Web 开发 29
1 第三方登录(以Google为例子)
将 Google 登录功能集成到您的 Web 应用中 | Web guides | Google for Developers![]() https://developers.google.com/identity/sign-in/web/sign-in?hl=zh-cn#add_a_google_sign-in_button
https://developers.google.com/identity/sign-in/web/sign-in?hl=zh-cn#add_a_google_sign-in_button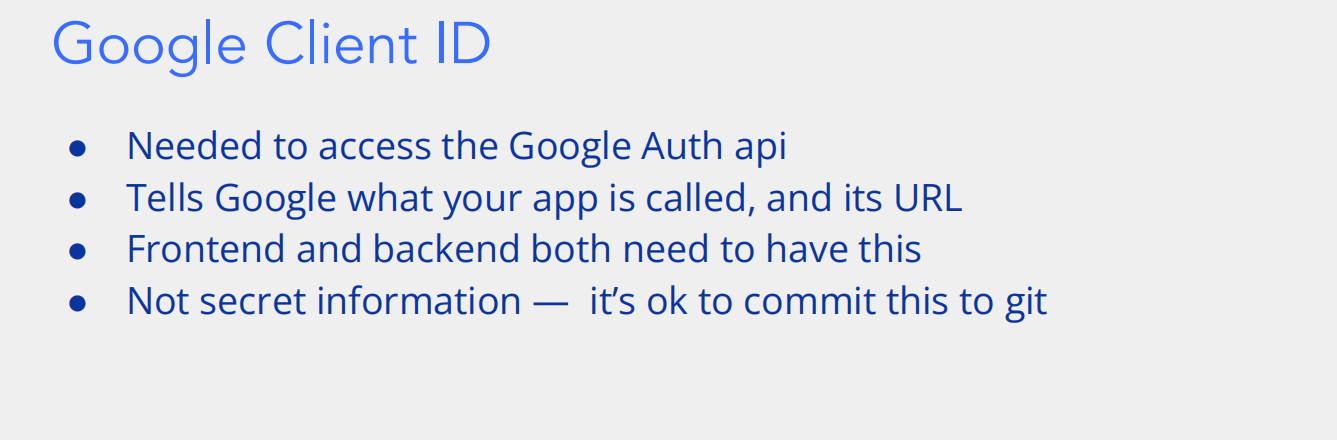
详细解释
- Needed to access the Google Auth api:Google Client ID 是访问 Google 身份验证 API(Google Auth API)的必需凭证。Google 身份验证 API 提供了用户身份验证相关的功能,比如让用户使用 Google 账号登录第三方应用等。只有通过有效的 Client ID,应用才能与该 API 进行交互,获取身份验证服务。
- Tells Google what your app is called, and its URL:它向 Google 表明你的应用程序的名称以及其对应的 URL。这有助于 Google 识别发起请求的应用,确保请求来自合法且已注册的应用,同时也能在身份验证流程中,正确地将用户重定向回应用的指定 URL 等操作。
- Frontend and backend both need to have this:在应用的前后端分离架构中,前端(比如网页的前端界面、移动应用的前端部分)和后端(处理业务逻辑、与数据库交互等的服务端)都需要使用 Google Client ID。前端可能用它来发起客户端的身份验证请求,而后端可能用它来验证从前端或 Google 那边传来的身份验证相关信息等,以协同完成整个身份验证流程。
- Not secret information — it’s ok to commit this to git:Google Client ID 不是机密信息。与一些需要严格保密的密钥(如客户端密钥等)不同,它可以安全地提交到代码版本控制系统(如 Git)中,不用担心因为公开该 ID 而导致安全风险,方便团队协作开发时共享和使用。
扩展
在实际的应用开发中,当集成 Google 身份验证功能时,开发者首先需要在 Google 开发者控制台中创建项目,然后为项目配置 OAuth 2.0 客户端,此时会生成 Google Client ID(以及客户端密钥,客户端密钥是需要保密的)。
有了 Client ID 后,应用的前后端就可以基于此来实现 “使用 Google 账号登录” 等功能。
