AgentLightning框架(1)
目录
- 框架概述
- 训练机制
- 智能体能力增强原理
- 训练流程
- 代码执行流程
- 策略网络详解
- 使用外部API的优化策略
- 训练后策略使用
- sql_agent注释
框架概述
AgentLightning是一个用于训练智能体的强化学习框架,采用Agent-Server分离架构:
- Agent端:负责与环境交互,执行具体任务
- Server端:负责训练策略,更新模型参数
这种架构允许多个agent并行运行,同时由中央服务器协调训练过程。
训练机制
整体架构
- 启动Ray分布式计算框架管理资源
- 初始化训练器(AgentLightningTrainer)和算法(VERL)
- 加载预训练的基础模型
训练流程
- 任务分配:训练器向智能体分发任务
- 策略执行:智能体使用当前策略执行任务
- 轨迹收集:收集完整的执行轨迹
- 奖励计算:根据执行结果计算奖励
- 模型更新:使用GRPO/PPO算法更新策略网络参数
核心技术
- 强化学习算法:Generalized Reward Policy Optimization (GRPO) + Proximal Policy Optimization (PPO)
- 分布式训练:基于Ray框架实现
- 内存优化:使用FSDP(Fully Sharded Data Parallel)
智能体能力增强原理
1. 策略优化
通过强化学习训练,智能体的策略网络逐渐优化:
- 初始状态:基于预训练模型的通用能力
- 训练过程:通过奖励信号引导策略向最优方向发展
- 最终状态:具备专门针对目标任务的优化策略
2. 经验积累
智能体在训练过程中积累经验:
- 学习识别有效的任务执行模式
- 掌握任务环境的理解和应用
- 发展出更好的错误检测和纠正能力
3. 自我改进循环
智能体实现多轮自我改进:
- 执行初始任务
- 观察执行结果
- 分析错误并生成反馈
- 根据反馈调整策略
- 重复直到成功或达到最大轮数
训练流程

代码执行流程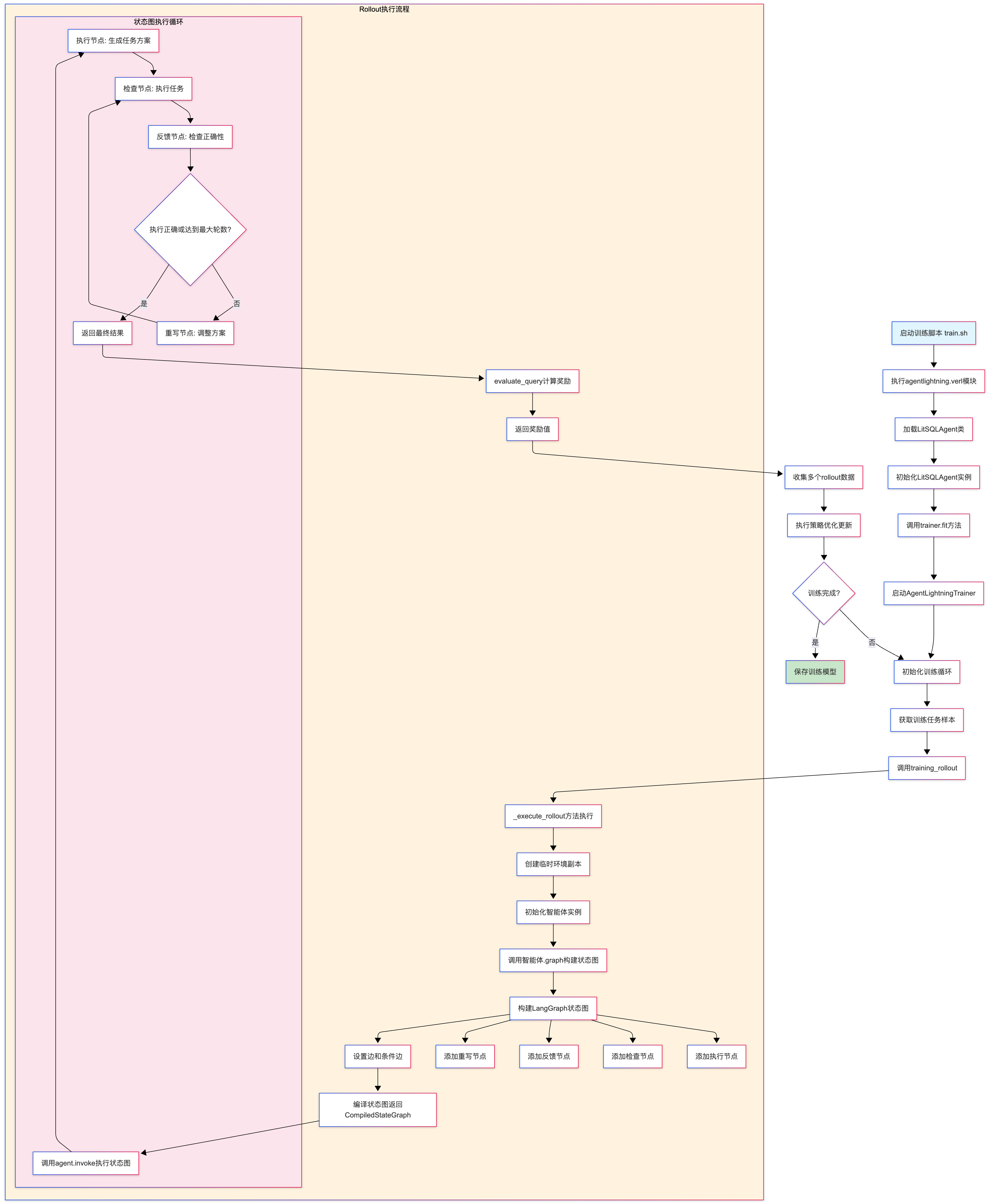
策略网络详解
策略网络是什么
策略网络是基础语言模型加上训练过程中学习到的适配器参数:
- 基础语言模型:如Qwen2.5-Coder-1.5B-Instruct
- 适配器层:训练过程中学习到的特定任务参数
- 价值网络:用于评估状态价值的辅助网络
策略网络结构
# policy.pt文件包含的内容
{"model_state_dict": {"transformer.h.0.attn.c_attn.weight": tensor(...),"transformer.h.0.attn.c_proj.weight": tensor(...),...},"adapter_state_dict": {"lora_A.0.weight": tensor(...),"lora_B.0.weight": tensor(...),...},"training_config": {"base_model": "Qwen/Qwen2.5-Coder-1.5B-Instruct","learning_rate": 1e-6,...}
}
使用外部API的优化策略
优化内容
当使用OpenAI等外部API作为基础模型时,强化学习优化的内容包括:
1. 提示工程优化
# 训练后学到的更好的提示构造方式
optimized_prompt = """
You are an expert task executor. Given the context:
{context}Execute the task: {input}Important considerations:
- Follow best practices
- Handle edge cases
- Optimize for accuracy
"""
2. 决策策略优化
# 训练后学到的决策逻辑
def should_rewrite(execution_result, feedback):# 通过训练学到何时需要重写执行方案if "syntax error" in execution_result.lower():return Trueif "empty result" in feedback.lower() and expected_non_empty:return Truereturn False
