分布式计算框架:从批处理到流处理的演进
🚀 分布式计算框架:从批处理到流处理的演进
文章目录
- 🚀 分布式计算框架:从批处理到流处理的演进
- 🌐 一、分布式计算的发展演进
- 🔄 从批处理到流处理的技术演进
- 💡 分布式计算的核心挑战
- ⚙️ 二、MapReduce 核心原理
- 🏗️ MapReduce 编程模型
- 🔄 Shuffle 过程深度解析
- ⚖️ MapReduce 优缺点分析
- ⚡ 三、Spark 架构与内存计算
- 🏗️ Spark 核心架构
- 🔄 RDD 与 DAG 执行模型
- ⚡ Spark Streaming 微批处理
- 🌊 四、Flink 与流处理革命
- 🏗️ Flink 流优先架构
- 🔄 有状态流计算
- ⚡ Checkpoint 与容错机制
- 🔄 流批一体处理
- ⚖️ 五、三者对比与选型指南
- 📊 技术特性对比矩阵
- 🎯 应用场景分析
- 🔧 选型决策指南
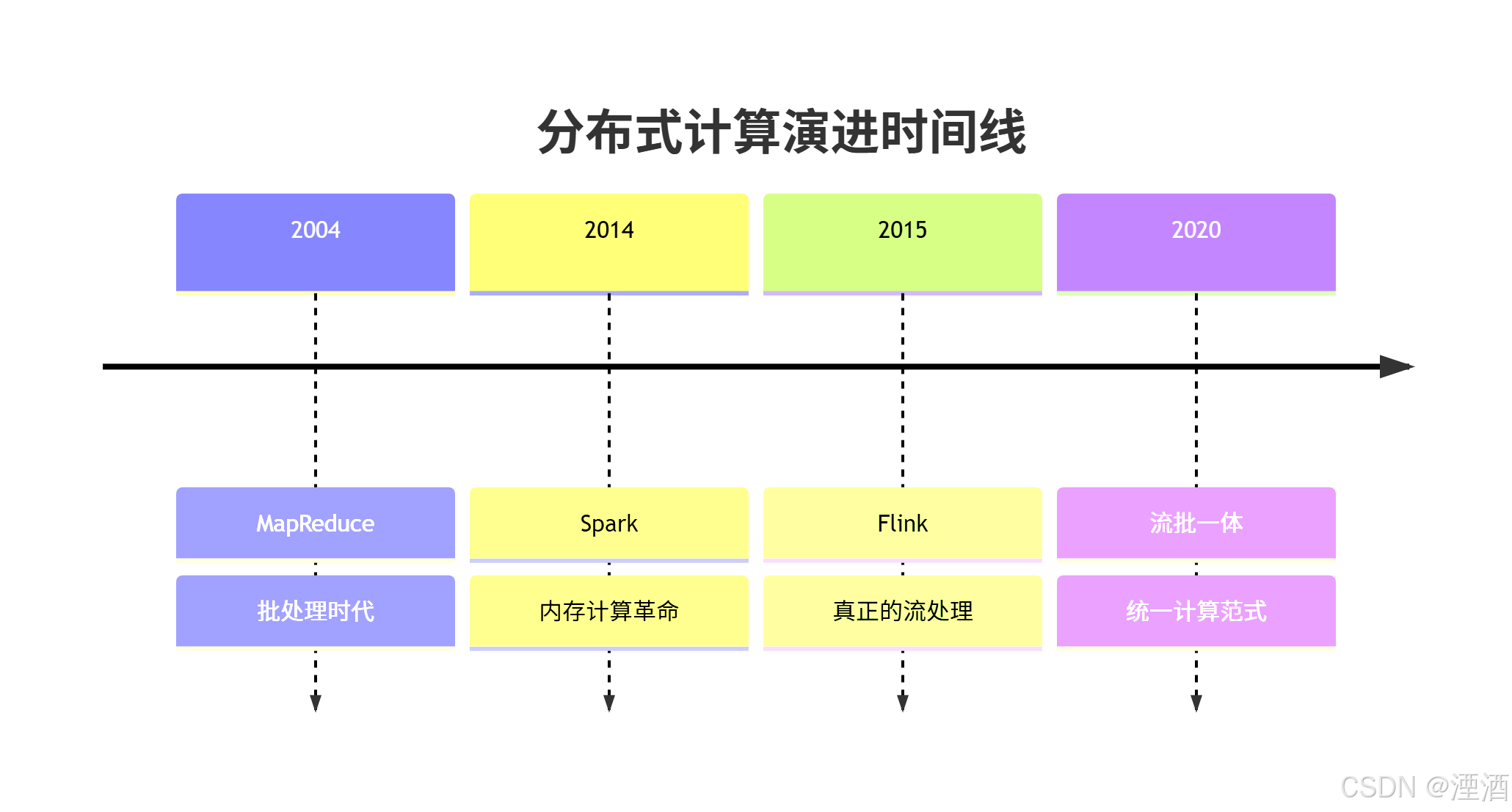
🌐 一、分布式计算的发展演进
🔄 从批处理到流处理的技术演进
数据处理范式的演变:
不同计算模式的典型应用场景对比
| 计算模式 | 数据处理方式 | 延迟级别 | 典型应用场景 |
|---|---|---|---|
| 批处理(Batch Processing) | 处理有界数据集,一次性全量计算 | 小时级 | 数据仓库构建、离线分析、报表统计(如 Hadoop、Spark Batch) |
| 微批处理(Micro-Batch Processing) | 将流式数据按时间窗口分批处理 | 分钟级 | 准实时分析、行为聚合(如 Spark Streaming) |
| 流处理(Stream Processing) | 处理无界数据流,事件驱动、持续计算 | 秒级 / 毫秒级 | 实时监控、告警系统、交易风控(如 Flink、Kafka Streams) |
💡 分布式计算的核心挑战
数据分布与计算并行化:
// 传统单机处理的局限性
public class SingleMachineProcessing {public void processLargeFile(File largeFile) {// 问题1: 内存限制List<Record> allRecords = loadAllRecords(largeFile); // 可能OOM// 问题2: 计算效率低for (Record record : allRecords) {processRecord(record); // 单线程处理}// 问题3: 故障恢复难if (processFailed) {// 需要从头开始重试}}
}// 分布式计算的优势
public class DistributedProcessing {public void processDistributed(Path inputPath) {// 数据自动分片List<DataSplit> splits = splitData(inputPath, 128); // 128个分片// 并行计算ExecutorService executor = Executors.newFixedThreadPool(32);for (DataSplit split : splits) {executor.submit(() -> processSplit(split));}// 容错机制executor.submit(new RecoveryMonitor()); // 监控故障并重试}
}
⚙️ 二、MapReduce 核心原理
🏗️ MapReduce 编程模型
经典WordCount示例:
// Mapper 实现
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private final static IntWritable one = new IntWritable(1);private Text word = new Text();@Overridepublic void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");for (String w : words) {word.set(w);context.write(word, one); // 输出: (单词, 1)}}
}// Reducer 实现
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overridepublic void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable value : values) {sum += value.get();}context.write(key, new IntWritable(sum)); // 输出: (单词, 总次数)}
}// 驱动程序
public class WordCountDriver {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCountDriver.class);job.setMapperClass(WordCountMapper.class);job.setCombinerClass(WordCountReducer.class);job.setReducerClass(WordCountReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
🔄 Shuffle 过程深度解析
MapReduce Shuffle 机制:
Shuffle 优化配置:
<!-- mapred-site.xml 优化配置 -->