例如,前端页面可以嵌入 Google 登录按钮,点击后通过 Client ID 向 Google 发起登录请求,用户授权后,Google 会返回相关的身份信息,前端或后端再利用这些信息来确认用户身份,进而为用户提供相应的服务。(第三方登录)
由于 Client ID 不涉及敏感的安全信息,所以在团队协作开发时,将其纳入代码仓库(如 Git 仓库)进行版本管理是很常见且安全的做法,不会引发信息泄露等问题。
2 登录登出的路由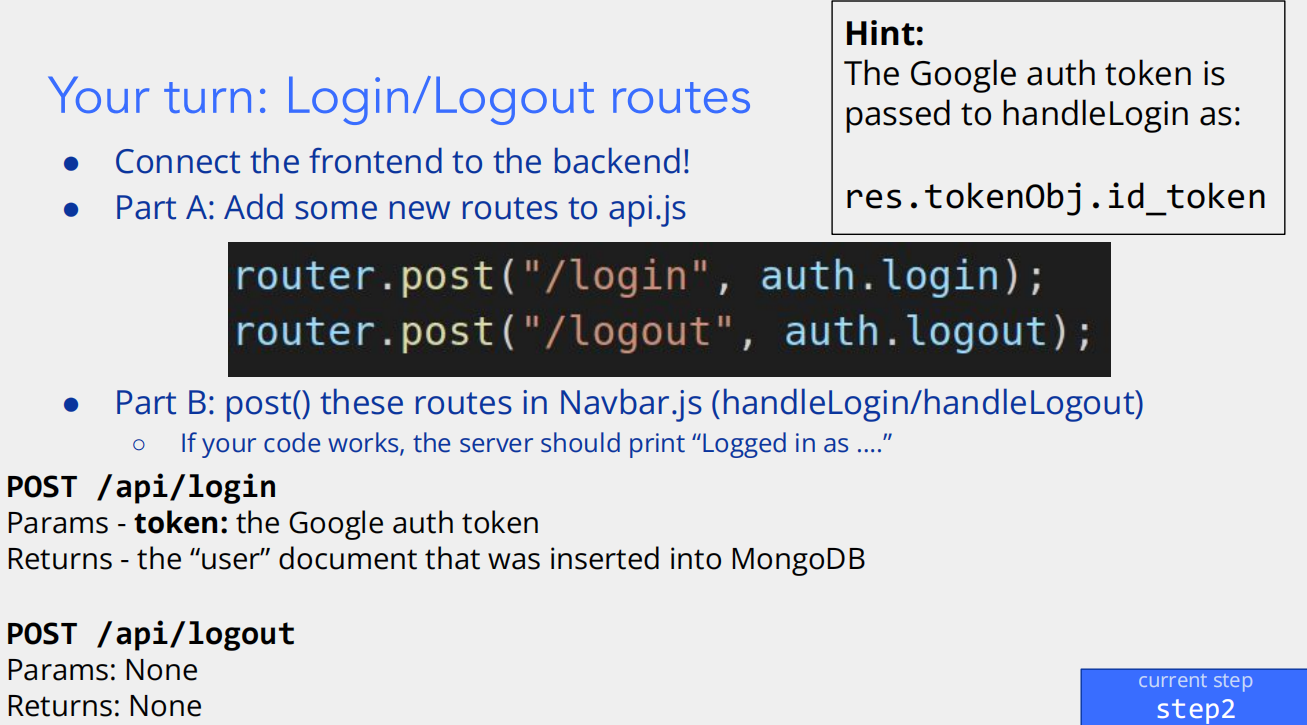
核心内容解释
这部分是在指导你实现前端和后端之间关于用户登录(Login)和登出(Logout)的交互逻辑。
- Part A: 在 api.js 中添加新路由
- 代码
router.post("/login", auth.login);和router.post("/logout", auth.logout);是用后端框架(比如 Express.js)来定义路由。router.post表示这是一个处理 POST 请求的路由,"/login"和"/logout"是路由的路径,auth.login和auth.logout是对应的处理函数,当前端向这两个路径发送 POST 请求时,就会执行这些函数来处理登录和登出逻辑。
- 代码
- Part B: 在 Navbar.js 中发送这些路由的 POST 请求
- 在
Navbar.js里的handleLogin和handleLogout函数中,需要用前端的请求方式(比如fetch或者axios)向刚才在api.js中定义的/login和/logout路由发送 POST 请求。如果代码没问题,服务器会打印出 “Logged in as....” 这样的信息,用来提示登录成功以及登录的用户相关信息。
- 在
- POST /api/login
- 这个接口是处理用户登录的 POST 请求,参数是
token,也就是 Google 授权令牌(由提示里的res.tokenObj.id_token传递过来)。当调用这个接口时,后端会利用这个令牌进行验证,然后把对应的用户文档插入到 MongoDB 数据库中,并且返回插入的 “user” 文档。
- 这个接口是处理用户登录的 POST 请求,参数是
- POST /api/logout
- 这个接口处理用户登出的 POST 请求,没有参数,调用后也没有返回值,主要作用是清除用户的登录状态等相关操作。
更深入详细的讲解和扩展
后端部分(以 Express.js + MongoDB 为例)
- 路由处理函数(auth.login 和 auth.logout)
