网站建设与管理视频教程建设招标网 手机官方网站
Torchvision 是 PyTorch 官方推出的计算机视觉工具库,集成了常用的数据集、模型架构和图像变换工具,极大简化了计算机视觉任务的开发流程。本文将围绕 Torchvision 的核心功能展开,重点讲解图像变换(transforms)和数据加载(datasets、DataLoader)的使用方法。
4.1 Torchvision 核心模块简介
Torchvision 主要包含以下四个核心模块:
torchvision.transforms:图像预处理与数据增强工具,提供多种图像变换操作(如尺寸调整、裁剪、归一化等)。
第5节 Transforms使用-CSDN博客
torchvision.datasets:内置常用数据集(如 MNIST、CIFAR-10、ImageNet 等),支持自动下载和加载。
torchvision.models:预训练模型库(如 ResNet、VGG、MobileNet 等),可直接用于迁移学习。
torchvision.utils:辅助工具函数(如图像拼接、保存等)。
4.2 torchvision.datasets 与 DataLoader 数据加载
在 PyTorch 中,数据加载是模型训练与评估的基础环节。torchvision.datasets 提供了便捷的数据集加载方式(内置经典数据集和自定义数据接口),而 DataLoader 则负责将数据集按批次、多线程加载,大幅提升数据处理效率。
4.2.1 torchvision.datasets:数据集加载工具
torchvision.datasets 是用于加载图像数据集的模块,支持两种类型的数据集:内置经典数据集(如 MNIST、CIFAR-10 等)和自定义数据集(通过 ImageFolder 或自定义类实现)。
(1)、内置经典数据集
datasets 模块包含多种常用数据集,支持自动下载、解压和预处理,无需手动处理数据文件。
核心参数(通用):
root:数据集保存路径(如 "./data")。
train:布尔值,True 表示加载训练集,False 表示加载测试集。
download:布尔值,True 表示若本地无数据则自动下载。
transform:对数据应用的预处理变换(如 Resize、ToTensor 等)。
target_transform:对标签(label)应用的变换(较少使用)。
常用内置数据集及示例:
(1)MNIST(手写数字数据集)
包含 60,000 张训练图像和 10,000 张测试图像,尺寸为 28×28(单通道灰度图),标签为 0-9 的数字。
from torchvision import datasets
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter# 定义预处理变换(转换为Tensor)
transform = transforms.Compose([transforms.ToTensor()])# 加载训练集
train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)# 加载测试集
test_dataset = datasets.MNIST(root="./data", train=False, download=True, transform=transform)# 使用SummaryWriter创建TensorBoard日志
writer = SummaryWriter("logs") # 日志保存路径# 从训练集中选取前5张图片并写入TensorBoard
num_images = 5 # 要显示的图片数量
for i in range(num_images):# 获取第i个样本(图片和标签)image, label = train_dataset[i]# MNIST图片加载后形状为(1, 28, 28),正好符合CHW格式# 写入TensorBoardwriter.add_image(tag=f"MNIST_Train_Images/Label_{label}",img_tensor=image, # 形状为(1, 28, 28)global_step=i,dataformats="CHW" # 明确指定为通道数、高度、宽度格式)writer.close()
print("图片已成功写入TensorBoard,可通过命令 tensorboard --logdir=logs 查看")
运行结果:

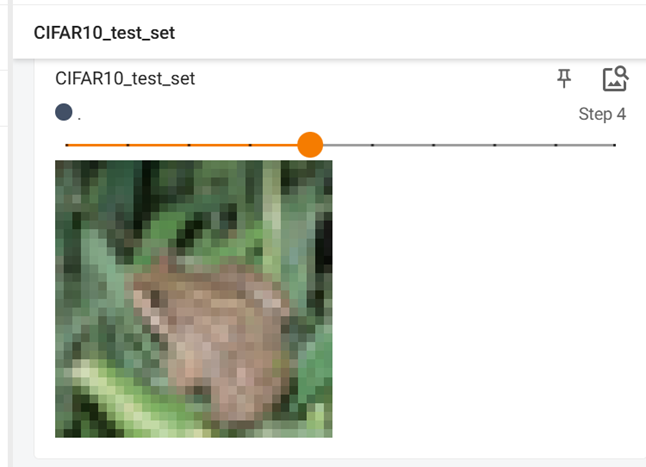
(2)、CIFAR-10(10 类小图像数据集)
包含 50,000 张训练图像和 10,000 张测试图像,尺寸为 32×32(3 通道 RGB 图),类别包括飞机、汽车、鸟类等。