<configuration><!-- Map端优化 --><property><name>mapreduce.task.io.sort.mb</name><value>512</value> <!-- 排序内存大小 --></property><property><name>mapreduce.map.sort.spill.percent</name><value>0.8</value> <!-- 溢出阈值 --></property><!-- Reduce端优化 --><property><name>mapreduce.reduce.shuffle.parallelcopies</name><value>20</value> <!-- 并行拷贝数 --></property><property><name>mapreduce.reduce.shuffle.input.buffer.percent</name><value>0.7</value> <!-- 内存缓冲区比例 --></property>
</configuration>
⚖️ MapReduce 优缺点分析
优势分析:
- 简单编程模型:只需实现map和reduce函数
- 自动容错:任务失败自动重新调度
- 线性扩展:轻松扩展到数千节点
- 数据本地性:计算向数据移动,减少网络传输
局限性分析:
// MapReduce 的典型问题示例
public class MRProblems {// 问题1: 中间结果落盘,性能开销大public void diskIOBottleneck() {// Map输出写入磁盘 -> 网络传输 -> Reduce读取磁盘// 多次磁盘IO严重影响性能}// 问题2: 迭代计算效率低public void iterativeProcessing() {// 每次迭代都需要完整的MapReduce作业for (int i = 0; i < 10; i++) {Job iterationJob = createMRJob();iterationJob.waitForCompletion(true); // 同步等待}}// 问题3: 实时性差public void latencyIssue() {// 批处理模式,延迟至少分钟级// 不适合实时数据处理需求}
}
⚡ 三、Spark 架构与内存计算
🏗️ Spark 核心架构
Spark 生态系统组成:
🔄 RDD 与 DAG 执行模型
RDD 弹性分布式数据集:
// Spark RDD 操作示例
object SparkWordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("WordCount")val sc = new SparkContext(conf)// 创建RDD并执行转换操作val textFile = sc.textFile("hdfs://.../large-file.txt")val wordCounts = textFile.flatMap(line => line.split(" ")) // 转换操作:扁平化.map(word => (word, 1)) // 转换操作:映射.reduceByKey(_ + _) // 转换操作:按键聚合// 行动操作触发计算wordCounts.saveAsTextFile("hdfs://.../output")sc.stop()}
}// DAG(有向无环图)构建过程
class DAGExample {def demonstrateDAG(): Unit = {// RDD转换操作构建DAGval rdd1 = sc.parallelize(Seq(1, 2, 3, 4, 5))val rdd2 = rdd1.filter(_ % 2 == 0) // 转换1val rdd3 = rdd2.map(_ * 2) // 转换2val rdd4 = rdd3.reduce(_ + _) // 行动操作// 对应的DAG:// ParallelCollectionRDD -> FilteredRDD -> MappedRDD -> Result}
}
Spark 内存管理优化:
// Spark 配置优化
val conf = new SparkConf().set("spark.executor.memory", "8g") // Executor内存.set("spark.driver.memory", "4g") // Driver内存.set("spark.memory.fraction", "0.6") // 内存分配比例.set("spark.memory.storageFraction", "0.5") // 存储内存比例.set("spark.sql.adaptive.enabled", "true") // 自适应查询.set("spark.sql.adaptive.coalescePartitions.enabled", "true")// 缓存策略选择
val df = spark.read.parquet("large_dataset.parquet")// 不同缓存级别
df.cache() // MEMORY_ONLY
df.persist(StorageLevel.MEMORY_AND_DISK) // 内存+磁盘
df.persist(StorageLevel.OFF_HEAP) // 堆外内存
⚡ Spark Streaming 微批处理
流处理示例:
