MySQL 数据库优化设计:优化原理和数据库表设计技巧
MySQL 数据库优化设计:从字段到索引的黄金法则
在构建高性能应用程序时,一个优化的数据库设计是地基。MySQL 优化不仅是关于编写更快的 SQL,更关键的是从 数据结构、索引策略 和 存储引擎 三个维度进行设计。
它们直接决定了数据库的运行效率:
- 数据结构 (Data Types): 决定存储空间和数据完整性。
- 索引 (Indexing): 决定查询速度和 I/O 成本。
- 存储引擎 (Storage Engine): 决定事务支持、锁机制和并发性能。
本文将总结优化数据库设计的三个核心原则。当然还要考虑数据表之间的关联,范式规范,有时候需要通过字段冗余进行反范式设计,减少io次数,提升查询效率。
字段类型的精打细算
选择正确的数据类型是优化的第一步,它直接决定了磁盘存储空间和查询效率。我们的核心原则是:选择能满足需求且占用空间最小的类型。
1. 字符串:CHAR vs. VARCHAR
| 特性 | CHAR (定长) | VARCHAR (变长) | 适用场景 |
|---|---|---|---|
| 存储机制 | 固定长度,不足部分用空格填充。 | 实际长度存储,外加 1~2 字节 存储长度信息。 | 长度固定(如 MD5 32位哈希,11位手机号) |
| 空间效率 | 低效(数据短时会浪费空间)。 | 高效(只占用实际数据空间)。 | 长度变化大(如用户名、标题) |
| 读写性能 | 稳定快速,因为数据位置固定。 | 变长更新时可能导致 行碎片,需要行迁移。 |
变长带来的 I/O 成本
当一个 VARCHAR 字段更新后,如果新数据变长且无法容纳在原有的物理空间内,InnoDB 存储引擎会将其移动到新的位置,并在原位置留下一个指针。
下一次查询这条记录时,数据库需要执行两次 I/O:第一次读取指针,第二次跟随指针到新位置读取数据,导致查询速度变慢。因此,如果字段长度变动不大,或者对性能要求极高,定长的 CHAR 更有优势。
2. 数字类型:选择最小且使用 UNSSIGNED
对于整数,我们应根据最大值选择:
- 错误选择: 存储用户年龄(最大
岁)时,使用
INT(4 字节)。 - 优化选择: 使用
TINYINT(1 字节)。
更进一步,由于年龄不会是负数,我们应添加 UNSIGNED(无符号) 关键字:
TINYINT范围:-128到127TINYINT UNSIGNED范围:0到 255
使用 UNSIGNED 不仅将存储上限提高了一倍,更重要的是在结构层面强制执行了 数据完整性 规则,阻止了负数这种无效数据的写入。
索引设计的黄金法则
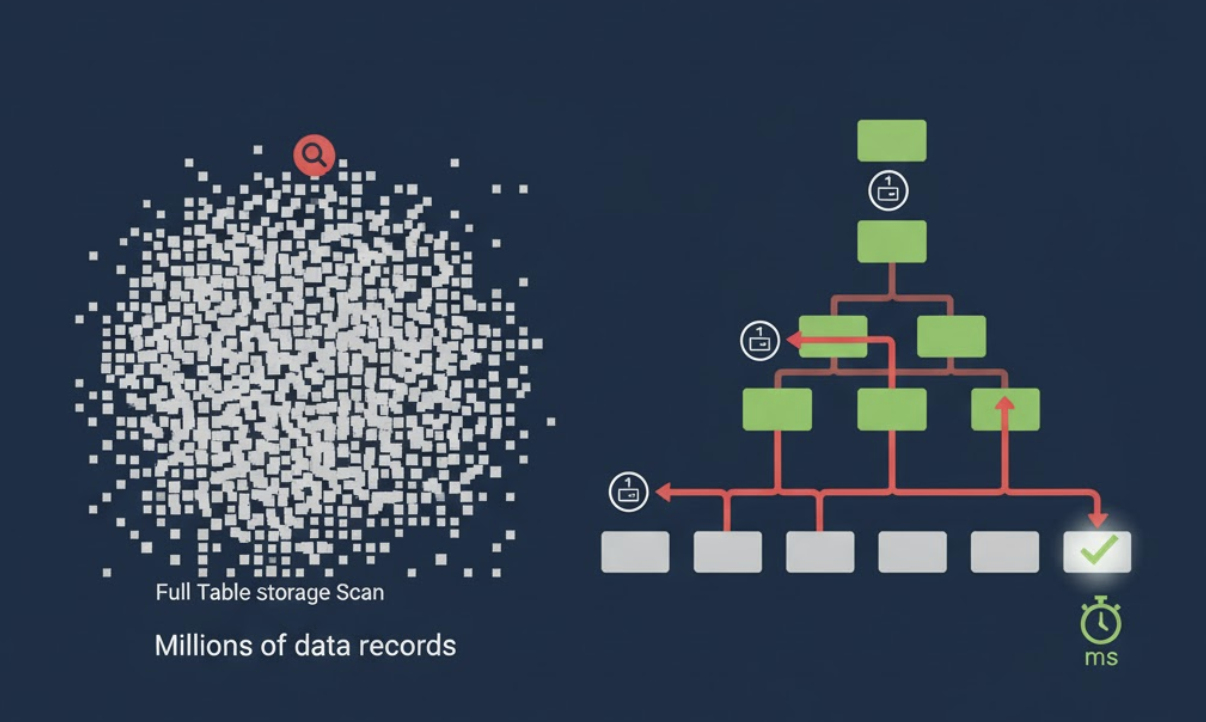
索引是数据库性能优化的核心。没有索引,查询会退化为耗费大量 磁盘 I/O 的全表扫描。
1. B-Tree 的高效秘密
MySQL 使用的 B-Tree(B+ Tree)结构之所以高效,是因为它是一种矮胖结构。一个 KB 的索引页可以容纳数百个键值和指针,导致树的分支系数极高。
对于数百万条数据,B-Tree 通常只需 3 到 4 次 I/O 就能定位到所需数据,极大减少了磁盘访问。
2. 避免回表:聚簇索引与二级索引
在 InnoDB 中,有两种索引:
| 索引类型 | 叶子节点存储内容 | 查找流程 | 查找 I/O 次数 |
|---|---|---|---|
| 聚簇索引 (主键) | 完整的数据行 | 1. 查找索引树 2. 直接获取数据 | 1 次 B-Tree 查找 |
| 二级索引 (普通索引) | 对应的主键值 | 1. 查找二级索引 2. 获取主键 3. 回表查找聚簇索引 4. 获取数据 | 2 次 B-Tree 查找 |
回表 (Table Lookup) 是二级索引相比主键索引 I/O 成本更高的根本原因。
3. 终极目标:覆盖索引与最左前缀
索引设计的两大目标:加速查找和避免回表。
-
目标一:覆盖索引 (Covering Index)
- 定义: 索引中包含了查询语句
SELECT和WHERE所需的所有字段。 - 效果: 数据库只访问索引即可返回结果,彻底避免回表。
- 案例: 对于查询
SELECT username, email WHERE email = '...',应创建复合索引(email, username)。
- 定义: 索引中包含了查询语句
-
目标二:最左前缀原则 (Left-most Prefix Rule)
- 原则: 对于复合索引
(A, B, C),查询条件必须从最左侧的字段开始使用,才能利用索引加速。 - 黄金法则: 将查询中等值条件(如
WHERE user_id = 100)且选择性高(能迅速排除大量数据)的字段放在复合索引的最左侧。 - 案例: 查询条件是
WHERE user_id = 100 AND order_date > '...',索引应设计为(user_id, order_date)。如果设计为(order_date, user_id),则无法加速只通过user_id查找的查询。
- 原则: 对于复合索引
随着mysql的发展,我们编写sql的时候,不用刻意指定字段顺序。当时理解最左前缀原则,可以帮助在设计索引的时候,建立合适的字段顺序,提高索引利用效果。
存储引擎与高并发
存储引擎的选择决定了数据库的数据安全性和高并发能力。InnoDB 已是 MySQL 的默认选择,其优势在于对事务和锁的支持。
| 特性 | InnoDB | MyISAM |
|---|---|---|
| 事务支持 | 支持 (COMMIT/ROLLBACK) | 不支持 |
| 数据安全 | 高(支持崩溃恢复) | 低 |
| 锁机制 | 行级锁 | 表级锁 |
| 并发性能 | 高(可同时处理多行) | 低(写入时需要排队) |
行级锁 vs. 表级锁
假设 100个用户同时更新同一张表的不同行数据:
- MyISAM (表级锁): 任何一个用户开始更新,都会锁定整个表。其他
个用户必须排队等待,导致并发性能急剧下降。
- InnoDB (行级锁): 用户 A 更新第 1 行,用户 B 更新第 100 行。他们互不干扰,可以同时进行操作。
结论: InnoDB 的行级锁极大地提高了高并发性,从而保证了数据库在处理高流量时拥有更高的 TPS (Transaction Per Second,吞吐量) 。
这是一个非常好的深入点!联表查询(JOIN)是关系型数据库的灵魂,也是性能瓶颈最常出现的地方。
我们来深入探讨联表查询的底层逻辑、核心算法,以及如何从设计和查询层面进行优化。
联表查询(JOIN)的逻辑与优化
联表查询的底层算法:嵌套循环连接(NLJ)
当我们在 MySQL 中执行 JOIN 操作时,优化器最常使用的基本算法是嵌套循环连接 (Nested Loop Join, NLJ) 。
它的逻辑非常直观,类似于程序中的两层 for 循环:
假设我们查询 SELECT * FROM A JOIN B ON A.id = B.a_id。
-
确定驱动表和被驱动表: MySQL 优化器会选择一个表作为驱动表(外层循环),另一个表作为被驱动表(内层循环)。
-
执行过程(NLJ):
- 从驱动表 A 中取出一行数据。
- 拿着这一行数据中的关联字段值 (
A.id),去被驱动表 B 中查找所有匹配的行 (B.a_id = A.id)。 - 将匹配的结果合并,作为结果集的一部分。
- 重复以上步骤,直到驱动表 A 的所有行都被处理完毕。
性能瓶颈:
如果驱动表有 MMM 行,被驱动表有 NNN 行,且被驱动表上的关联字段没有索引,则总查询次数约为:M+(M×N)M + (M \times N)M+(M×N)。这是一个灾难性的性能问题。
联表查询的优化策略 (两大核心)
联表查询优化的核心思想是:让被驱动表的查找过程变成高效的索引查找,而不是全表扫描。
优化策略一:为关联字段建立索引
要让 NLJ 算法高效工作,必须确保内层循环(查找被驱动表)的效率。
-
优化措施: 为被驱动表(B)的关联字段(
B.a_id)加上索引。 -
