【完整源码+数据集+部署教程】稻米害虫种类识别检测系统源码和数据集:改进yolo11-AKConv
背景意义
研究背景与意义
随着全球农业生产的不断发展,稻米作为主要粮食作物之一,其产量和质量直接影响到人们的生活水平和国家的粮食安全。然而,稻米在生长过程中常常受到多种害虫的侵害,这不仅会导致产量下降,还可能影响稻米的品质。因此,及时、准确地识别和检测稻米害虫种类,对于制定有效的防治措施、提高稻米的产量和质量具有重要的现实意义。
在传统的害虫识别方法中,依赖于人工观察和经验判断,这不仅耗时耗力,而且容易出现误判。随着计算机视觉技术的快速发展,基于深度学习的自动化识别系统逐渐成为解决这一问题的有效手段。YOLO(You Only Look Once)系列模型因其高效的实时检测能力和良好的准确性,已被广泛应用于物体检测领域。针对稻米害虫的识别,改进YOLOv11模型的应用将为实现精准农业提供新的解决方案。
本研究将基于改进的YOLOv11模型,构建一个稻米害虫种类识别检测系统。该系统将利用一个包含734张图像的数据集,涵盖四种主要的稻米害虫类别:Batu、Beras、Gabah和Kutu。通过对数据集的预处理和增强技术的应用,提升模型的泛化能力和识别准确率,进而实现对稻米害虫的快速识别与分类。
本项目的实施不仅能够为稻米种植者提供科学的害虫监测工具,帮助他们及时采取防治措施,还能为农业管理部门提供数据支持,促进农业可持续发展。通过将先进的计算机视觉技术与农业生产相结合,推动智能农业的发展,最终实现提高稻米生产效率和保障粮食安全的目标。
图片效果
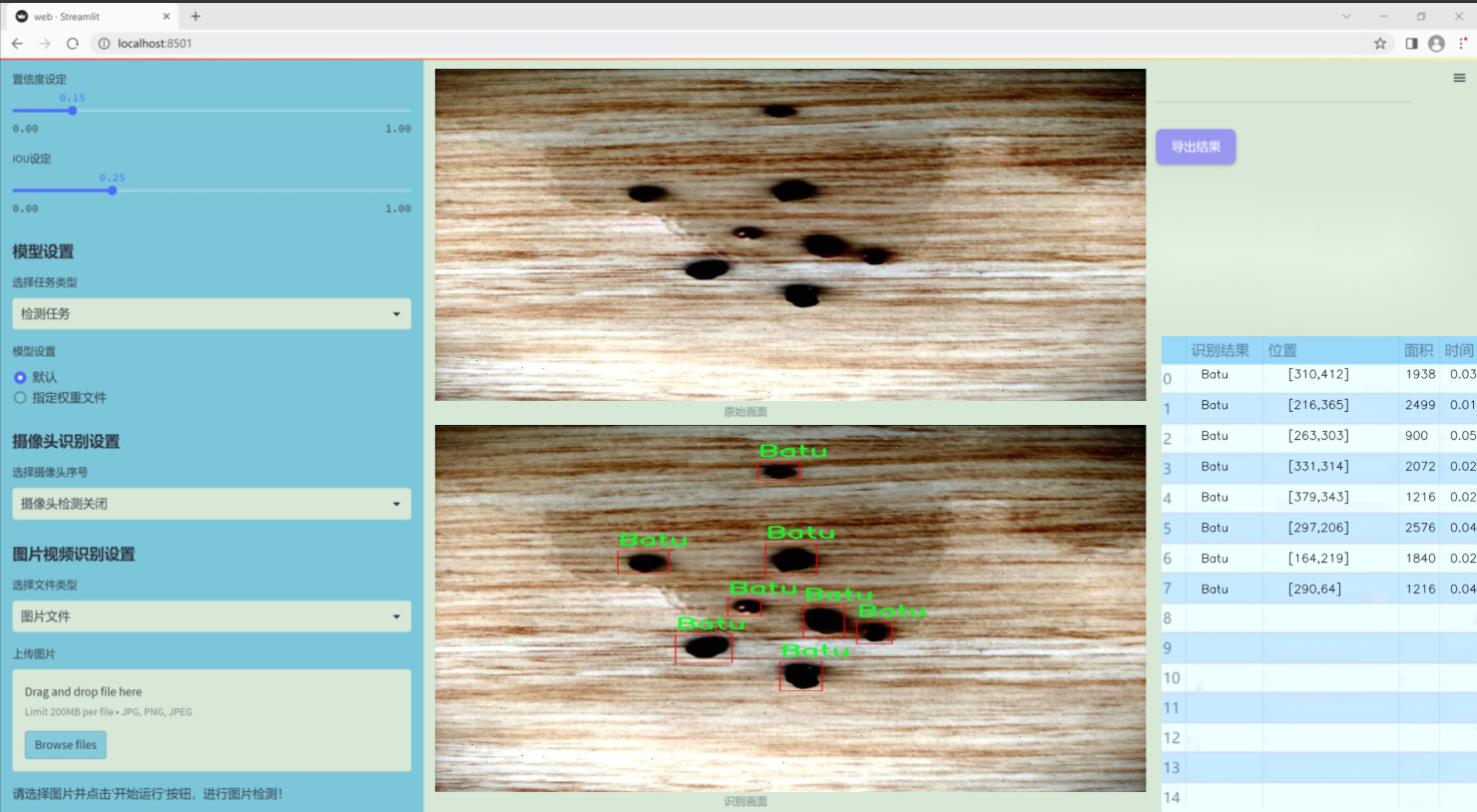
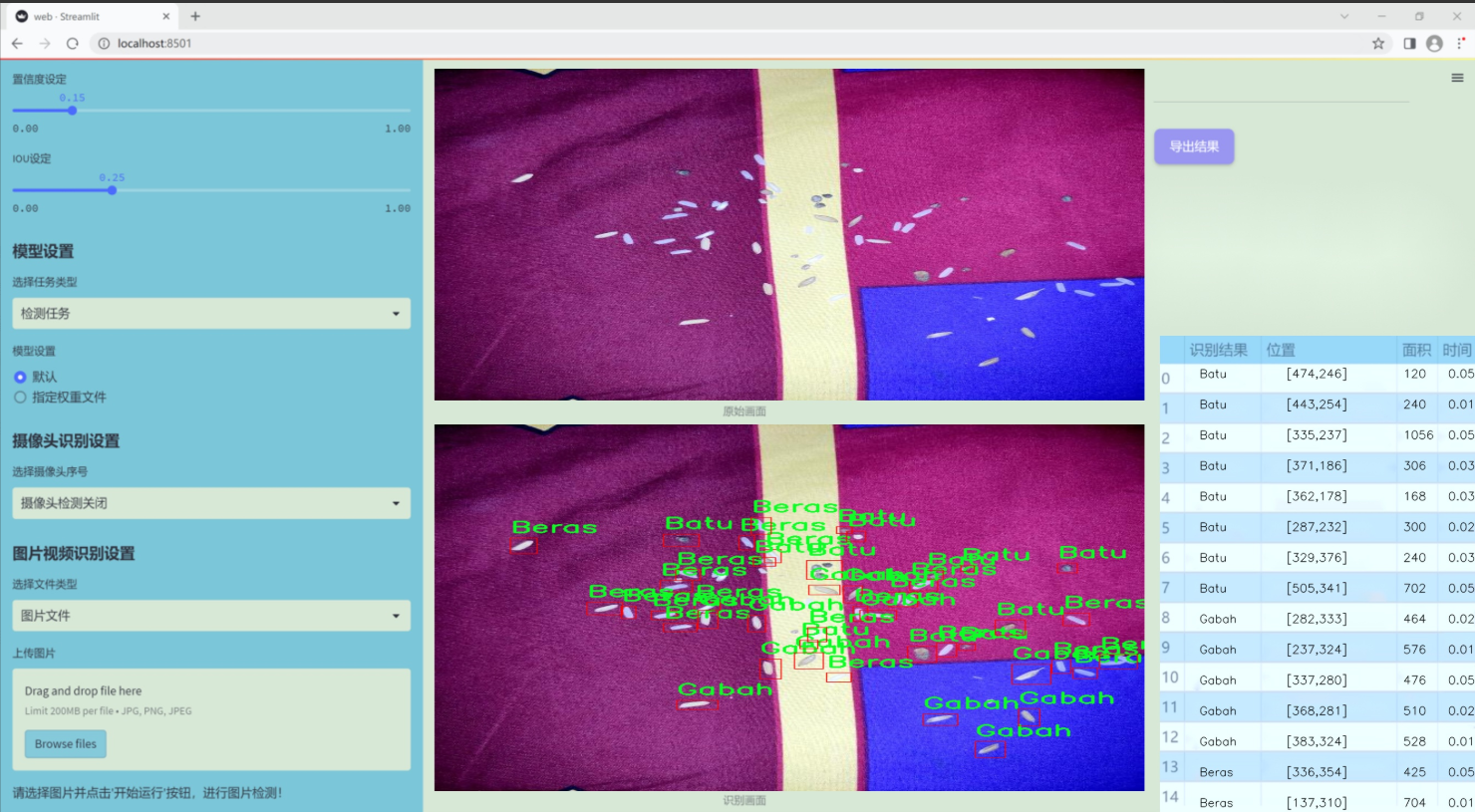
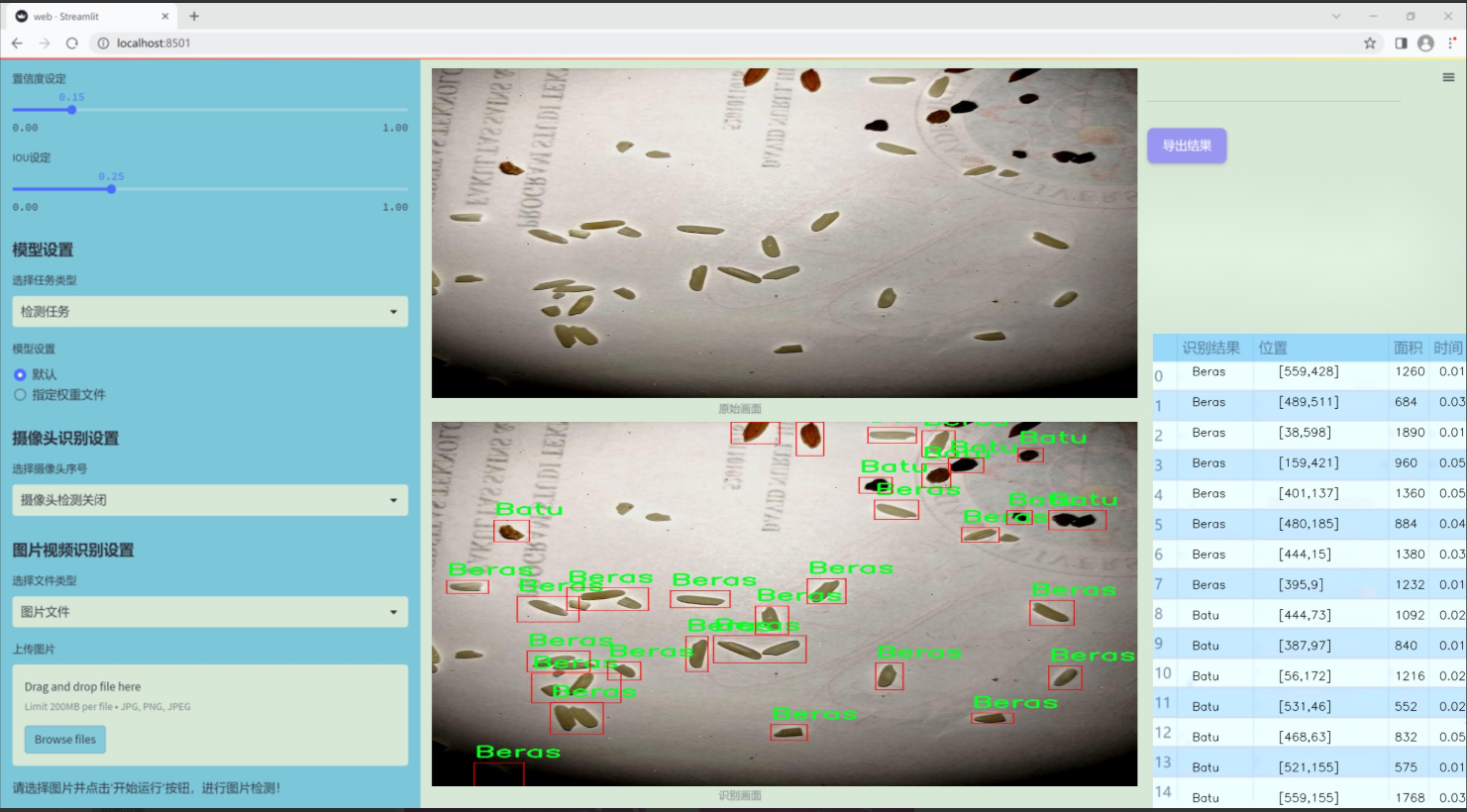
数据集信息
本项目数据集信息介绍
本项目所使用的数据集专注于稻米害虫种类的识别与检测,旨在通过改进YOLOv11模型,提高稻米种植过程中的害虫监测效率。数据集的主题为“Pendeteksi Beras”,意在为稻米种植者提供一个高效的工具,以便及时识别和处理稻米害虫,从而减少损失并提高产量。该数据集包含四个主要类别,分别为“Batu”(石头)、“Beras”(稻米)、“Gabah”(稻谷)和“Kutu”(害虫),每个类别的样本数量经过精心挑选,以确保模型训练的有效性和准确性。
在数据收集过程中,我们采用了多种采集手段,包括实地拍摄和网络资源的整合,确保数据的多样性和代表性。每个类别的样本均涵盖了不同的生长阶段和环境条件,力求在训练过程中让模型能够适应各种可能的实际情况。例如,“Kutu”类别中的样本不仅包括不同种类的稻米害虫,还涵盖了它们在不同稻米植株上的分布情况,帮助模型学习到害虫的多样性和潜在的伪装特征。
此外,为了提高数据集的质量,我们对图像进行了标注和预处理,确保每个样本的标签准确无误。数据集的设计不仅考虑到了模型的训练需求,还兼顾了实际应用中的可操作性,使得最终开发的稻米害虫识别系统能够在实际场景中发挥良好的效果。通过对该数据集的深入分析与利用,我们期望能够推动稻米种植领域的智能化发展,为农民提供更为科学和高效的害虫管理方案。





核心代码
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化参数
self.inputdim = input_dim # 输入维度
self.outdim = output_dim # 输出维度
self.degree = degree # 多项式的度数
