IEEE论文解读 | 基于概念驱动的强化学习探索方法(CDE)
核心问题
论文聚焦强化学习(RL)在视觉控制任务中的核心痛点 —— 高维图像信息提取难、探索效率低、视觉 - 语言模型(VLM)输出噪声干扰大,提出概念驱动探索(CDE)方法。该方法以 Franka Research 3 机械臂为实验载体,通过 “VLM 生成视觉概念 + 概念嵌入模型(CEM)学习双重表征 + 重构损失引导探索” 的创新框架,在模拟与真实世界操作任务中均实现高效探索与鲁棒性能,解决了传统视觉 RL 依赖全局视角、对噪声敏感、部署阶段依赖外部模型的关键问题。
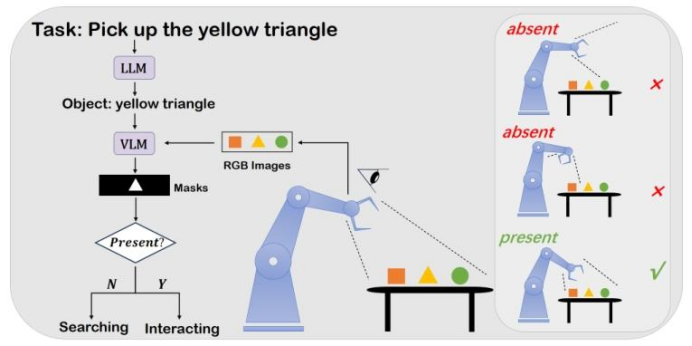
图 1:基于概念驱动的探索方法(CDE)整体框架。从任务描述中识别与任务相关的对象,再利用视觉 - 语言模型(VLM)为每个对象生成分割掩码。这些分割掩码用于塑造策略的表征学习过程,并引导探索方向。
验证方法与框架
CDE 的核心逻辑是 “以概念塑造表征,以表征引导探索”,整体框架分为 4 个关键模块
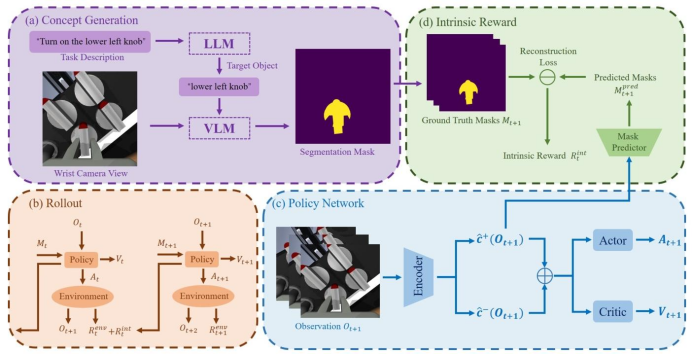
图2:CDE 架构图。(a)大语言模型(LLM)解析任务描述以提取目标对象,视觉 - 语言模型(VLM)对输入的 RGB 图像进行分割,生成掩码;(b)训练过程中,策略将分割掩码作为额外输入,并为最后一个时间步生成内在奖励信号;(c)在每个时间步 t+1,策略网络接收环境观测 oₜ₊₁,并将其编码为正嵌入向量ĉ⁺(oₜ₊₁) 与负嵌入向量ĉ⁻(oₜ₊₁),最终概念嵌入向量为这两个向量的加权和;(d)利用分割掩码 Mₜ₊₁监督从正嵌入向量ĉ⁺(oₜ₊₁) 中重构掩码的过程,并生成内在奖励信号 Rₜ^int。
1. 概念生成模块
输入:自然语言任务描述(如“打开微波炉门”);
流程:首先通过大语言模型(LLM,如 GPT-4)提取目标对象列表(如 “微波炉门把手”),再调用 VLM(如 Grounded-SAM2)从 RGB 图像中生成分割掩码(作为 “弱监督概念”);
作用:将抽象任务转化为具象的视觉概念(分割掩码),避免人工定义概念的局限性。
2. 概念学习模块(基于 CEM)
核心设计:针对腕部相机“目标可能不可见” 的问题,引入概念嵌入模型(CEM),学习对象的双重表征:
正嵌入(c^i+):对应目标对象在画面中 “存在” 的状态;
负嵌入(c^i−):对应目标对象在画面中 “缺失” 的状态;
