RabbitMQ核心机制解析
一、RabbitMQ 是什么?
RabbitMQ 是一个开源的消息代理软件,实现了高级消息队列协议(AMQP)。 它充当消息的"中间人",在生产者和消费者之间传递消息,而无需双方直接通信。
核心定位:异步消息通信的中间件,实现应用间的解耦、缓冲和可靠传递。
二、RabbitMQ 的核心概念与工作原理
核心组件
| 组件 | 作用 | 现实比喻 |
|---|---|---|
| Producer(生产者) | 发送消息的应用程序 | 写信人 |
| Consumer(消费者) | 接收消息的应用程序 | 收信人 |
| Exchange(交换器) | 接收生产者消息,决定将消息路由到哪些队列 | 邮局分拣员 |
| Queue(队列) | 存储消息的缓冲区,消费者从这里获取消息 | 邮箱 |
| Binding(绑定) | Exchange 和 Queue 之间的连接规则 | 邮寄地址清单 |
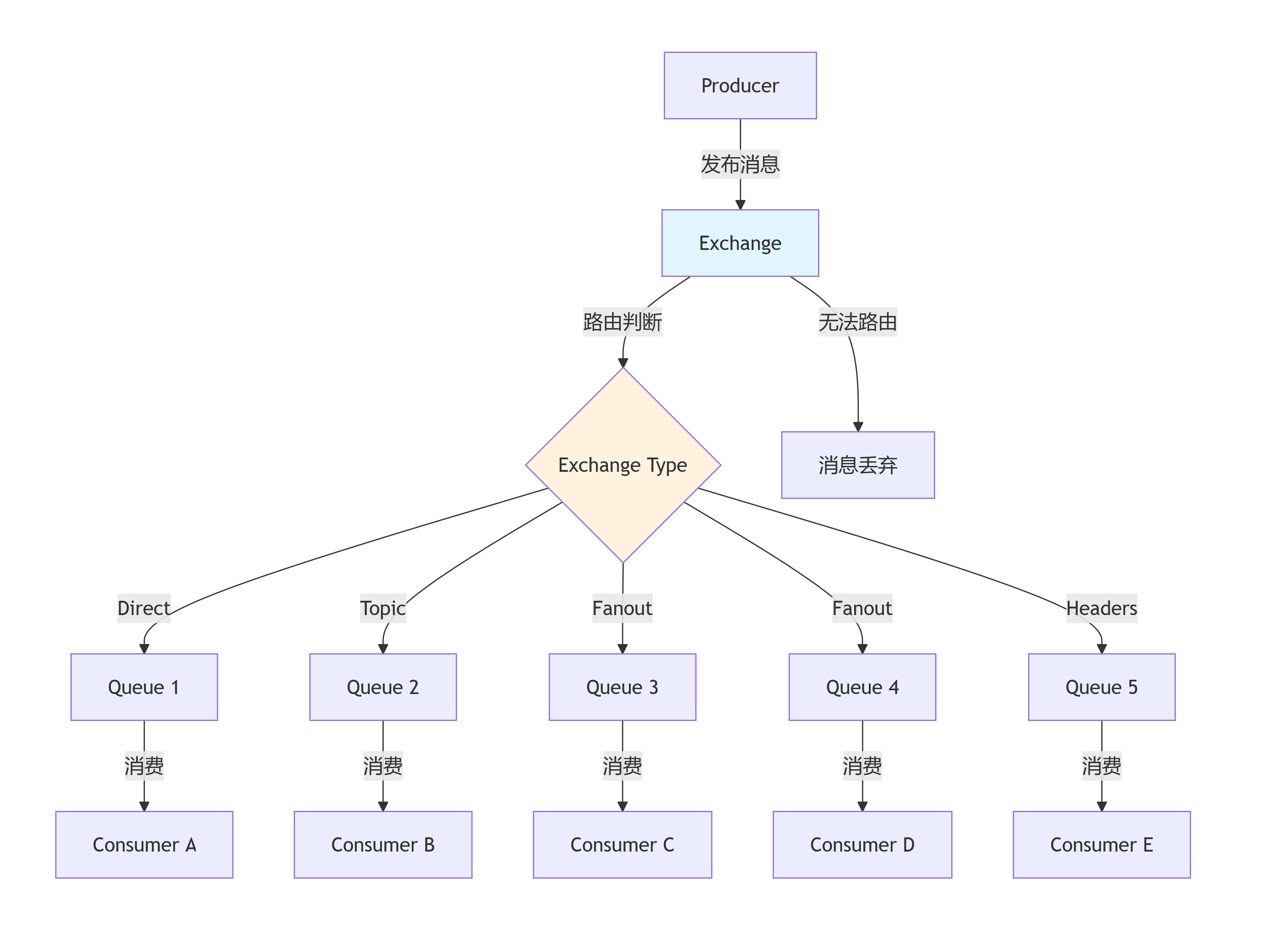
核心工作机制流程图
四种Exchange类型详解
1. Direct Exchange(直连交换器)
# 绑定规则:完全匹配Routing Key
channel.queue_bind(exchange='logs',queue='queue_l3',routing_key='l3_agent')
# 只有routing_key='l3_agent'的消息会进入queue_l3
2. Topic Exchange(主题交换器)
# 绑定规则:模式匹配
channel.queue_bind(exchange='logs',queue='queue_network',routing_key='network.node42.*')
# 匹配:network.node42.create, network.node42.delete
# 不匹配:network.node43.create
3. Fanout Exchange(扇出交换器)
# 绑定规则:广播到所有绑定队列
channel.queue_bind(exchange='broadcast',queue='queue_monitor1')
channel.queue_bind(exchange='broadcast', queue='queue_monitor2')
# 同一消息会同时进入queue_monitor1和queue_monitor2
4. Headers Exchange(头交换器)
# 绑定规则:基于消息头匹配
args = {'x-match': 'all', 'service': 'network', 'type': 'router'}
channel.queue_bind(exchange='headers_exchange',queue='queue_router',arguments=args)
# 只有headers包含service=network且type=router的消息才会路由
三、RabbitMQ 能做什么?