object SparkStreamingExample {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName("NetworkWordCount")val ssc = new StreamingContext(conf, Seconds(1)) // 1秒批处理间隔// 从TCP socket读取数据流val lines = ssc.socketTextStream("localhost", 9999)val wordCounts = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)wordCounts.print()ssc.start() // 启动流计算ssc.awaitTermination() // 等待终止}
}// 结构化流处理(Spark 2.0+)
val streamingDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "host1:port1,host2:port2").option("subscribe", "topic1").load()val words = streamingDF.selectExpr("CAST(value AS STRING)").as[String].flatMap(_.split(" "))val wordCounts = words.groupBy("value").count()val query = wordCounts.writeStream.outputMode("complete").format("console").start()
🌊 四、Flink 与流处理革命
🏗️ Flink 流优先架构
Flink 架构图:
🔄 有状态流计算
Flink 状态管理示例:
public class StatefulStreamProcessing {// 键控状态示例:实时用户会话分析public static class UserSessionAnalyzer extends KeyedProcessFunction<String, UserEvent, SessionSummary> {// 状态声明private ValueState<Long> lastActivityTime;private MapState<String, Integer> eventCounts;@Overridepublic void open(Configuration parameters) {// 初始化状态ValueStateDescriptor<Long> timeDescriptor = new ValueStateDescriptor<>("lastActivity", Long.class);lastActivityTime = getRuntimeContext().getState(timeDescriptor);MapStateDescriptor<String, Integer> countDescriptor = new MapStateDescriptor<>("eventCounts", String.class, Integer.class);eventCounts = getRuntimeContext().getMapState(countDescriptor);}@Overridepublic void processElement(UserEvent event, Context ctx, Collector<SessionSummary> out) throws Exception {// 更新状态lastActivityTime.update(event.getTimestamp());Integer currentCount = eventCounts.get(event.getType());if (currentCount == null) {eventCounts.put(event.getType(), 1);} else {eventCounts.put(event.getType(), currentCount + 1);}// 生成会话摘要if (isSessionTimeout(event.getTimestamp())) {SessionSummary summary = new SessionSummary(event.getUserId(),eventCounts.entries(),lastActivityTime.value());out.collect(summary);// 清理状态eventCounts.clear();lastActivityTime.clear();}}}
}// 流处理作业
public class StreamingJob {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置检查点间隔(容错机制)env.enableCheckpointing(5000); // 5秒一次DataStream<String> text = env.socketTextStream("localhost", 9999);DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(value -> value.f0).sum(1);counts.print();env.execute("Flink Streaming WordCount");}public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String value, Collector<Tuple2<String, Integer>> out) {String[] words = value.toLowerCase().split("\\W+");for (String word : words) {if (word.length() > 0) {out.collect(new Tuple2<>(word, 1));}}}}