auth.login函数:首先要从请求中获取到 Google 授权令牌(通常在请求体req.body.token中)。然后,可能需要调用 Google 的验证服务(比如使用google-auth-library)来验证这个令牌的有效性。验证通过后,会获取到用户的唯一标识(比如 Google 账号的 ID)等信息。接着,去 MongoDB 中查询是否已有该用户的记录,如果没有,就创建一个新的用户文档并插入到数据库中;如果有,就获取已有的用户信息。最后,可能会生成一个会话(Session)或者令牌(Token,比如 JWT)来维护用户的登录状态,并将用户文档返回给前端。auth.logout函数:主要是清除用户的会话或者使令牌失效。如果使用的是 Session 机制,就销毁对应的 Session;如果是 JWT,就可以设置令牌的过期时间或者在前端清除令牌。这样,用户再次访问需要登录的资源时,就会被要求重新登录。
- 数据库操作(MongoDB)
- 对于用户数据的存储,需要定义一个用户模型(Schema)。比如,使用
mongoose库的话,可以定义一个UserSchema,包含用户的 Google ID、姓名、邮箱等字段。当处理登录逻辑时,根据 Google ID 来进行查询和插入操作。这样可以保证每个 Google 用户在系统中有唯一的记录。
- 对于用户数据的存储,需要定义一个用户模型(Schema)。比如,使用
前端部分(以 React 为例)
- 发送请求(fetch 或 axios)
- 在
handleLogin函数中:当用户通过 Google 登录成功后,会获取到 Google 授权令牌。然后使用fetch或者axios向/api/login发送 POST 请求,将令牌作为请求体的数据发送给后端。例如:const handleLogin = async (googleToken) => {try {const response = await fetch("/api/login", {method: "POST",headers: {"Content-Type": "application/json",},body: JSON.stringify({ token: googleToken }),});const data = await response.json();// 处理返回的用户数据,比如存储到状态管理中} catch (error) {console.error("Login error:", error);} }; - 在
handleLogout函数中:向/api/logout发送 POST 请求,通知后端清除登录状态。例如:const handleLogout = async () => {try {await fetch("/api/logout", {method: "POST",headers: {"Content-Type": "application/json",},});// 清除前端的登录状态,比如从状态管理中移除用户信息} catch (error) {console.error("Logout error:", error);} };
