【EE初阶 - 网络原理】应用层协议(上)
文章目录
- 一.应用层协议
- (一)如何自定义协议
- 1.明确传输信息
- 2.约定信息组织格式
- (二)HTTP协议[重点]
- 1.HTTP一问一答模式
- 2.HTTP报文格式
- 3.认识"方法"(method)
- 4.报头 header => 键值对结构
- Host =>表示服务武器主机的地址和端口
- Content-Length 和 Content-Type 可有可无 取决于是否有body,没有body就没有这两个属性
- User-Agent(简称UA)
- Referer 描述了当前页面来源
一.应用层协议
应用层协议与应用程序直接相关,程序员所写的代码,只要涉及到网络通信,都可以视为是应用层的一部分~~
虽然应用层里面有一些现成的协议,但是在实际开发工作中也会存在 自定义应用层协议(约定好客户端和服务器按照啥样的格式传输数据)
(一)如何自定义协议
具体如何自定义协议呢?
自定义协议,分为两个阶段
1.根据需求,明确传输哪些信息
2.约定好信息组织的格式
1.明确传输信息
比如,我们点外卖的时候
①.明确传输的信息
请求: 用户位置,用户ID
响应:商家信息(地址,商品,评分…)
这些信息都是根据需求来的
2.约定信息组织格式
②.信息的组织格式
1.行文本 一行为一个信息 (用得不多了)
1000, 45E45N\n 或者
杨国福,图片.jpg,14.5,麻辣烫\n
类似于这样的,当然啦这样的形式有很多变数
