图解KV Cache:解锁LLM推理效率的关键
背景
LLM 用于推理的时候就是不断基于前面的所有 token 生成下一个 token。
假设现在已经生成了 t t t 个 token,用 x 1 : t x_{1:t} x1:t 表示。在下一轮,LLM 会生成 x t + 1 x_{t+1} xt+1,注意他们的前 t t t 个 token 是一样的:
x t + 1 = LLM ( x 1 : t ) x_{t+1} = \text{LLM}(x_{1:t}) xt+1=LLM(x1:t)
再下一步也是相似的:
x t + 2 = LLM ( x 1 : t + 1 ) x_{t+2} = \text{LLM}(x_{1:t+1}) xt+2=LLM(x1:t+1)
概括来说,每一轮用上一轮的输出当作新的输入让 LLM 预测,一般这个过程会持续到输出达到提前设定的最大长度或者 LLM 自己生成了特殊的结束 token。
KV Cache 原理
💡 信息
LLM 的推理过程很好理解,但是这个简单的实现存在一个问题——存在不少的重复计算导致计算效率不是很高 🫠
只需要看 LLM 的连续两次前向传播推理计算就很容易理解为什么说存在重复计算了。
比如考虑下面这一步:
x t + 1 = LLM ( x 1 : t ) x_{t+1} = \text{LLM}(x_{1:t}) xt+1=LLM(x1:t)
LLM 的输入是 x 1 : t x_{1:t} x1:t,先来看最后一个 token x t x_t xt,它的 query 方向量会和前面的每个 token 以及自己产生的 key 方向量计算:
q t T k 1 , q t T k 2 , … , q t T k t q_t^T k_1, q_t^T k_2, \dots, q_t^T k_t qtTk1,qtTk2,…,qtTkt
然后看后一步:
x t + 2 = LLM ( x 1 : t + 1 ) x_{t+2} = \text{LLM}(x_{1:t+1}) xt+2=LLM(x1:t+1)
LLM 的输入是 x 1 : t + 1 x_{1:t+1} x1:t+1,看最后一个 token x t + 1 x_{t+1} xt+1,它的 query 方向量会和前面的每个 token 以及自己产生的 key 方向量计算:
q t + 1 T k 1 , q t + 1 T k 2 , … , q t + 1 T k t , q t + 1 T k t + 1 q_{t+1}^T k_1, q_{t+1}^T k_2, \dots, q_{t+1}^T k_t, q_{t+1}^T k_{t+1} qt+1Tk1,qt+1Tk2,…,qt+1Tkt,qt+1Tkt+1
此时考虑 x t x_t xt 的前一个 token x t − 1 x_{t-1} xt−1,它也要参与这次的计算:
q t − 1 T k 1 , q t − 1 T k 2 , … , q t − 1 T k t q_{t-1}^T k_1, q_{t-1}^T k_2, \dots, q_{t-1}^T k_t qt−1Tk1,qt−1Tk2,…,qt−1Tkt
可以看到,这个计算完全和上一轮的计算重复,对于在 x t x_t xt 之前的 token 也是这个问题。我们需要重新计算 x t x_t xt 的所有 key 方向量和 value 方向量,而这些值的值其实是不会变的 🫠。
图解KV Cache
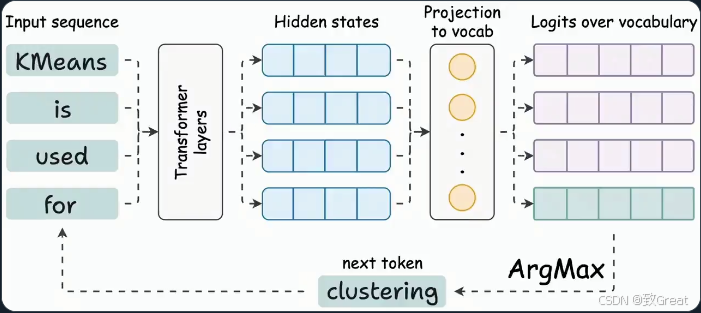
LLM中下一个token预测
- Transformer 生成隐藏状态
- Transformer 为所有 token 生成隐藏状态。
- 隐藏状态被投射到词汇空间。