- 在
- 状态管理
- 当登录成功后,后端返回用户文档,前端需要将用户信息存储起来,方便在整个应用中使用。可以使用 React 的
useState结合上下文(Context)或者专门的状态管理库(如 Redux、MobX)来管理用户的登录状态和用户信息。这样,在导航栏(Navbar)或者其他组件中,就可以根据用户是否登录来显示不同的内容(比如登录按钮或用户信息)。
- 当登录成功后,后端返回用户文档,前端需要将用户信息存储起来,方便在整个应用中使用。可以使用 React 的
认证与授权的扩展
- JWT(JSON Web Token)
- 除了 Session 机制,还可以使用 JWT 来进行身份验证。在登录成功后,后端生成一个包含用户信息的 JWT 令牌,返回给前端。前端在后续的请求中,将这个令牌放在请求头(
Authorization头)中发送给后端。后端通过验证 JWT 令牌的有效性来确定用户的身份,这样可以实现无状态的认证,适合分布式系统。
- 除了 Session 机制,还可以使用 JWT 来进行身份验证。在登录成功后,后端生成一个包含用户信息的 JWT 令牌,返回给前端。前端在后续的请求中,将这个令牌放在请求头(
- 权限控制
- 在实际应用中,不同的用户可能有不同的权限。比如,管理员可以访问某些特殊的接口,而普通用户不能。这时候,就需要在后端对接口进行权限控制。可以在用户模型中添加
role字段(如admin、user),然后在路由处理函数中,根据用户的role来判断是否允许访问该接口。
- 在实际应用中,不同的用户可能有不同的权限。比如,管理员可以访问某些特殊的接口,而普通用户不能。这时候,就需要在后端对接口进行权限控制。可以在用户模型中添加
3 基于 Google 认证的用户登录流程
核心流程解释
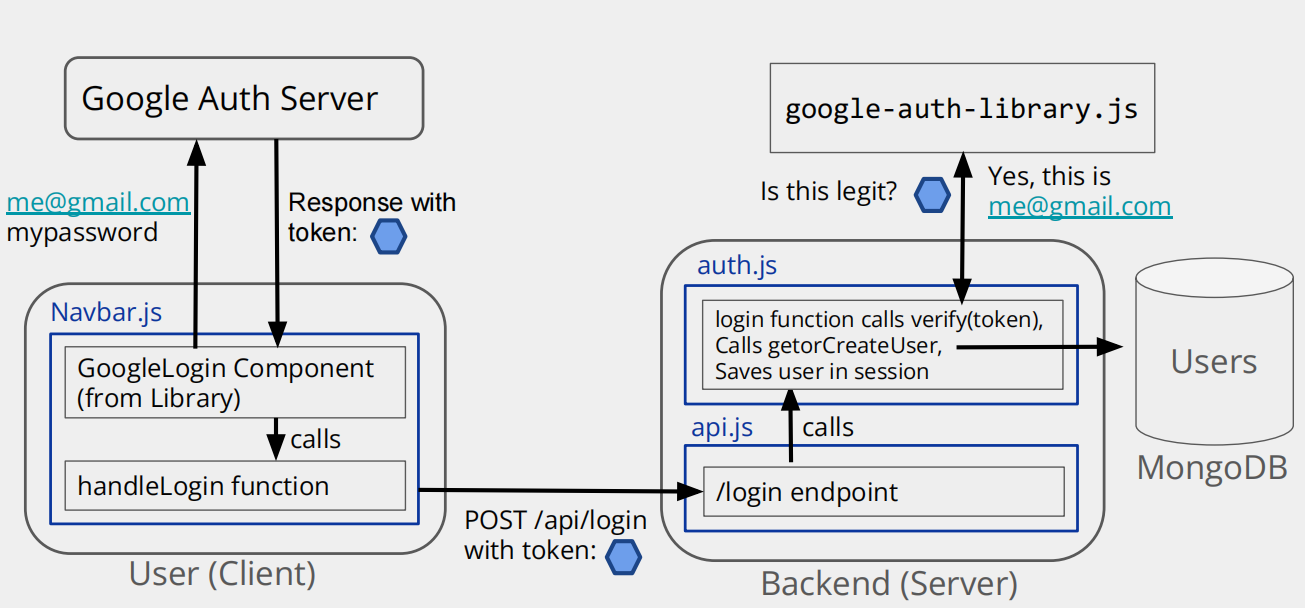
这张图展示的是基于 Google 认证的用户登录流程,从用户在前端(Client)操作,到后端(Server)处理、与数据库交互的完整过程。
1. 前端(User (Client))部分
- 用户输入认证信息:用户在
Navbar.js里的GoogleLogin Component(从第三方库引入的 Google 登录组件)中,输入自己的 Google 账号(比如me@gmail.com)和密码,发送给Google Auth Server(Google 的认证服务器)。 - 获取令牌(Token):
Google Auth Server验证用户身份合法后,会返回一个令牌(Token)(图里的蓝色六边形)给前端。 - 调用