3. 交互策略优化
# 训练后学到的多轮交互策略
def interaction_strategy(task, previous_attempts):if len(previous_attempts) == 0:# 第一次尝试:使用标准方法return generate_initial_solution(task)elif len(previous_attempts) == 1:# 第二次尝试:基于反馈调整return refine_solution_based_on_feedback(task, previous_attempts[0])else:# 多次失败后:使用更保守的策略return generate_simplified_solution(task)
训练后策略使用
1. 策略规则文件
# 训练后生成的策略配置文件 (optimized_strategy.json)
{"prompt_templates": {"execute_task": "优化后的提示模板...","check_result": "优化后的检查模板..."},"decision_rules": {"rewrite_threshold": 0.3,"max_attempts": 3,"error_handling": {"syntax_error": "重写策略A","empty_result": "重写策略B"}},"interaction_patterns": {"standard_flow": ["execute", "check"],"error_flow": ["execute", "check", "rewrite", "execute", "check"]}
}
2. 使用策略规则文件
# 加载训练后优化的策略
import jsonclass InferenceAgent:def __init__(self, strategy_file="optimized_strategy.json"):# 加载训练优化的策略with open(strategy_file, 'r') as f:self.strategy = json.load(f)def execute_task(self, task, context):# 使用优化的提示模板prompt = self.strategy["prompt_templates"]["execute_task"].format(input=task,context=context)# 调用API时应用优化策略response = call_api(prompt)# 使用优化的决策逻辑if self.should_check_response(response):feedback = self.check_result(response)if self.should_rewrite(feedback):return self.rewrite_solution(response, feedback)return response
3. 实际使用示例
# 1. 训练阶段
bash train.sh # 生成优化策略和检查点# 2. 导出优化策略
python export_strategy.py --checkpoint experiments/spider/checkpoint-1 \--output optimized_strategy.json# 3. 推理阶段使用优化策略
python inference.py --strategy optimized_strategy.json \--model gpt-4.1-mini \--task "查询用户表中年龄大于30的记录"
# inference.py
from trained_agent import TrainedAgent# 加载训练优化的策略
agent = TrainedAgent(model_endpoint="https://api.openai.com/v1",strategy_file="optimized_strategy.json"
)# 使用优化策略进行推理
solution, result = agent.execute(task="查询用户表中年龄大于30的记录",context=get_database_schema()
)print(f"生成的解决方案: {solution}")
print(f"执行结果: {result}")
