吴恩达d6-DL 选择合适的策略来优化、选择模型
目录
一、模型评估
二、交叉验证
三、上述J之外的评估方法
四、学习曲线
五、偏差方差与神经网络
六、机器学习项目流程
一、模型评估
将数据划分为测试训练集,线性回归模型:比如通过计算测试与训练集的成本函数来评估模型拟合;逻辑回归同样可计算J又或者可以计算最终结果误分类的比例来评估模型性能
训练误差可能远低于测试平均误差,表明泛化能力差
注意这里的J都不包含正则化项,它只存于训练过程中
二、交叉验证
把数据划分成3个集
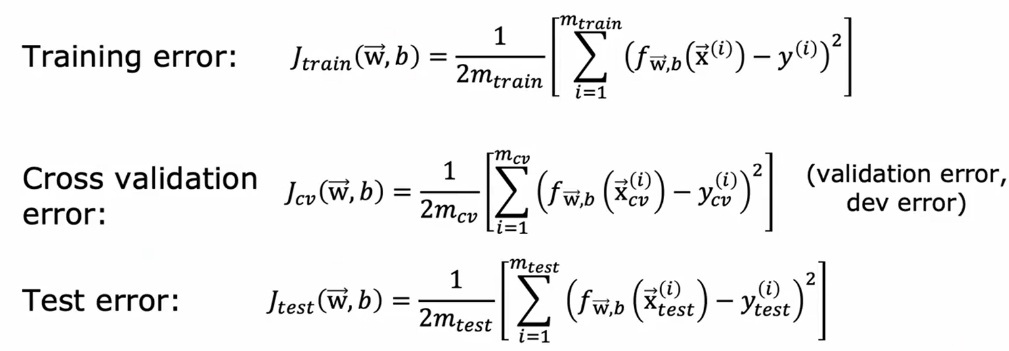
这三个集分别计算一个误差。在得出每个模型的最优参数后,先对比各个模型在此参数下的验证集误差,找出误差最小对应的模型并使用这个模型的参数,然后再把测试数据输入最优模型计算测试误差,以证明其泛化能力
三、上述J之外的评估方法
理解这两种方法会有效帮助在实践中决定下一步的调整
偏差是预测值与真实值的平均偏差程度
方差衡量模型预测结果的波动程度
高偏差:训练J高,验证J高,欠拟合
高方差:训练J低,验证J高,过拟合

正则化如何影响偏差、方差:尝试不同的入值
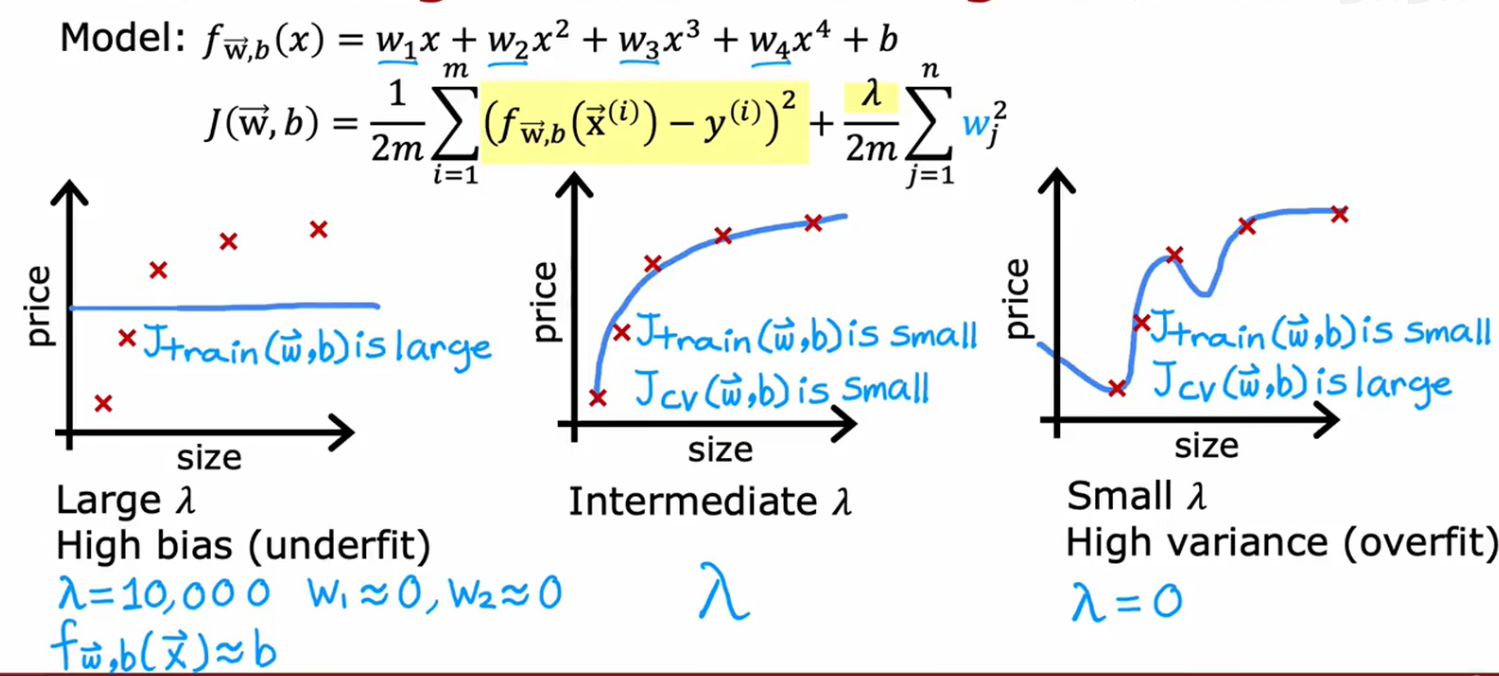
那么如何选一个合适的入值
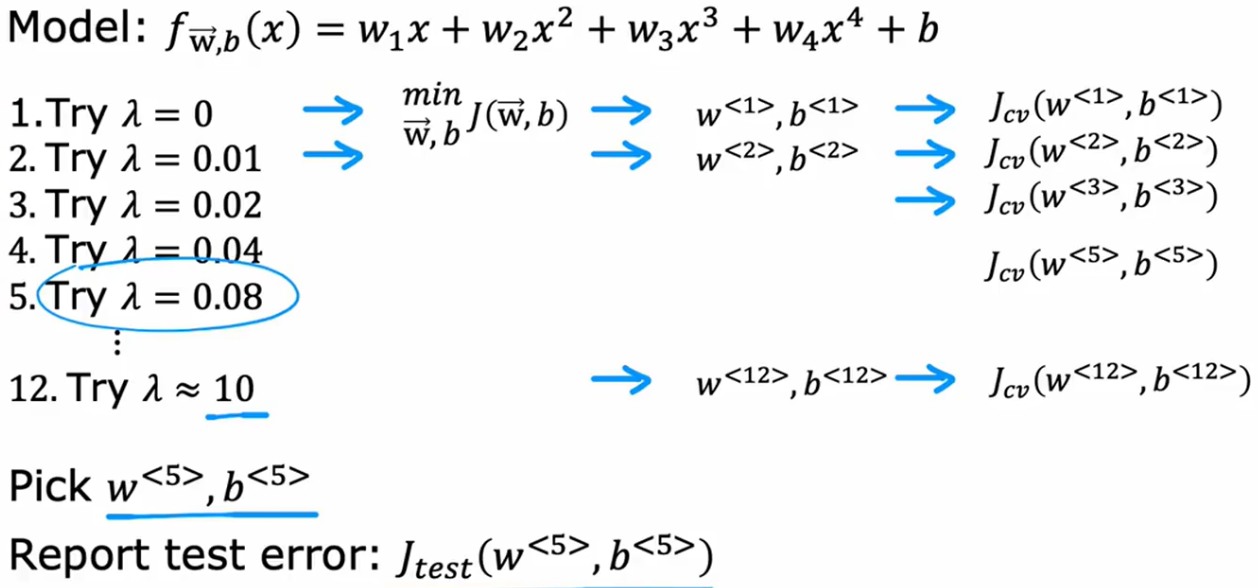
