【Redis】缓存热点数据
Redis缓存数据功能
目录
- 概述
- 缓存设计原则
- 项目中的缓存实现
- 3.1 店铺信息缓存
- 3.2 店铺类型缓存
- 缓存操作流程
- 技术要点
- 缓存优化建议
- 总结
概述
在本项目中,为了提高系统的响应速度和减轻数据库压力,我们使用Redis作为缓存层来存储热点数据。主要缓存的数据包括店铺信息和店铺类型信息。
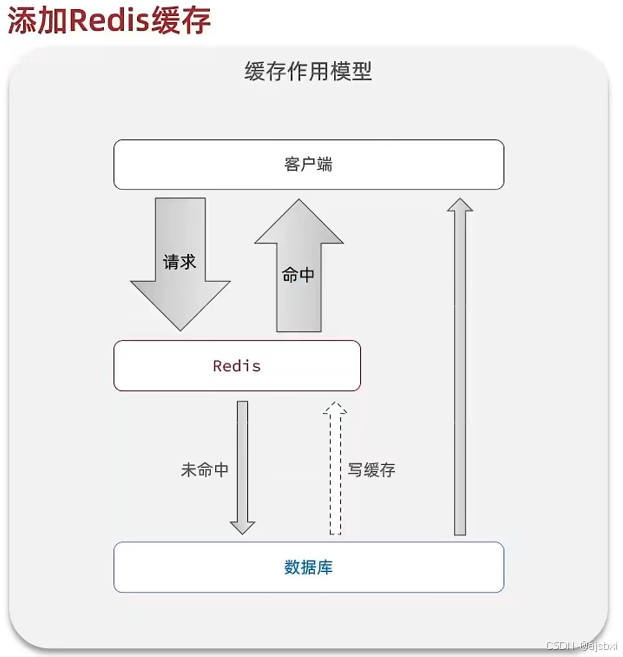
缓存的核心思想是:
- 查询数据时先从缓存中获取
- 如果缓存命中则直接返回
- 如果缓存未命中则查询数据库,并将结果写入缓存
缓存设计原则
- 读写策略:采用先读缓存,缓存不命中再读数据库的策略
- 数据一致性:缓存中的数据设置合理的过期时间
- 键命名规范:使用统一的前缀+业务标识符作为缓存键
- 数据序列化:使用JSON格式存储复杂对象
项目中的缓存实现
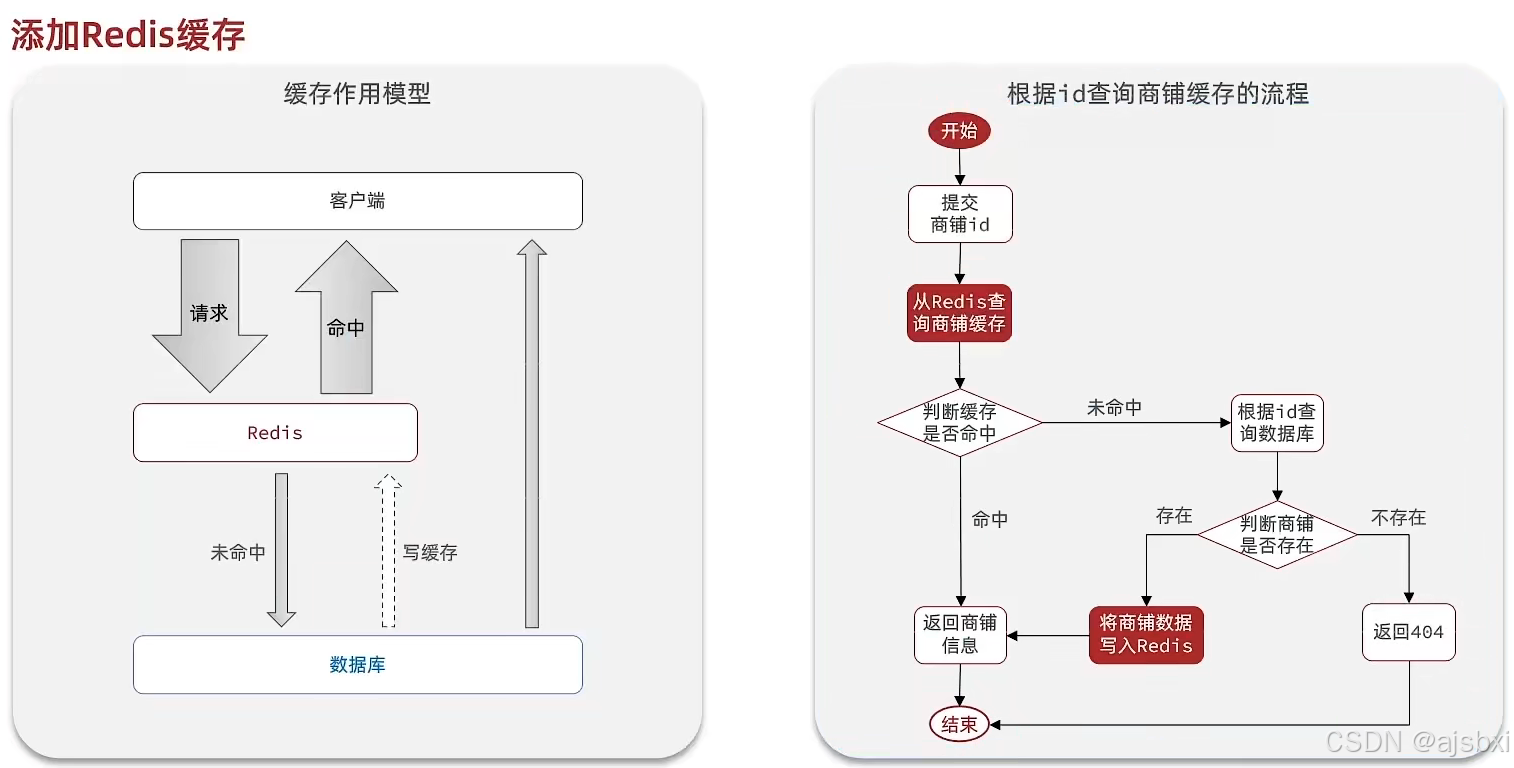
店铺信息缓存
店铺信息是系统的核心数据之一,访问频率高,适合缓存。
缓存流程图
缓存键设计
public class RedisConstants {public static final String CACHE_SHOP_KEY = "cache:shop:";
}
核心代码实现
@Override
public Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;// 从redis查询String shopJson = stringRedisTemplate.opsForValue().get(key);Shop shop = null;// 判断缓存是否命中if(StrUtil.isNotBlank(shopJson)){// 缓存命中,直接返回店铺数据shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}// 缓存未命中,从数据库中查询店铺数据shop = getById(id);if(Objects.isNull(shop)){// 不存在,返回错误return Result.fail("店铺不存在!");}// 数据库中存在,写入Redis,并返回店铺数据stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop));return Result.ok(shop);
}
店铺类型缓存
店铺类型信息相对稳定,访问频率也很高,同样适合缓存。
缓存键设计
public class RedisConstants {public static final String CACHE_SHOP_TYPE_KEY = "cache:shop:type:";public static final Long CACHE_SHOP_TYPE_TTL = 30L;
}
核心代码实现
@Override
public List<ShopType> queryTypeList() {// 1、从Redis中查询店铺类型String key = CACHE_SHOP_TYPE_KEY + UUID.randomUUID();String shopTypeJSON = stringRedisTemplate.opsForValue().get(key);// 2、判断缓存是否命中if (StrUtil.isNotBlank(shopTypeJSON)) {// 2.1 缓存命中,直接返回缓存数据return JSONUtil.toList(shopTypeJSON, ShopType.class);}// 