}
⚡ Checkpoint 与容错机制
精确一次语义保证:
public class ExactlyOnceExample {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 检查点配置CheckpointConfig checkpointConfig = env.getCheckpointConfig();checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);checkpointConfig.setCheckpointInterval(5000); // 5秒checkpointConfig.setMinPauseBetweenCheckpoints(1000);checkpointConfig.setCheckpointTimeout(60000);checkpointConfig.setMaxConcurrentCheckpoints(1);// 状态后端配置(决定状态存储位置)env.setStateBackend(new FsStateBackend("hdfs://checkpoints"));// 从Kafka读取数据(支持精确一次)Properties kafkaProps = new Properties();kafkaProps.setProperty("bootstrap.servers", "localhost:9092");kafkaProps.setProperty("group.id", "flink-group");FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("input-topic",new SimpleStringSchema(),kafkaProps);// 设置从检查点恢复consumer.setStartFromGroupOffsets();}
}// 两阶段提交Sink(保证端到端精确一次)
public class ExactlyOnceSink {public static class TransactionalFileSink extends TwoPhaseCommitSinkFunction<String, TransactionalFileSink.TxnState, Void> {public TransactionalFileSink() {super(new KryoSerializer<>(TxnState.class), VoidSerializer.INSTANCE);}@Overrideprotected TxnState beginTransaction() throws Exception {// 开始事务:创建临时文件String txnId = UUID.randomUUID().toString();Path tempFile = new Path("/temp/" + txnId + ".tmp");return new TxnState(txnId, tempFile);}@Overrideprotected void invoke(TxnState transaction, String value, Context context) throws Exception {// 写入临时文件FileSystem fs = FileSystem.get(new Configuration());try (FSDataOutputStream out = fs.append(transaction.tempFile)) {out.writeUTF(value + "\n");}}@Overrideprotected void preCommit(TxnState transaction) throws Exception {// 预提交:刷新数据FileSystem fs = FileSystem.get(new Configuration());fs.hflush(transaction.tempFile);}@Overrideprotected void commit(TxnState transaction) {// 提交:重命名文件try {FileSystem fs = FileSystem.get(new Configuration());Path finalFile = new Path("/final/" + transaction.txnId + ".txt");fs.rename(transaction.tempFile, finalFile);} catch (Exception e) {throw new RuntimeException("Commit failed", e);}}@Overrideprotected void abort(TxnState transaction) {// 回滚:删除临时文件try {FileSystem fs = FileSystem.get(new Configuration());fs.delete(transaction.tempFile, false);} catch (Exception e) {// 忽略删除失败}}public static class TxnState {public String txnId;public Path tempFile;public TxnState(String txnId, Path tempFile) {this.txnId = txnId;this.tempFile = tempFile;}}}
}
🔄 流批一体处理
统一数据处理API:
public class UnifiedProcessingExample {// 批处理模式public static void batchProcessing() throws Exception {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();DataSet<String> text = env.readTextFile("hdfs://input.txt");DataSet<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).groupBy(0).sum(1);counts.writeAsText("hdfs://output");env.execute("Batch WordCount");}// 流处理模式public static void streamProcessing() throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> text = env.readTextFile("hdfs://input.txt");DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1);counts.writeAsText("hdfs://output");env.execute("Streaming WordCount");}// 表API(SQL-like接口)public static void tableProcessing() throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);// 注册表tableEnv.createTemporaryView("user_events", env.fromElements(new UserEvent("user1", "click", 1000L),new UserEvent("user2", "view", 1001L)));// SQL查询Table result = tableEnv.sqlQuery("SELECT user_id, COUNT(*) as event_count " +"FROM user_events " +"GROUP BY user_id");// 转换为DataStream输出DataStream<Row> resultStream = tableEnv.toAppendStream(result, Row.class);resultStream.print();env.execute();}
}
⚖️ 五、三者对比与选型指南
📊 技术特性对比矩阵
| 特性维度 | MapReduce | Spark | Flink | 优势分析 |
|---|---|---|---|---|
| 处理模型 | 批处理(Batch) | 微批处理(Micro-Batch) | 真正的流处理(Stream) | ⚡ Flink 流处理最先进 |
| 延迟级别 | 小时级 | 秒级 / 分钟级 | 毫秒级 | ⏱️ Flink 延迟最低 |
| 内存使用 | 以磁盘 IO 为主 | 内存计算模型 | 内存 + 状态混合优化 | 💾 Spark 内存利用最佳 |
| 状态管理 | 无状态 | 有限状态支持 | 内置强大状态管理机制 | 🧠 Flink 状态管理最完善 |
| 容错机制 | 任务重试机制 | 基于 RDD 血缘恢复 | 精确一次性 Checkpoint | 🛡️ Flink 容错最精确 |
| API 丰富度 | 基础 Java API | 提供多语言多层次 API | 流批统一 API 设计 | 🌐 Spark 生态最丰富 |
| 学习曲线 | 简单易上手 | 中等难度 | 较陡峭,概念复杂 | 🧩 MapReduce 最易入门 |
🎯 应用场景分析
MapReduce 适用场景:
- 超大规模批处理:TB/PB级数据离线处理
- 简单ETL任务:数据清洗、格式转换
- 成本敏感场景:对延迟不敏感,追求硬件利用率
- 遗留系统集成:与Hadoop生态深度集成
Spark 最佳场景:
- 交互式查询:数据探索、即席查询
- 机器学习:迭代算法、模型训练
- 复杂ETL管道:多阶段数据处理
- 准实时分析:分钟级延迟的流处理
Flink 优势场景:
- 实时监控告警:毫秒级延迟要求的场景
- 事件驱动应用:复杂事件处理、模式检测
- 流式ETL:实时数据清洗和转换
- 金融风控:需要精确一次语义的交易处理
🔧 选型决策指南
技术选型决策树:
具体选型建议:
| 业务场景 | 推荐方案 | 主要理由 | 配置建议 |
|---|---|---|---|
| 数据仓库 ETL | Spark | 内存计算加速批量处理,生态成熟(Hive、HDFS兼容) | 🧠 大内存节点(≥64GB),SSD 存储以提升 shuffle 性能 |
| 实时推荐系统 | Flink | 毫秒级延迟,事件驱动流式计算,支持 CEP 复杂事件检测 | ⚙️ 高 CPU 核数、低延迟网络(万兆网卡),启用 RocksDB 状态后端 |
| 历史数据分析 | MapReduce | 成本低、可靠性高,适合大规模离线统计 | 💾 使用标准 x86 服务器,磁盘型节点(大容量 SATA),关注 IO 吞吐 |
| 交互式查询 / BI 报表 | Spark SQL | 内存查询引擎快,支持缓存与列存优化(Parquet、ORC) | 🚀 配置 Executor 内存缓存,启用 DataFrame Cache 优化 |
| 物联网数据处理 | Flink | 支持无界流、高吞吐、复杂事件模式匹配 | 🌐 部署分布式状态后端(RocksDB+Checkpoint),配合 Kafka + HBase |