handleLogin发请求:前端拿到令牌后,调用handleLogin函数,通过POST /api/login这个请求,把令牌发送到后端的/login接口。
2. 后端(Backend (Server))部分
api.js接收请求:后端的api.js里定义了/login这个接口(对应之前讲的router.post("/login", auth.login)),它会接收前端发来的带令牌的POST请求。auth.js处理登录逻辑:- 验证令牌:
auth.js里的login函数会调用google-auth-library.js(Google 官方的认证库)来验证令牌是否合法(也就是图里的 “Is this legit?” 步骤)。 - 获取 / 创建用户:如果令牌合法,
login函数会执行getorCreateUser操作 —— 去MongoDB的Users集合里查,有没有这个 Google 账号对应的用户;如果没有,就新建一个用户文档;如果有,就拿已有的用户信息。 - 保存会话(Session):最后,把用户信息保存到会话(Session)中,这样后续用户访问需要登录的页面时,后端能识别出 “这是哪个用户”。
- 验证令牌:
扩展知识(Web 开发角度)
1. 令牌的作用
令牌是 “用户身份的临时凭证”。因为直接在前端存用户密码不安全,所以用令牌代替 —— 令牌由权威的 Google Auth Server 生成,后端只需验证令牌,不用接触用户密码,大大提高了安全性。
2. google-auth-library.js 的细节
这个库是 Google 官方提供的,专门用来验证 “Google 签发的令牌” 是否合法。它内部会做这些事:
- 检查令牌的签名(确保是 Google 生成的,没被篡改)。
- 验证令牌的有效期(防止用过期令牌冒充身份)。
- 确认令牌对应的用户身份(比如是不是
me@gmail.com这个账号的令牌)。
3. Session 的作用
Session 是后端用来“记住用户登录状态” 的机制。用户登录后,后端会生成一个 Session ID,存在用户的 Cookie 里;同时后端自己也存一份 “Session ID ↔ 用户信息” 的映射。
后续用户每次发请求,都会带 Cookie 里的 Session ID,后端通过它就能知道 “这个请求是哪个用户发的”,从而判断是否需要拦截(比如未登录用户访问个人中心页面,就会被重定向到登录页)。
4. MongoDB 与用户数据
MongoDB 是非关系型数据库,这里用它存用户信息很合适 —— 用户数据不需要严格的 “表结构”,用类似 JSON 的文档(Document)存储更灵活。比如一个用户文档可能长这样:
{"googleId": "123456789","email": "me@gmail.com","name": "XXX","createdAt": "2025-10-13"
}