优化原理:
- 当从驱动表 A 取出一行数据后,拿着
A.id的值去 B 表查找匹配行时,如果B.a_id上有索引,查找过程将从 O(N)O(N)O(N) 的全表扫描,降为 O(logN)O(\log N)O(logN) 的 B+ 树查找。 - I/O 成本: 总成本从 M×NM \times NM×N 次查找,大幅优化为 MMM 次 B+ 树查找(忽略常数 I/O)。
- 当从驱动表 A 取出一行数据后,拿着
优化策略二:选择正确的驱动表 (小表驱动大表)
-
优化措施: 尽量选择行数较少的表作为驱动表(外层循环),即著名的“小表驱动大表”。
- 注意: 这里的“小”不仅指行数,更指优化器实际需要访问和处理的行数。
-
优化原理:
- 驱动表决定了外层循环的次数(即对被驱动表进行索引查找的次数)。
- 如果驱动表(A)有 MMM 行,被驱动表(B)有 NNN 行(且 M<NM < NM<N),选择 A 作为驱动表,只需要执行 MMM 次 B+ 树查找。如果选择 B 作为驱动表,则需要执行 NNN 次 B+ 树查找。
- 结论: 较小的 MMM 次查找,总 I/O 成本更低。
联表查询的优化进阶:MRR 与 BKA 算法
NLJ 算法可以进一步优化为 块嵌套循环连接 (Block Nested Loop, BNL) 和 批量键查找 (Batched Key Access, BKA) 算法。
| 算法 | 关键逻辑 | 性能特点 | 优化依赖 |
|---|---|---|---|
| NLJ | 每次只从驱动表取 1 行,然后去被驱动表查找。 | 基础算法,如果被驱动表无索引则慢。 | 被驱动表上的索引。 |
| BKA | 每次从驱动表取出 一批数据,存入 Join Buffer,然后用这一批关联键批量去被驱动表上进行索引查找。 | 性能更高,利用磁盘的顺序预读,减少随机 I/O。 | 必须依赖被驱动表上的索引。 |
实战总结: 目标是让优化器能够选择 BKA 算法。实现这一点的最有效方法就是确保 被驱动表的关联字段上存在高效索引。
案例说明
假设我们有两个表:
-
users(用户表): 1000 万行 -
orders(订单表): 100 万行 -
查询:获取某一个用户的订单列表:
SELECT u.username, o.order_id, o.amount
FROM users u JOIN orders o ON u.user_id = o.user_id
WHERE u.username = 'Alice';
优化前的潜在问题
如果 orders.user_id 字段没有索引:
- 优化器通常会选择行数少的
orders作为驱动表(100 万次循环)。 - 但由于查询有
WHERE u.username = 'Alice'筛选条件,优化器会先处理users表的筛选,所以驱动表很可能是users。 - 如果
users是驱动表,它取出 Alice 的user_id(1 次循环),然后去orders表查找。由于orders.user_id没有索引,它将对orders表进行全表扫描(100 万次 I/O)。
优化后的设计(核心是加索引)
优化设计:
users表: 确保username上有索引(加速 WHERE 筛选)。orders表: 在关联字段user_id上建立索引。
优化后的逻辑:
- 优化器首先通过
users.username上的索引,快速找到用户 Alice 的user_id。 - 优化器选择
users作为驱动表(因为经过WHERE筛选后,它只有 1 行)。 - 拿着 Alice 的
user_id,去被驱动表orders中查找。由于orders.user_id上有索引,这次查找是非常高效的 B+ 树查找。
结论: 联表查询优化的 90%90\%90% 工作,都是确保被驱动表的关联字段上有合适的索引。
总结与展望
一个优化的 MySQL 数据库,是在空间效率(小数据类型)、查询速度(高效索引)和业务可靠性(InnoDB 事务和锁)之间找到的最佳平衡点。