快速掌握【Redis】Set:从基础命令到内部编码

目录
1.前言
插播一条消息~
2.1概念:Redis Set是什么?
2.2常见set七大命令
2.2.1sadd
2.2.2smembers
2.2.3sismember
2.2.4scard
2.2.5spop
2.2.6smove
2.2.7srem
2.3集合间操作:交集、并集、差集
2.3.1sinter(交集)
2.3.2sinterstore
2.3.3sunion(并集)
2.3.4sunionstore
2.3.5sdiff(差集)
2.3.6sdiffstore
2.4内部编码:intset和hashtable
2.5使用场景:从理论到实战
2.5.1标签系统:给内容“贴标签”
2.5.2计算共同好友:社交场景的“刚需”
3.小结
1.前言
哈喽大家好呀~。今天咱们来聊聊Redis中一个非常实用的数据结构——Set。如果你在开发中遇到过“需要存储不重复元素”“快速判断元素是否存在”“计算两个集合的交集”这类需求,那Redis Set绝对是你的不二之选。它就像一个“无序且不重复的口袋”,不仅能高效去重,还支持丰富的集合间操作,在社交、标签、推荐系统等场景中出镜率极高。话不多说,咱们直接开干!
插播一条消息~
🔍十年经验淬炼 · 系统化AI学习平台推荐
系统化学习AI平台![]() https://www.captainbed.cn/scy/
https://www.captainbed.cn/scy/
- 📚 完整知识体系:从数学基础 → 工业级项目(人脸识别/自动驾驶/GANs),内容由浅入深
- 💻 实战为王:每小节配套可运行代码案例(提供完整源码)
- 🎯 零基础友好:用生活案例讲解算法,无需担心数学/编程基础
🚀 特别适合
- 想系统补强AI知识的开发者
- 转型人工智能领域的从业者
- 需要项目经验的学生
2.1概念:Set是什么?
Redis Set(集合)是一个无序、元素唯一的字符串集合。它的核心特性可以用两个词概括:
- 无序性:元素没有固定顺序,不能通过索引访问(这点和Java的
HashSet类似); - 唯一性:集合中不会有重复元素,重复添加相同元素只会保留一个(相当于自带去重功能)。
和Redis其他数据结构的对比
为了让大家更清晰地理解Set的定位,咱们拿它和Redis的另外两个常用结构做个对比:
| 数据结构 | 有序性 | 元素唯一性 | 典型场景 |
|---|---|---|---|
| List | 有序(按插入顺序) | 可重复 | 消息队列、最新列表 |
| Set | 无序 | 唯一 | 去重、标签、共同好友 |
| Sorted Set | 有序(按分数排序) | 唯一 | 排行榜、带权重的集合 |
简单说,如果你需要“不重复”但不关心顺序,选Set;需要排序选Sorted Set;需要重复元素或顺序存储选List。
2.2常见set七大命令
Redis为Set提供了一系列直观易用的命令,咱们逐个拆解,每个命令都配上Redis CLI示例和Java代码(Jedis版),确保大家看完就能上手。
2.2.1sadd
作用:向集合中添加一个或多个元素,返回成功添加的元素个数(已存在的元素会被忽略)。
语法:sadd key member [member ...]
示例:
Redis CLI:
# 向set:fruits集合添加元素"apple"、"banana"、"orange"
127.0.0.1:6379> sadd set:fruits apple banana orange
(integer) 3 # 3个新元素添加成功# 再次添加"apple"(已存在)和"grape"(新元素)
127.0.0.1:6379> sadd set:fruits apple grape
(integer) 1 # 只有"grape"是新元素,返回1
注意:如果集合不存在,sadd会自动创建集合并添加元素。
2.2.2smembers
作用:返回集合中的所有元素(无序)。
语法:smembers key
示例:
Redis CLI:
# 查看set:fruits的所有元素
127.0.0.1:6379> smembers set:fruits
1) "banana"
2) "apple"
3) "orange"
4) "grape" # 注意:输出顺序可能和添加顺序不同(无序性)
注意:如果集合元素很多(比如百万级),smembers会一次性返回所有元素,可能阻塞Redis,建议用sscan分批遍历(后面场景部分会提到)。
2.2.3sismember
作用:判断元素是否是集合的成员,返回1(存在)或0(不存在)。
语法:sismember key member
示例:
Redis CLI:
# 判断"apple"是否在集合中
127.0.0.1:6379> sismember set:fruits apple
(integer) 1 # 存在# 判断"watermelon"是否在集合中
127.0.0.1:6379> sismember set:fruits watermelon
(integer) 0 # 不存在
使用场景:快速判断用户是否点赞、是否关注某个话题等(O(1)时间复杂度,非常高效)。
2.2.4scard
作用:返回集合中的元素个数( cardinality,基数)。
语法:scard key
示例:
Redis CLI:
# 获取set:fruits的元素个数
127.0.0.1:6379> scard set:fruits
(integer) 4 # 集合中有4个元素
2.2.5spop
作用:随机移除并返回集合中的一个元素(如果指定count参数,可返回多个)。
语法:spop key [count]
示例:
Redis CLI:
# 随机移除一个元素
127.0.0.1:6379> spop set:fruits
"orange" # 随机返回"orange",此时集合中已无"orange"# 随机移除2个元素
127.0.0.1:6379> spop set:fruits 2
1) "banana"
2) "grape" # 此时集合中只剩"apple"
使用场景:随机抽奖(从用户集合中随机选N个中奖者)、随机推荐(从内容集合中随机返回N条内容)。
2.2.6smove
作用:将元素从一个集合移动到另一个集合(原子操作,要么成功要么失败)。
语法:smove source destination member
示例:
Redis CLI:
# 创建目标集合set:basket
127.0.0.1:6379> sadd set:basket pear
(integer) 1# 将set:fruits中的"apple"移动到set:basket
127.0.0.1:6379> smove set:fruits set:basket apple
(integer) 1 # 移动成功# 查看原集合(已无"apple")
127.0.0.1:6379> smembers set:fruits
(empty list or set)# 查看目标集合(新增"apple")
127.0.0.1:6379> smembers set:basket
1) "pear"
2) "apple"
注意:如果源集合中没有该元素,或目标集合中已存在,返回0(移动失败)。
2.2.7srem
作用:移除集合中的一个或多个元素,返回成功移除的元素个数(不存在的元素忽略)。
语法:srem key member [member ...]
示例:
Redis CLI:
# 从set:basket中移除"pear"和"apple"
127.0.0.1:6379> srem set:basket pear apple
(integer) 2 # 移除2个元素# 移除不存在的元素
127.0.0.1:6379> srem set:basket watermelon
(integer) 0 # 移除失败
2.3集合间操作:交集、并集、差集
Redis Set最强大的功能之一,就是支持多个集合间的交集、并集、差集操作。这些操作在社交(共同好友)、推荐(相似用户)等场景中非常实用。咱们用“好友关系”举例,直观理解这三种操作:
- 交集(sinter):A和B共同拥有的好友(你的好友且是我的好友);
- 并集(sunion):A和B的所有好友(你的好友或我的好友,去重);
- 差集(sdiff):A有但B没有的好友(你的好友中不是我的好友)。
2.3.1sinter(交集)
作用:返回多个集合的交集元素(同时存在于所有集合中的元素)。
语法:sinter key [key ...]
示例:
假设:
user:1:friends(用户1的好友):{2, 3, 4}user:2:friends(用户2的好友):{1, 3, 5}
交集就是共同好友:{3}
Redis CLI:
# 添加用户1的好友
127.0.0.1:6379> sadd user:1:friends 2 3 4
(integer) 3# 添加用户2的好友
127.0.0.1:6379> sadd user:2:friends 1 3 5
(integer) 3# 计算共同好友(交集)
127.0.0.1:6379> sinter user:1:friends user:2:friends
1) "3" # 共同好友是3
2.3.2sinterstore
作用:计算多个集合的交集,并将结果存储到新集合中(不会改变原集合)。
语法:sinterstore destination key [key ...]
示例:
Redis CLI:
# 将user:1和user:2的共同好友存储到user:1:2:common_friends
127.0.0.1:6379> sinterstore user:1:2:common_friends user:1:friends user:2:friends
(integer) 1 # 交集元素个数为1# 查看存储结果
127.0.0.1:6379> smembers user:1:2:common_friends
1) "3"
2.3.3sunion(并集)
作用:返回多个集合的并集元素(存在于任意一个集合中的元素,去重)。
语法:sunion key [key ...]
示例:
用上面的用户好友数据,user:1和user:2的并集好友是{1, 2, 3, 4, 5}
Redis CLI:
127.0.0.1:6379> sunion user:1:friends user:2:friends
1) "1"
2) "2"
3) "3"
4) "4"
5) "5" # 所有好友去重合并
2.3.4sunionstore
作用:计算多个集合的并集,并将结果存储到新集合中。
语法:sunionstore destination key [key ...]
示例:
Redis CLI:
# 存储并集结果到user:1:2:all_friends
127.0.0.1:6379> sunionstore user:1:2:all_friends user:1:friends user:2:friends
(integer) 5 # 并集元素个数为5# 查看结果
127.0.0.1:6379> smembers user:1:2:all_friends
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
2.3.5sdiff(差集)
作用:返回第一个集合与其他集合的差集(存在于第一个集合,但不存在于其他集合的元素)。
语法:sdiff key [key ...]