getorCreateUser 就是根据 googleId(每个 Google 账号的唯一标识)来查用户,保证 “一个 Google 账号对应 MongoDB 里唯一的用户”。
5. 前端后端的协作逻辑
前端负责“和用户交互、传递令牌”,后端负责“验证身份、管理用户数据、维护登录状态”。
两者通过 API 接口(如 /api/login) 通信,这种 “前后端分离” 的模式是现代 Web 开发的主流 —— 前端可以用 React/Vue 等框架,后端用 Node.js/Java/Python 等,只要接口约定好,技术栈能灵活搭配。
4 解释 req.user 的来源
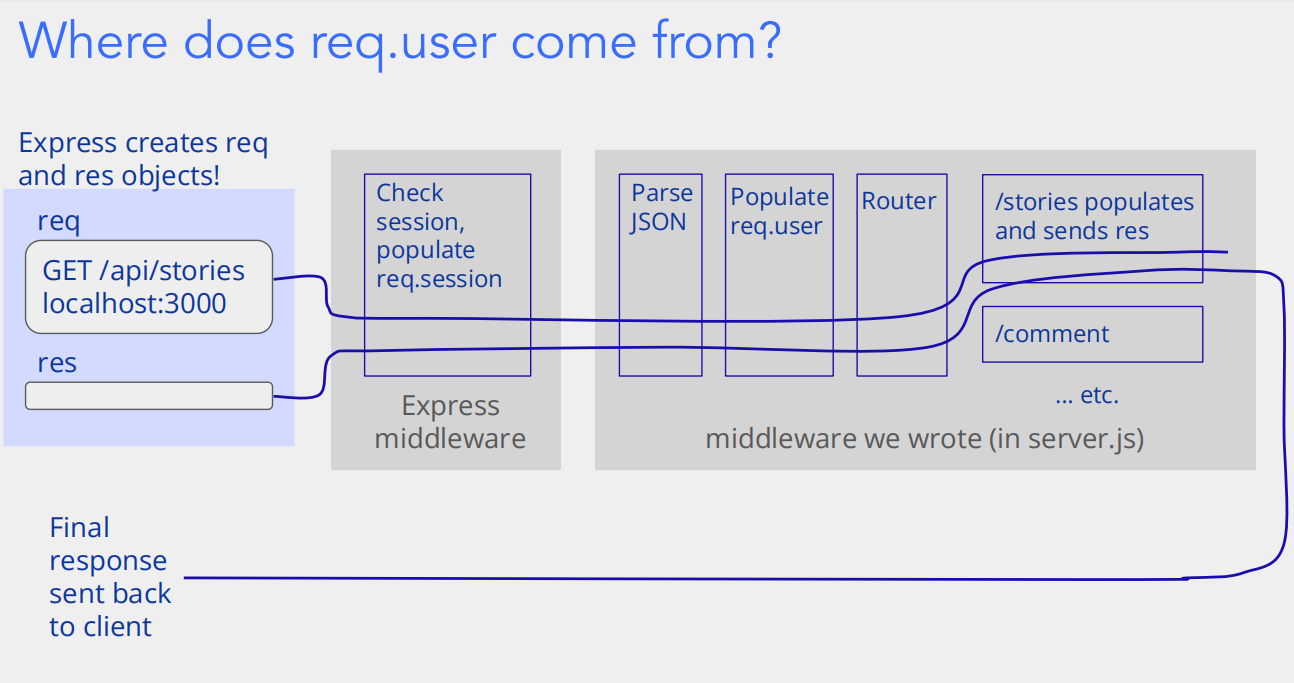

1. 先理解「中间件(Middleware)」的角色
在 Express 里,中间件就像 “请求的过滤器 / 处理器”:当客户端发一个请求(比如 GET /api/stories),这个请求会依次经过一串中间件,每个中间件都能对 req(请求对象)、res(响应对象)做操作,然后决定 “把请求传给下一个中间件” 或者 “直接返回响应”。
2. req.session 是怎么来的?
Express 本身不直接管 “会话(Session)”,但会借助会话中间件(比如 express-session 这个库)。当你在项目里配置了会话中间件后:
- 客户端第一次发请求时,中间件会生成一个唯一的 Session ID,把它存在用户的 Cookie 里;同时,服务器端会存一份 “Session ID ↔ 会话数据” 的映射。
- 后续用户再发请求,会带着 Cookie 里的 Session ID,中间件就能通过这个 ID,找到对应的 “会话数据”,并把数据挂到
req.session上。 - 正因为有这样的机制,
req.session能 “跨页面刷新”—— 哪怕用户刷新浏览器,Cookie 里的 Session ID 还在,服务器就能通过它找到之前的req.session,所以req.session里的内容不会丢。
3. 把「用户 ID」存到 req.session.user
当用户登录成功时(比如通过 Google 登录,后端验证令牌合法后),后端会做一件事:把这个用户的唯一标识(比如数据库里的 _id,或者 Google 账号的 ID),存到 req.session.user 里。
举个例子,登录逻辑大概长这样(伪代码):
app.post('/api/login', (req, res) => {// 验证令牌、查数据库拿到用户信息后const userId = user._id; // 假设 user 是数据库里的用户文档req.session.user = userId; // 把用户 ID 存到会话里res.send('登录成功');
});