1. 应用解耦
场景:订单系统与库存系统
- 传统方式:订单系统直接调用库存系统API,一方宕机则整体失败
- RabbitMQ方式:订单系统发送消息到MQ,库存系统按需消费,互不影响
2. 异步处理
场景:用户注册流程
# 同步方式(耗时5秒)
用户提交注册 → 写入数据库 → 发送邮件 → 发送短信 → 返回响应# 异步方式(耗时0.5秒)
用户提交注册 → 写入数据库 → 发送消息到MQ → 返回响应↓ (异步)邮件服务消费消息 → 发送邮件短信服务消费消息 → 发送短信
3. 流量削峰
场景:秒杀活动
- 瞬间万级请求 → RabbitMQ队列缓冲 → 后端服务按处理能力消费
- 避免服务器被冲垮,保证系统稳定性
4. 发布/订阅
场景:系统通知
- 一个消息被多个独立服务消费(日志服务、监控服务、数据分析服务)
四、完整工作流程案例:OpenStack Neutron
让我们通过一个具体的网络创建请求,来看RabbitMQ在OpenStack中的实际应用。
场景:用户创建虚拟路由器
具体代码逻辑
Neutron-API (生产者)
def create_router(self, request):# 1. 验证请求参数router_data = validate_request(request)# 2. 发送RPC消息到RabbitMQwith connection_pool.get() as channel:channel.basic_publish(exchange='neutron',routing_key='router.create',body=json.dumps({'router_id': router_data['id'],'tenant_id': router_data['tenant_id'],'name': router_data['name']}),properties=pika.BasicProperties(delivery_mode=2, # 持久化消息reply_to=self.reply_queue # 用于接收响应))# 3. 立即返回,不等待后端处理完成return {'status': 'accepted', 'router_id': router_data['id']}
Neutron-L3-Agent (消费者)
def start_consuming(self):# 启动时声明队列和绑定channel = self.connection.channel()channel.queue_declare(queue='l3_agents', durable=True)channel.queue_bind(exchange='neutron',queue='l3_agents',routing_key='router.*' # 订阅所有路由器相关操作)# 开始消费消息channel.basic_consume(queue='l3_agents',on_message_callback=self.handle_router_message)channel.start_consuming()def handle_router_message(self, channel, method, properties, body):message = json.loads(body)if 'router.create' in method.routing_key:self.create_router(message)elif 'router.delete' in method.routing_key:self.delete_router(message)# 确认消息已处理channel.basic_ack(delivery_tag=method.delivery_tag)
五、为什么选择 RabbitMQ?关键优势
1. 可靠性
- 消息持久化:队列和消息都可持久化,服务器重启不丢失
- 生产者确认:确保消息到达Broker
- 消费者确认:确保消息被成功处理
2. 灵活的路由
- 四种Exchange类型满足各种路由需求
- 支持复杂消息流模式
3. 集群与高可用
- 支持多节点集群
- 队列镜像,故障自动转移
4. 多语言支持
- 支持几乎所有编程语言
- 提供完善的客户端库
六、与其他技术的对比
| 特性 | RabbitMQ | gRPC/HTTP2 | Kafka |
|---|---|---|---|
| 通信模式 | 异步消息 | 同步RPC | 流式日志 |
| 数据持久化 | 内存/磁盘 | 无 | 磁盘 |
| 吞吐量 | 中等 | 高 | 非常高 |
| 延迟 | 低 | 极低 | 低 |
| 主要场景 | 任务分发、解耦 | 服务间通信 | 日志流、事件流 |
七、总结
RabbitMQ 的核心价值在于:
- 解耦神器:生产者和消费者完全隔离,独立发展和扩展
- 异步引擎:将同步操作转为异步,提升系统响应速度
- 弹性缓冲:应对流量高峰,保护后端服务
- 可靠传递:确保重要消息不丢失
在OpenStack这样的复杂分布式系统中,RabbitMQ提供了服务间通信的"神经系统",让各个组件能够松耦合地协作,这正是它被选为核心基础设施的原因。