最后给一下仓库给的代码例子,添加了注释
sql_agent注释
# Copyright (c) Microsoft. All rights reserved."""
基于LangChain和LangGraph的SQL代理实现,用于与SQL数据库交互并生成、执行和验证SQL查询。
该实现改编自以下教程:
- https://python.langchain.com/docs/tutorials/sql_qa/
- https://langchain-ai.github.io/langgraph/tutorials/sql-agent/主要功能:
1. 生成SQL查询以回答用户问题
2. 执行生成的SQL查询
3. 检查查询的正确性
4. 根据反馈重写查询
5. 使用Spider数据集进行训练和评估
"""# 启用延迟注解解析,允许在类型提示中引用尚未定义的类
from __future__ import annotations# 导入标准库模块
import os # 用于操作系统相关功能,如路径操作和环境变量
import re # 用于正则表达式操作
import shutil # 用于高级文件操作,如复制文件
import tempfile # 用于创建临时文件和目录
import time # 用于时间相关操作
# 导入类型提示相关模块
from typing import Any, Dict, Literal, Optional, cast# 导入第三方库模块
import dotenv # 用于加载.env文件中的环境变量
import termcolor # 用于在终端中输出带颜色的文本
# 导入LangChain相关模块
from langchain.chat_models import init_chat_model # 用于初始化聊天模型
from langchain_community.tools.sql_database.tool import QuerySQLDatabaseTool # 用于执行SQL查询的工具
from langchain_community.utilities import SQLDatabase # 用于SQL数据库连接
from langchain_core.messages import AnyMessage, BaseMessage, HumanMessage # 用于处理消息类型
from langchain_core.prompts import ChatPromptTemplate # 用于创建聊天提示模板
# 导入LangGraph相关模块
from langgraph.graph import END, START, MessagesState, StateGraph # 用于构建状态图
from langgraph.graph.state import CompiledStateGraph # 用于编译状态图
# 导入Spider数据集评估模块
from spider_eval.exec_eval import eval_exec_match # 用于评估SQL查询执行结果# 导入AgentLightning框架模块
import agentlightning# 配置日志记录器
agentlightning.configure_logger()# 获取当前模块的日志记录器
logger = agentlightning.configure_logger(name=__name__)# 生成SQL查询的Prompt模板
# 思路注释:
# 1. 指示模型作为SQL数据库交互代理
# 2. 要求生成语法正确的SQL查询
# 3. 提供表结构信息作为上下文
# 4. 规定输出格式为代码块形式
WRITE_QUERY_PROMPT = ChatPromptTemplate([("system","""
You are an agent designed to interact with a SQL database.Given an input question, create a syntactically correct {dialect} query to run to help find the answer.Pay attention to use only the column names that you can see in the schema description.
Be careful to not query for columns that do not exist.
Also, pay attention to which column is in which table.## Table Schema ##Only use the following tables:
{table_info}## Output Format ##Respond in the following format:```{dialect}
GENERATED QUERY
```
""".strip(),),("user", "Question: {input}"),]
)# 检查SQL查询的Prompt模板
# 思路注释:
# 1. 指示模型作为SQL专家,专注于细节检查
# 2. 要求检查常见SQL错误
# 3. 提供表结构信息作为上下文
# 4. 规定输出格式,明确指出查询是否正确
CHECK_QUERY_PROMPT = ChatPromptTemplate([("system","""
You are a SQL expert with a strong attention to detail.
Double check the {dialect} query for common mistakes, including:
- Using NOT IN with NULL values
- Using UNION when UNION ALL should have been used
- Using BETWEEN for exclusive ranges
- Data type mismatch in predicates
- Properly quoting identifiers
- Using the correct number of arguments for functions
- Casting to the correct data type
- Using the proper columns for joins
- Explicit query execution failures
- Clearly unreasoable query execution results## Table Schema ##{table_info}## Output Format ##If any mistakes from the list above are found, list each error clearly.
After listing mistakes (if any), conclude with **ONE** of the following exact phrases in all caps and without surrounding quotes:
- If mistakes are found: `THE QUERY IS INCORRECT.`
- If no mistakes are found: `THE QUERY IS CORRECT.`DO NOT write the corrected query in the response. You only need to report the mistakes.
""".strip(),),("user","""Question: {input}Query:```{dialect}
{query}
```Execution result:```
{execution}
```""",),]
)# 重写SQL查询的Prompt模板
# 思路注释:
# 1. 指示模型作为SQL数据库交互代理
# 2. 要求根据反馈重写SQL查询
# 3. 提供原始问题、之前的查询、执行结果和反馈作为上下文
# 4. 规定输出格式为代码块形式
REWRITE_QUERY_PROMPT = ChatPromptTemplate([("system","""
You are an agent designed to interact with a SQL database.
Rewrite the previous {dialect} query to fix errors based on the provided feedback.
The goal is to answer the original question.
Make sure to address all points in the feedback.Pay attention to use only the column names that you can see in the schema description.
Be careful to not query for columns that do not exist.
Also, pay attention to which column is in which table.## Table Schema ##Only use the following tables:
{table_info}## Output Format ##Respond in the following format:```{dialect}
REWRITTEN QUERY
```
""".strip(),),("user","""Question: {input}## Previous query ##```{dialect}
{query}
```## Previous execution result ##```
{execution}
```## Feedback ##{feedback}Please rewrite the query to address the feedback.""",),]
)# 状态类,用于存储SQL代理的执行状态
# 思路注释:
# 1. 继承自MessagesState,用于存储消息历史
# 2. 添加特定于SQL代理的字段来跟踪执行过程
# 3. 包含问题、查询、执行结果、答案、反馈、迭代次数和消息历史
class State(MessagesState):# 用户提出的问题question: str# 生成的SQL查询query: str# SQL查询的执行结果execution: str# 查询的答案answer: str# 检查查询时的反馈feedback: str# 当前迭代次数num_turns: int# 消息历史记录messages: list[AnyMessage]class SQLAgent:"""SQL代理类,用于与SQL数据库交互,能够生成、执行和验证SQL查询思路注释:1. 初始化数据库连接和LLM模型2. 配置调试选项和限制参数3. 根据是否使用VERL替换来决定LLM模型的初始化方式"""def __init__(self,db: str,max_turns: int = 5,debug: bool = False,db_schema: str | None = None,endpoint: str | None = None,verl_replacement: Dict[str, Any] | None = None,table_info_truncate: int = 2048,execution_truncate: int = 2048,):# 初始化SQL数据库连接self.db = SQLDatabase.from_uri(db) # type: ignore# 数据库模式信息,用于在无法获取实际表信息时作为备用self.db_schema = db_schema# 调试模式开关,开启时会打印详细信息self.debug = debug# 最大迭代次数,防止无限循环self.max_turns = max_turns# 表信息截断长度,防止过长的表信息影响模型处理self.table_info_truncate = table_info_truncate# 执行结果截断长度,防止过长的执行结果影响模型处理self.execution_truncate = execution_truncate# 如果使用VERL替换配置,则按VERL的方式初始化LLMif verl_replacement is not None:self.model_name: str = verl_replacement["model"] # type: ignoreassert endpoint is not Noneself.llm = init_chat_model(self.model_name,model_provider="openai",openai_api_base=endpoint,openai_api_key=os.environ.get("OPENAI_API_KEY", "dummy"),temperature=verl_replacement["temperature"],max_retries=0,max_tokens=2048,)else:# 否则使用环境变量配置的LLMself.model_name: str = os.environ.get("MODEL", "gpt-4.1-mini")self.llm = init_chat_model(self.model_name,model_provider="openai",openai_api_base=endpoint or os.environ["OPENAI_API_BASE"],openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0,max_retries=1,max_tokens=2048,)"""获取数据库表信息思路注释:1. 尝试从数据库获取表信息2. 如果获取失败则使用备用的数据库模式信息3. 对过长的信息进行截断处理"""def get_table_info(self) -> str:"""Get the table information in a human-readable format."""try:# 尝试从数据库获取表信息table_info = self.db.get_table_info()# 如果表信息过长则进行截断if len(table_info) > self.table_info_truncate:table_info = table_info[: self.table_info_truncate] + "\n... (truncated)"return table_infoexcept Exception as e:logger.error(f"Failed to get table info: {e}")# 如果无法从数据库获取表信息,则使用备用的数据库模式信息if self.db_schema:if len(self.db_schema) > self.table_info_truncate:return self.db_schema[: self.table_info_truncate] + "\n... (truncated)"return self.db_schemareturn "No schema available.""""调用LLM模型处理Prompt思路注释:1. 在调试模式下打印Prompt内容2. 调用LLM模型处理Prompt3. 在调试模式下打印模型响应4. 处理可能的异常情况"""def invoke_prompt(self, prompt: Any) -> AnyMessage:# 如果处于调试模式,打印Prompt内容if self.debug:for message in prompt.messages:termcolor.cprint(message.pretty_repr(), "blue")try:# 调用LLM模型处理Promptresult = self.llm.invoke(prompt)except Exception as e:logger.error(f"Failed to invoke prompt: {e}")# 如果调用失败,使用备用方案生成随机SQL查询# FIXME: fallback to create a random trajectoryresult = self.llm.invoke([HumanMessage(content="Please create a random SQL query as an example.")])# 如果处于调试模式,打印模型响应if self.debug:termcolor.cprint(result.pretty_repr(), "green")return result # type: ignore"""截断执行结果到合理长度思路注释:1. 防止过长的执行结果影响模型处理2. 如果执行结果超过设定的截断长度,则截取前面部分并添加截断标识3. 如果未超过长度则直接返回原结果"""def truncate_execuion(self, execution: str) -> str:"""Truncate the execution result to a reasonable length."""if len(execution) > self.execution_truncate:return execution[: self.execution_truncate] + "\n... (truncated)"return execution"""解析消息中的SQL查询思路注释:1. 使用正则表达式从消息内容中提取SQL查询2. 查找以```开头和结尾的代码块3. 提取代码块中的内容并去除首尾空白4. 如果未找到匹配项则返回None"""def parse_query(self, message: AnyMessage) -> str | None:result: str | None = Nonefor match in re.finditer(r".*```\w*\n(.*?)\n```.*", message.content, re.DOTALL): # type: ignoreresult = match.group(1).strip() # type: ignorereturn result # type: ignore"""生成SQL查询思路注释:1. 使用WRITE_QUERY_PROMPT模板生成Prompt,包含问题和表信息2. 调用LLM模型生成SQL查询3. 解析模型响应中的SQL查询4. 更新状态,包括生成的查询、迭代次数和消息历史"""def write_query(self, state: State) -> State:"""Generate SQL query to fetch information."""prompt: Any = WRITE_QUERY_PROMPT.invoke( # type: ignore{"dialect": self.db.dialect,"input": state["question"],"table_info": self.get_table_info(),})result = self.invoke_prompt(prompt) # type: ignorequery = self.parse_query(result) or result.content # type: ignorereturn { # type: ignore**state,"query": query, # type: ignore"num_turns": 1,"messages": [*prompt.messages, result],}"""执行SQL查询思路注释:1. 使用QuerySQLDatabaseTool工具执行SQL查询2. 获取查询执行结果3. 在调试模式下打印执行结果4. 更新状态,包括执行结果"""def execute_query(self, state: State) -> State:"""Execute SQL query."""execute_query_tool = QuerySQLDatabaseTool(db=self.db)execution_result = execute_query_tool.invoke(state["query"]) # type: ignoreif not isinstance(execution_result, str):# Convert to string if it's not alreadyexecution_result = str(execution_result)if self.debug:termcolor.cprint(execution_result, "yellow")return {**state, "execution": execution_result}"""检查SQL查询的正确性思路注释:1. 使用CHECK_QUERY_PROMPT模板生成Prompt,包含问题、查询、执行结果和表信息2. 调用LLM模型检查SQL查询的正确性3. 获取模型反馈4. 更新状态,包括反馈和消息历史"""def check_query(self, state: State) -> State:"""Check the SQL query for correctness."""prompt: Any = CHECK_QUERY_PROMPT.invoke( # type: ignore{"dialect": self.db.dialect,"input": state["question"],"query": state["query"],"execution": self.truncate_execuion(state["execution"]),"table_info": self.get_table_info(),})result = self.invoke_prompt(prompt) # type: ignoreres = { # type: ignore**state,"feedback": result.content, # type: ignore"messages": [*state.get("messages", []), *prompt.messages, result],}return res # type: ignore"""重写SQL查询思路注释:1. 使用REWRITE_QUERY_PROMPT模板生成Prompt,包含问题、查询、执行结果、反馈和表信息2. 调用LLM模型根据反馈重写SQL查询3. 解析模型响应中的重写查询4. 更新状态,包括重写后的查询、迭代次数和消息历史"""def rewrite_query(self, state: State) -> State:"""Rewrite SQL query if necessary."""prompt: Any = REWRITE_QUERY_PROMPT.invoke( # type: ignore{"dialect": self.db.dialect,"input": state["question"],"query": state["query"],"execution": self.truncate_execuion(state["execution"]),"feedback": state["feedback"],"table_info": self.get_table_info(),})result = self.invoke_prompt(prompt) # type: ignorerewritten_query = self.parse_query(result) # type: ignorereturn {**state,"query": rewritten_query or state["query"],"num_turns": state.get("num_turns", 0) + 1,"messages": [*prompt.messages, result], # clear previous prompts}"""判断是否应该继续执行思路注释:1. 检查最后一条消息是否包含"THE QUERY IS CORRECT",如果包含则结束执行2. 如果同时包含"THE QUERY IS CORRECT"和"THE QUERY IS INCORRECT",则根据最后出现的位置决定是否结束3. 如果迭代次数达到最大值,则结束执行4. 否则继续执行,返回"rewrite_query"以重写查询"""def should_continue(self, state: State) -> Literal[END, "rewrite_query"]: # type: ignore"""Determine if the agent should continue based on the result."""if state["messages"] and isinstance(state["messages"][-1], BaseMessage): # type: ignorelast_message = state["messages"][-1]if "THE QUERY IS CORRECT" in last_message.content: # type: ignoreif "THE QUERY IS INCORRECT" in last_message.content: # type: ignore# Both correct and incorrect messages found# See which is the last onecorrect_index = last_message.content.rfind("THE QUERY IS CORRECT") # type: ignoreincorrect_index = last_message.content.rfind("THE QUERY IS INCORRECT") # type: ignoreif correct_index > incorrect_index:return ENDelse:return ENDif state.get("num_turns", 0) >= self.max_turns:return ENDreturn "rewrite_query"def graph(self) -> CompiledStateGraph[State]:"""构建并返回 SQL 代理的状态图(StateGraph)。思路:1. 创建一个状态图构建器,使用自定义的 State 类作为状态类型2. 添加四个节点分别对应代理的主要功能:- write_query: 生成 SQL 查询- execute_query: 执行 SQL 查询- check_query: 检查查询正确性- rewrite_query: 重写查询(当检查发现错误时)3. 定义节点间的连接关系:- 从起始节点连接到 write_query- write_query -> execute_query -> check_query- check_query 根据检查结果条件性地连接到 rewrite_query 或结束- rewrite_query 重新连接到 execute_query 形成循环4. 编译并返回状态图返回:CompiledStateGraph[State]: 编译后的状态图,可用于执行 SQL 查询生成和验证流程"""builder = StateGraph(State)builder.add_node(self.write_query) # type: ignorebuilder.add_node(self.execute_query) # type: ignorebuilder.add_node(self.check_query) # type: ignorebuilder.add_node(self.rewrite_query) # type: ignorebuilder.add_edge(START, "write_query")builder.add_edge("write_query", "execute_query")builder.add_edge("execute_query", "check_query")builder.add_conditional_edges("check_query",self.should_continue, # type: ignore)builder.add_edge("rewrite_query", "execute_query")return builder.compile() # type: ignoredef evaluate_query(query: str, ground_truth: str, database: str, raise_on_error: bool = True) -> float:"""评估生成的SQL查询与标准答案的匹配程度。思路注释:1. 使用Spider数据集提供的eval_exec_match函数来评估查询结果2. 首先检查数据库文件是否存在3. 调用eval_exec_match函数进行评估,返回执行匹配得分4. 根据得分返回奖励值(1.0表示完全匹配,0.0表示不匹配)5. 处理可能的异常情况,根据raise_on_error参数决定是否抛出异常参数:query (str): 生成的SQL查询语句ground_truth (str): 标准答案SQL查询语句database (str): 数据库文件路径raise_on_error (bool): 是否在出现异常时抛出异常,默认为True返回:float: 奖励值,1.0表示完全匹配,0.0表示不匹配"""# TODO(yuge): Maybe we can evaluate intermediate queries and assign more precise rewards.# included in the original evaluation script# query = query.replace("value", "1")try:database = os.path.abspath(database)if not os.path.exists(database):raise FileNotFoundError(f"Database file {database} does not exist.")# Parameters following the default settingexec_score = eval_exec_match(db=database,p_str=query,g_str=ground_truth,plug_value=False,keep_distinct=False,progress_bar_for_each_datapoint=False,)if exec_score == 1:return 1.0else:return 0.0except Exception as e:if raise_on_error:raiseelse:logger.exception(f"Error evaluating query: {e}")return 0.0class LitSQLAgent(agentlightning.LitAgent[Any]):"""基于AgentLightning框架的SQL代理类,用于训练和验证SQL生成代理思路注释:1. 继承自agentlightning.LitAgent,实现训练和验证的rollout方法2. 配置训练参数,如最大迭代次数、截断长度等3. 处理训练和验证数据的执行流程"""def __init__(self,trained_agents: Optional[str] = r"write",val_temperature: Optional[float] = None,max_turns: int = 3,table_info_truncate: int = 2048,execution_truncate: int = 2048,) -> None:"""初始化LitSQLAgent实例思路注释:1. 调用父类初始化方法2. 设置验证时的温度参数3. 配置Spider数据集目录4. 设置最大迭代次数和截断长度参数参数:trained_agents (Optional[str]): 训练的代理名称,默认为"write"val_temperature (Optional[float]): 验证时的温度参数,默认为Nonemax_turns (int): 最大迭代次数,默认为3table_info_truncate (int): 表信息截断长度,默认为2048execution_truncate (int): 执行结果截断长度,默认为2048"""super().__init__(trained_agents=trained_agents)self.val_temperature = val_temperatureself.spider_dir = os.environ.get("VERL_SPIDER_DATA_DIR", "data")self.max_turns = max_turnsself.table_info_truncate = table_info_truncateself.execution_truncate = execution_truncatedef _execute_rollout(self, sample: dict[str, Any], *, resources: agentlightning.NamedResources, rollout_id: str, is_training: bool) -> float | None:"""执行一次rollout,用于训练或验证SQL代理思路注释:1. 从样本数据中提取问题和标准答案2. 根据是训练还是验证阶段,确定数据库文件路径3. 检查数据库文件是否存在,如果不存在则跳过4. 读取数据库模式信息5. 创建临时目录并在其中复制数据库文件6. 初始化SQL代理并执行查询生成流程7. 评估生成的查询并计算奖励8. 记录执行时间和评估结果参数:sample (dict[str, Any]): 样本数据,包含问题、数据库ID和标准答案resources (agentlightning.NamedResources): 资源对象,包含LLM等资源rollout_id (str): rollout的唯一标识符is_training (bool): 是否为训练阶段返回:float | None: 奖励值,如果出错则返回None"""question = sample["question"]start_time = time.time()llm: agentlightning.LLM = cast(agentlightning.LLM, resources["main_llm"])if is_training:original_db_path = os.path.join(self.spider_dir, "database", sample["db_id"], sample["db_id"] + ".sqlite")else:original_db_path = os.path.join(self.spider_dir, "test_database", sample["db_id"], sample["db_id"] + ".sqlite")ground_truth = sample["query"]if not os.path.exists(original_db_path):logger.error(f"Database {original_db_path} does not exist. Skipping.")return Noneschema_path = os.path.join(os.path.dirname(original_db_path), "schema.sql")if os.path.exists(schema_path):with open(schema_path, "r") as f:schema = f.read()else:logger.error("Schema file not found: %s", schema_path)schema = "No schema available."with tempfile.TemporaryDirectory() as temp_dir:db_path = os.path.join(temp_dir, os.path.basename(original_db_path))shutil.copyfile(original_db_path, db_path)logger.info(f"[Rollout {rollout_id}] Question: {question}")logger.info(f"[Rollout {rollout_id}] Ground Truth: {ground_truth}")# Run the agentagent = SQLAgent("sqlite:///" + db_path,max_turns=self.max_turns,table_info_truncate=self.table_info_truncate,execution_truncate=self.execution_truncate,debug=False,db_schema=schema,endpoint=llm.endpoint,verl_replacement=({"model": llm.model, **llm.sampling_parameters}if is_trainingelse {"model": llm.model,"temperature": (self.val_temperatureif self.val_temperature is not Noneelse llm.sampling_parameters.get("temperature", 0.0)),}),).graph()try:result = agent.invoke( # type: ignore{"question": question}, # type: ignore{"callbacks": [self.tracer.get_langchain_callback_handler()], "recursion_limit": 100}, # type: ignore)except Exception as e:logger.exception(f"[Rollout {rollout_id}] Error during agent invocation: {e}")returnlogger.info(f"[Rollout {rollout_id}] Generated Query: {result['query']}")end_time_rollout = time.time()with tempfile.TemporaryDirectory() as temp_dir:db_path = os.path.join(temp_dir, os.path.basename(original_db_path))shutil.copyfile(original_db_path, db_path)reward = evaluate_query(result["query"], ground_truth, db_path, raise_on_error=False)logger.info("[Rollout %s] Reward: %s", rollout_id, reward)end_time_eval = time.time()logger.info("[Rollout %s] Time taken for rollout: %.2f seconds", rollout_id, end_time_rollout - start_time)logger.info("[Rollout %s] Time taken for evaluation: %.2f seconds", rollout_id, end_time_eval - end_time_rollout)return rewarddef training_rollout(self, task: Any, rollout_id: str, resources: agentlightning.NamedResources) -> Any: # type: ignore"""训练阶段的rollout方法思路注释:1. 调用_execute_rollout方法执行训练阶段的rollout2. 传入is_training=True参数标识为训练阶段参数:task (Any): 训练任务数据rollout_id (str): rollout的唯一标识符resources (agentlightning.NamedResources): 资源对象,包含LLM等资源返回:Any: _execute_rollout方法的返回结果"""return self._execute_rollout(task, resources=resources, rollout_id=rollout_id, is_training=True)def validation_rollout(self, task: Any, rollout_id: str, resources: agentlightning.NamedResources) -> Any: # type: ignore"""验证阶段的rollout方法思路注释:1. 调用_execute_rollout方法执行验证阶段的rollout2. 传入is_training=False参数标识为验证阶段参数:task (Any): 验证任务数据rollout_id (str): rollout的唯一标识符resources (agentlightning.NamedResources): 资源对象,包含LLM等资源返回:Any: _execute_rollout方法的返回结果"""return self._execute_rollout(task, resources=resources, rollout_id=rollout_id, is_training=False)def spider_dev_data():"""加载Spider数据集的开发数据用于测试思路注释:1. 从环境变量VERL_SPIDER_DATA_DIR或默认的"data"目录中读取dev.parquet文件2. 检查文件是否存在,如果不存在则抛出异常3. 使用pandas读取parquet文件4. 检查环境变量OPENAI_API_BASE是否设置,如果没有设置则使用默认值5. 创建LLM资源配置6. 返回包含前10条数据记录和资源的DevTaskLoader对象返回:agentlightning.DevTaskLoader: 包含开发数据和资源的加载器对象"""# Read from dev.parquetimport pandas as pdspider_dev_data_path = os.path.join(os.environ.get("VERL_SPIDER_DATA_DIR", "data"), "dev.parquet")if not os.path.exists(spider_dev_data_path):raise FileNotFoundError(f"Spider dev data file {spider_dev_data_path} does not exist.")df = pd.read_parquet(spider_dev_data_path) # type: ignoreif "OPENAI_API_BASE" not in os.environ:logger.warning("Environment variable OPENAI_API_BASE is not set. Using default value 'https://api.openai.com/v1'.")openai_api_base = "https://api.openai.com/v1"else:openai_api_base = os.environ["OPENAI_API_BASE"]resource = {"main_llm": agentlightning.LLM(model="gpt-4.1-nano",endpoint=openai_api_base,sampling_parameters={"temperature": 0.0,},)}return agentlightning.DevTaskLoader(df.head(10).to_dict(orient="records"), resource) # type: ignoreif __name__ == "__main__":dotenv.load_dotenv()agent, trainer = agentlightning.lightning_cli(LitSQLAgent, agentlightning.Trainer)trainer.fit(agent, os.environ["VERL_API_BASE"], dev_data=spider_dev_data())