self.kernel_size = kernel_size # 卷积核大小
self.padding = padding # 填充
self.stride = stride # 步幅
self.dilation = dilation # 膨胀
self.groups = groups # 分组卷积的组数
self.ndim = ndim # 数据的维度(1D, 2D, 3D)
self.dropout = None # Dropout层初始化为None
# 如果dropout大于0,则根据维度选择合适的Dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查分组参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 初始化层归一化self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化多项式卷积层self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注册一个缓冲区,用于存储多项式的系数arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 前向传播过程,处理每个组的输入x = torch.tanh(x) # 应用tanh激活函数x = x.acos().unsqueeze(2) # 计算反余弦并增加一个维度x = (x * self.arange).flatten(1, 2) # 乘以多项式系数并展平x = x.cos() # 计算余弦x = self.poly_conv[group_index](x) # 通过对应的卷积层x = self.layer_norm[group_index](x) # 进行层归一化if self.dropout is not None:x = self.dropout(x) # 如果有dropout,则应用dropoutreturn xdef forward(self, x):# 前向传播,处理所有组的输入split_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone()) # 保存输出y = torch.cat(output, dim=1) # 将所有组的输出拼接return y
代码说明:
KACNConvNDLayer:这是一个自定义的卷积层,支持多维卷积(1D、2D、3D),并实现了基于多项式的卷积操作。
初始化方法:构造函数中初始化了输入输出维度、卷积参数、分组数、归一化层、卷积层以及dropout层。
前向传播:
forward_kacn方法处理每个组的输入,应用激活函数、反余弦、乘以多项式系数、卷积和归一化。
forward方法将输入按组分割,调用forward_kacn处理每个组,并将结果拼接成最终输出。
这个程序文件定义了一个名为 kacn_conv.py 的模块,主要实现了一个自定义的卷积层 KACNConvNDLayer 及其一维、二维和三维的具体实现类。这个模块使用了 PyTorch 框架,主要用于构建神经网络中的卷积层。
首先,KACNConvNDLayer 类是一个通用的多维卷积层,继承自 nn.Module。在其构造函数中,接受多个参数,包括卷积类型、归一化类型、输入和输出维度、卷积核大小、分组数、填充、步幅、扩张、维度数量以及丢弃率等。构造函数中首先调用父类的构造函数,然后对输入参数进行初始化,并检查一些条件,如分组数必须为正整数,输入和输出维度必须能被分组数整除。