这样,只要用户没登出,req.session.user 里就一直存着 “当前登录用户的 ID”。
4. 用「自定义中间件」生成 req.user
现在,req.session.user 里只有用户 ID,但实际业务中,我们需要 “用户的完整信息”(比如用户名、邮箱),这时候就需要自定义中间件来 “填充 req.user”。
假设中间件叫 populateCurrentUser(对应你图里 auth.js 第 55 行的逻辑),它的工作流程是这样的:
- 每当有请求过来,这个中间件会先检查
req.session.user是否存在(也就是 “用户有没有登录”)。 - 如果存在,就拿着
req.session.user里的用户 ID,去数据库(比如 MongoDB)里查这个 ID 对应的用户文档。 - 查到后,把完整的用户文档挂到
req.user上。这样,在后续的路由处理函数里(比如处理/api/stories的函数),就能直接通过req.user获取当前用户的所有信息了。
中间件的伪代码大概是这样:
function populateCurrentUser(req, res, next) {const userId = req.session.user;if (!userId) {// 没登录,req.user 设为 null 或者直接 next()req.user = null;return next();}// 去数据库查用户UserModel.findById(userId, (err, user) => {if (err) return next(err);req.user = user; // 把查到的用户文档挂到 req.usernext(); // 传给下一个中间件或路由处理函数});
}// 把中间件注册到 Express 里,让所有请求都经过它
app.use(populateCurrentUser);
5. 总结 req.user 的诞生流程
- 会话中间件生成
req.session,并保证它 “跨页面刷新”。 - 用户登录时,把用户 ID存到
req.session.user。 - 自定义中间件(如
populateCurrentUser)读取req.session.user里的 ID,去数据库查完整用户信息,然后把信息挂到req.user。 - 后续的路由 / 控制器里,直接用
req.user就能拿到 “当前登录用户” 的所有信息啦
5 前端开发中 “数据管理优劣” 的典型对比
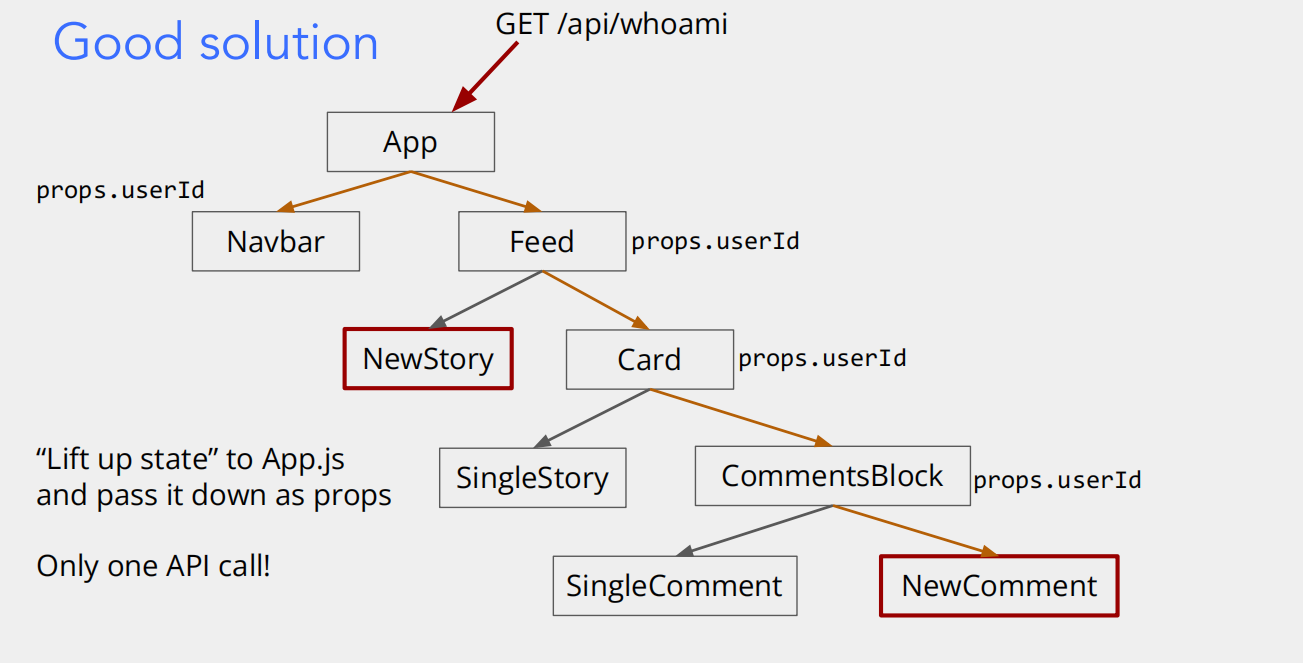
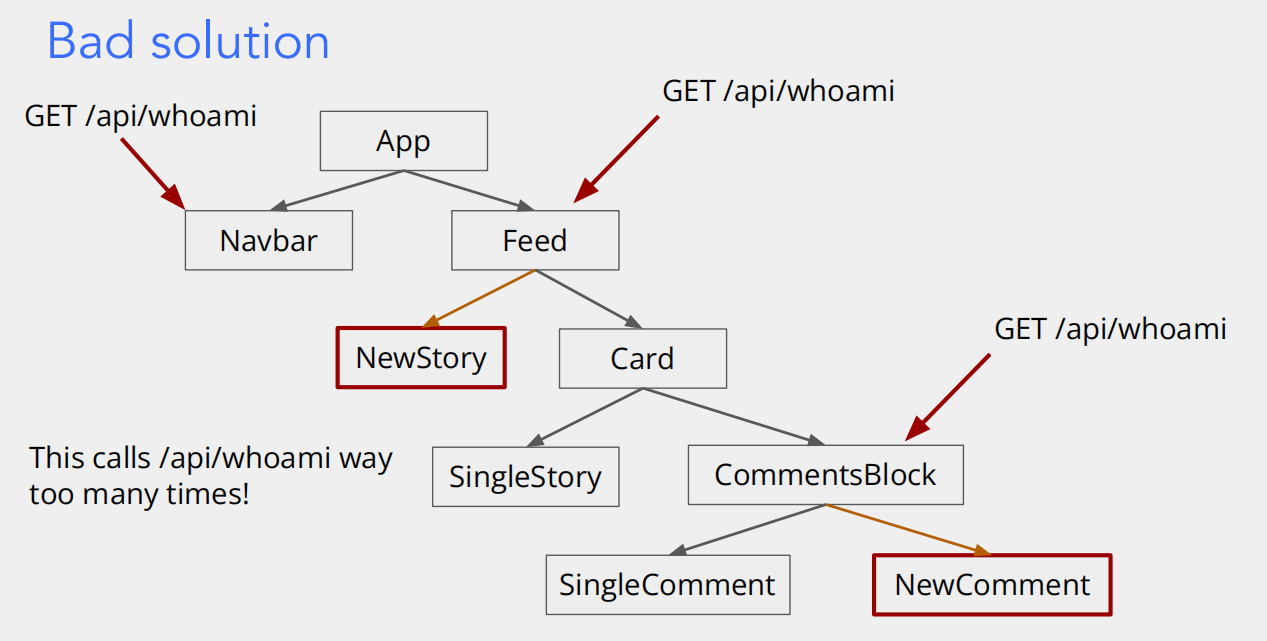
这两张图对比了前端应用中获取用户身份信息(通过 GET /api/whoami 接口)的两种不同数据管理方式,核心是讲解 React 等前端框架中「状态提升(Lift up state)」的重要性,以及对性能的影响。
