青岛建站方案网络营销存在的问题及解决对策
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/146840732
免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。
DeepSeek-R1 通过强化学习,显著提升大语言模型推理能力,使用特殊的训练策略,其中 DeepSeek-R1-Zero 完全摒弃有监督微调(SFT),依靠强化学习训练,开创大模型训练中,跳过监督微调的先例。DeepSeek-R1 使用冷启动数据微调,通过多阶段强化学习,进一步优化推理能力。强化学习驱动的训练,不仅降低数据依赖,让模型在训练过程中,自发形成 “回头检查步骤” 的自我反思能力。
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeepSeek-R1: 通过 强化学习 激励大语言模型的 推理(Reasoning) 能力
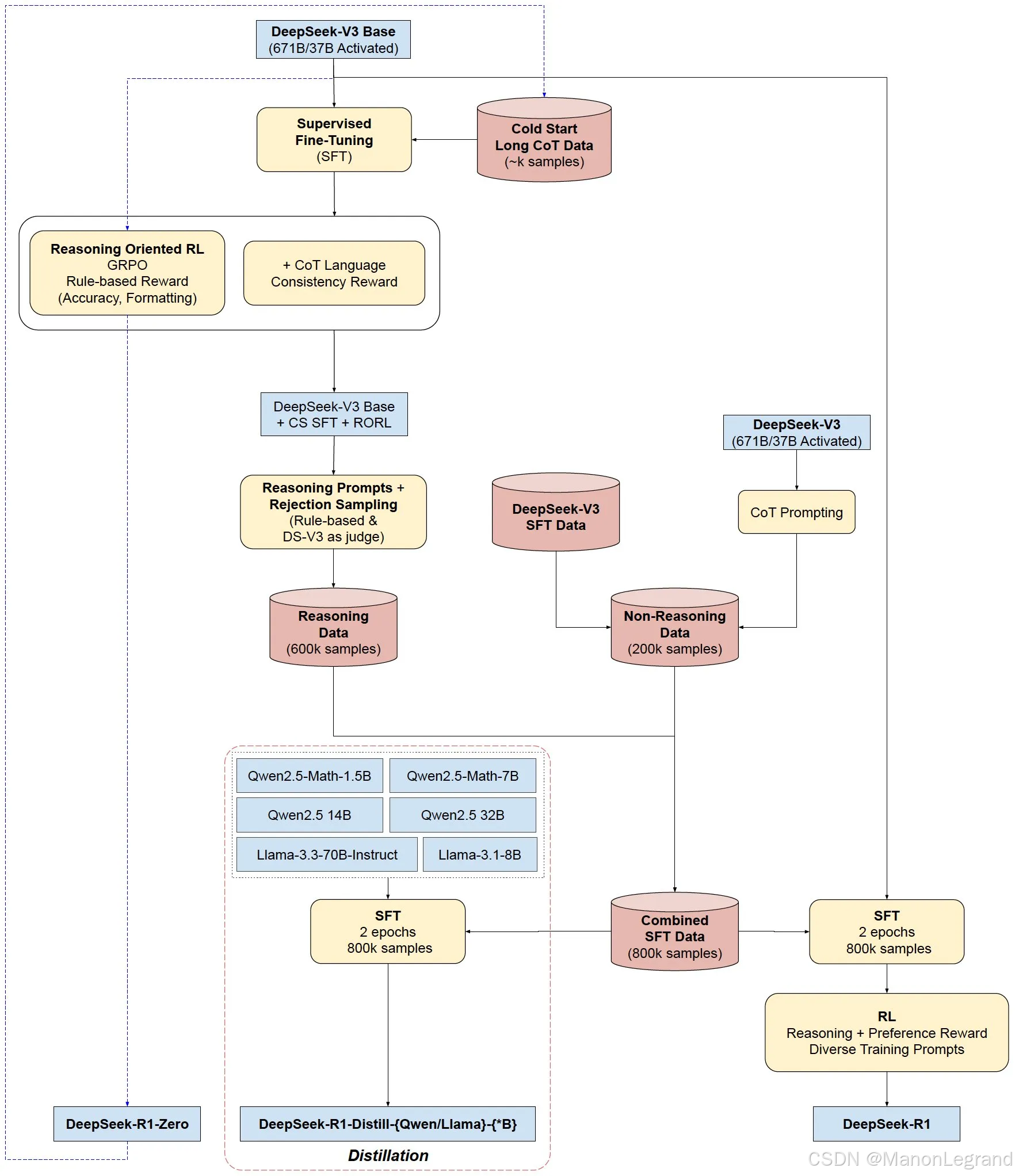
1. DeepSeek-R1框架
DeepSeek-R1 在 RL 之前,加入 多阶段训练(Multi-Stage Training) 和 冷启动(Cold-Start) 数据。
- 收集 数千条(Thousands) 冷启动数据 对 DeepSeek-V3-Base 模型进行微调(Fine-Tune)
- 以 面向推理(Reasoning-Oriented) 的强化学习。
- 在强化学习过程接近收敛时,在强化学习检查点,通过 拒绝采样(Rejection Sampling) 构建新的 SFT 数据(约600k+200k=800k),同时结合写作(Writing)、事实问答(Factual QA) 和 自我认知(Self-Cognition) 等监督数据(DeepSeek-V3),重新训练 DeepSeek-V3-Base 模型(SFT)。
- 经过新数据的微调之后,再通过额外的强化学习过程,考虑所有场景的提示。
Qwen2.5-32B 从 DeepSeek-R1 进行知识蒸馏的表现,优于在该模型上应用 RL,表明大型基础模型发现的推理模式(Reasoning Patterns),对于提升推理能力至关重要。
后训练(Post-Training):在基础模型上 进行 大规模强化学习(Large-Scale Reinforcement Learning)
- 直接应用强化学习(RL):直接将 强化学习(RL) 应用于基础模型,而不依赖于初始步骤的 有监督微调(SFT)。使得模型探索解决复杂问题的思维链(CoT),研发出 DeepSeek-R1-Zero。DeepSeek-R1-Zero 展现出,自我验证(Self-Verification)、反思(Reflection) 以及 生成长思维链(Long CoT) 等能力。研究验证,大语言模型(LLM) 的推理能力可以通过纯粹的 RL 激励,而无需 有监督微调(SFT)。
- DeepSeek-R1开发流程:研发 DeepSeek-R1 流程,包含 2 个 RL 阶段,在发现更优的推理模式,符合人类偏好;以及 2 个 SFT 阶段,作为模型推理和非推理能力的起点。