2.1 缓存未命中,查询数据库List<ShopType> typeList = query().orderByAsc("sort").list();// 3、判断数据库中是否存在该数据if (Objects.isNull(typeList)) {// 3.1 数据库中不存在该数据,返回空列表return new ArrayList<>();}// 3.2 店铺数据存在,写入Redis,并返回查询的数据stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(typeList),CACHE_SHOP_TYPE_TTL, TimeUnit.MINUTES);return typeList;
}
缓存操作流程
读取流程
- 构造缓存键
- 从Redis中获取数据
- 判断缓存是否命中(数据是否存在且非空)
- 如果命中,直接反序列化并返回数据
- 如果未命中,查询数据库获取数据
- 将数据库查询结果序列化并存入Redis
- 返回数据
数据序列化与反序列化
- 对象序列化:使用
JSONUtil.toJsonStr()将Java对象转换为JSON字符串 - 对象反序列化:使用
JSONUtil.toBean()将JSON字符串转换为Java对象 - 列表序列化:使用
JSONUtil.toJsonStr()将List转换为JSON数组字符串 - 列表反序列化:使用
JSONUtil.toList()将JSON数组字符串转换为Java对象列表
技术要点
1. 缓存键设计
// 统一前缀命名规范
public static final String CACHE_SHOP_KEY = "cache:shop:";
public static final String CACHE_SHOP_TYPE_KEY = "cache:shop:type:";
2. 缓存过期时间
// 设置合理的过期时间,单位分钟
public static final Long CACHE_SHOP_TTL = 30L;
public static final Long CACHE_SHOP_TYPE_TTL = 30L;
3. 空值处理
对于数据库中不存在的数据,可以缓存空值防止缓存穿透:
if(Objects.isNull(shop)){// 可以将空值写入redis,防止缓存穿透stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);return Result.fail("店铺不存在!");
}
4. 数据一致性
通过设置合理的过期时间来保证缓存与数据库的数据一致性。
缓存优化建议
1. 缓存预热
对于热点数据,可以在系统启动时预先加载到缓存中。
2. 缓存更新策略
- 定时更新:定期刷新缓存数据
- 事件驱动更新:在数据变更时主动更新缓存
3. 缓存粒度控制
根据业务场景合理控制缓存的数据粒度,避免缓存过大的数据块。
4. 缓存监控
监控缓存的命中率、内存使用情况等指标,及时发现和解决问题。
总结
本项目中的缓存实现具有以下特点:
- 简单有效:采用经典的Cache-Aside模式,实现简单且效果明显
- 统一规范:使用统一的缓存键命名规范和过期时间设置
- 合理过期:为不同类型的数据设置合理的过期时间,平衡性能和一致性
- 易于扩展:缓存逻辑封装良好,便于后续添加新的缓存数据类型
通过引入Redis缓存,系统在以下方面得到了改善:
- 显著提高了数据查询的响应速度
- 减轻了数据库的查询压力
- 提升了系统的整体性能和用户体验
我们可以根据业务需求进一步优化缓存策略,比如引入多级缓存、实现缓存预热、使用更复杂的缓存更新机制等。