具体的取决于客户端和服务器,只要约定好,怎样都行
2.xml格式 (也用的比较少了) 可以自定义标签
优点:可读性比较好
缺点:冗余信息多,消耗带宽 ⇒ 带宽很贵
对于服务器来说,带宽最贵,内存其次,CPU小贵,磁盘最便宜
3.JSON(最流行) 键值对 逗号分隔
优点:可读性好,相比xml带宽有所节省
缺点:仍存在冗余信息
使用 { } 来包含一些键值对;键值对之间,使用逗号分隔,每个键值对的键和值之间使用冒号分割
JSON 要求键的部分必须是字符串,而值的部分,可以是数字,可以是字符串,还可以是数组(使用[ ],甚至可以是另一个JSON)
4.protobuf 基于二进制的格式,对数据进行压缩,这样就不涉及 JSON和xml的冗余信息了
带宽消耗最少,可读性变差了



json 是当下用来自定义协议的时候,非常常用的格式!也有很多相关的第三方库,可以用来操作 json 数据
数据组织格式
- 1.行文本(最原始)
- 2.xml(比较原始,可读性好,冗余较多)
- 3.JSON(最主流的方式,可读性好,冗余一般) --> Java web开发的基本盘
- 4.protobuf(高性能场景下使用的方式,可读性差,冗余最小)
但凡实现一个具体程序,写代码之前,一定要先约定应用层协议的格式~~
(二)HTTP协议[重点]
应用层除了自定义协议之外,还有一些大佬搞好的现成的协议
FTP 文件传输
SSH 远程操作主机
telent 网络调试工具

其中HTTP协议为当前web开发中最核心的协议,只要使用网站,都会用到HTTP
大家在网站常看到的都是HTTPS
HTTPS = 在HTTP的基础上 + 安全层(S表示安全层,SSL)
目前我们使用的最流行的版本是 HTTP/1.1
1.HTTP一问一答模式
客户端发一个请求,服务器就返回一个响应,请求响应一一对应
网络通信也有其他模型
- 多问一答 -->上传大文件
- 一问多答 -->下载大文件
- 多问多答 -->远程控制
浏览器打开网页的场景/手机APP加载数据的场景,都是典型的一问一答,使用 HTTP就非常合适
2.HTTP报文格式
需要打配抓包工具,来查看报文格式
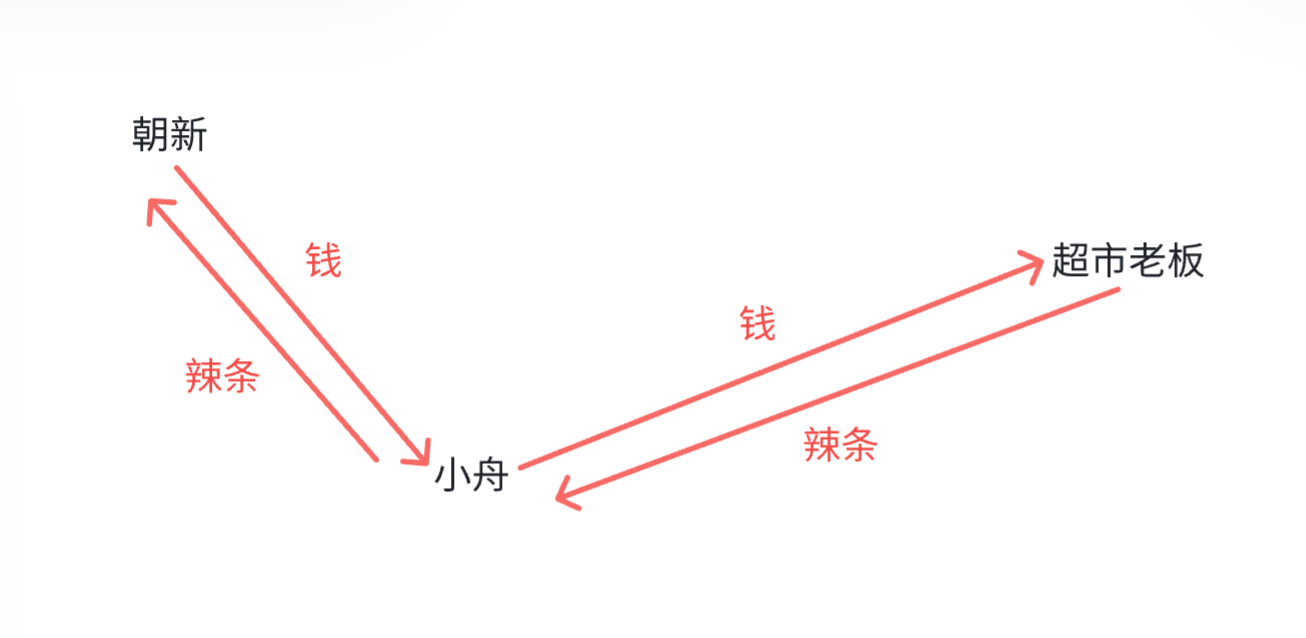
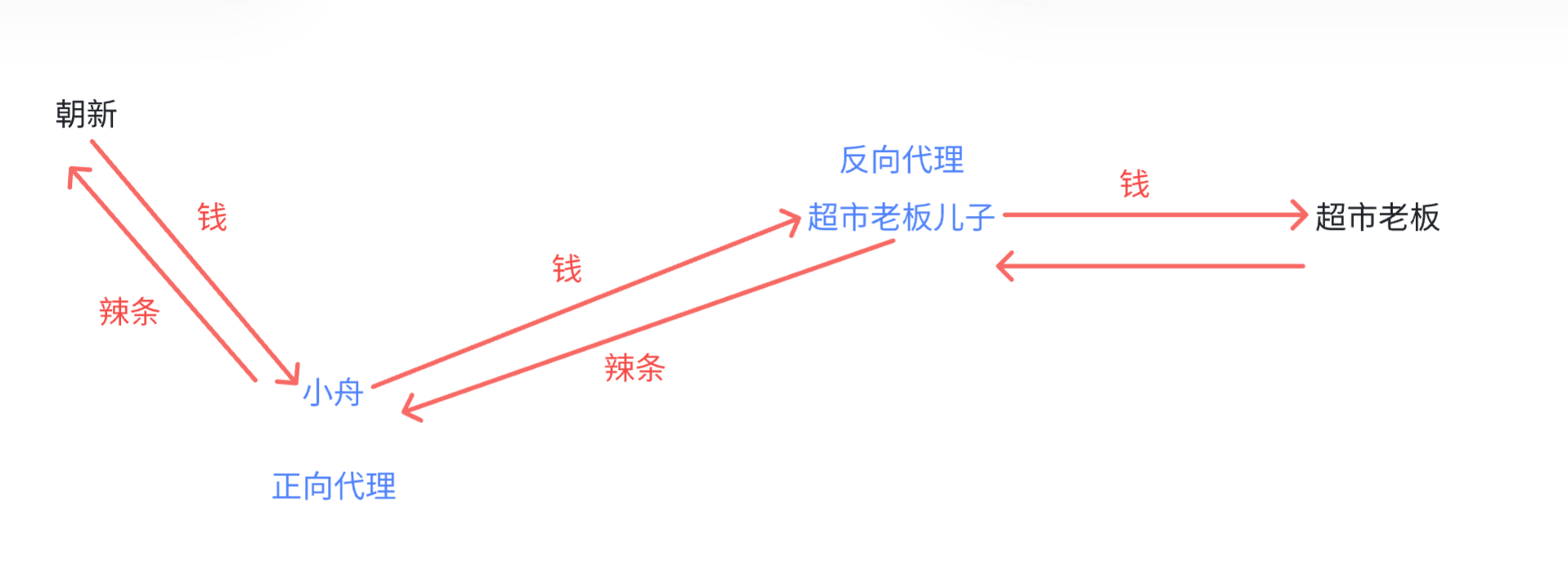
抓包工具:能够获取到网络的数据包,详细的格式都解析出来
抓包工具相当于"代理" --正向代理 反向代理
其中,小舟同学就相当于一个代理
其中,老板儿子也是一个代理
正向代理(代表为客户端干活)
反向代理(代表为服务器干活)
抓包工具的使用
wireshark 知名的抓包工具,能抓很多协议,HTTP,TCP,UDP,IP,以太网数据帧…使用起来门槛比较高,比较麻烦~~
fiddler 专门抓HTTP,功能简单,使用更简单
我们使用fiddler就足够了,后续我们演示都是用fiddler来抓包
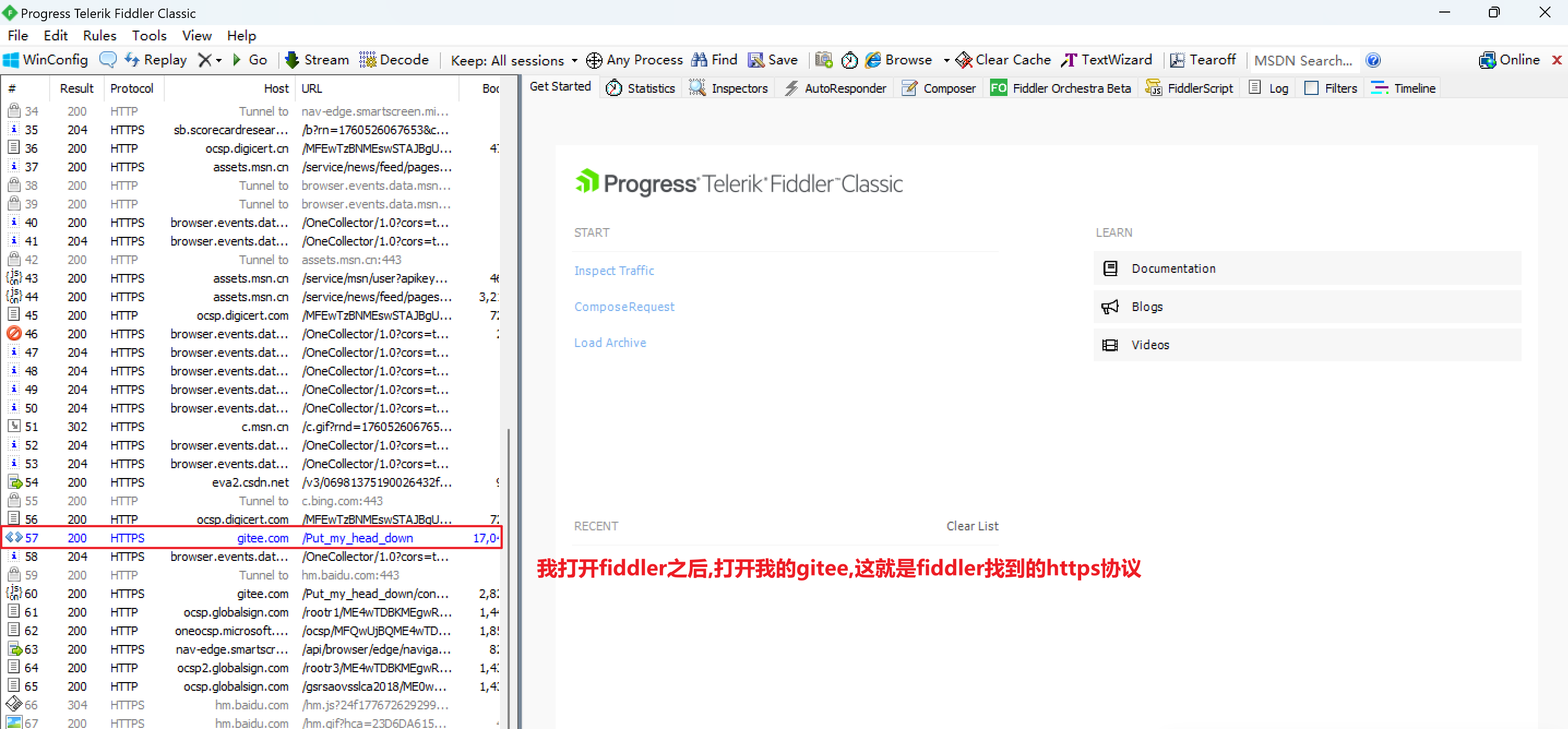
