除了DeepSpeed,在训练和推理的时候,显存不足还有什么优化方法吗?FlashAttention 具体是怎么做的
除了DeepSpeed,训练和推理时显存不足的优化方法及FlashAttention原理详解
DeepSpeed的基础内容:ZeRO分布式训练策略
一、显存不足的优化方法
1. 混合精度训练(Mixed Precision Training)
- 原理
使用FP16和FP32混合精度,权重和激活用FP16存储(减少显存占用),关键计算(如梯度累积)用FP32保持数值稳定性。 - 工具支持
- NVIDIA的Apex库
- PyTorch的
AMP(自动混合精度)
2. 梯度累积(Gradient Accumulation)
- 原理
将多个小批次的梯度累加后统一更新,等效于增大批次大小,显存占用仅为单个小批次的量。
3. 激活检查点(Activation Checkpointing)
- 原理
反向传播时重新计算中间激活值,而非存储所有中间结果,牺牲计算时间换取显存节省。 - 实现
PyTorch的torch.utils.checkpoint。
4. 模型并行与流水线并行
- 模型并行
将模型拆分到多个GPU上(如将Transformer层分片)。 - 流水线并行
按层分段,不同GPU处理不同阶段的数据。
5. 参数卸载(Offloading)
- 原理
将暂时不用的参数/梯度卸载到CPU内存,需时再加载回GPU。 - 工具
DeepSpeed的ZeRO-Offload、Hugging Face的accelerate库。
6. 模型量化(Quantization)
- 训练后量化
将FP32权重转换为INT8等低精度格式(推理时使用)。 - 动态量化
推理时动态降低精度,如PyTorch的torch.quantization。
7. 模型蒸馏(Knowledge Distillation)
- 原理
用小模型(学生模型)学习大模型(教师模型)的输出分布,减少参数量。
8. 内存高效优化器
- Adafactor
优化器状态用低秩分解存储,显存占用低于Adam。 - SM3
适用于稀疏训练的优化器。
9. 动态计算图与稀疏激活
- Mixture of Experts (MoE)
每个样本仅激活部分专家层,如Switch Transformer。
10. 数据加载与预处理优化
- 使用
TFRecord(TensorFlow)或WebDataset加速数据加载,减少CPU到GPU的等待时间。
二、FlashAttention的实现原理
1. 传统注意力机制的显存瓶颈
传统Transformer计算注意力时需存储中间矩阵(如QKT和Softmax结果),显存复杂度为O(N²)(N为序列长度),导致长序列训练困难。
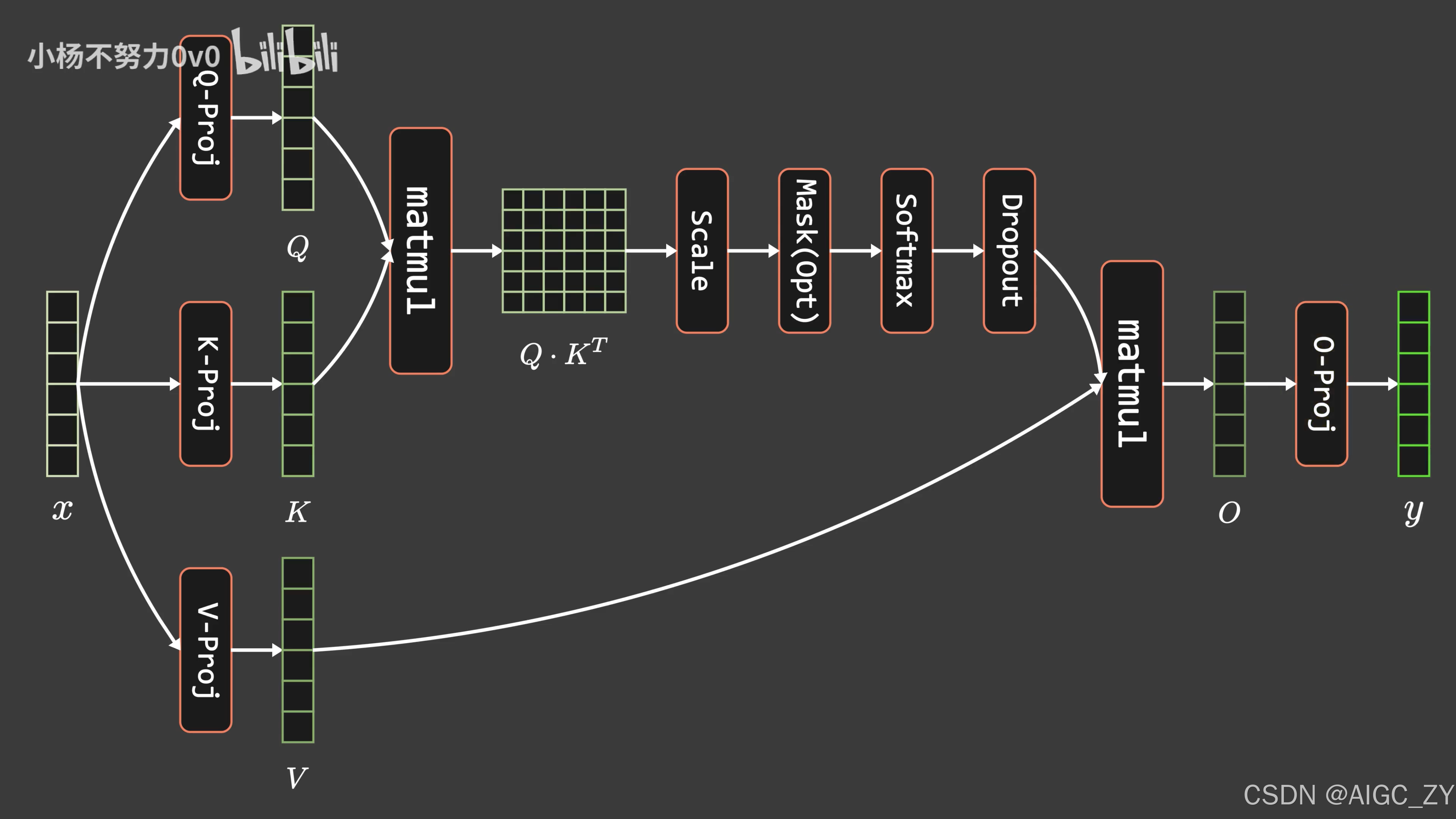
2. FlashAttention的核心思想
通过分块计算(Tiling)和重计算(Recomputation),避免存储中间矩阵,显存复杂度降至O(N)。
3. 实现步骤
- 分块计算
将Q、K、V矩阵切分为小块,在GPU高速缓存(SRAM)中逐块计算。 - 增量更新
逐步计算Softmax并更新输出,避免存储完整的QKT矩阵。- Softmax技巧:保存每块的归一化因子,融合到最终结果中。
- 反向传播优化
重计算中间结果而非存储,牺牲计算时间换取显存节省。
4. 优势
- 显存节省:显存占用降低4-20倍(依赖序列长度)。
- 速度提升:利用GPU SRAM的高带宽,减少HBM访问次数,加速计算。
5. 适用场景
- 长序列任务(如文本、音频、图像处理)。
- 支持CUDA GPU,已集成到
Triton库和Hugging FaceTransformers中。
三、总结
显存优化需结合算法、系统、硬件多层面策略,而FlashAttention通过算法创新显著降低了注意力机制的显存需求,是Transformer模型长序列训练的突破性优化。实际应用中,可混合使用多种方法(如混合精度+梯度累积+FlashAttention)实现最佳效果。