确定基准性能方法:1.统计人类的一般水平2.别人的算法表现3.根据自己经验期望的结果
所以一个判断是否高偏差方差的方法是计算
 看两两值的差距大小
看两两值的差距大小
四、学习曲线
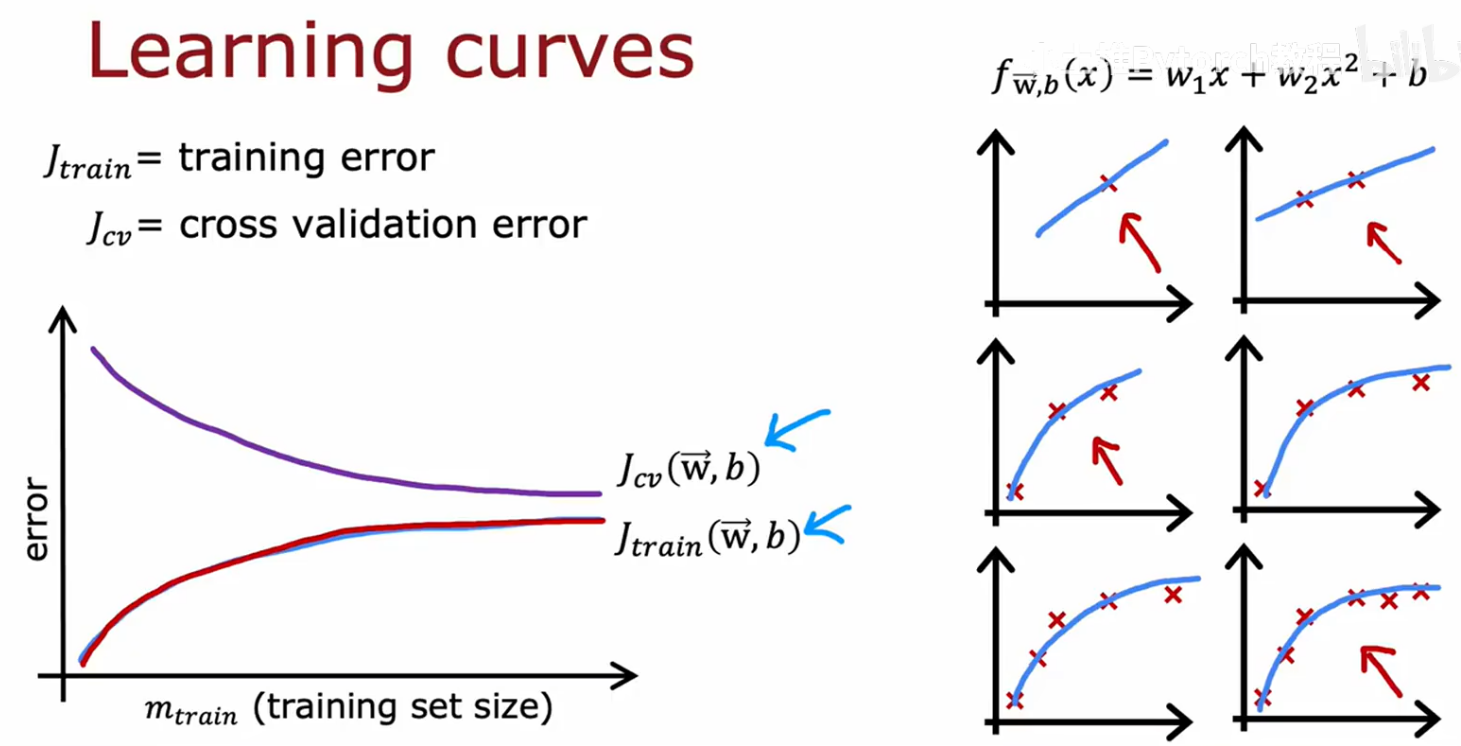 为什么训练集误差会增
为什么训练集误差会增
x轴样本数量,y轴误差,最后jcv要比jt大,是因为参数是靠训练集得到的
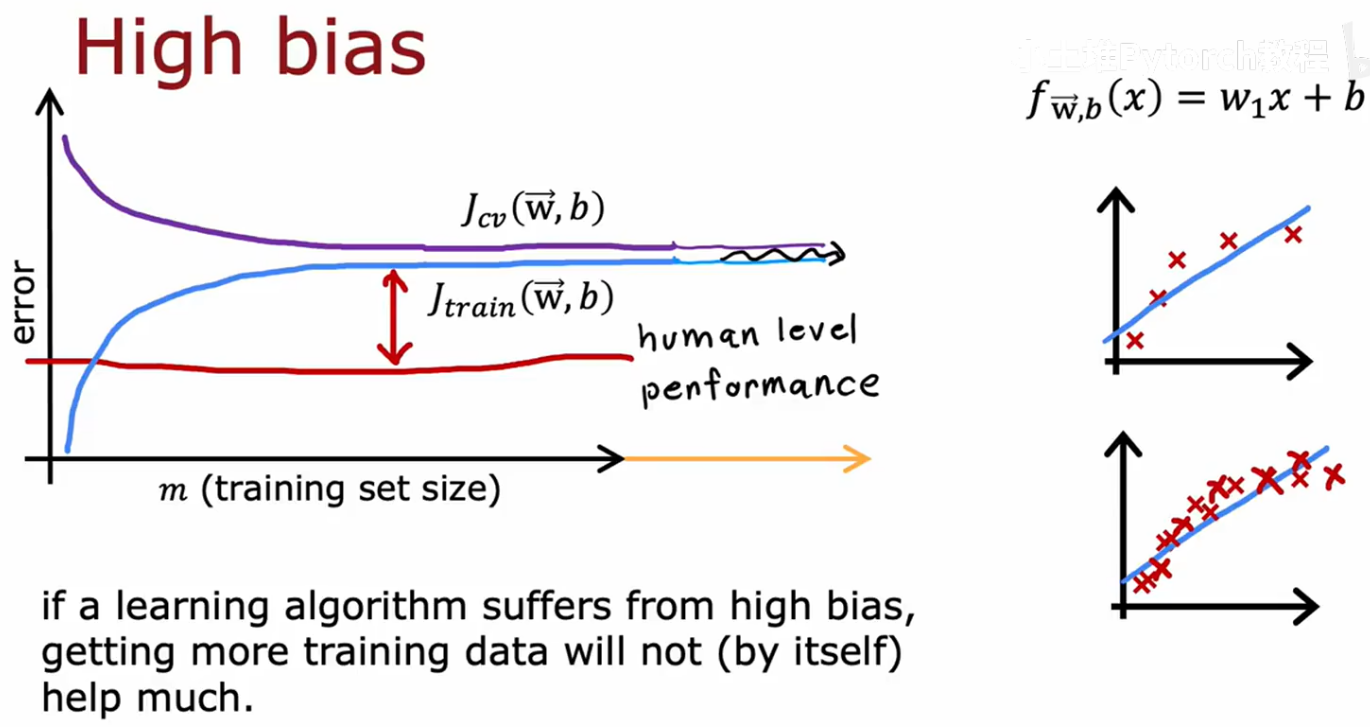 先看基准线位置
先看基准线位置
曲线后面趋于平坦,因为拟合的只是一直线,再多样本也没什么可改变的地方