左侧窗口,当前的请求/响应的列表(fiddler只抓HTTP)
红色表示报错
蓝色表示关键抓包数据,这个请求得到这个网页
绿色表示得到了一个js
灰色表示这个相应数据已经被缓存
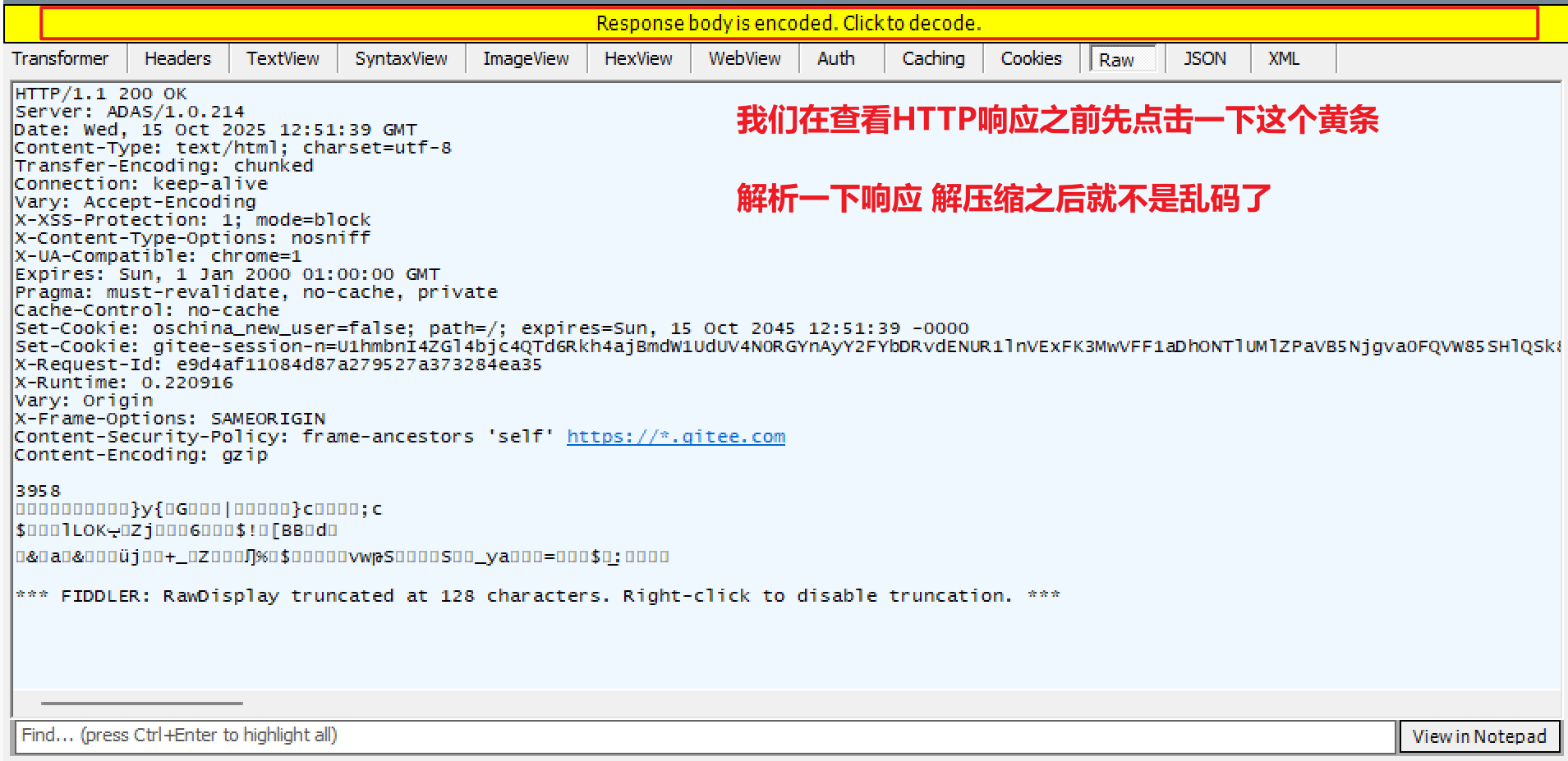
响应数据,经常是压缩后传输的,为了节省网络带宽
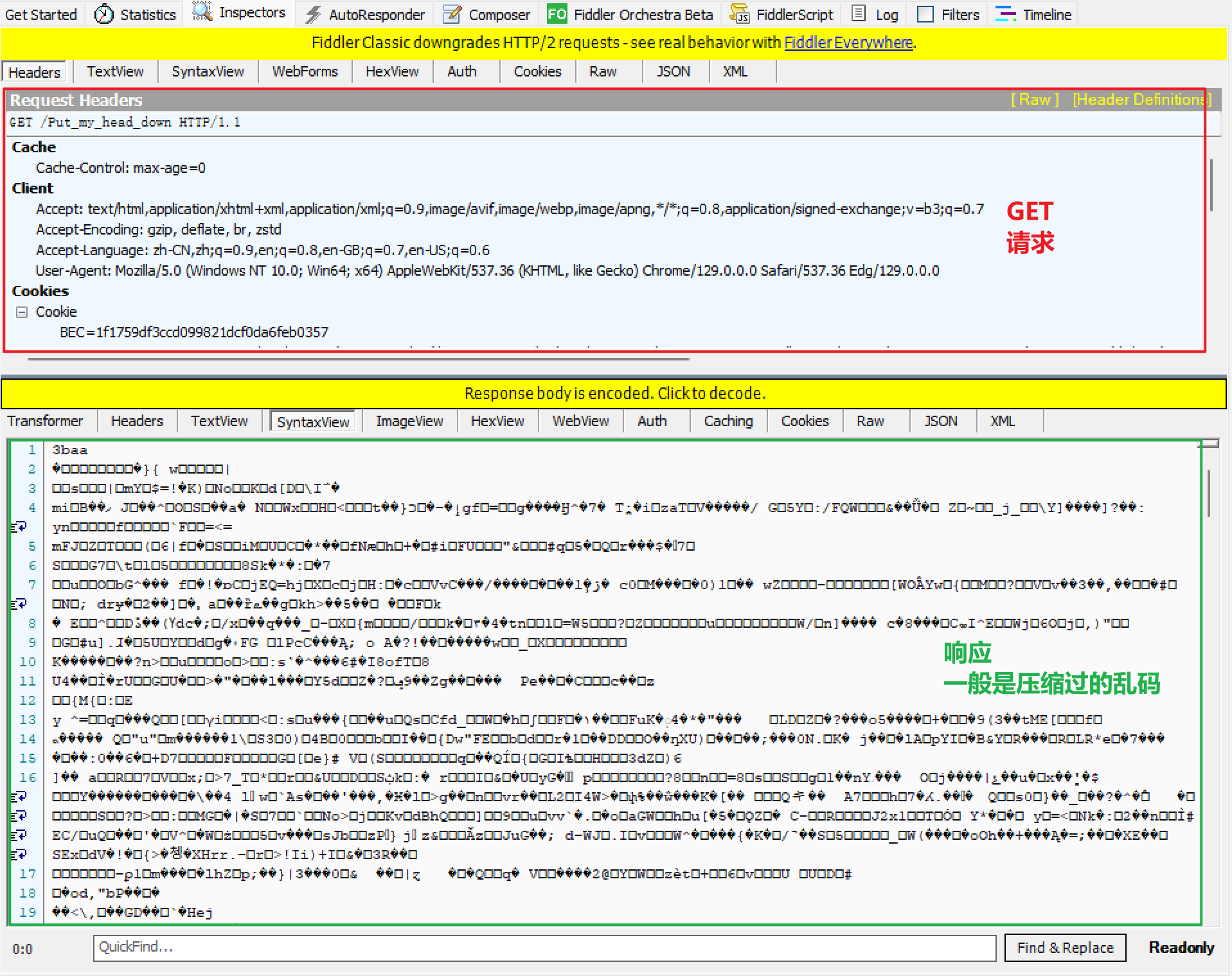
HTTP请求
1.首行 方法 URL 版本号
2.请求头 (键值对)
3.空行
4.正文(body)
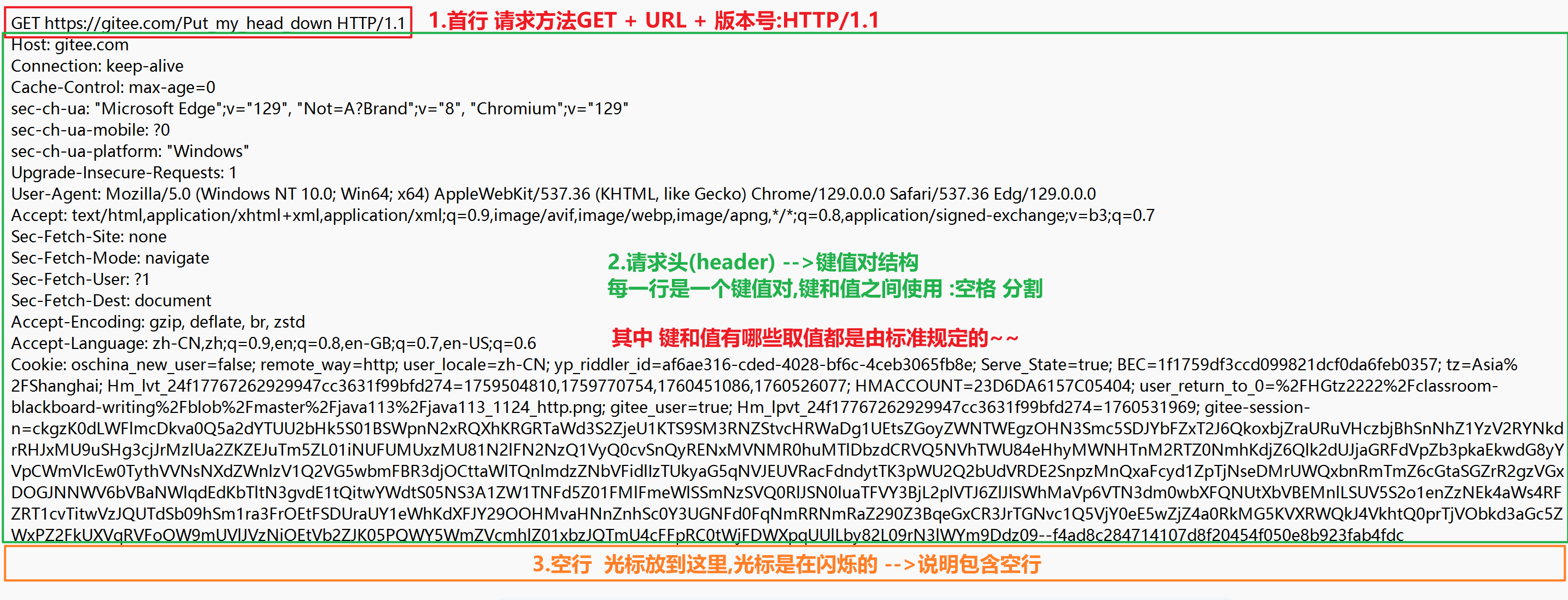
有些请求有正文,有些请求没有正文
HTTP响应
1.首行 版本号 状态码 状态码描述
2.响应头(键值对)
3.空行
4.正文

URL
学习MySQL时的JDBC编程创建DataSource有接触过URL
jdbc:mysql://127.0.0.1:3306/chaoxin?characterEncoding=utf8&useSSL=false
有的时候端口号没写,浏览器会自动添加默认的端口号
这是取决于协议是啥
http => 80
https => 443
注意,不要混淆,这里的端口是要访问的端口 => 目的端口

- 举个栗子🌰,来生动的理解URL的组成
https://陕科大餐厅:18/熏肉大饼/猪肉的熏肉大饼?葱=少放&香菜=不要&辣椒=微辣
我要去陕科大餐厅18号档口买少葱不要香菜微辣的猪肉熏肉大饼
urlencode
