优)
| 排名 | 模型(类型) | 复杂声明 IMR(%) | 假新闻 IMR(%) | 社交谣言 IMR(%) | 整体 IMR(%) | 整体 Grade |
|---|---|---|---|---|---|---|
| 1 | GPT-4o(闭源) | 14.05 | 10.56 | 10.48 | 12.02 | 7.21 |
| 2 | Qwen2.5-72B(开源) | 22.08 | 10.42 | 15.00 | 16.00 | 7.17 |
| 3 | Claude3.5-Sonnet(闭源) | 32.71 | 15.00 | 18.57 | 24.34 | 6.78 |
| 4 | Gemini-Pro(闭源) | 30.21 | 19.39 | 32.86 | 27.25 | 6.14 |
| 5 | Qwen2.5-7B(开源) | 38.97 | 21.54 | 36.67 | 31.76 | 5.91 |
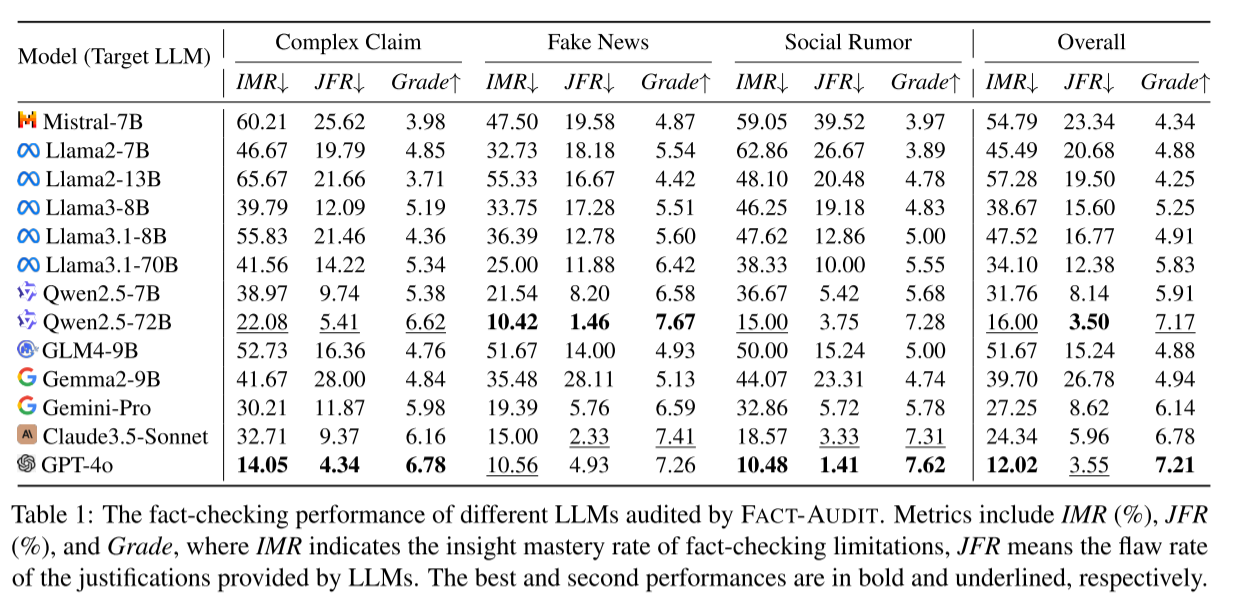
2)不同场景的模型表现
-
假新闻场景:整体表现最优,如 Qwen2.5-72B 的 IMR 仅 10.42%,因假新闻事实性更明确,推理难度低。
-
复杂声明场景:整体表现最差,如 Mistral-7B 的 IMR 达 60.21%,因需多步骤推理、多源证据整合,对 LLM 推理能力要求高。
-
社交谣言场景:表现波动大(如 Llama2-7B 的 IMR=62.86%,GPT-4o 的 IMR=10.48%),因谣言依赖语境且语言复杂。
(3)不同测试模式的难度对比(以 GPT-4o 为例)
测试模式 IMR(%) JFR(%) Grade 难度排序 [claim] 23.05 16.67 6.11 1(最难) [wisdom of crowds] 15.40 8.51 6.67 2(中等) [evidence] 10.61 8.77 7.00 3(最易) - 原因:[claim] 模式依赖 LLM 内部知识,易受知识偏差影响;[evidence] 模式提供明确证据,降低推理负担;[wisdom of crowds] 需从噪声评论中提取信息,难度居中。
(4)框架可靠性验证
-
人类评估验证
:随机抽样 600 条数据(每场景 200 条),3 名专业标注员评估,关键指标通过率如下:
评估对象 通过率(%) Cohen’s Kappa 系数 详细分类体系 98.86 0.810 待核查声明 97.17 0.795 参考答案 90.33 0.762 评估输出 89.02 0.658 -
基准对比:与 Pinocchio(Hu 等 2024b)、LLMFake(Chen 和 Shu 2024)对比,FACT-AUDIT 在冗余(1.22)、多样性(2.62)、覆盖度(2.58)上表现更优,证明数据质量更高。
七、研究结论
FACT-AUDIT 通过多智能体协作与自适应更新机制,解决了传统 LLM 事实核查评估静态、单一、场景适配差的问题,实现了对 LLMs裁决预测与论证生成能力的动态、全面审计。实验证明该框架能有效区分 13 个主流 LLMs 的事实核查能力,揭示闭源模型(如 GPT-4o)与部分开源大模型(如 Qwen2.5-72B)的优势,以及 LLMs 在不同场景、模式下的能力短板,为 LLMs 事实核查能力的优化与信任度提升提供了关键工具。
面审计。实验证明该框架能有效区分 13 个主流 LLMs 的事实核查能力,揭示闭源模型(如 GPT-4o)与部分开源大模型(如 Qwen2.5-72B)的优势,以及 LLMs 在不同场景、模式下的能力短板,为 LLMs 事实核查能力的优化与信任度提升提供了关键工具。