第一张图:Good solution(好的解决方案)
流程解释
- 顶层获取数据:只有最顶层的
App组件发起一次GET /api/whoami请求,从后端获取当前用户的userId。 - 状态提升与 props 传递:
App组件把获取到的userId,通过 props(属性) 一层一层传递给下层组件(比如Navbar、Feed、Card等)。 - 下层组件复用数据:所有需要
userId的子组件(比如NewStory、NewComment,图中红框标记的是需要用户身份的 “创建类” 组件),都从父组件传递下来的 props 中获取userId,不需要自己再发请求。
核心优势:“状态提升” + “单次请求”
- 状态提升(Lift up state):把 “获取用户信息” 这个状态(数据),提升到组件树的最顶层(
App组件)管理。这样避免了多个子组件各自管理同一份数据,减少了冗余和不一致。 - 性能优化:整个应用只发一次
GET /api/whoami请求,就能让所有组件拿到userId。减少了网络请求次数,减轻了后端压力,也让前端渲染更高效。
第二张图:Bad solution(糟糕的解决方案)
流程解释
- 多个组件各自请求:
Navbar、Feed、CommentsBlock等多个组件,都各自发起GET /api/whoami请求,去后端获取userId。 - 重复请求的后果:比如
NewStory、NewComment这些需要用户身份的组件,所在的父组件(或自身)都可能发请求,导致大量重复的/api/whoami调用。
核心问题:“重复请求” + “数据分散”
- 重复请求:同一个接口被调用多次,完全是冗余的 —— 因为所有组件要的都是 “当前用户是谁” 这同一份数据,但却各自发请求,既浪费网络带宽,又让后端重复处理相同的逻辑。
- 数据分散:每个组件都自己存一份
userId,如果用户身份有变化(比如登出再登录),要保证所有组件的数据同步会非常困难,容易出现 “有的组件显示已登录,有的显示未登录” 的不一致问题。
扩展:为什么 “状态提升” 很重要?
在 React 等前端框架中,“状态提升” 是管理共享数据的核心模式,原因有这些:
- 单一数据源:所有组件依赖的同一份数据(比如用户信息、全局配置),由顶层组件统一管理,确保 “一处修改,处处同步”。
- 减少网络请求:像图中 “好的方案”,只需要一次请求就能供所有组件使用,避免重复请求带来的性能开销。
- 简化逻辑:子组件不需要关心 “数据从哪来”,只需要通过 props 接收即可,代码更简洁、易维护。
简单总结:好的方案通过「状态提升」让顶层组件统一获取数据,再向下传递;糟糕的方案让多个组件各自获取同一份数据,导致重复请求和数据混乱。这就是前端开发中 “数据管理优劣” 的典型对比。