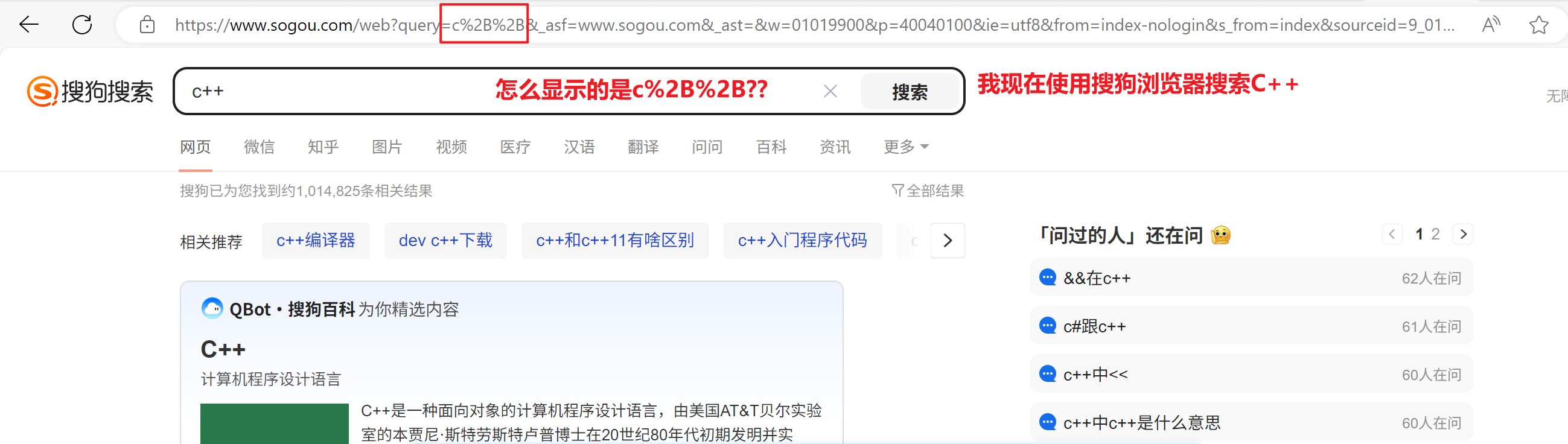
这就是urlencode转义 + 转义后为%2B
urlencode 把数据的二进制内容,每个字节取出来用十六进制表示,前面加上%
因为URL中本身就有一些特殊符号,代表不同的特殊含义
>转义操作,不仅仅是标点符号,对于中文等其他非英语的文字也需要转义,只不过很多浏览器为了用户看起来方便,显示的时候显示转移之前的,实际上抓包中就能看到是已经转义的数据
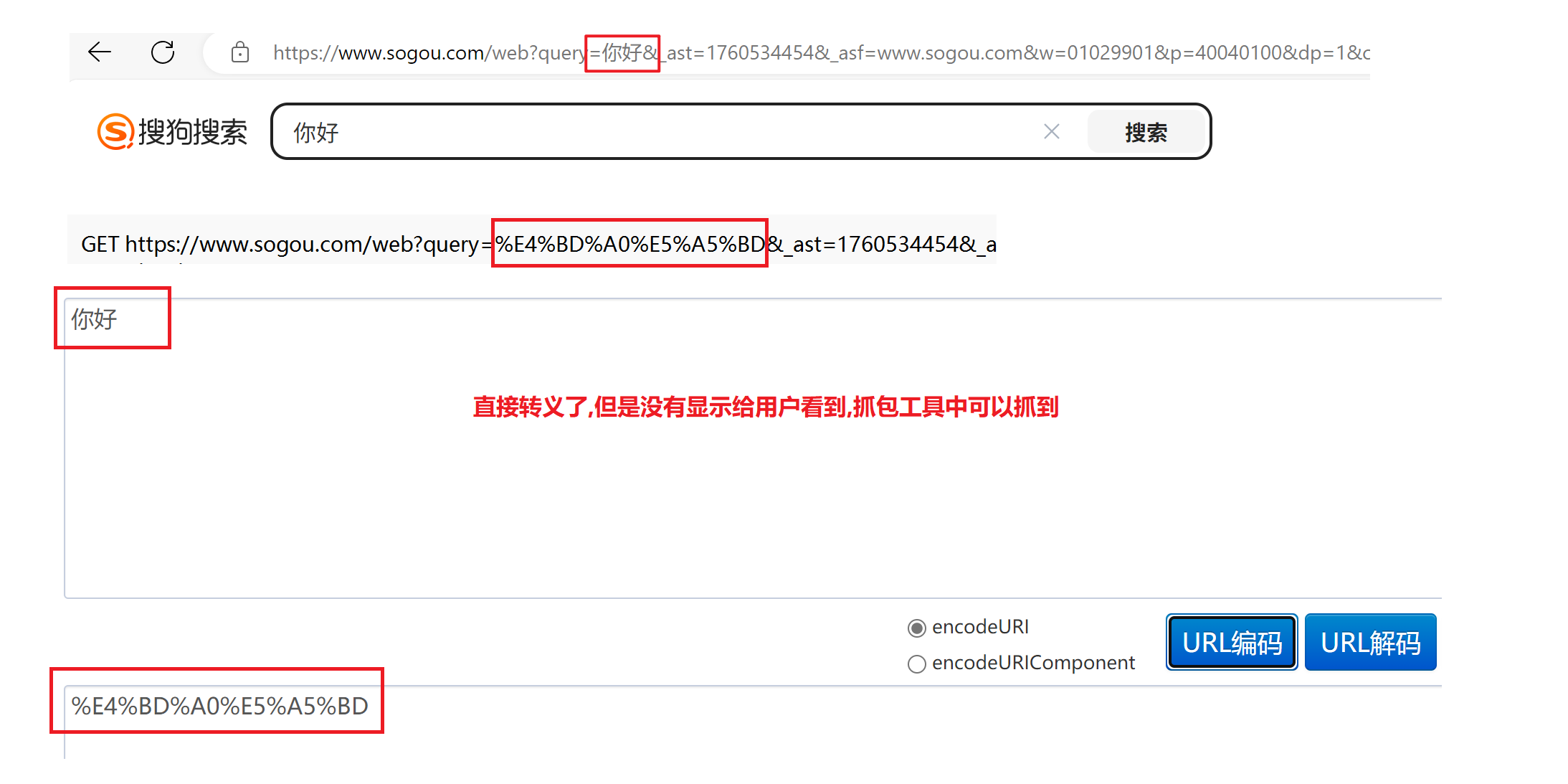
没有转义URL中非英语的文字,可能会导致请求失败
3.认识"方法"(method)
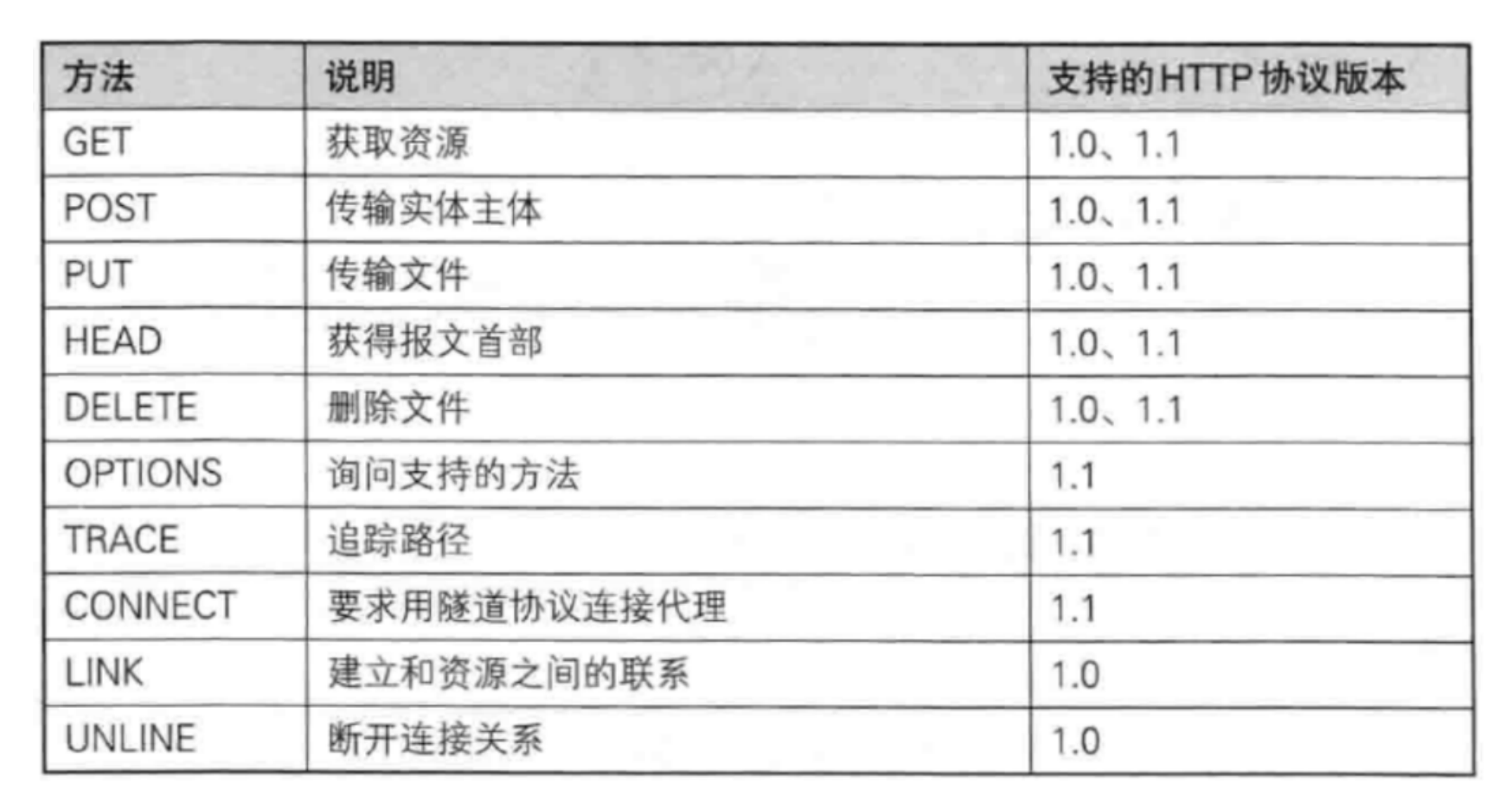
- GET–获取资源
- POST–传输实体主体
- PUT–传输文件
- DELETE–删除文件
其中GET和POST数字常见的请求
从语义上来说,两个方法有所区别,但是实际开发中不一定严格按照语义进行区分,实际上可以灵活掌控
这所有的方法有十斗,GET独占八斗,POST占一斗,剩下的方法共分一斗
- 典型的GET =>获取html,获取css,获取js等操作
- 典型的POST =>登录,上传文件
若我们在刷新页面时,ctrl+F5强制刷新 =>忽略本地缓存,所有资源都重新从服务器获取 —>抓包会一下子增多
浏览器的缓存机制 =>浏览器从服务器/通过网络加载页面的速度
CPU > 内存 > 硬盘 > 网络