- 最后一个 token 的 logits 用于生成下一个 token。
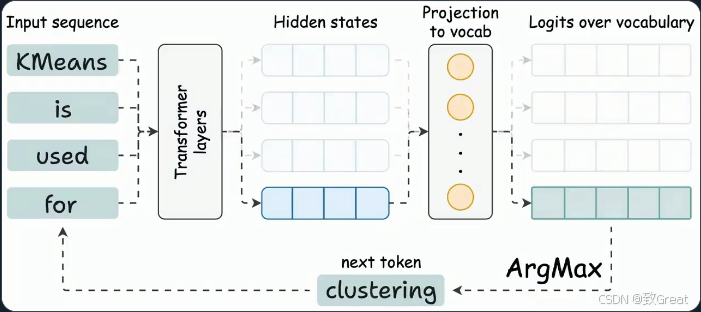
- 生成新 token 的输出
- 要生成新 token,我们只需要最新 token 的隐藏状态。
- 其他隐藏状态不需要重新计算。
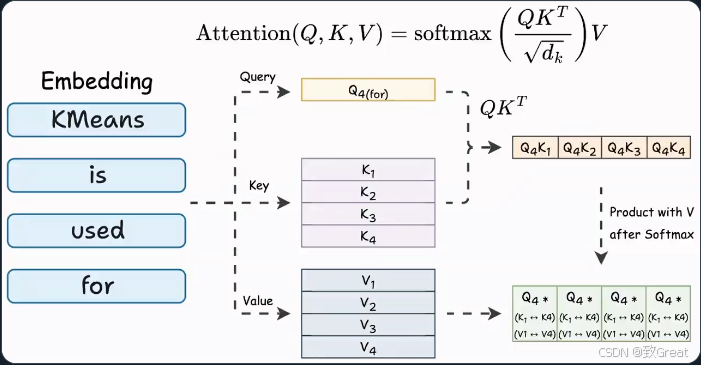
注意力机制中的计算
在注意力阶段(Softmax计算):
- Query-Key-Value的最后一列计算涉及:
- 最后一个查询向量。
- 所有Key向量。
此外:
- 最终注意力结果的最后一行涉及:
- 最后一个Query向量。
- 所有Key和Value向量。
我们可以发现
要生成新 token,网络中的每个注意操作只需要:
- 最后一个Token的Query向量。
- 所有Key和Value向量。
KV 缓存的核心思想
当我们生成新 token 时:
- 用于所有先前 token 的 KV 向量不会改变。
- 因此,我们只需要为前一步生成的 token 生成一个 KV 向量。
- 其余的 KV 向量可以从缓存中检索,节省计算和时间。
这称为 KV 缓存!
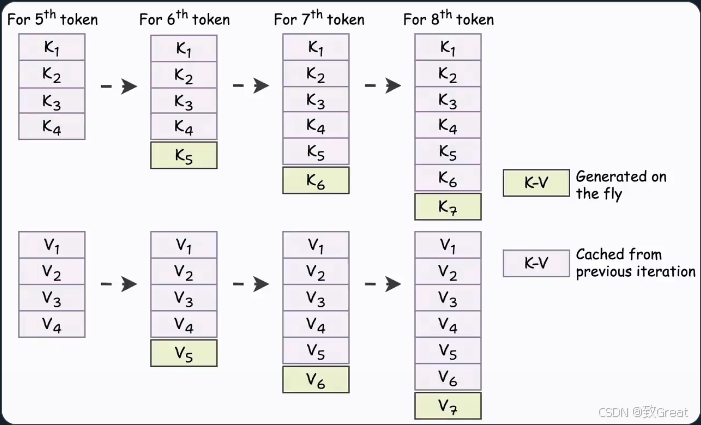
具体工作流程如下:
- 为前一步生成的标记生成 QKV 向量。
- 从缓存中获取所有其他 KV 向量。
- 计算注意力。
尽管 KV 缓存加速了推理,但它也占用了大量内存。例如:
- Llama3-70B 参数下:
- 总层数 = 80
- 隐藏大小 = 8k
- 最大输出大小 = 4k
- 每个Token在 KV 缓存中占用约 2.5 MB。
- 4k 个Token将占用 10.5 GB。
简单来说,用了KV Cache可以支持更多用户,提高效率 →但是同时也会占用更多内存,以空间换时间。
整体动态图如下:

总结
在Transformer架构中,KV Cache是一种关键的性能优化机制。它通过缓存已计算的Key和Value矩阵,避免在自回归生成过程中重复计算,从而显著提升推理效率。这种机制类似于人类思维中的短期记忆系统,使模型能够高效地利用历史信息。
KV Cache 作为 Transformer 架构中的关键性能优化机制,通过巧妙的缓存设计显著提升了模型的推理效率。其工作原理主要体现在三个核心维度:
-
首先,在计算效率方面,KV Cache通过缓存已处理token的Key和Value表示,有效消除了重复计算的开销。这种机制使得模型在自回归生成过程中能够实现2-3倍的速度提升,显著降低了计算资源的浪费,为大规模应用部署提供了可能。
-
其次,在上下文处理能力上,KV Cache通过维持完整的长序列表示,确保了模型对上下文的准确理解。这种机制增强了注意力机制的效果,使模型能够精确检索历史信息,从而保证了长文本生成时的语义连贯性和质量稳定性。
-
最后,在动态特性方面,KV Cache展现出优秀的自适应能力。系统能够根据输入序列的长度动态调整缓存大小,灵活应对不同场景的需求,尤其适合实时交互式对话等动态应用场景。
KV 缓存是加速 LLM 推理的关键技术之一。通过减少重复计算,它显著提升了生成速度,但也带来了内存占用的挑战。理解其工作原理有助于更好地优化和部署大语言模型。
参考资料
- LLM 推理加速 - KV Cache
- LLM 推理优化探微 (2) :Transformer 模型 KV 缓存技术详解
- 【大模型LLM基础】自回归推理生成的原理以及什么是KV Cache?
- LLM(二十):漫谈 KV Cache 优化方法,深度理解 StreamingLLM
- ThreadReaderApp 展开链接
- [LLM]KV cache详解 图示,显存,计算量分析,代码
- KV Cache量化技术详解:深入理解LLM推理性能优化