代码演示:
import torchvision
from torch.utils.tensorboard import SummaryWriter# 把dataset_transform运用到数据集中的每一张图片,都转为tensor数据类型
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()
])
# root使用相对路径,会在该.py所在位置创建一个叫dataset的文件夹,同时把数据保存进去
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)# print(test_set[0])writer = SummaryWriter("logs")
# 显示测试数据集中的前10张图片
for i in range(10):img, target = test_set[i]writer.add_image("CIFAR10_test_set", img, i) # img已经转成了tensor类型writer.close()运行结果:
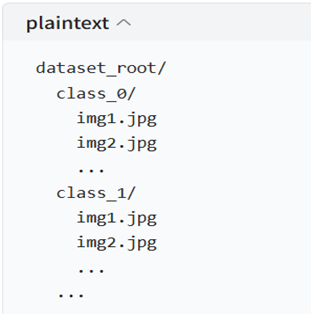
(2)、自定义数据集加载:ImageFolder
当处理自有数据时,ImageFolder 是最常用的工具,要求数据按“类别→图像”的目录结构存放如下:
ImageFolder 参数:
root:数据集根目录(包含所有类别子目录)。
transform:数据预处理变换。
target_transform:标签变换(可选)
代码演示:
from torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.tensorboard import SummaryWriter# 定义数据变换
transform = transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor()
])# 加载数据集
train_dataset = ImageFolder(root="custom/train", # 训练集根目录transform=transform
)# 查看数据集信息
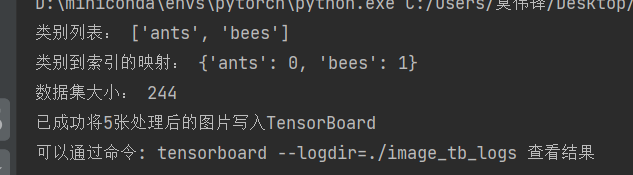
print("类别列表:", train_dataset.classes)
print("类别到索引的映射:", train_dataset.class_to_idx)
print("数据集大小:", len(train_dataset))# 创建TensorBoard写入器
writer = SummaryWriter("logs")# 选择要显示的图片数量
num_images = 5# 抽取5张图片并显示
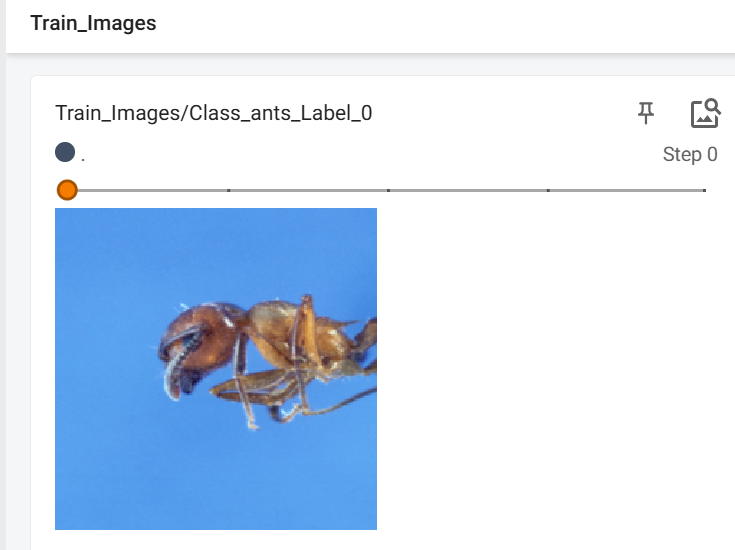
for i in range(num_images):# 获取图像和标签image, label = train_dataset[i]# 获取类别名称class_name = train_dataset.classes[label]# 写入TensorBoardwriter.add_image(tag=f"Train_Images/Class_{class_name}_Label_{label}",img_tensor=image,global_step=i,dataformats="CHW" # 图像格式为(通道数, 高度, 宽度))# 关闭写入器
writer.close()
print(f"已成功将{num_images}张处理后的图片写入TensorBoard")
print("可以通过命令: tensorboard --logdir=logs 查看结果")
运行结果:
4.3 DataLoader:批量数据加载器
DataLoader 来自 torch.utils.data 模块,用于将数据集按批次(batch)加载,支持多线程加速、数据打乱等功能,是训练时不可或缺的工具。
4.3.1 核心参数
- dataset:要加载的数据集(如 train_dataset)。
- batch_size:每批次的样本数量(如 32、64,根据显存大小调整)。
- shuffle:布尔值,True 表示每个 epoch 打乱数据顺序(仅用于训练集)。
- num_workers:加载数据的进程数(多线程加速,Windows 系统建议设为 0,避免报错)。
- drop_last:布尔值,True 表示丢弃最后一个不完整的批次(如总样本数 100,batch_size=32 时,最后 4 个样本会被丢弃)。
- pin_memory:布尔值,True 表示将数据加载到 CUDA pinned 内存(加速 GPU 访问,仅当使用 GPU 时有效)。
4.3.2 代码演示
# 用上节课torchvision提供的自定义的数据集
# CIFAR10原本是PIL Image,需要转换成tensorimport torchvision.datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())# 加载测试集
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# batch_size=4,意味着每次从test_data中取4个数据进行打包writer = SummaryWriter("logs")
step = 0
for data in test_loader:imgs, targets = data # imgs是tensor数据类型writer.add_images("test_data", imgs, step)step = step + 1
print("写入数据!")
writer.close()
运行结果:
运行结果:

参考:
【我是土堆 - Pytorch教程】 知识点 学习总结笔记(三)-CSDN博客