快手one系列核心合集随笔 (随着系列推出更新)
1.OneSearch: A Preliminary Exploration of the Unified End-to-End Generative Framework for E-commerce Search
场景:电商搜索
核心创新点:
把RQ-Kmeans和OPQ结合起来(2+3),前者离散化层次的共性信息,后者离散化独特的信息,在这个场景上RQ-Kmeans比RQ-VAE效果好
设计引入行为信息的微调任务,优化embedding模型,用margin不同行为用margin loss;用llm打分,然后用bge这个表征模型来对齐这个相关分数
核心实体增强:用NER识别实体,并且用页面浏览量来排,用qwen-vl识别相应的item的实体,在推理时用这个方法来快速匹配query的实体:Aho-CorasickAutomaton,这些实体的候选已经预先用表征模型产生了embedding,最后query和item的embedding是实体和原始的embedding的加权和: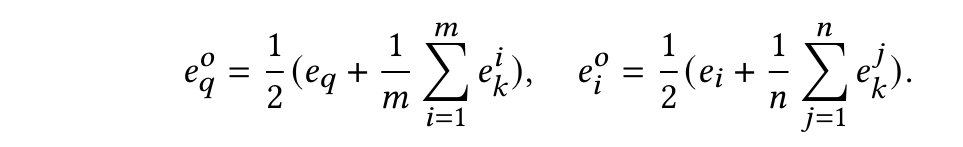
user id从随机产生改为采用近期和历史item id的加权和的两个结果
模型结构:BART-B
2.OneSug: The Unified End-to-End Generative Framework for E-commerce QuerySuggestion
快手电商query补全
对于prefix的输入,产生其sid时要用一些强相关的query的表征来做语义补齐,这个强相关通过聚类搜索来完成,对prefix的embedding用强相关的query做池化之后加权和
把dpo损失加了一个margin,同时在正样本上加了一个sft的loss,以防止模型丢失生成的能力,把所有的负样本都和正样本来做dpo的损失,以引入一些排序的能力
3.OneRec
模型结构:Encoder-decoder,decoder的FFN换成MOE
RL:在sft过程中按照一定概率采取dpo;其中奖励模型用各个行为塔产生数据进行训练,然后用这个训练出来的奖励模型区分正负样本对
会话级别生成,与逐点生成模型不同,训练目标是一个完整的序列列表,即一次性端到端生成一个完整的推荐列表:5-10个item。
定义了筛选高质量会话的几个关键标准 :
- 用户在当次推荐的会话中,实际观看的短视频数量大于等于5个 。
- 用户观看该会话的总时长超过了预设的阈值 。
-
用户在该会话中产生了点赞、收藏或分享等互动行为 。
线上服务会用beam search推理出多个会话列表,但是展现给用户的可能需要结合奖励模型或者其它策略来评估展示哪个或者哪些候选
4.OneLoc
本地生活的推荐和用户兴趣和实时位置相关密切,这篇文章主要解决两个问题:1.充分利用地理信息,用sid;2.权衡多种优化目标,用户与店铺的距离、GMV等商业目标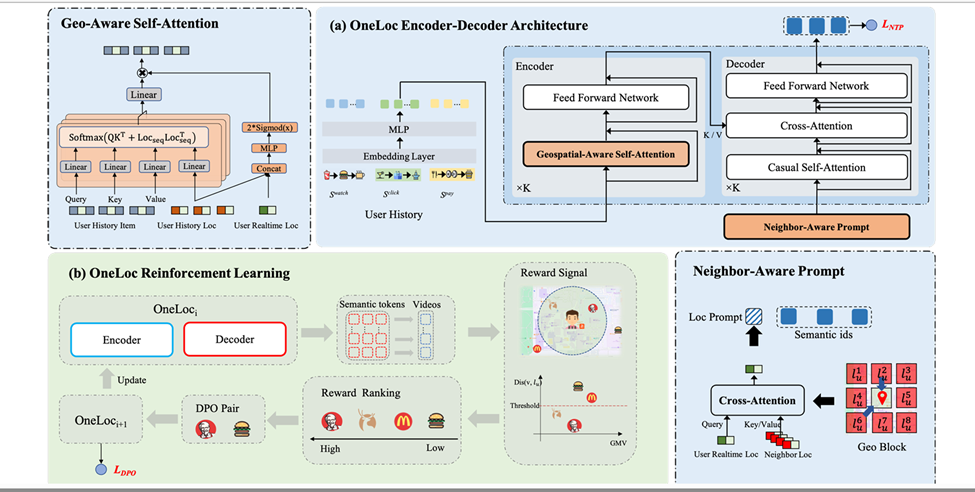
对于利用地理信息,提出了地理sid、在encoder中同时运用视频位置相似度和用户的实时位置、邻居提示词丰富用户周围语境信息;对于多种优化目标,设计RL的两种奖励,即地理奖励和GMV奖励。最终在快手本地生活服务中推全
任务:根据用户交互序列和实时位置预测下一个交互视频
分为encoder和decoder两部分,第一部分对历史序列、历史位置和实时位置交互建模,第二部分把周围的八个点的地理信息注入到表征中,把实时位置和临近的点的地理信息通过crossnet整合为loc prompt,作为decoder-only的输入部分
规则奖励: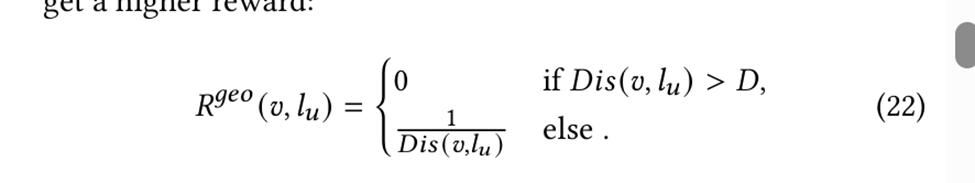
鼓励产生和user更近的item,同时还有一个GMV打分模型给出的奖励信息