接下来,构造函数中创建了一个归一化层的模块列表 layer_norm,用于对每个分组的输出进行归一化。同时,还创建了一个多项式卷积层的模块列表 poly_conv,该卷积层的输入通道数是输入维度与分组数的比值乘以多项式的次数加一,输出通道数是输出维度与分组数的比值。最后,使用 Kaiming 正态分布初始化卷积层的权重,以帮助模型更好地训练。
forward_kacn 方法是该类的前向传播方法,接受输入 x 和分组索引 group_index。该方法首先对输入进行激活,然后进行线性变换,接着通过多项式卷积层进行处理,并应用归一化和丢弃层(如果有的话)。最后返回处理后的输出。
forward 方法用于处理整个输入数据。它将输入数据按分组拆分,然后对每个分组调用 forward_kacn 方法进行处理,最后将所有分组的输出拼接在一起返回。
接下来,文件中定义了三个具体的卷积层类:KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer,分别对应三维、二维和一维卷积。这些类都继承自 KACNConvNDLayer,并在构造函数中指定了相应的卷积和归一化层类型。
总的来说,这个模块实现了一个灵活且可扩展的卷积层,能够支持多种维度的卷积操作,并结合了多项式卷积和归一化技术,以提高模型的表现。
10.3 attention.py
以下是代码中最核心的部分,并添加了详细的中文注释:
import torch
from torch import nn
class EMA(nn.Module):
def init(self, channels, factor=8):
super(EMA, self).init()
self.groups = factor # 将通道分为多个组
assert channels // self.groups > 0 # 确保每组至少有一个通道
self.softmax = nn.Softmax(-1) # 用于计算权重的softmax
self.agp = nn.AdaptiveAvgPool2d((1, 1)) # 自适应平均池化到1x1
self.pool_h = nn.AdaptiveAvgPool2d((None, 1)) # 自适应平均池化到(h, 1)
self.pool_w = nn.AdaptiveAvgPool2d((1, None)) # 自适应平均池化到(1, w)
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups) # 组归一化
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1) # 1x1卷积
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, padding=1) # 3x3卷积
def forward(self, x):b, c, h, w = x.size() # 获取输入的批量大小、通道数、高度和宽度group_x = x.reshape(b * self.groups, -1, h, w) # 将输入重塑为(b*g, c//g, h, w)x_h = self.pool_h(group_x) # 对每组进行高度池化x_w = self.pool_w(group_x).permute(0, 1, 3, 2) # 对每组进行宽度池化并转置hw = self.conv1x1(torch.cat([x_h, x_w], dim=2)) # 连接高度和宽度的池化结果并通过1x1卷积x_h, x_w = torch.split(hw, [h, w], dim=2) # 将结果分为高度和宽度部分x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid()) # 通过sigmoid激活并进行组归一化x2 = self.conv3x3(group_x) # 通过3x3卷积处理原始输入x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 计算x1的权重x12 = x2.reshape(b * self.groups, c // self.groups, -1) # 重塑x2x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1)) # 计算x2的权重x22 = x1.reshape(b * self.groups, c // self.groups, -1) # 重塑x1weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w) # 计算最终权重return (group_x * weights.sigmoid()).reshape(b, c, h, w) # 应用权重并重塑为原始形状
class SimAM(nn.Module):
def init(self, e_lambda=1e-4):
super(SimAM, self).init()
self.activaton = nn.Sigmoid() # 使用sigmoid激活函数
self.e_lambda = e_lambda # 正则化参数
def forward(self, x):b, c, h, w = x.size() # 获取输入的批量大小、通道数、高度和宽度n = w * h - 1 # 计算nx_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2) # 计算每个像素与均值的平方差y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5 # 计算yreturn x * self.activaton(y) # 返回加权后的输入
class SpatialGroupEnhance(nn.Module):
def init(self, groups=8):
super().init()
self.groups = groups # 组数
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 自适应平均池化到1x1
self.weight = nn.Parameter(torch.zeros(1, groups, 1, 1)) # 权重参数
self.bias = nn.Parameter(torch.zeros(1, groups, 1, 1)) # 偏置参数
self.sig = nn.Sigmoid() # 使用sigmoid激活函数
self.init_weights() # 初始化权重
def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out') # 使用He初始化卷积层权重if m.bias is not None:nn.init.constant_(m.bias, 0) # 偏置初始化为0elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1) # 批归一化权重初始化为1nn.init.constant_(m.bias, 0) # 偏置初始化为0elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, std=0.001) # 线性层权重初始化为小的正态分布if m.bias is not None:nn.init.constant_(m.bias, 0) # 偏置初始化为0def forward(self, x):b, c, h, w = x.shape # 获取输入的批量大小、通道数、高度和宽度x = x.view(b * self.groups, -1, h, w) # 重塑输入为(b*g, dim//g, h, w)xn = x * self.avg_pool(x) # 计算加权平均xn = xn.sum(dim=1, keepdim=True) # 对每组求和t = xn.view(b * self.groups, -1) # 重塑为(b*g, h*w)t = t - t.mean(dim=1, keepdim=True) # 减去均值std = t.std(dim=1, keepdim=True) + 1e-5 # 计算标准差t = t / std # 归一化t = t.view(b, self.groups, h, w) # 重塑为(b, g, h, w)t = t * self.weight + self.bias # 应用权重和偏置t = t.view(b * self.groups, 1, h, w) # 重塑为(b*g, 1, h, w)x = x * self.sig(t) # 应用sigmoid激活x = x.view(b, c, h, w) # 重塑为原始形状return x
以上代码实现了三个核心模块:EMA(Exponential Moving Average)、SimAM(Similarity Attention Module)和SpatialGroupEnhance(空间组增强)。每个模块都有详细的中文注释,解释了其构造函数和前向传播过程中的每一步。
这个程序文件 attention.py 实现了一系列与注意力机制相关的深度学习模块,主要用于计算机视觉任务中的特征提取和增强。文件中包含多个类,每个类实现了一种特定的注意力机制或模块,下面对这些模块进行逐一说明。
首先,文件导入了必要的库,包括 PyTorch、Torchvision 和一些其他的工具库。这些库提供了构建神经网络所需的基本组件,如张量操作、卷积层、激活函数等。
接下来,文件定义了一系列注意力机制的类。EMA 类实现了一种增强的多头注意力机制,利用自适应平均池化和卷积操作来计算注意力权重。SimAM 类则实现了一种简单的自适应注意力机制,通过计算输入特征的均值和方差来生成注意力权重。
SpatialGroupEnhance 类通过对输入特征进行分组和增强来提升特征的表达能力。TopkRouting 类实现了一种可微分的 Top-k 路由机制,用于选择最重要的特征。KVGather 类则用于根据路由索引选择键值对。
BiLevelRoutingAttention 类实现了一种双层路由注意力机制,结合了局部和全局特征的注意力计算。FocusedLinearAttention 类则通过线性变换和聚合操作来实现关注特定区域的注意力机制。
文件中还实现了一些其他的注意力模块,如 CoordAtt、TripletAttention、BAMBlock、EfficientAttention 等。这些模块通过不同的方式对输入特征进行加权,旨在提高模型的表现。
DeformConv 类实现了可变形卷积,用于捕捉输入特征中的空间变形信息。EffectiveSEModule 和 LSKA 类则实现了有效的通道注意力机制,分别通过全局平均池化和可分离卷积来增强特征表示。
最后,文件中还定义了一些辅助类,如 LayerNormProxy、Conv2d_BN 和 CascadedGroupAttention,这些类用于实现标准化、卷积操作和分组注意力机制。
总体而言,这个文件提供了一套丰富的注意力机制实现,适用于各种计算机视觉任务,能够有效地增强模型的特征表达能力和性能。
10.4 SMPConv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
定义相对位置的函数
def rel_pos(kernel_size):
# 创建一个从-1到1的线性空间,步数为kernel_size
tensors = [torch.linspace(-1, 1, steps=kernel_size) for _ in range(2)]
# 生成网格坐标
kernel_coord = torch.stack(torch.meshgrid(*tensors), dim=-0)
kernel_coord = kernel_coord.unsqueeze(0) # 增加一个维度
return kernel_coord
定义SMP卷积类
class SMPConv(nn.Module):
def init(self, planes, kernel_size, n_points, stride, padding, groups):
super().init()
self.planes = planes # 输出通道数self.kernel_size = kernel_size # 卷积核大小self.n_points = n_points # 关键点数量self.init_radius = 2 * (2/kernel_size) # 初始化半径# 生成卷积核坐标kernel_coord = rel_pos(kernel_size)self.register_buffer('kernel_coord', kernel_coord) # 注册为缓冲区# 初始化权重坐标weight_coord = torch.empty(1, n_points, 2)nn.init.trunc_normal_(weight_coord, std=0.2, a=-1., b=1.) # 使用截断正态分布初始化self.weight_coord = nn.Parameter(weight_coord) # 注册为可学习参数# 初始化半径self.radius = nn.Parameter(torch.empty(1, n_points).unsqueeze(-1).unsqueeze(-1))self.radius.data.fill_(value=self.init_radius) # 填充初始值# 初始化权重weights = torch.empty(1, planes, n_points)nn.init.trunc_normal_(weights, std=.02) # 使用截断正态分布初始化self.weights = nn.Parameter(weights) # 注册为可学习参数def forward(self, x):# 生成卷积核并添加维度kernels = self.make_kernels().unsqueeze(1)x = x.contiguous() # 确保输入张量是连续的kernels = kernels.contiguous() # 确保卷积核张量是连续的# 根据输入数据类型选择不同的卷积实现if x.dtype == torch.float32:x = _DepthWiseConv2dImplicitGEMMFP32.apply(x, kernels) # 使用FP32的深度卷积elif x.dtype == torch.float16:x = _DepthWiseConv2dImplicitGEMMFP16.apply(x, kernels) # 使用FP16的深度卷积else:raise TypeError("Only support fp32 and fp16, get {}".format(x.dtype)) # 抛出异常return x def make_kernels(self):# 计算权重坐标与卷积核坐标的差diff = self.weight_coord.unsqueeze(-2) - self.kernel_coord.reshape(1, 2, -1).transpose(1, 2) # [1, n_points, kernel_size^2, 2]diff = diff.transpose(2, 3).reshape(1, self.n_points, 2, self.kernel_size, self.kernel_size) # 重塑为适合的形状diff = F.relu(1 - torch.sum(torch.abs(diff), dim=2) / self.radius) # 计算差的绝对值并应用ReLU# 计算卷积核kernels = torch.matmul(self.weights, diff.reshape(1, self.n_points, -1)) # [1, planes, kernel_size*kernel_size]kernels = kernels.reshape(1, self.planes, *self.kernel_coord.shape[2:]) # 重塑为[1, planes, kernel_size, kernel_size]kernels = kernels.squeeze(0) # 去掉多余的维度kernels = torch.flip(kernels.permute(0, 2, 1), dims=(1,)) # 反转卷积核的维度return kernels
定义SMPBlock类
class SMPBlock(nn.Module):
def init(self, in_channels, dw_channels, lk_size, drop_path, n_points=None, n_points_divide=4):
super().init()
# 定义逐点卷积和激活函数
self.pw1 = conv_bn_relu(in_channels, dw_channels, 1, 1, 0, groups=1)
# 定义大卷积核
self.large_kernel = SMPCNN(in_channels=dw_channels, out_channels=dw_channels, kernel_size=lk_size,