一个算法有高偏差,继续增加样本数不会提性能,所以在使用大规模数据时,要检查算法是否高偏差

基准线,右边曲线的叉叉数量
总结:在项目中如果有1000个样本,可以先分别取200,400个样本等画学习曲线,但因计算量大,实践中一般不用

五、偏差方差与神经网络
只要训练集不是很大,一个大型神经网络是一个低偏差的机器,可以通过增大神网来解决高偏差,可以拟合很复杂的函数,这样一般只需处理高方差
只要适当的正则化一个越来越大的神经网络并不会过拟合,但计算量会很大
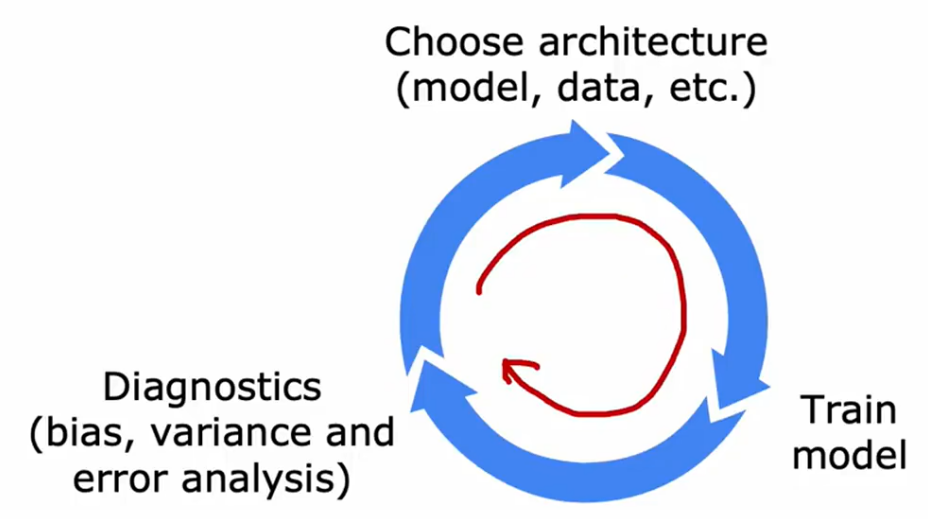
六、机器学习项目流程