蒸馏(Distillation):小模型可以很强大
- 大模型推理模式的蒸馏:证明大模型的推理模式,通过蒸馏转移到小模型中,表现优于通过 RL 在小模型中发现的推理模式。
- 基于 DeepSeek-R1 推理数据的微调:使用 DeepSeek-R1 生成的推理数据,对于密集模型进行微调。评估结果显示,经过蒸馏的小模型在基准测试中,表现出色。
不使用监督微调(SFT) 作为初始状态,通过大规模强化学习(RL)也能显著提升推理能力。加入少量初始数据,能进一步提高性能:
- DeepSeek-R1-Zero:直接将 RL 应用于基础模型,不使用任何 SFT 数据。
- DeepSeek-R1:该模型从一个经过数千个长链式思维(CoT)示例微调的检查点开始应用RL。
- 从 DeepSeek-R1 提炼推理能力到小型密集模型中。
2. Reward
奖励 是训练信号的来源,决定 强化学习(RL) 的优化方向。在训练 DeepSeek-R1-Zero 时,采用基于规则的奖励系统,主要包含以下 2 种奖励:
-
准确性奖励:准确性奖励模型用于评估回答是否正确。例如,在数学问题这种有确定结果的情况下,模型需要以特定格式提供最终答案,进行可靠的基于规则的正确性验证。类似地,在处理 LeetCode 问题时,使用编译器根据预定义的测试用例生成反馈。
-
格式奖励:除了准确性奖励模型外,使用格式奖励模型,强制模型将其推理过程放在
<think>和</think>标签之间。
在研发 DeepSeek-R1-Zero 时,没有使用结果或过程奖励模型,因为奖励模型在大规模强化学习过程中,出现 奖励篡改(Reward Hacking) 问题,而且重新训练奖励模型,需要额外的训练资源,还会使整个训练流程变得更加复杂。
实际在源码中的奖励,包括:
- Accuracy Reward(准确性奖励):检查完成结果是否与真实答案一致,如数学、关键词等。
- Format Reward(格式奖励):检查推理过程是否被
<think>和</think>标签所包围,同时,最终答案是否被<answer>和</answer>标签所包围。 - Reasoning Steps Reward(推理步骤奖励):奖励函数,用于检查,是否具有清晰的分步推理过程。正则表达式模式:Step 1N,序号1N,多个点或星号,
First|Second|Next|Finally等过度词。 - Len Reward(长度奖励):计算基于长度的奖励,以减少过度思考并提高标记效率。Kimi-1.5
- Cosine Scaled Reward(余弦缩放奖励):根据完成长度(Completion Length),按余弦调度缩放的奖励函数。较短的正确解会比长的解获得更高的奖励。较长的错误解会比短的错误解受到较小的惩罚。
- Repetition Penalty Reward(重复惩罚奖励):计算 N-Gram 重复性惩罚。
- Code Reward(代码奖励):计算代码通过的覆盖率。
参考:https://github.com/huggingface/open-r1/blob/main/src/open_r1/rewards.py
框架如下: