顶级 AI 模型横评:智能、性能与价格等方面全面对比
前言

人工智能分析智能指数(Artificial Analysis Intelligence Index)第 3.0 版 由 Artificial Analysis 团队在专用硬件环境中独立测试完成,覆盖全球范围,并采用 CC BY 4.0 开源许可(可自由使用但需署名)。该指数综合了 10 个关键评估项目——MMLU-Pro、GPQA Diamond、Humanity’s Last Exam、LiveCodeBench、SciCode、AIME 2025、IFBench、AA-LCR、Terminal-Bench Hard、𝜏²-Bench Telecom——用于全面衡量大型语言模型(LLMs)的综合智能表现。作为一个多维度的智能评测体系,它涵盖推理能力、科学与编程能力、任务执行、长期推理及行业专业智能等核心指标,是目前最直接、最具代表性的模型智力对比标准。
综合对比如下:
人工智能分析智能指数(Artificial Analysis Intelligence Index)
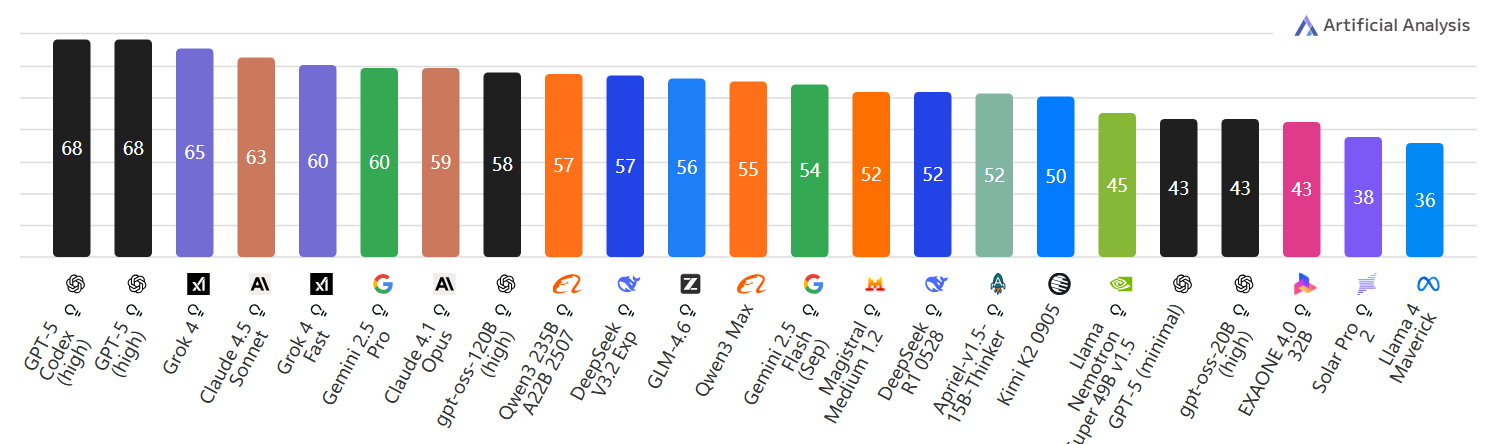
Reasoning vs Non-Reasoning(推理型 vs 非推理型)
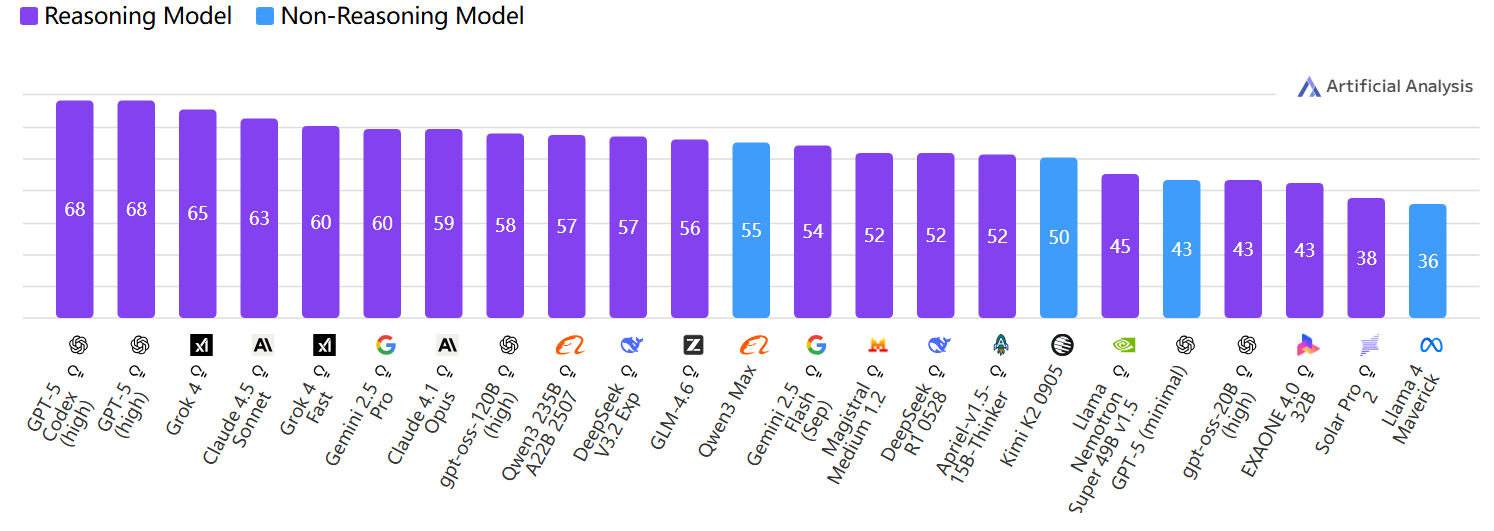
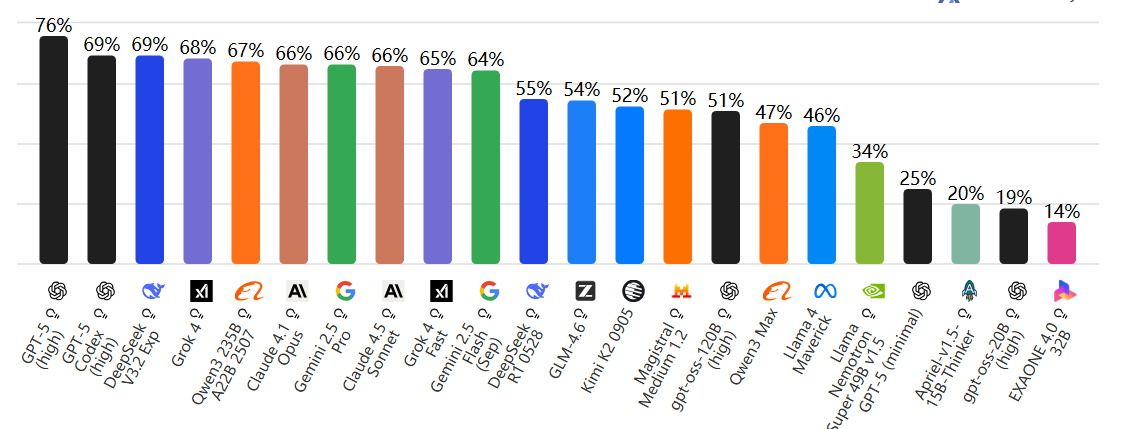
Open Weights vs Proprietary(开源权重 vs 专有模型)
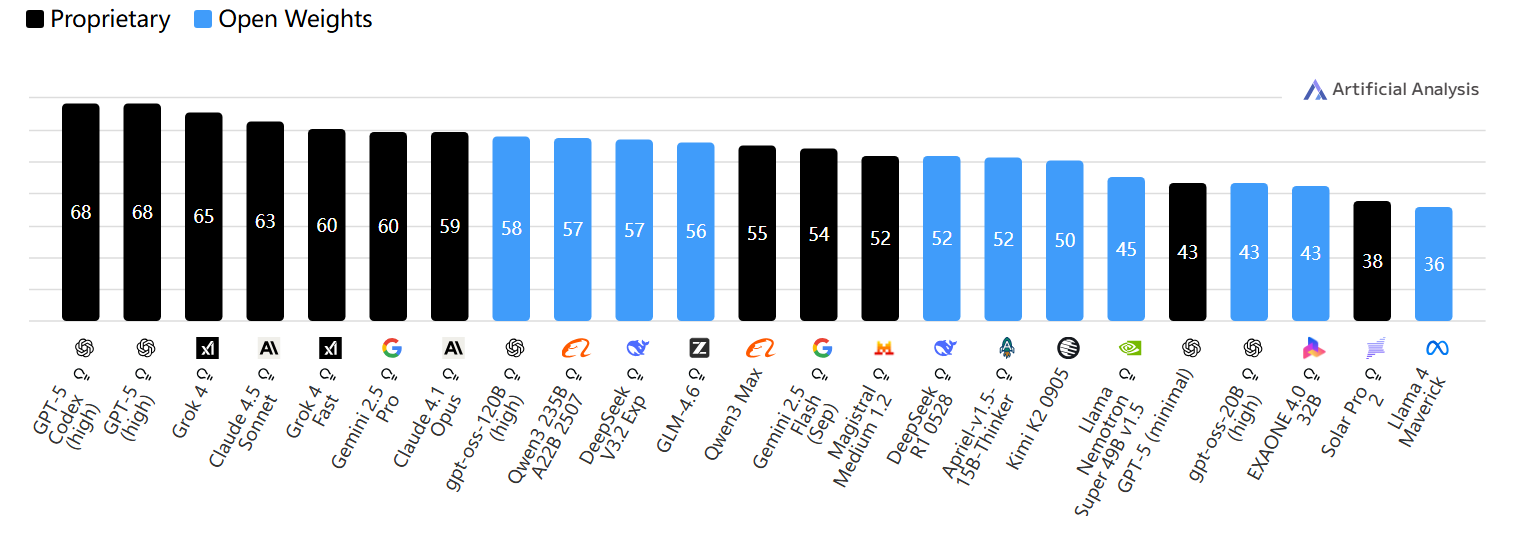
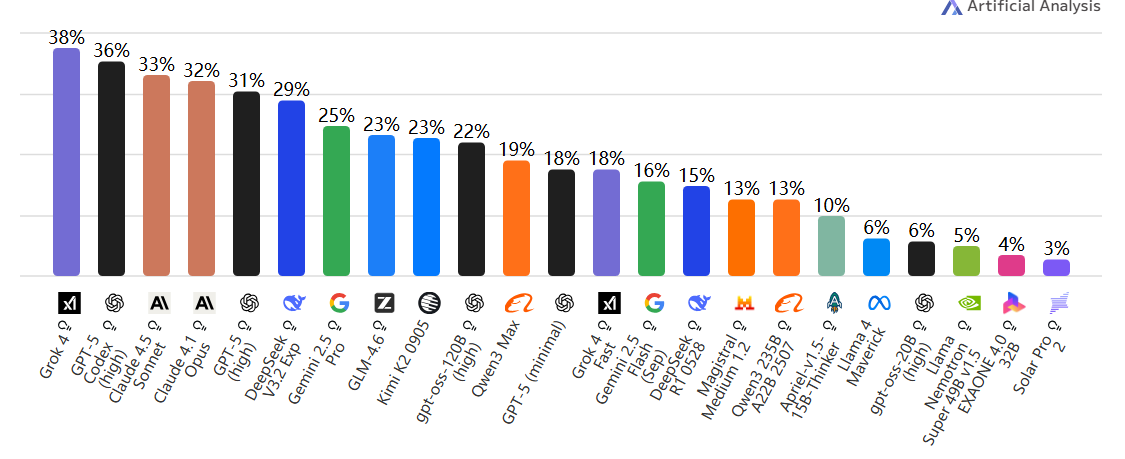
Coding Index(代码智能指数)
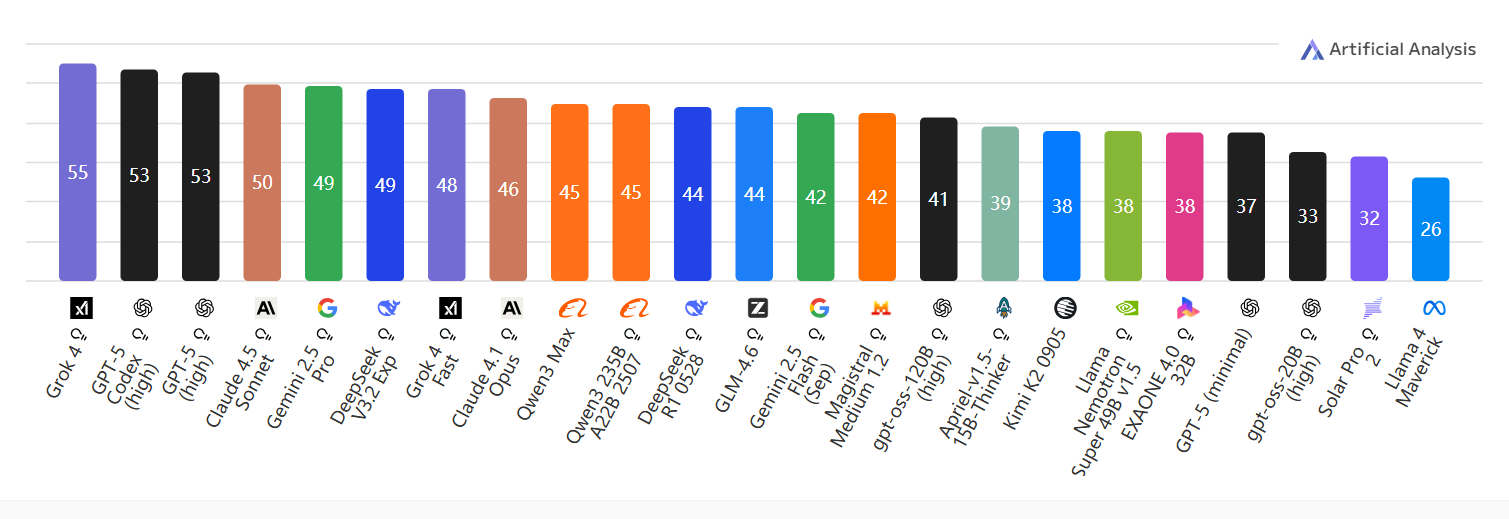
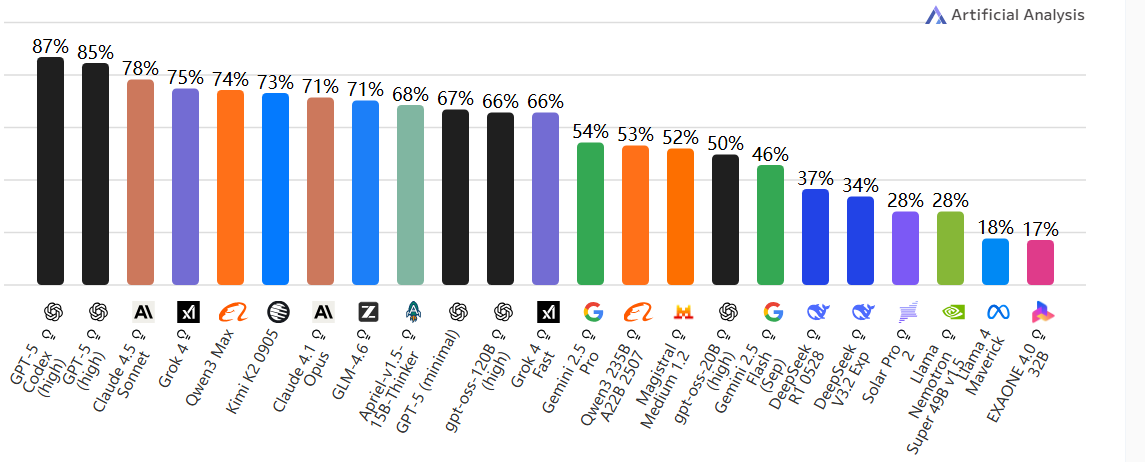
Agentic Index(自主体智能指数)
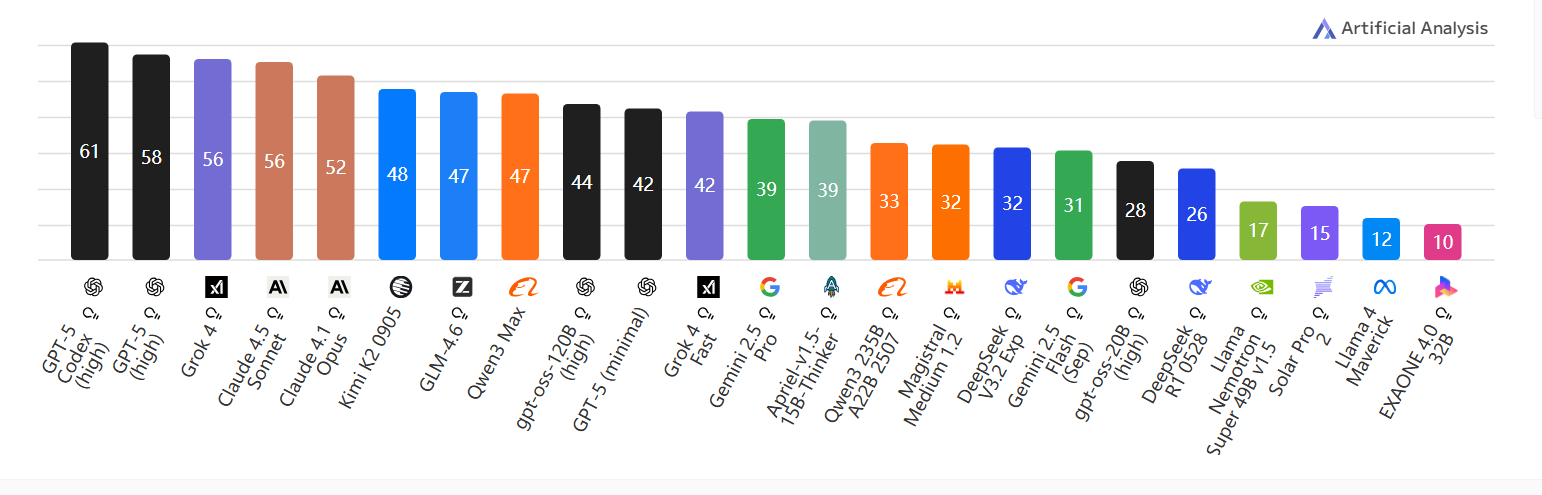
智能评估
由 Artificial Analysis 独立测量的智能评估结果;数值越高代表智能表现越好
Terminal-Bench Hard
📘 含义:终端操作评测(高难度版)。
🧩 内容:AI 通过命令行(Linux shell)执行真实任务。
🧠 测试 AI 的系统操作与工程执行能力。
💻 比如“安装软件、解析日志、写脚本”等。
τ²-Bench Telecom
📘 含义:Tau-square Benchmark for Telecom Intelligence
🧩 内容:电信领域特定任务,如网络流量分析、异常检测、信号优化。
🧠 测试 AI 在行业应用场景(特别是通信安全、网络管理)下的表现。
📡 面向“垂直行业智能”。
AA-LCR
📘 含义:Agent Arena – Long Context Reasoning
🧩 内容:在多轮长上下文对话中进行任务推理。
🧠 测试 AI 的长期记忆与多步推理能力。
🧭 看 AI 是否能“记住前文、持续理解场景”。
Humanity’s Last Exam
📘 含义:人类最后考试。
🧩 内容:哲学、伦理、科学、社会决策、价值判断。
🧠 测试 AI 在人类核心认知、道德和长远推理方面的表现。
💬 类似“AI 能否像人一样做复杂思考”的考试。
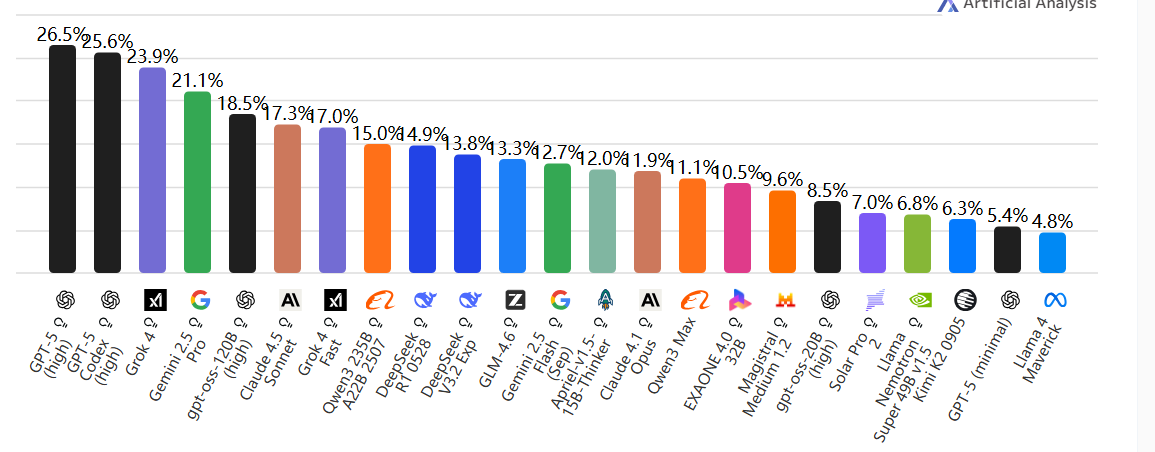
MMLU-Pro(Massive Multitask Language Understanding Pro)
📘 含义:多任务语言理解专业版。
🧩 测试内容:涵盖从中学到博士水平的 57+ 学科(物理、法律、历史、医学等)。
🧠 用途:衡量模型的广泛知识覆盖面和理解力。
💬 类似“AI 的大学综合考试”。
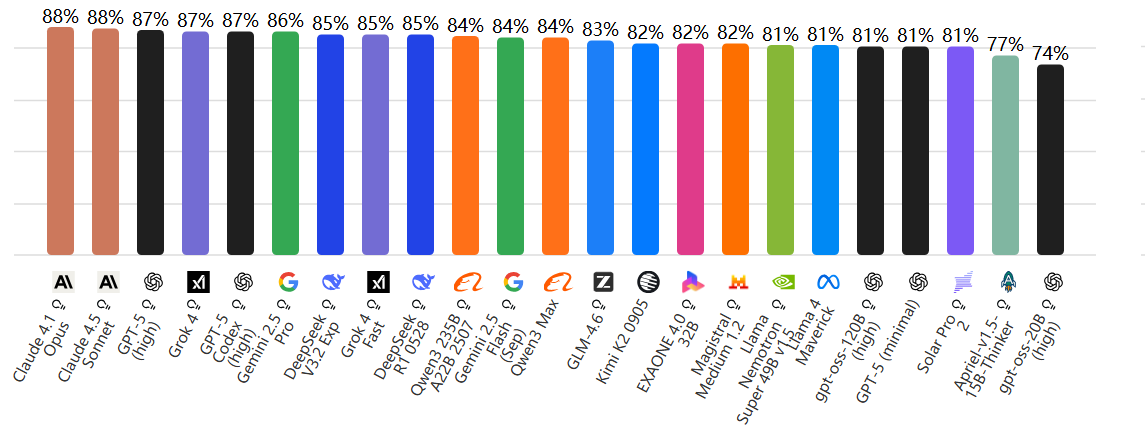
GPQA Diamond
📘 含义:Graduate-level Google-Proof Question Answering(研究生级别难度、无法直接搜索答案的问题)。
🧩 内容:物理、数学、生物等深层科学问题。
🧠 测试 AI 的推理与知识整合能力。
💎 “Diamond”表示最高难度版本。
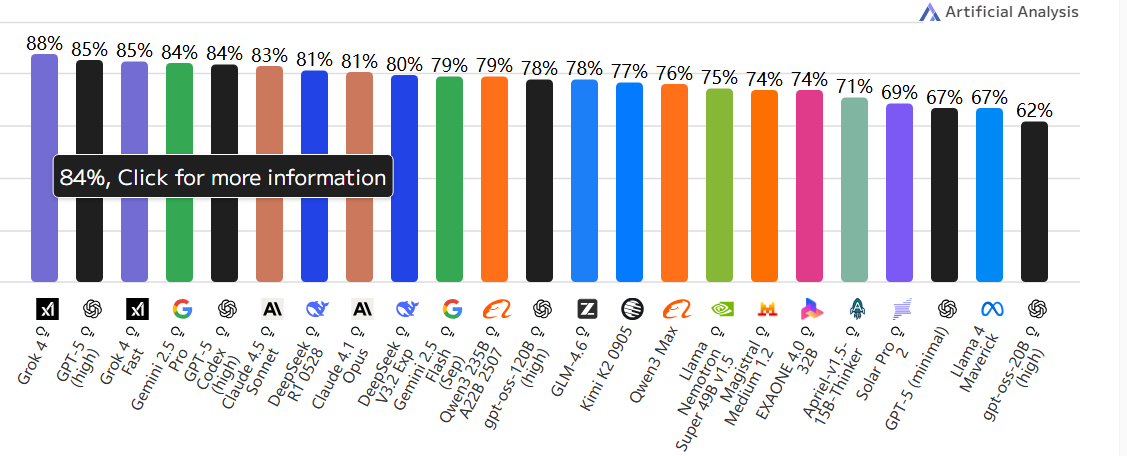
LiveCodeBench
📘 含义:动态代码生成与执行评测。
🧩 内容:AI 生成并执行代码来解决实时任务。
🧠 测试 AI 的编程能力与执行正确率。
💻 类似“在线编程竞赛”。
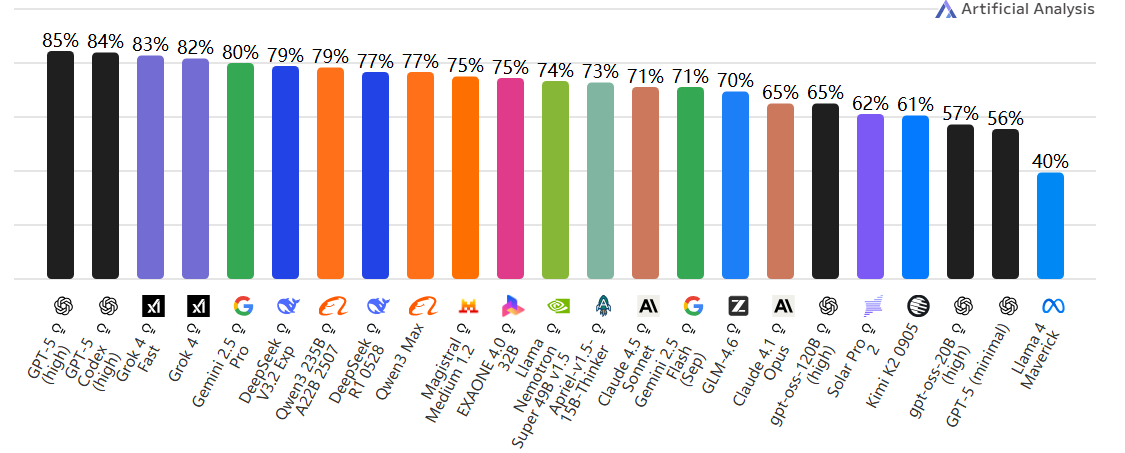
SciCode
📘 含义:科学计算与算法实现测试。
🧩 内容:涉及物理模拟、数学推导、统计建模等。
🧠 测试 AI 的科学计算与逻辑思维能力。
⚗️ 更偏“科研助理级编程智能”。
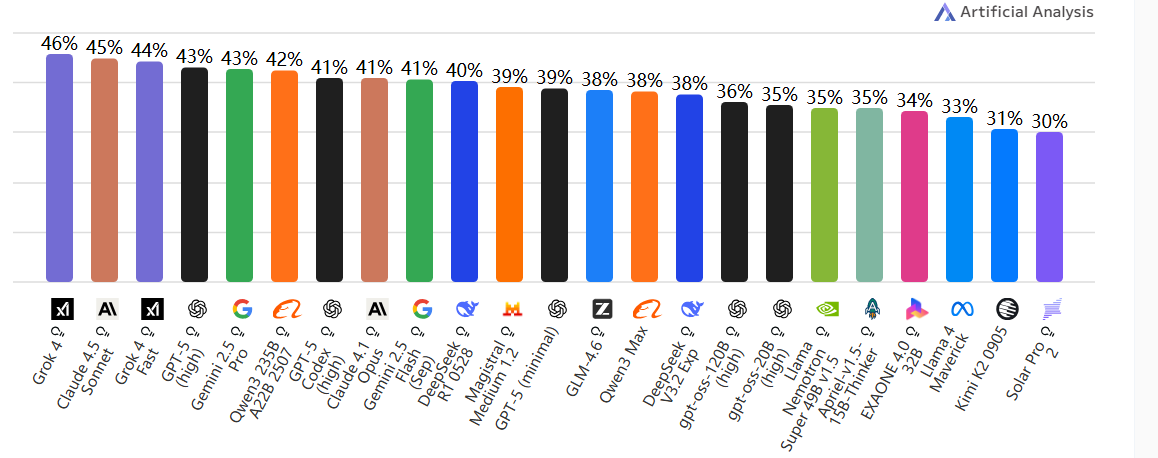
IFBench
📘 含义:Instruction Following Benchmark。
🧩 内容:测试模型对复杂指令的理解与执行能力。
🧠 关注“AI 是否真的听得懂人话”,能否准确执行多层逻辑任务。
💬 类似现实应用中的任务自动化测试。
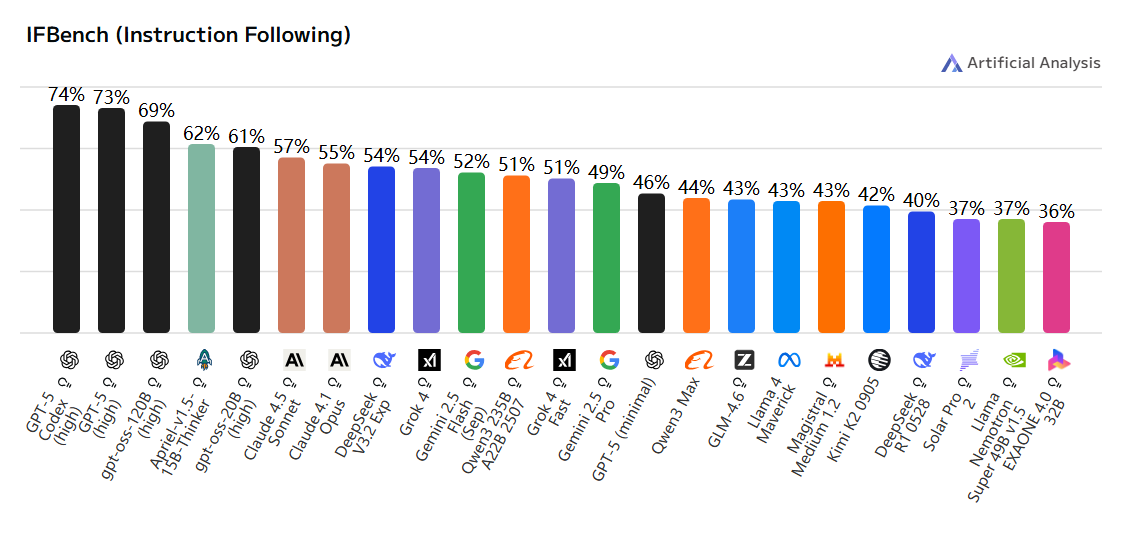
AIME 2025
📘 含义:American Invitational Mathematics Examination(美国邀请数学竞赛)。
🧩 内容:奥数级推理题。
🧠 测试 AI 的数学创造力与精确推理。
🧮 高难度数学 reasoning benchmark。
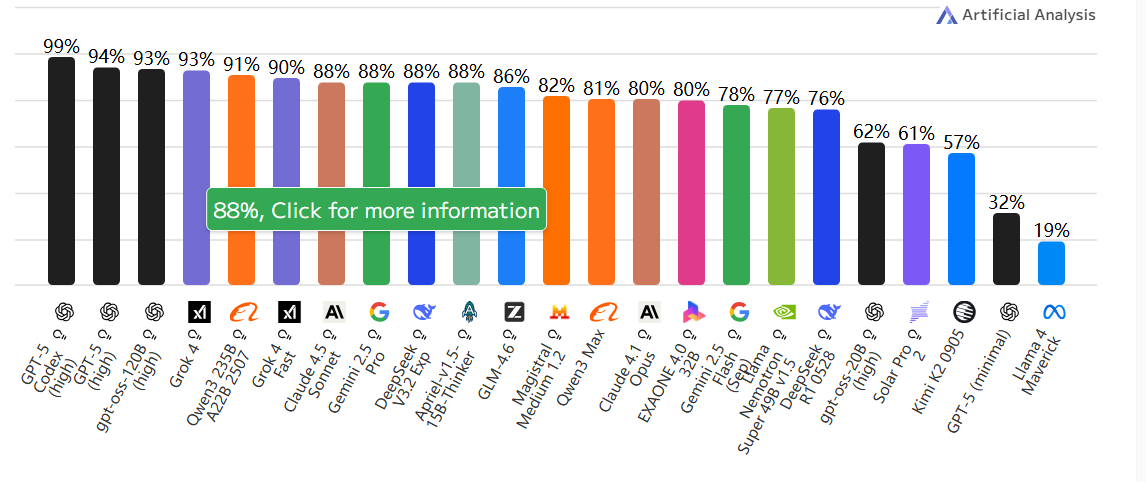
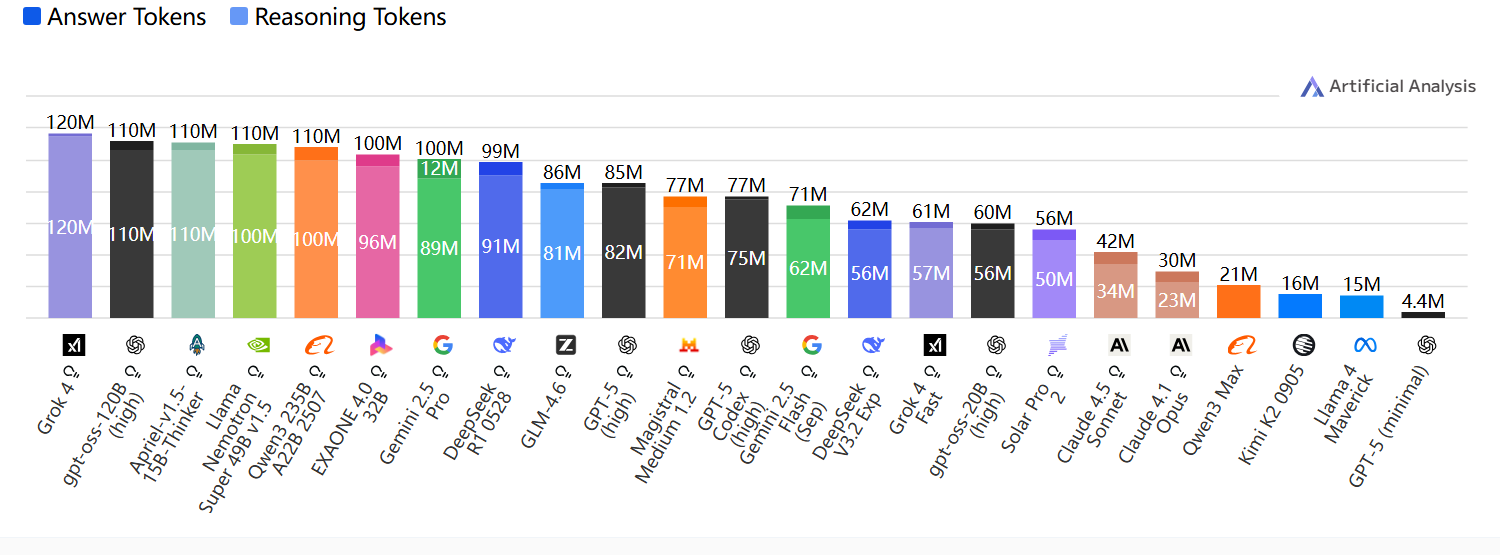
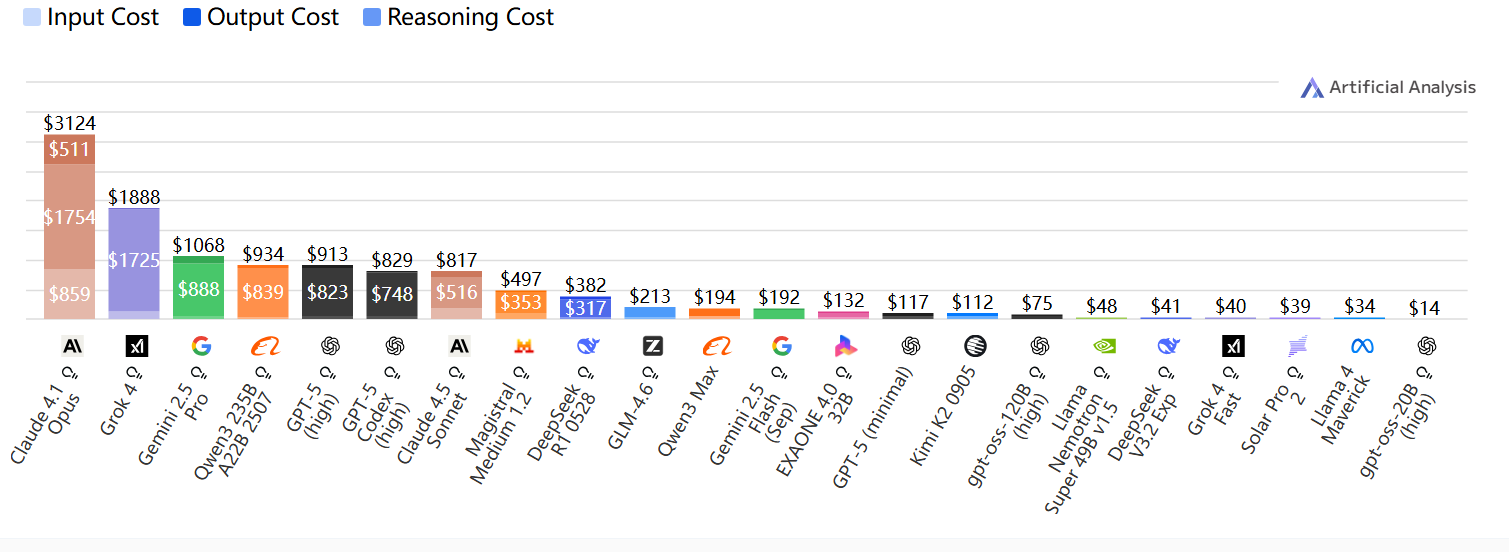
智能指数Token与使用成本
运行人工分析智能指数中所有评估所使用的Token
运行人工分析智能指数的费用(美元)
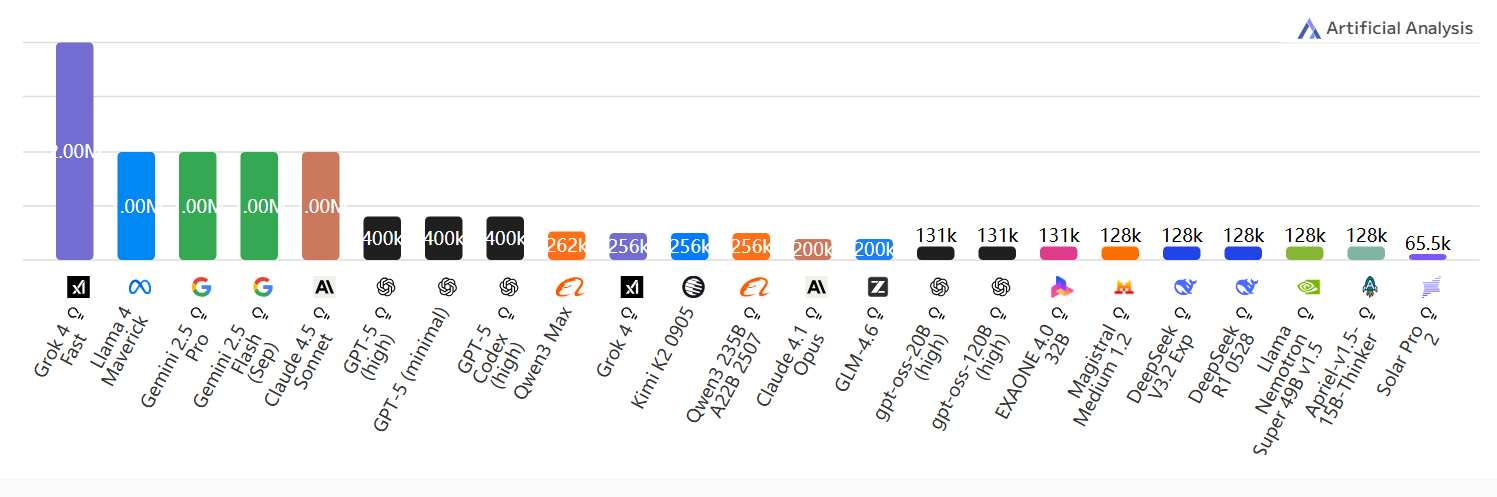
上下文窗口
上下文窗口:Token限制;数值越高越好
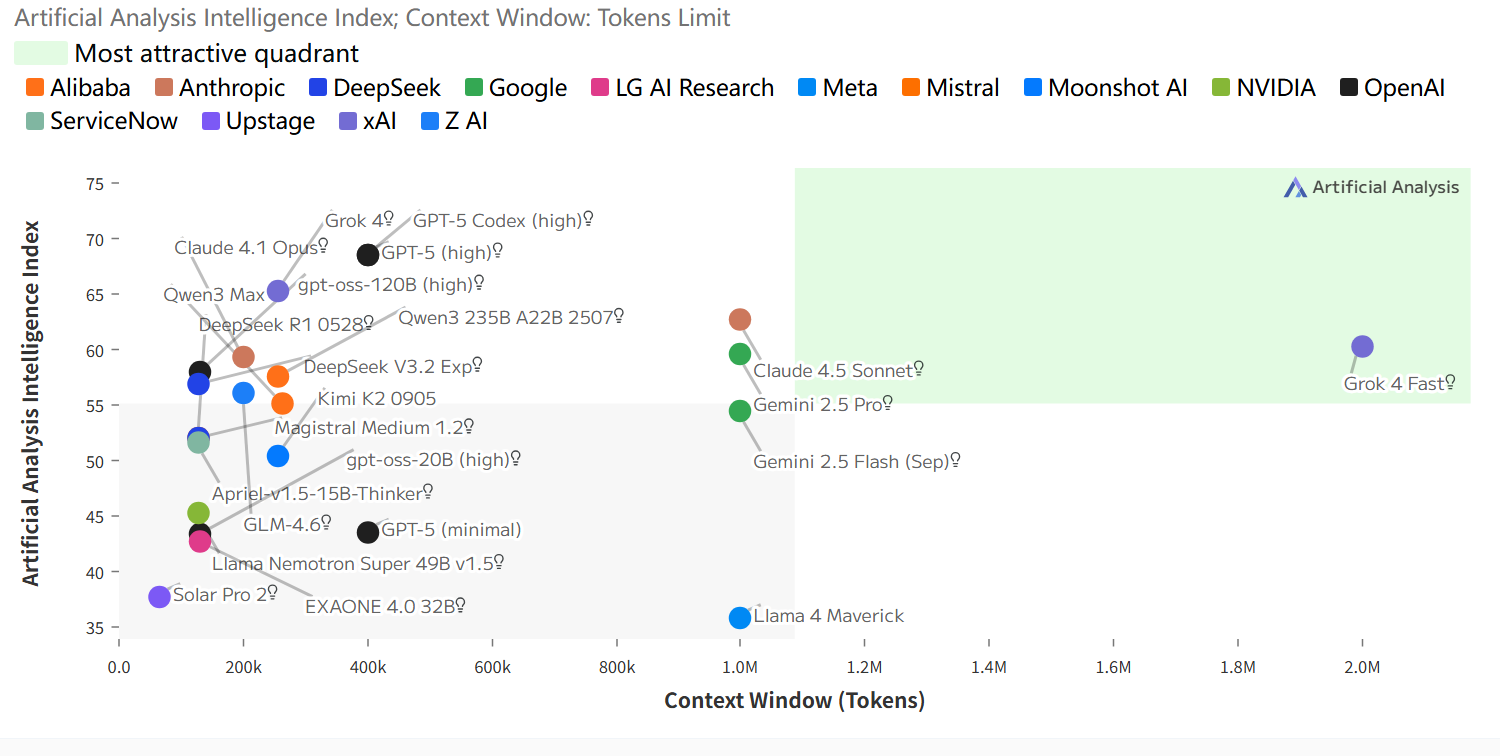
智能指数与上下文窗口的关系
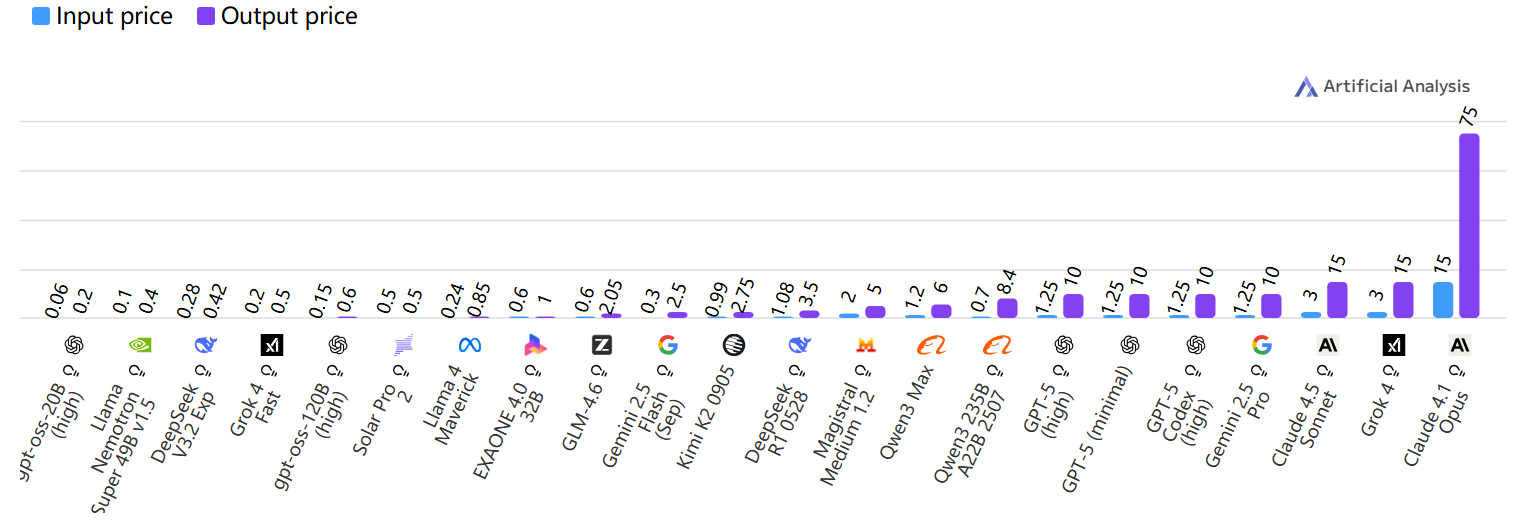
价格
输入与输出价格
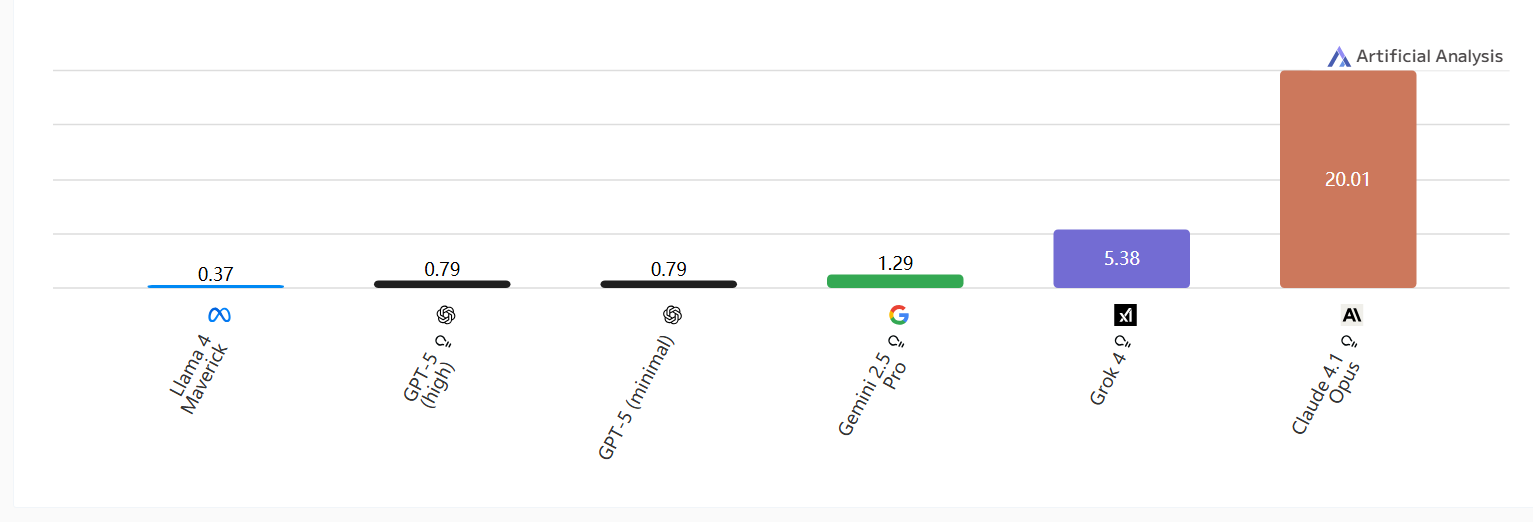
图像输入价格
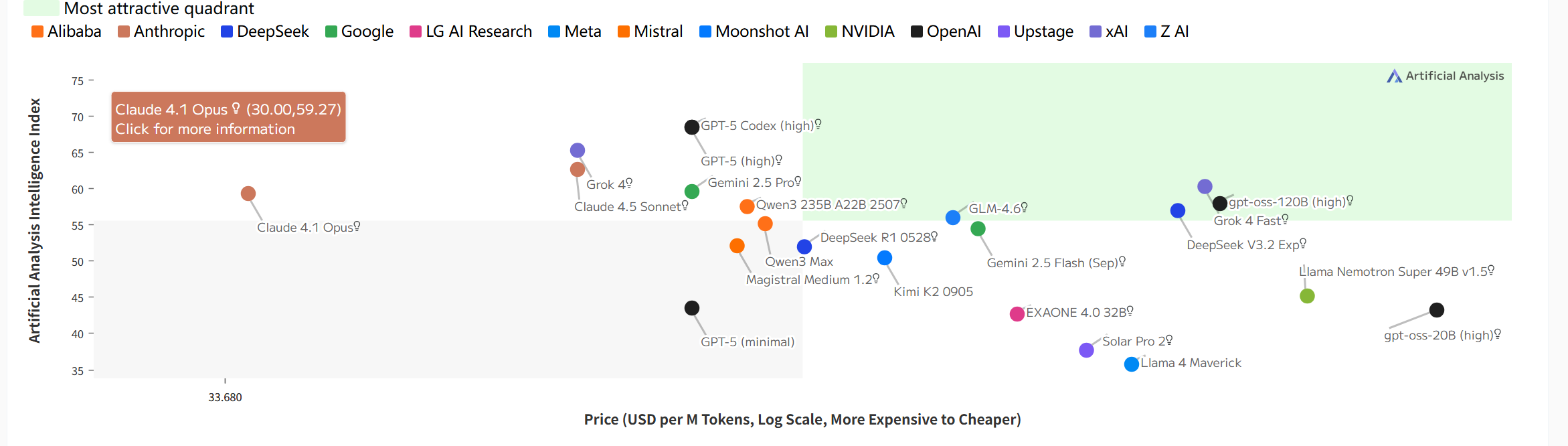
智能指数与价格(对数刻度)
速度
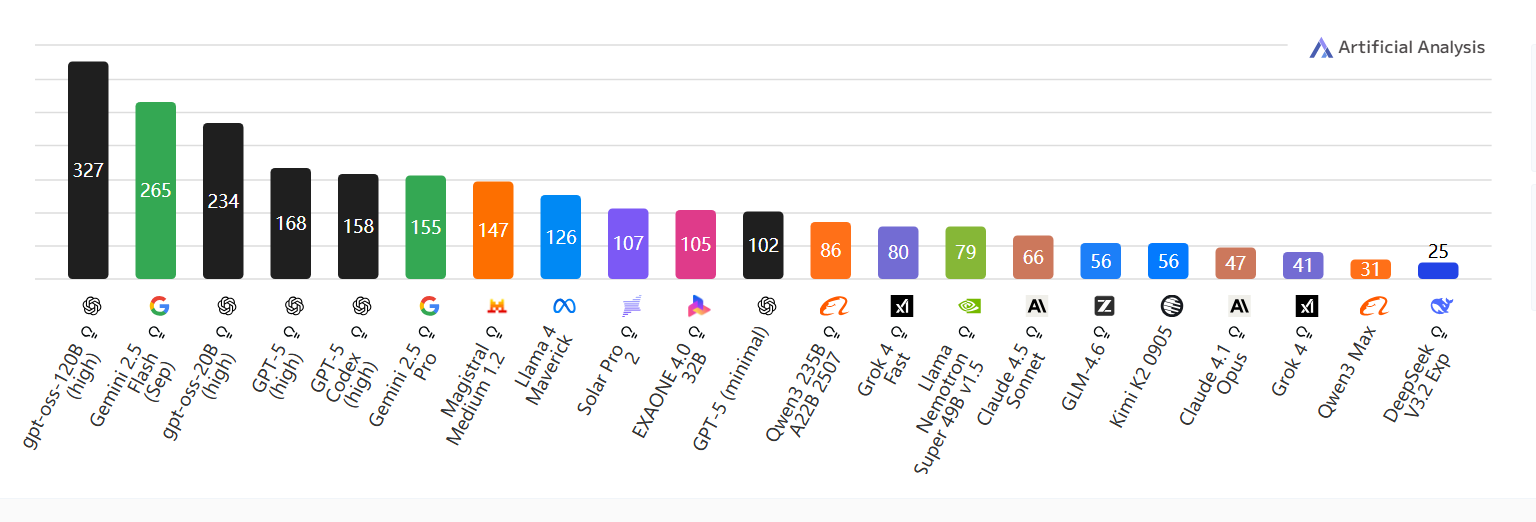
输出速度
每秒输出代Token ;数值越高越好
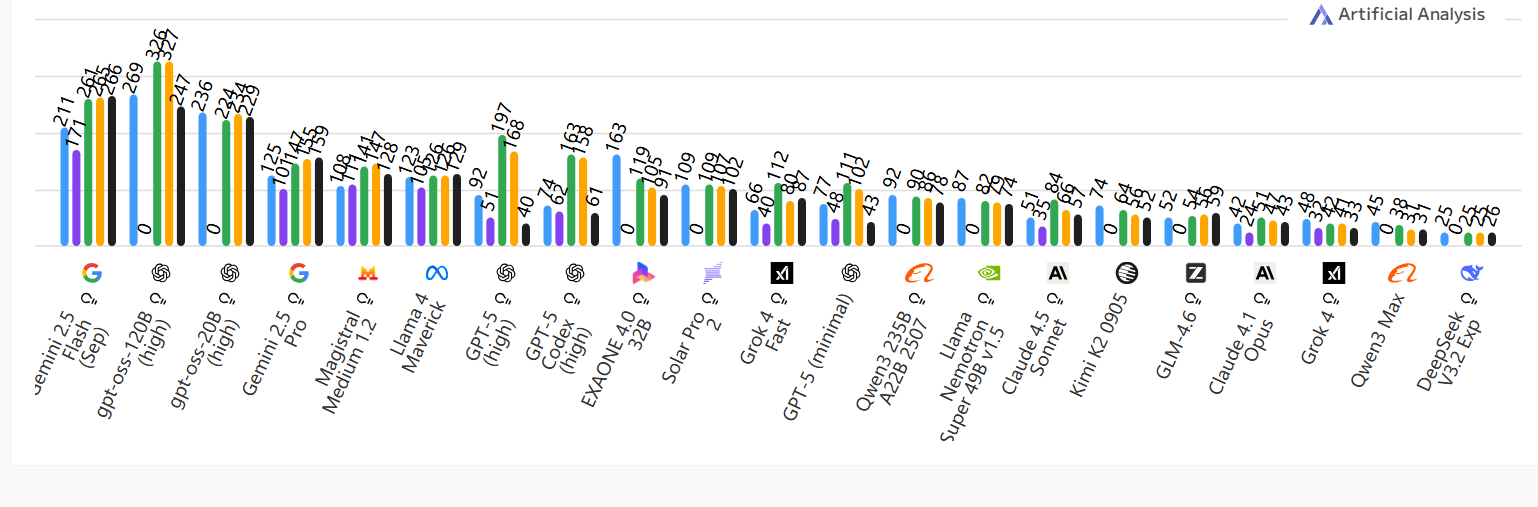
按输入Token 数量(上下文长度)计算的输出速度
每秒输出代Token ;数值越高越好
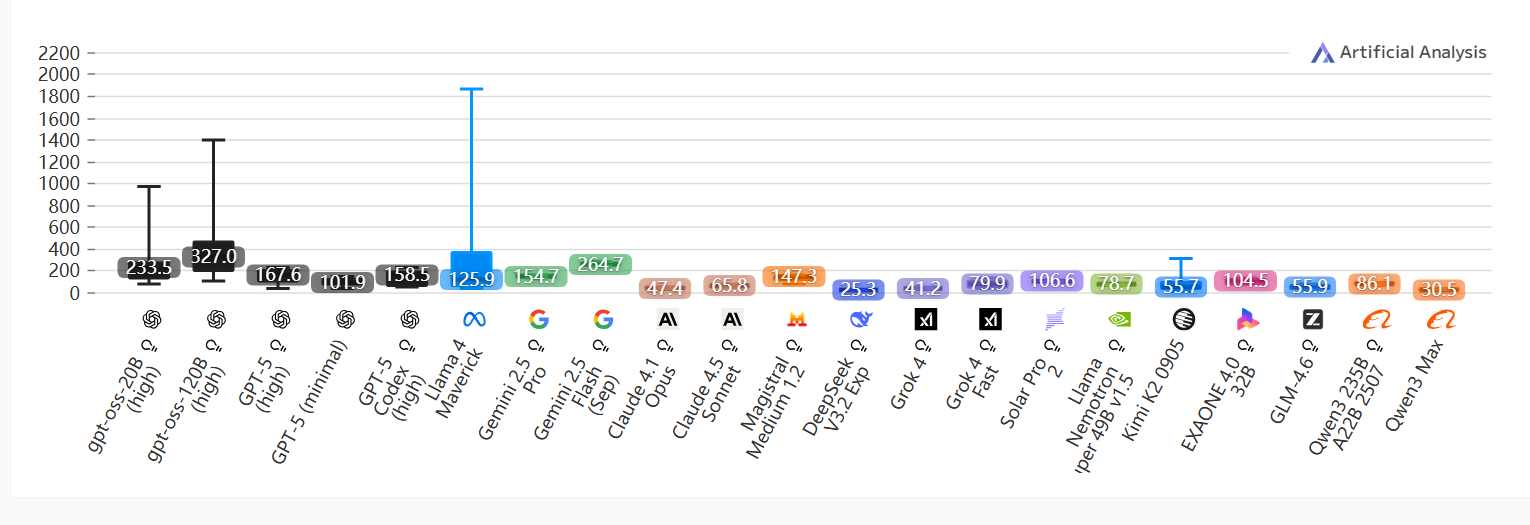
输出速度差异
每秒输出Token 数;按百分位显示结果;数值越高越好
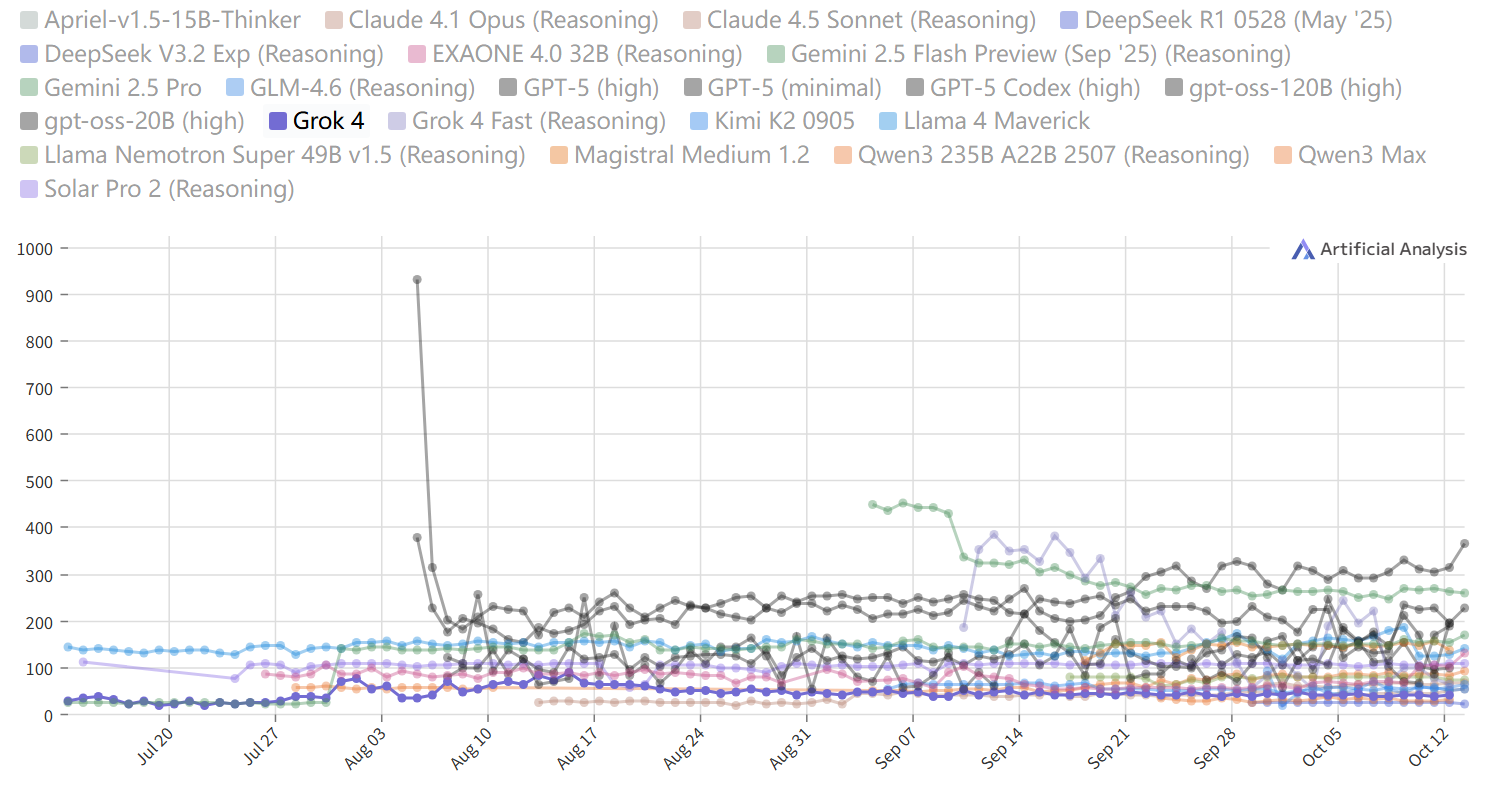
输出速度随时间变化
速度比较
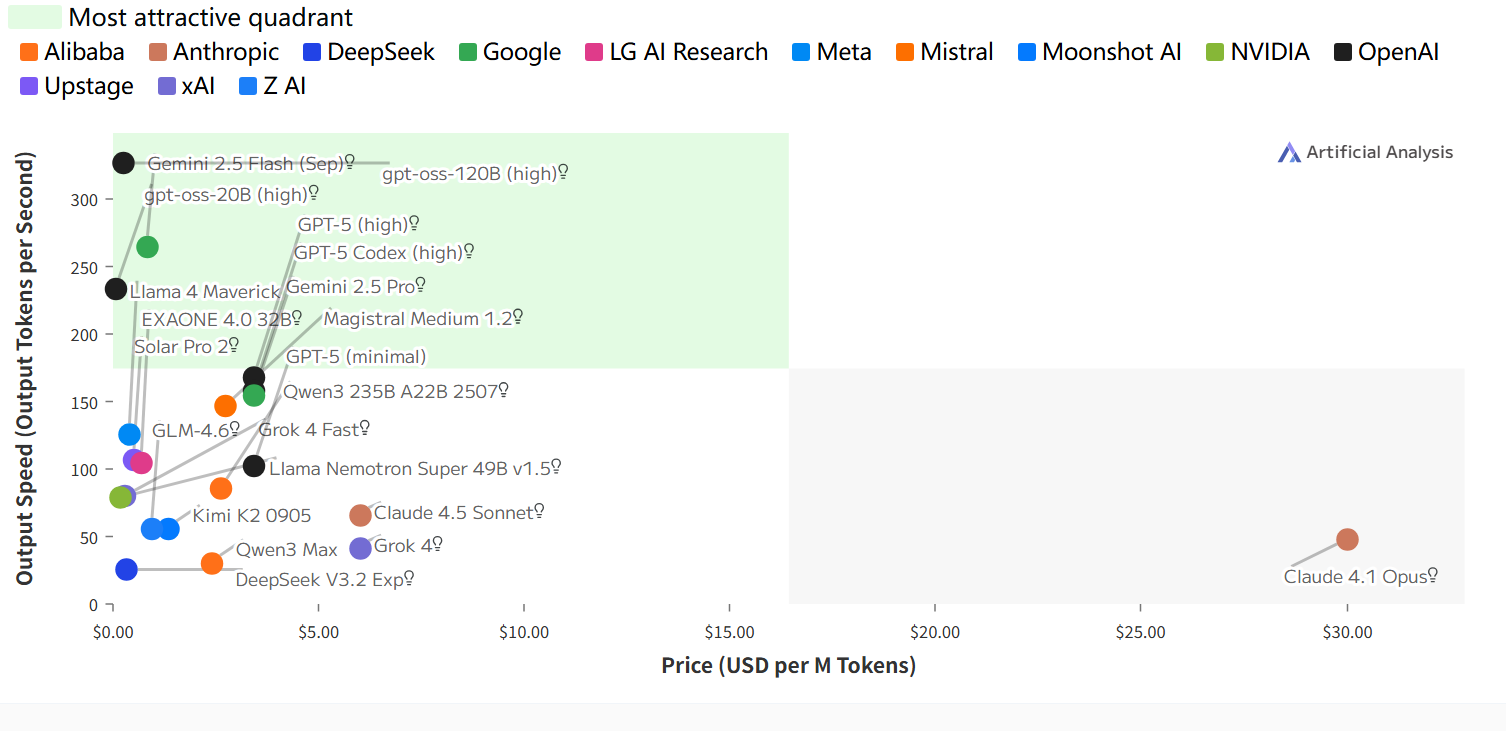
输出速度和价格
输出速度:每秒输出Token数;
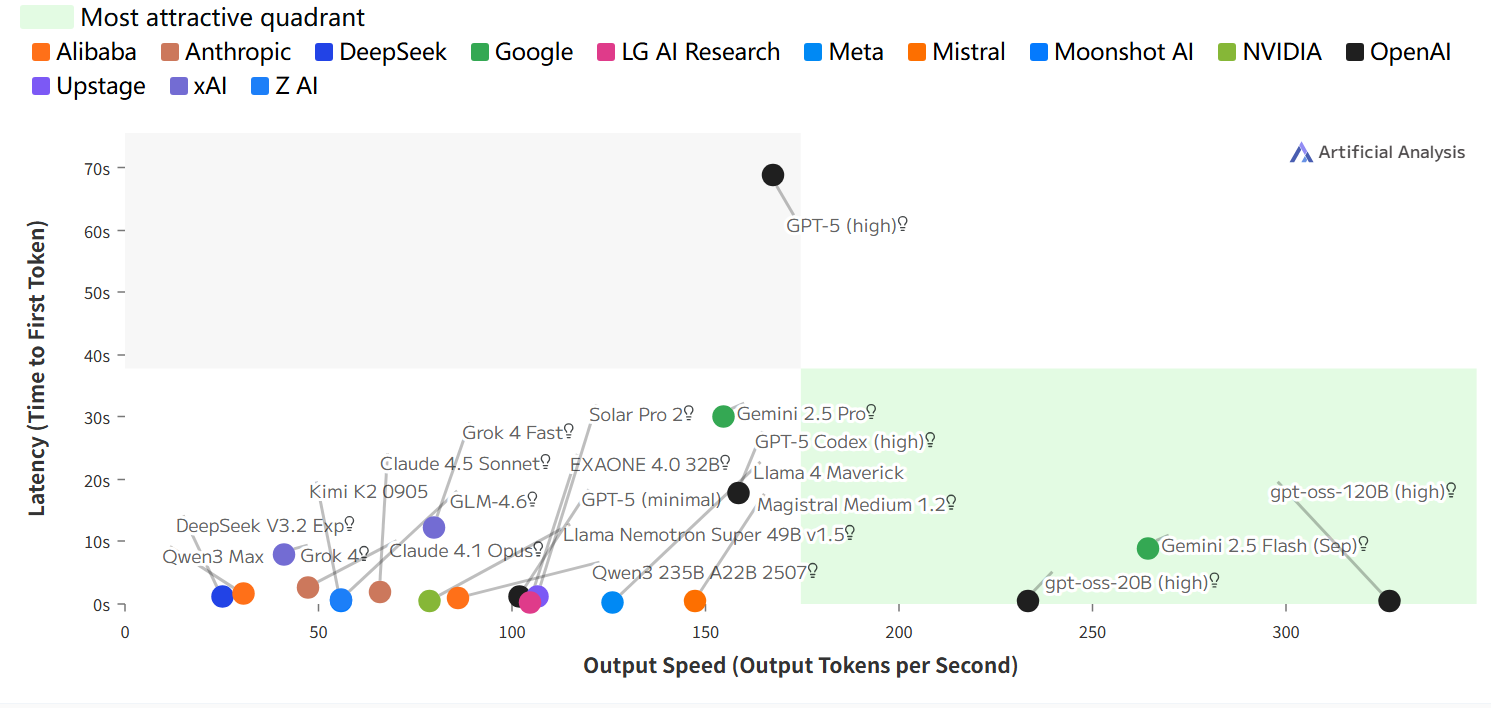
延迟与输出速度
延迟:接收到第一个Token所需的时间(秒);
输出速度:每秒输出Token数
延迟
接收第一个Token所需时间
接收到第一个Token所需时间(秒);数值越低越好
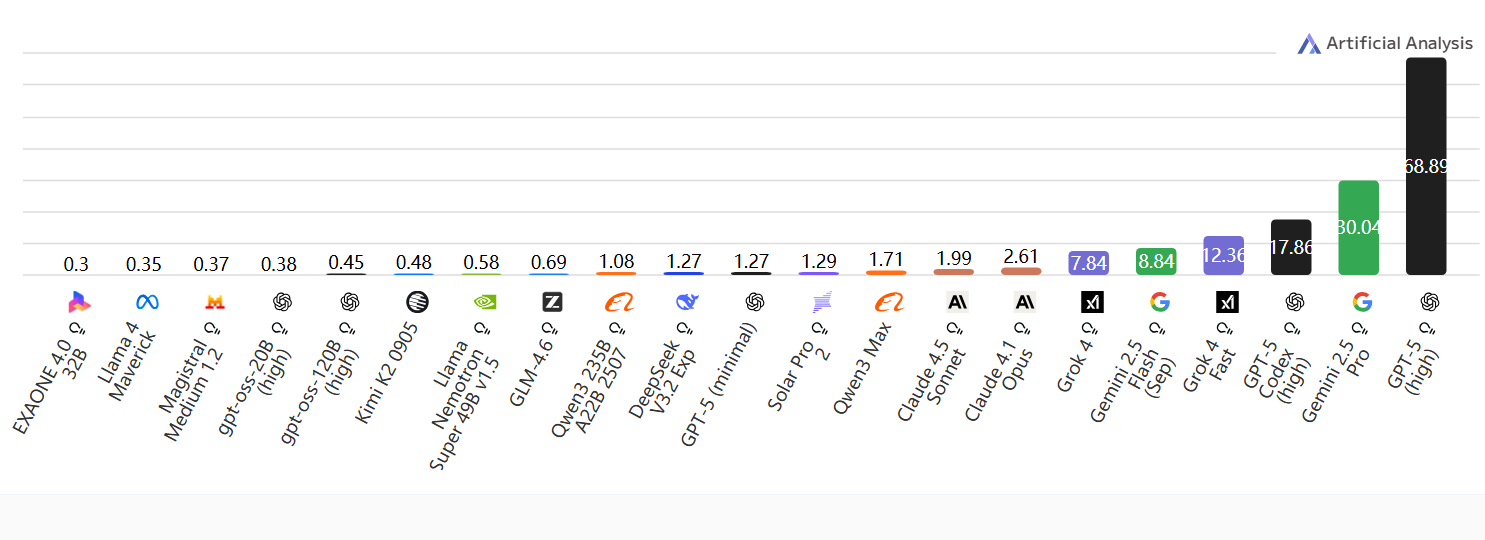
按输入Token数量(上下文长度)计算的延迟
按输入Token数量(上下文长度)计算的接收第一个代币时间
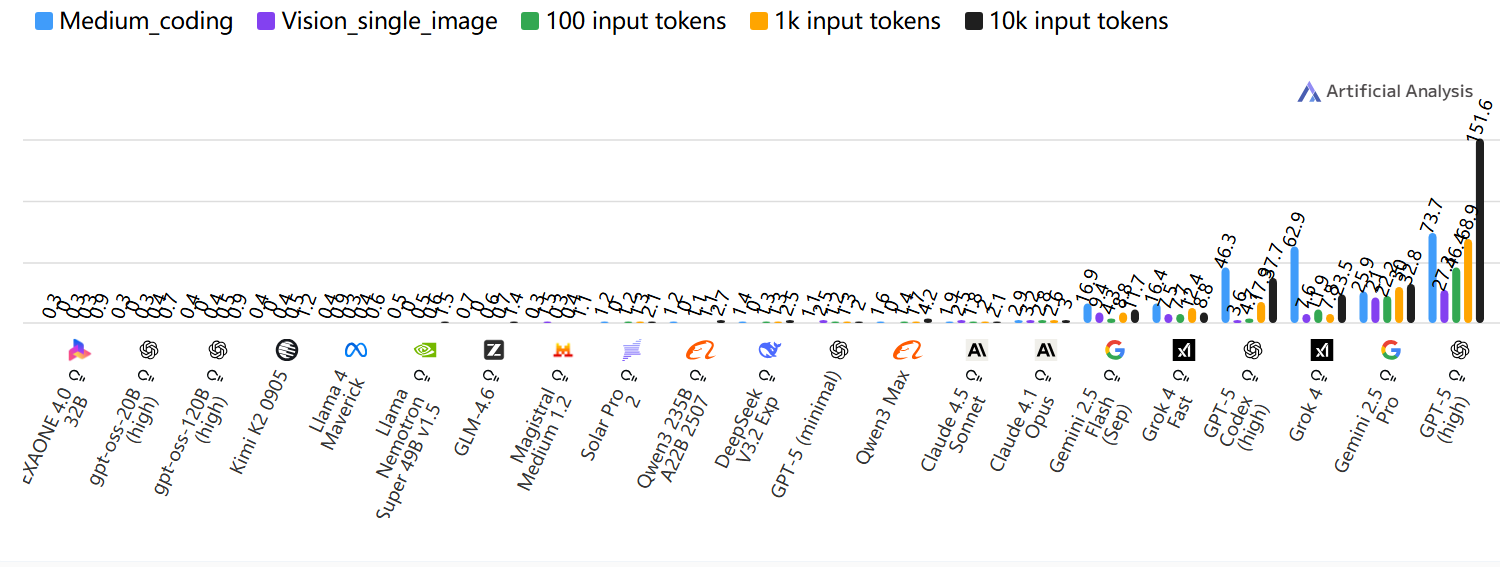
延迟差异
接收第一个Token时间的差异,接收到第一个Token所需时间(秒);按百分位显示结果;数值越低越好
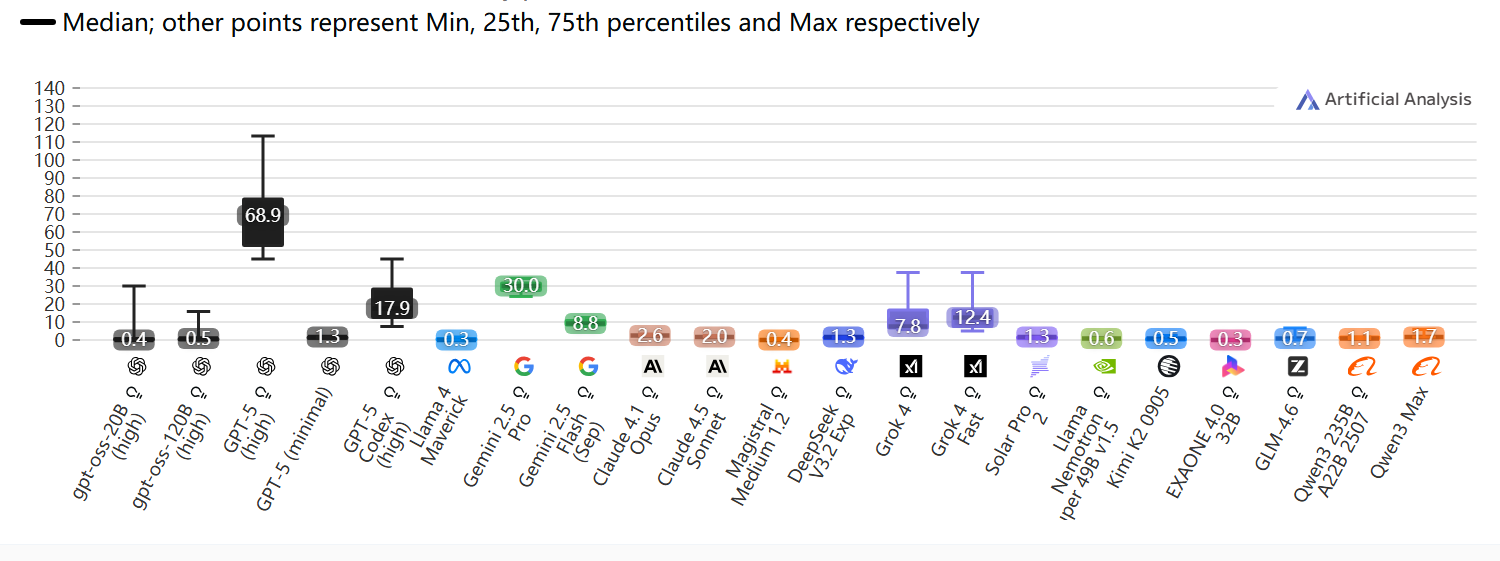
延迟超时时间
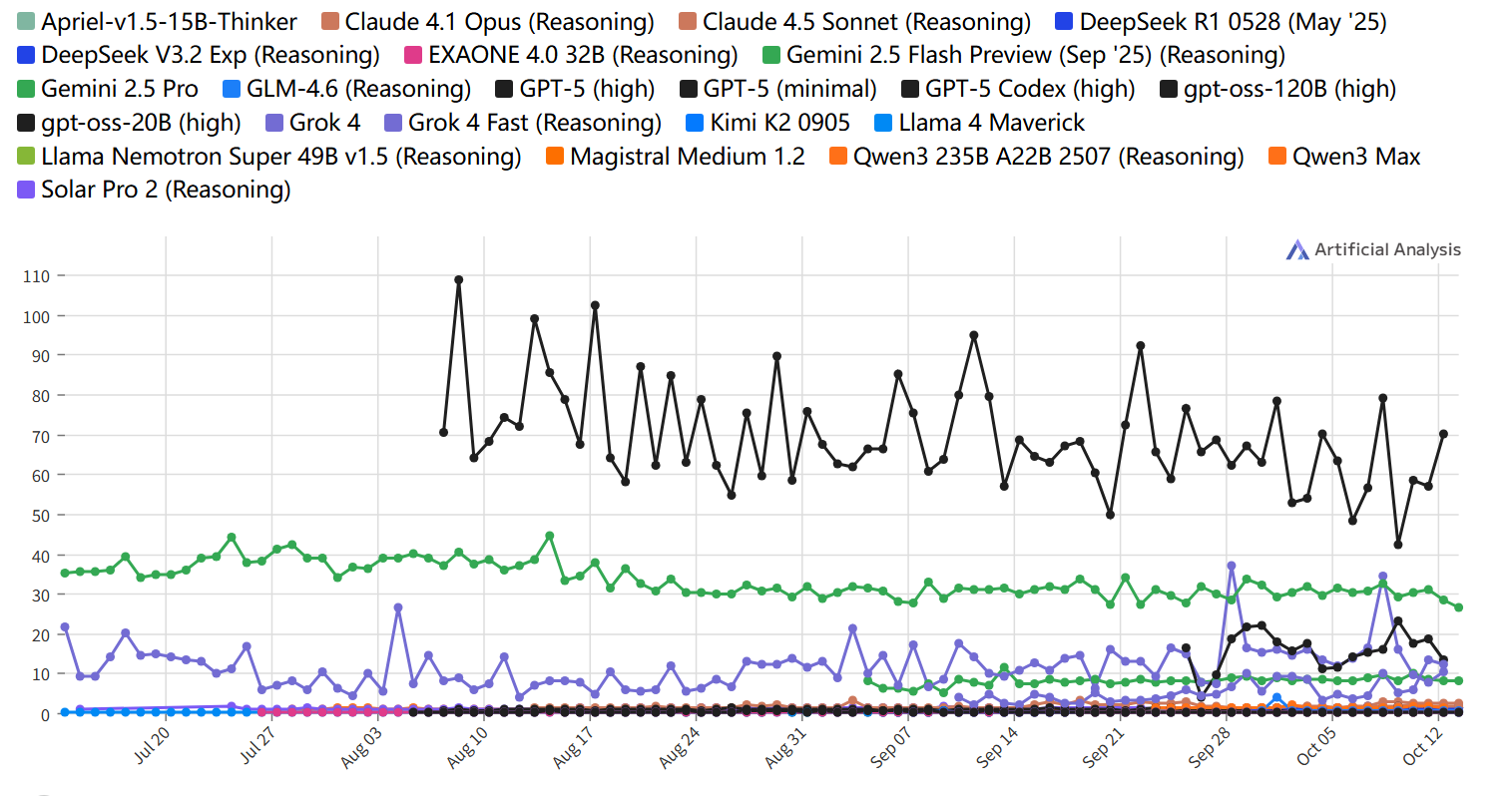
端到端响应时间
输出 500 个Token所需时间(秒),基于接收第一个代币时间、推理模型“思考”时间和输出速度计算
端到端响应时间
输出 500 个Token所需时间,包括推理模型“思考”时间;数值越低越好
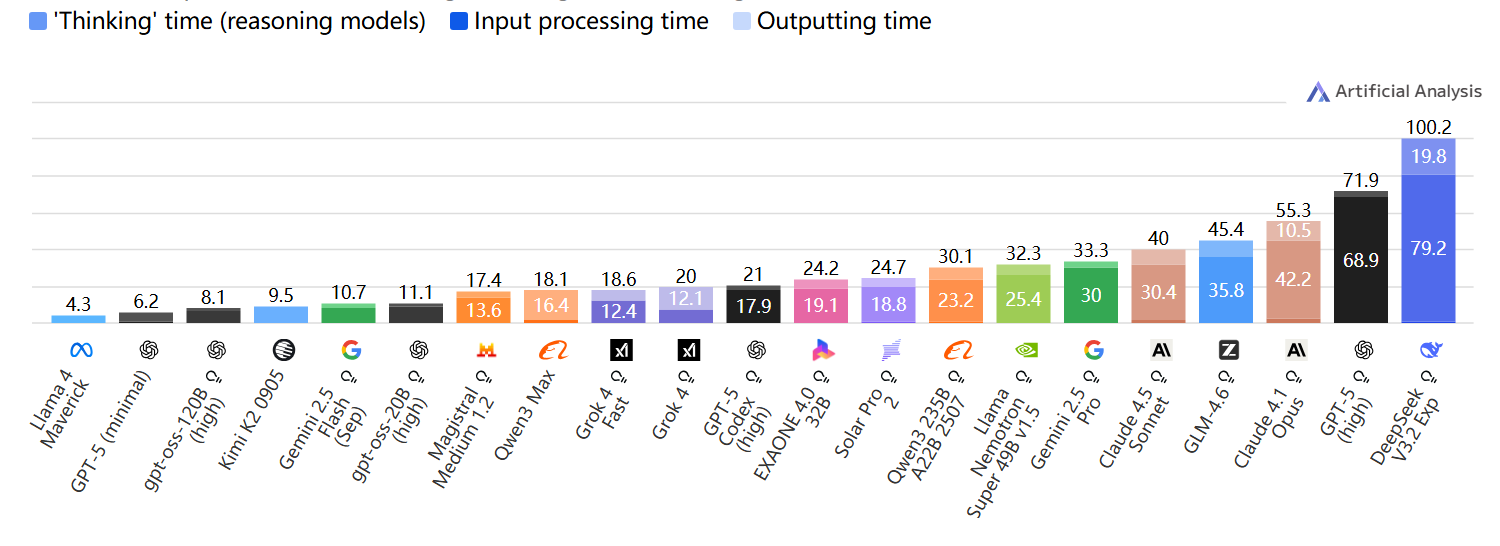
按输入Token数量(上下文长度)计算的端到端响应时间
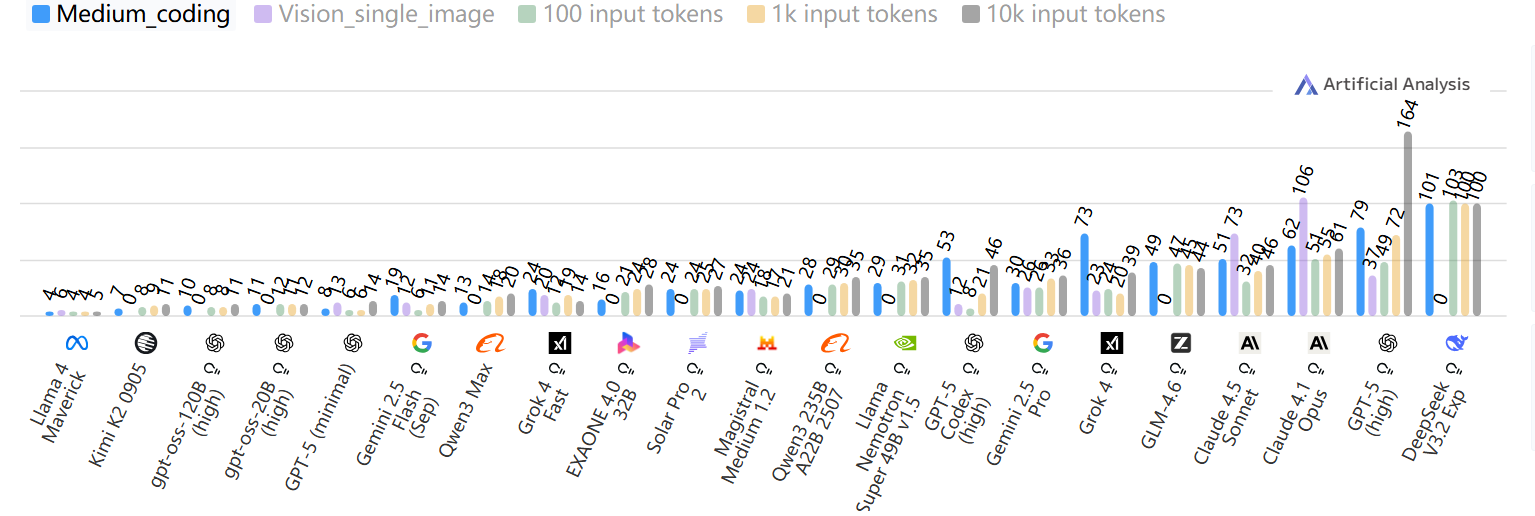
端到端响应时间随时间变化
总结对照表
| 模型名称 | 🧠 智能 (Intelligence) | ⚡ 输出速度 (Speed) | ⏱️ 延迟 (Latency) | 💰 成本 (Cost) | 🧩 上下文窗口 (Context) | ⭐ 综合评分 |
|---|---|---|---|---|---|---|
| GPT-5 Codex (high) | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐ | 9.3 |
| GPT-5 (high) | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐ | 9.0 |
| GPT-5 (medium) | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | 8.5 |
| o3 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | 8.4 |
| Gemini 2.5 Flash-Lite (Sep) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | 8.6 |
| Gemini 2.5 Flash-Lite | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | 8.3 |
| Granite 3.3 8B | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 7.9 |
| Aya Expanse 8B | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 8.1 |
| NVIDIA Nemotron Nano 9B V2 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 8.0 |
| Command-R | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 7.8 |
| Gemma 3n E4B | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | 8.2 |
| Ministral 3B | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 8.0 |
| Llama 3.2 3B | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 7.6 |
| Llama 3.2 1B | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | 7.5 |
| Llama 4 Scout | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | 8.7 |
| MiniMax-Text-01 | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | 8.3 |
| Grok 4 Fast | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | 8.0 |
更详细链接:https://artificialanalysis.ai/models?intelligence-tab=agentic&intelligence-vs-tab=price&context-window-tab=intelligenceVsContext&pricing-tab=image&speed-tab=speedByInputTokenCount&speed-comparison-tab=vsLatency&latency-tab=overTime&end-to-end-tab=overTime#intelligence-index-tokens-cost