浏览器为了加快访问速度,就会把网页依赖的一些静态资源(css,js,图片,字体,MP3…)缓存到硬盘上
第一次访问时,需要加载,后续访问不必重新加载
GET请求一般没有body,如果需要通过GET给服务器发送一些数据,通过Query String 传递过去~~
POST一般有body,
[经典面试题]GET和POST的区别
结论:GET和POST没有本质区别,经常是能够混用的,从使用方法习惯上来说主要是两个方面的区别~~ 语义上的区别 和 携带数据的方式
GET 和 POST的区别
1.语义上的区别 => 可以混着用
2.携带数据的方式
POST 也是可以携带有 Query String(很少见)
GET理论上也可以携带body (更少见)
3.GET 请求通常建议设计成幂等的 POST无要求
幂等只是HTTP标准文档给的建议,不是强制要求
幂等 =>请求一定的 ->得到的响应也还一定的,通常支付场景需要考虑幂等性
4.GET设计成幂等,就可以允许请求的结果被缓存
POST 由于不要求幂等,经常是不迷等的,救人位不能被缓存
实际上现在GET不幂等也是比较常见了,因为现在的互联网产品都讲究"个性化推荐"
关于 PUT DELETE 这两个方法,实现restful风格的api是会用到,EE进阶会提及,这里我们不多说
4.报头 header => 键值对结构
分成很多行,每一行是一个键值对
键和值之间使用 : 空格 分割
键/值的取值 =>在RFC标准文档中规定
Host =>表示服务武器主机的地址和端口
Host:gitee.com +端口号 就是一个 Host
ip地址(域名):端口号
绝大部分情况下,这俩属性也是一致~~
但是也是有一些特殊场景下是不一致的–> 使用代理
即使使用了代理,也可以通过Host来获取到最原始的目标是啥
比如HTTP协议中,传输的时候可能会涉及到加密HTTPS
URL部分都是明文传输,不会加密,被加密的是header和body
服务器收到请求之后就可以做一个最终校验,验证URL中的内容和header中加密的内容是否一致~~
Content-Length 和 Content-Type 可有可无 取决于是否有body,没有body就没有这两个属性
- Content-Length =>表示body 中的数据长度 单位:字节 => 提示从哪里到哪里是一个完整的http请求数据
请求头中的键值对,要把这一串字符串写入到TCP Socket中
对于基于TCP的应用层协议而言一个连接可以发多个请求
服务器这边收到数据的时候,就需要区分一下,从哪里到哪里是一个完整的http请求数据
对于没有body的请求,读到空行就可以认为结束了
对于有body的请求呢?
1.先读取首行和header,读到空行
2.解析header中的Content-Length,根据这里的值,接下来在读取固定字节的长度
我们前面写的TCP代码,next来读取(隐含了一个约束,使用空白符作为结束标记)
对于UDP来说就不用这样的两个属性
UDP面向数据报,读写基本单位就是一个UDP数据报
若某个应用层协议基于UDP,一个UDP数据报就对应一个完整的应用层数据包
调用一次receive操作,就得到一个明确的UDP的数据包
- Content-Type =>表示请求的body 中的数据格式 =>提示了接收方如何解析 body 中的数据

请求和相应,都会用到这两个header~~,如果有body,并且没有这俩属性(哪怕只有一个)都认为是非法的HTTP报文
要么俩属性都有,要么俩属性都无
User-Agent(简称UA)
用来表示用户设备的操作系统/浏览器的情况
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0

Referer 描述了当前页面来源
描述这个页面是从哪个页面跳转来的
如果直接在浏览器中输入URL/直接通过收藏夹访问页面是没有Referer的
搜狗页跳转到广告页的Referer:
Referer: https://www.sogou.com/web?query=%E5%AE%A2%E5%AE%B6%E7%B2%97%E5%8F%B6%E7%B2%84&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8
是否存在可能,有人把referer 给改了,比如本来是搜狗的referer改成了别人的
在大概十年前,这种情况非常普遍~~
这就是运营商劫持:通过软件,分析数据流量,把一些广告的HTTP数据进行修改
关于运营商劫持和报头的其他组成,我们在应用层协议(下)里面具体讲,敬请期待~~