表征融合:通过VLM 生成的分割掩码判断目标是否存在(激活像素数≥阈值 ε 则为 “存在”),以二元权重(pi)融合双重表征,公式为:c^i=pic^i++(1−pi)c^i−(训练时用 VLM 掩码判断pi,部署时用模型预测掩码判断)。
3. 内在奖励模块
奖励来源:以“正嵌入重构分割掩码的损失(Lrecons)” 作为内在奖励;
计算逻辑:已探索过的状态重构损失小,未探索的目标相关状态重构损失大,因此将γ⋅clip(Lrecons,0,1)加入总奖励,引导策略优先探索目标相关区域;
优势:相比传统“像素奖励”,重构损失对 VLM 噪声更鲁棒,且无需依赖外部信号。
4. 联合优化模块
总损失函数:将RL 的评论家损失(Lcritic)与重构损失(Lrecons)联合优化,公式为:Ltotal=αLcritic+βLrecons(α、β 为权重系数);
关键特性:训练阶段仅需VLM 提供初始概念,部署阶段策略已 “内化” 概念,无需再调用 VLM,降低实时依赖。
实验配置
机械臂:Franka Research 3(用于真实世界实验,具备高精度力控与运动控制能力);
相机:Intel Realsense D435i(腕部安装,仅提供第一视角观测,模拟真实部署场景);
计算资源:NVIDIA A100 GPU(40GB),用于模拟实验的训练(30万时间步,GT/SN 掩码任务耗时约4小时,VLM掩码任务耗时约8小时)。
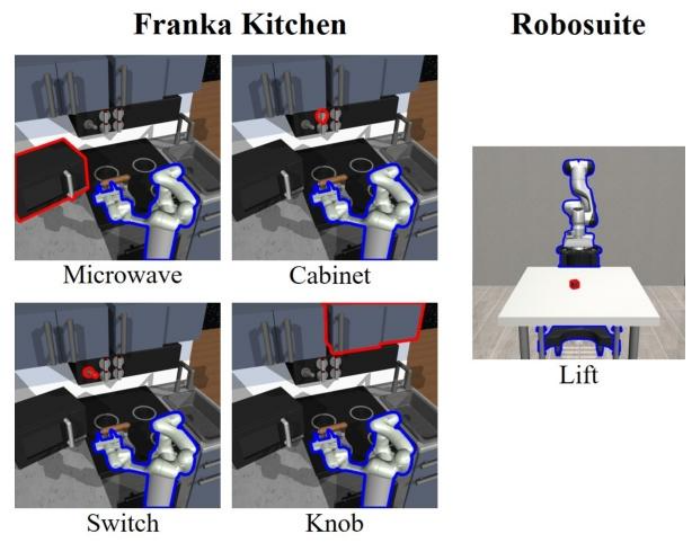

图8:(a) 现实世界任务设置。(b) 腕戴式相机视角。
实验设计与验证(问题与挑战)
问题 1:是否适配 “非全局视角”(腕部相机)?
验证逻辑:对比“使用 CEM 双重表征” 与 “仅使用正表征” 的消融实验(见表 1);
结果:使用双重表征的CDE 在 “目标不可见频率高” 的任务(如 Lift)中成功率提升 15%-20%,证明 CEM 有效解决了腕部相机的视角局限;
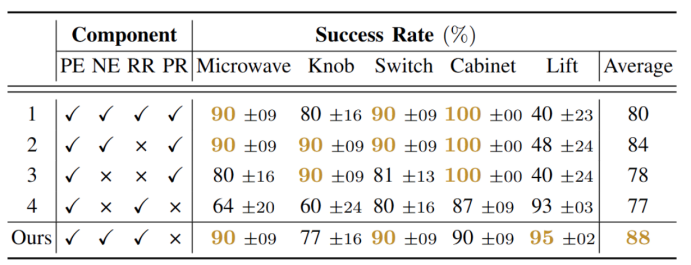
表1:消融研究。PE代表正嵌入,NE代表负嵌入,RR代表重建奖励,PR代表像素奖励。我们报告平均成功率及标准误差,每个任务的最高成功率用黄色突出显示。
核心结论:双重表征使策略在“搜索目标” 与 “交互目标” 两种模式间平滑切换,避免因目标不可见导致的探索停滞。
问题 2:是否对 VLM 噪声鲁棒?