示例:
用上面的用户好友数据,user:1的好友中不是user:2好友的是{2, 4}
Redis CLI:
127.0.0.1:6379> sdiff user:1:friends user:2:friends
1) "2"
2) "4" # user:1有但user:2没有的好友
2.3.6sdiffstore
作用:计算差集并存储到新集合中。
语法:sdiffstore destination key [key ...]
示例:
Redis CLI:
# 存储差集结果到user:1:2:diff_friends
127.0.0.1:6379> sdiffstore user:1:2:diff_friends user:1:friends user:2:friends
(integer) 2 # 差集元素个数为2# 查看结果
127.0.0.1:6379> smembers user:1:2:diff_friends
1) "2"
2) "4"
2.4内部编码:intset和hashtable
Redis Set的内部实现有两种编码方式,会根据集合元素的特点自动切换,目的是优化内存占用和性能。
两种编码的对比
| 编码方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| intset(整数集合) | 1. 所有元素都是整数(int64范围内) 2. 元素个数≤set-max-intset-entries(默认512) | 1. 内存占用极低(连续内存存储,无哈希表开销) 2. 查找、添加、删除效率高(二分查找,时间复杂度O(log n)) | 1. 只支持整数元素 2. 元素超过512个或添加非整数元素时,会自动转为hashtable |
| hashtable(哈希表) | 1. 存在非整数元素 2. 元素个数>512个 | 1. 支持任意字符串元素 2. 不受元素个数限制(只要内存够) | 1. 内存占用高(哈希表有指针、哈希冲突等开销) 2. 查找效率O(1)但常数时间比intset大 |
编码转换示例
# 1. 添加整数元素,个数≤512 → intset编码
127.0.0.1:6379> sadd set:int 1 2 3
(integer) 3
127.0.0.1:6379> object encoding set:int
"intset" # 当前编码是intset# 2. 添加非整数元素 → 转为hashtable
127.0.0.1:6379> sadd set:int "a"
(integer) 1
127.0.0.1:6379> object encoding set:int
"hashtable" # 编码已切换# 3. 重新创建集合,添加513个整数 → 转为hashtable
127.0.0.1:6379> del set:bigint
(integer) 1
127.0.0.1:6379> eval "for i=1,513 do redis.call('sadd', KEYS[1], i) end" 1 set:bigint
(nil)
127.0.0.1:6379> object encoding set:bigint
"hashtable" # 元素个数>512,编码为hashtable
注意:编码转换是单向的(intset→hashtable),一旦转为hashtable,即使删除元素让个数≤512或全是整数,也不会转回intset。
2.5使用场景:从理论到实战
Redis Set的特性(无序、唯一、集合操作)使其在很多场景中大放异彩,咱们结合代码和架构聊聊最常用的两个场景。
2.5.1标签系统:给内容“贴标签”
场景描述:一篇文章、一个商品可能有多个标签(如“Java”“Redis”“后端”),用户可以通过标签快速筛选内容。用Set存储标签的优势:
- 天然去重(同一内容不会重复打同一个标签);
- 支持“标签A且标签B”(交集)、“标签A或标签B”(并集)的内容筛选。
实现方案:
-
存储内容与标签的映射:
tag:content:{contentId}→ 存储内容contentId的所有标签(Set);tag:{tagName}:contents→ 存储标签tagName对应的所有内容ID(Set)。
- 添加标签:
发布一篇文章(ID=1001),标签为“Java”“Redis”“后端”:String contentId = "1001"; String[] tags = {"Java", "Redis", "后端"};// 1. 内容→标签(记录这篇文章有哪些标签) jedis.sadd("tag:content:" + contentId, tags);// 2. 标签→内容(记录每个标签下有哪些文章) for (String tag : tags) {jedis.sadd("tag:" + tag + ":contents", contentId); } -
筛选内容:
- 筛选“Java且Redis”的文章(交集):
Set<String> contentIds = jedis.sinter("tag:Java:contents", "tag:Redis:contents"); System.out.println("同时包含Java和Redis的文章:" + contentIds); - 筛选“Java或后端”的文章(并集):
Set<String> contentIds = jedis.sunion("tag:Java:contents", "tag:后端:contents");
- 筛选“Java且Redis”的文章(交集):
-
注意事项:
- 如果标签下的内容很多(如百万级),
sinter/sunion可能耗时,建议用SINTERSTORE将结果缓存到新集合,定期更新; - 遍历标签下的内容时,用
sscan代替smembers(避免阻塞Redis):// 用sscan分批获取标签下的内容ID(每次10个) ScanParams params = new ScanParams().count(10); String cursor = "0"; do {ScanResult<String> result = jedis.sscan("tag:Java:contents", cursor, params);List<String> ids = result.getResult();System.out.println("分批获取的内容ID:" + ids);cursor = result.getStringCursor(); } while (!cursor.equals("0"));
- 如果标签下的内容很多(如百万级),
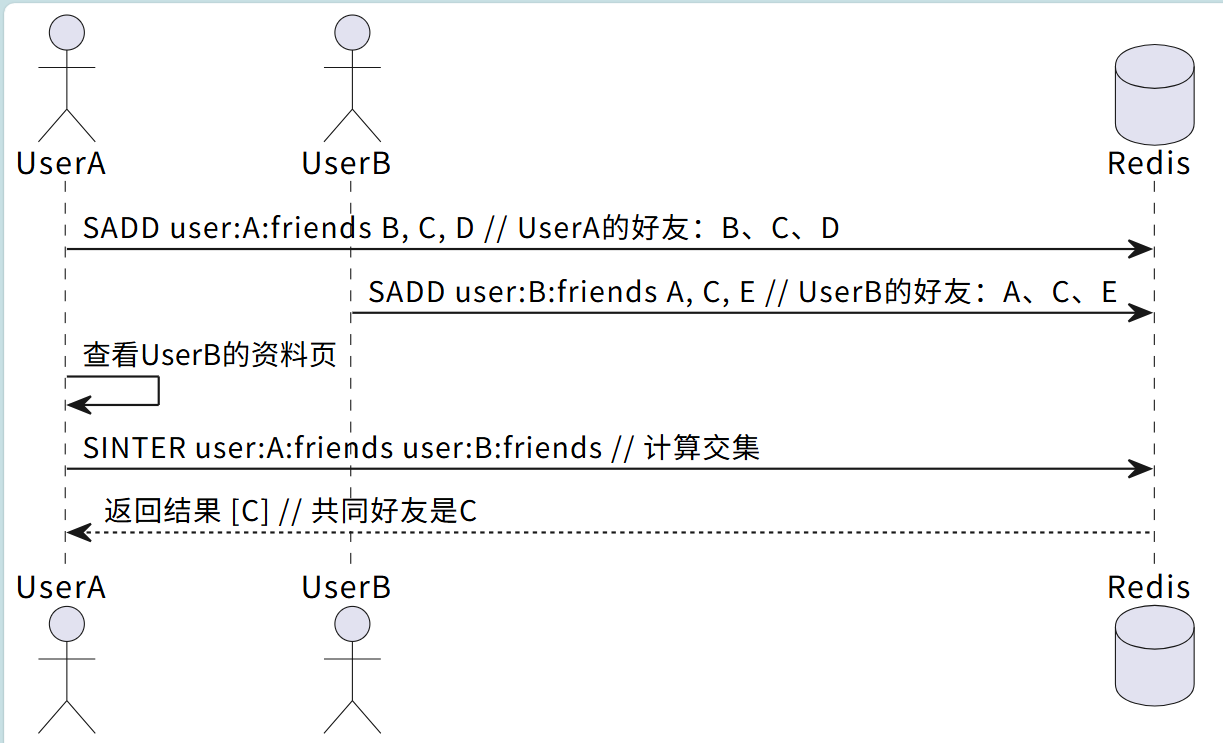
2.5.2计算共同好友:社交场景的“刚需”
场景描述:社交APP中“共同好友”功能(如微信的“共同好友”、微博的“你可能认识的人”),本质就是计算两个用户好友集合的交集。
实现方案:
- 存储用户好友关系:
user:{userId}:friends→ 存储用户userId的所有好友ID(Set)。 - 计算共同好友:
直接用sinter命令计算两个用户好友集合的交集。
UML时序图(共同好友计算流程):
优化点:
- 缓存交集结果:如果两个用户经常互查共同好友,用
sinterstore将结果缓存到user:{A}:{B}:common_friends,定期更新(如每天凌晨); - 处理大数据量:如果用户好友数很多(如明星账号千万级好友),直接
sinter会很慢,可采用“分桶存储”(将好友ID哈希到多个小集合,分别计算交集再合并)。
3.小结
Redis Set是一个无序、唯一的字符串集合,核心优势在于:
- 高效去重:天然支持元素唯一性,添加重复元素自动忽略;
- 快速判断:
sismember命令O(1)时间复杂度判断元素是否存在; - 强大的集合操作:支持交集、并集、差集,轻松实现共同好友、标签筛选等场景;
- 内存优化:根据元素特点自动切换intset/hashtable编码,平衡性能和内存占用。
使用建议:
- 存储小数据量集合(≤512个整数)时,利用intset编码节省内存;
- 避免用
smembers遍历大数据量集合,改用sscan分批获取; - 集合间操作(如
sinter)结果可缓存,减少重复计算; - 随机推荐、抽奖场景优先用
spop或srandmember(随机返回元素但不移除)。
希望本文能帮大家搞懂Redis Set的用法和原理,实际开发中多结合场景选择合适的命令,让Redis成为你的性能利器!如果有疑问或补充,欢迎在评论区留言~