stride=1, groups=dw_channels, n_points=n_points, n_points_divide=n_points_divide)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity() # DropPath用于随机丢弃路径
def forward(self, x):out = self.pw1(x) # 逐点卷积out = self.large_kernel(out) # 大卷积核return x + self.drop_path(out) # 残差连接
代码核心部分说明:
SMPConv类:实现了一个自定义的卷积层,支持动态生成卷积核,利用权重坐标和卷积核坐标计算卷积操作。
make_kernels方法:计算卷积核的过程,涉及权重和卷积核坐标的差异,并生成最终的卷积核。
SMPBlock类:结合逐点卷积和大卷积核,使用残差连接的方式构建网络模块,支持DropPath的随机丢弃策略。
这个程序文件 SMPConv.py 定义了一些用于深度学习的卷积模块,主要是实现了一种特殊的卷积操作和一些相关的网络结构。代码中使用了 PyTorch 框架,以下是对代码的详细说明。
首先,导入了必要的库,包括 PyTorch 的核心模块和一些自定义的模块。Conv 是一个自定义的卷积模块,DropPath 是一种用于正则化的技术。文件中还尝试导入了一些深度可分离卷积的实现,如果导入失败则会被忽略。
接下来,定义了一个函数 rel_pos,用于生成相对位置的坐标张量,这在卷积操作中可能用于计算卷积核的相对位置。
SMPConv 类是这个文件的核心部分,继承自 nn.Module。在其构造函数中,初始化了一些参数,包括输出通道数、卷积核大小、点数、步幅、填充和分组卷积的设置。kernel_coord 用于存储卷积核的相对位置坐标,而 weight_coord 和 weights 则是用于存储卷积核的权重和坐标。
forward 方法实现了前向传播,其中调用了 make_kernels 方法生成卷积核,并根据输入数据的类型选择不同的深度可分离卷积实现。make_kernels 方法通过计算权重坐标和卷积核坐标之间的差异,生成适合当前输入的卷积核。
radius_clip 方法用于限制半径的范围,确保其在指定的最小值和最大值之间。
接下来的 get_conv2d 函数用于根据输入参数返回相应的卷积层,如果满足特定条件则返回 SMPConv,否则返回标准的 nn.Conv2d。
enable_sync_bn 和 get_bn 函数用于处理批归一化,允许选择同步批归一化或标准批归一化。
conv_bn 和 conv_bn_relu 函数用于构建包含卷积层和批归一化层的序列模块,后者还包括一个 ReLU 激活函数。
fuse_bn 函数用于将卷积层和批归一化层融合,以提高推理速度。
SMPCNN 类是一个卷积神经网络模块,包含一个 SMP 卷积层和一个小卷积层,前者使用 conv_bn 构建,后者使用自定义的 Conv 类。
SMPCNN_ConvFFN 类实现了一个前馈网络,包含两个逐点卷积层和一个 GELU 激活函数,同时支持 DropPath 正则化。
最后,SMPBlock 类定义了一个包含多个卷积操作的块,使用了前面定义的卷积模块和激活函数,并实现了残差连接。
整体来看,这个文件实现了一种新型的卷积结构,结合了深度可分离卷积和标准卷积的优点,适用于需要高效计算的深度学习模型。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式