验证逻辑:在SN(合成噪声)与 VLM(真实噪声)场景下,对比 CDE 与基准方法(DrQv2-RGB、DrQv2-RGBM、DrQv2-ME)的性能;
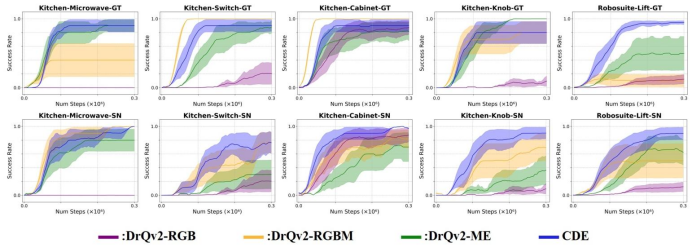
图5:模拟任务结果。所有任务均在10个随机种子上运行,我们报告平均成功率及标准误差。(顶行)使用地面实况掩码进行学习。(底行)使用带有合成噪声的掩码进行学习。CDE比基线方法对噪声掩码输入表现出更好的稳定性和鲁棒性。
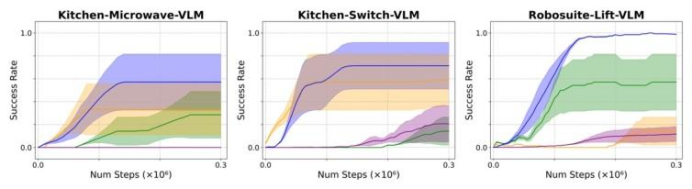
图6:使用VLM生成掩码的模拟任务结果。由于计算资源的限制,我们在7个随机种子上运行了部分任务,并报告了带有标准误差的平均成功率。对于DrQv2-RGB,我们使用之前实验的结果进行比较。
关键发现
SN 场景:CDE 在 Knob、Switch 等任务中成功率比基准方法高 10%-15%,因基准方法直接使用含噪掩码,会传递误差;
VLM 场景:CDE 性能接近 GT 场景,而基准方法性能下降 30% 以上,证明 CDE 通过 “重构损失” 有效过滤了 VLM 噪声;
例外分析:在Knob 任务中,CDE 在 SN 场景的性能优于 GT 场景 —— 因 GT 场景中多个非目标旋钮会干扰探索,而 SN 场景仅扰动目标掩码,反而聚焦了探索方向。

图4:每种噪声设置下的示例掩码。图像和掩码的分辨率均为84×84,对于VLM掩码,我们在320×320的RGB图像上分割掩码,然后下采样到84×84。
问题 3:是否实现 “高效探索”?
验证方法:记录训练初期(33% 时间步)、中期(66%)、后期(100%)的机械臂末端位置,以热力图可视化探索轨迹(见图 7);
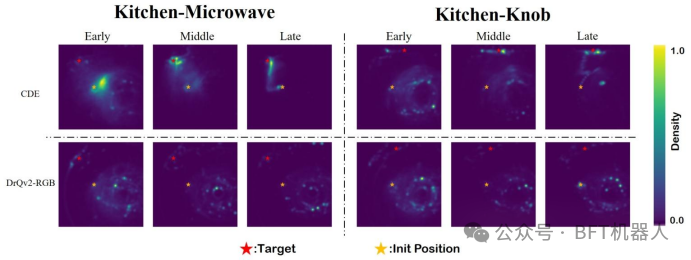
图7:热图展示了训练三个不同阶段访问过的状态:早期(33%)、中期(66%)、晚期(100%)。CDE探索目标物体附近的状态,而DrQv2-RGB主要进行随机探索。
结果对比:
传统方法(如DrQv2-RGB):全程随机探索,热力图分散;
CDE:中期已聚焦目标区域,后期轨迹集中于 “最优交互位置”,探索效率提升约 50%;
核心结论:CDE通过 “重构损失引导” 实现了 “针对性广度优先搜索”,避免无意义的随机探索。
关键突破:
突破“VLM 依赖” 的部署瓶颈,为真实世界低延迟应用提供可能;
建立 “视角通用” 的视觉表征范式,解决了传统方法依赖全局视角的局限,拓宽了视觉RL 的应用范围。
未来应用方向
复杂场景机器人操作
多智能体协作任务
跨域迁移任务
结语
本文提出的CDE方法,以 “概念驱动” 为核心,通过VLM生成弱监督概念、CEM学习视角鲁棒表征、重构损失引导高效探索,系统性解决了视觉RL在 “高维信息处理”“噪声鲁棒性”“视角通用性” 上的三大痛点。
实验证明,CDE在Franka Research 3机械臂上不仅实现了80%的真实世界任务成功率,更在方法论上为 “弱监督、低依赖、高泛化” 的视觉RL提供了新范式。未来随着LLM/VLM的持续进化,CDE有望进一步拓展至更复杂的动态场景(如人机协作、未知环境探索),推动强化学习从 “模拟验证” 走向 “真实应用”。
项目链接:https://sites.google.com/view/concept-learn/home