具身导航分层思考、动态行动!MFRA:面向视觉语言导航的层次化多模态融合与推理
- 作者:Junrong Yue1^{1}1, Chuan Qin2^{2}2, Bo Li3,4^{3,4}3,4, Wenxin Zhang5^{5}5, Xinlei Yu6^{6}6, Xiaomin Lie1^{1}1, Zhendong Zhao5^{5}5, Yifan Zhang1^{1}1
- 单位:1^{1}1香港城市大学,2^{2}2墨尔本大学,3^{3}3清华大学,4^{4}4百度,5^{5}5中国科学院大学,6^{6}6新加坡国立大学
- 论文标题:Think Hierarchically, Act Dynamically: Hierarchical Multi-modal Fusion and Reasoning for Vision-and-Language Navigation
- 论文链接:https://arxiv.org/pdf/2504.16516
主要贡献
- 提出了多级融合和推理架构(MFRA),用于视觉语言导航(VLN)任务,通过有效整合视觉观察、语言指令和导航历史来增强智能体的推理能力。
- 设计了层次化的融合机制,能够系统地结合从低级视觉线索到高级语义概念的多级特征,解决了全局表示缺乏区分度的问题。
- 开发了动态推理模块,通过指令引导的注意力来增强跨模态对齐,减轻了以对象为中心的方法的局限性。
- 通过广泛的实验验证了该方法的有效性,证明其优于现有方法,并具有更好的泛化能力。
研究背景
- 视觉语言导航(VLN)是具身人工智能(Embodied AI)中的一个关键研究领域,要求智能体能够处理自然语言指令、解释动态3D环境并执行准确的导航动作,对于从辅助机器人到增强现实等应用至关重要。
- 早期的VLN方法主要依赖于全局场景表示或对象级特征,但这些方法在语义同质化环境中缺乏区分度,且忽略了对象间的上下文关系,导致导航性能受限。
- 近期的研究尝试通过混合解决方案整合全局和对象特征,但仍存在一些问题,如静态特征加权机制难以适应不同的指令需求、忽略了人类推理的层次性以及在长时序导航任务中性能下降等。
方法
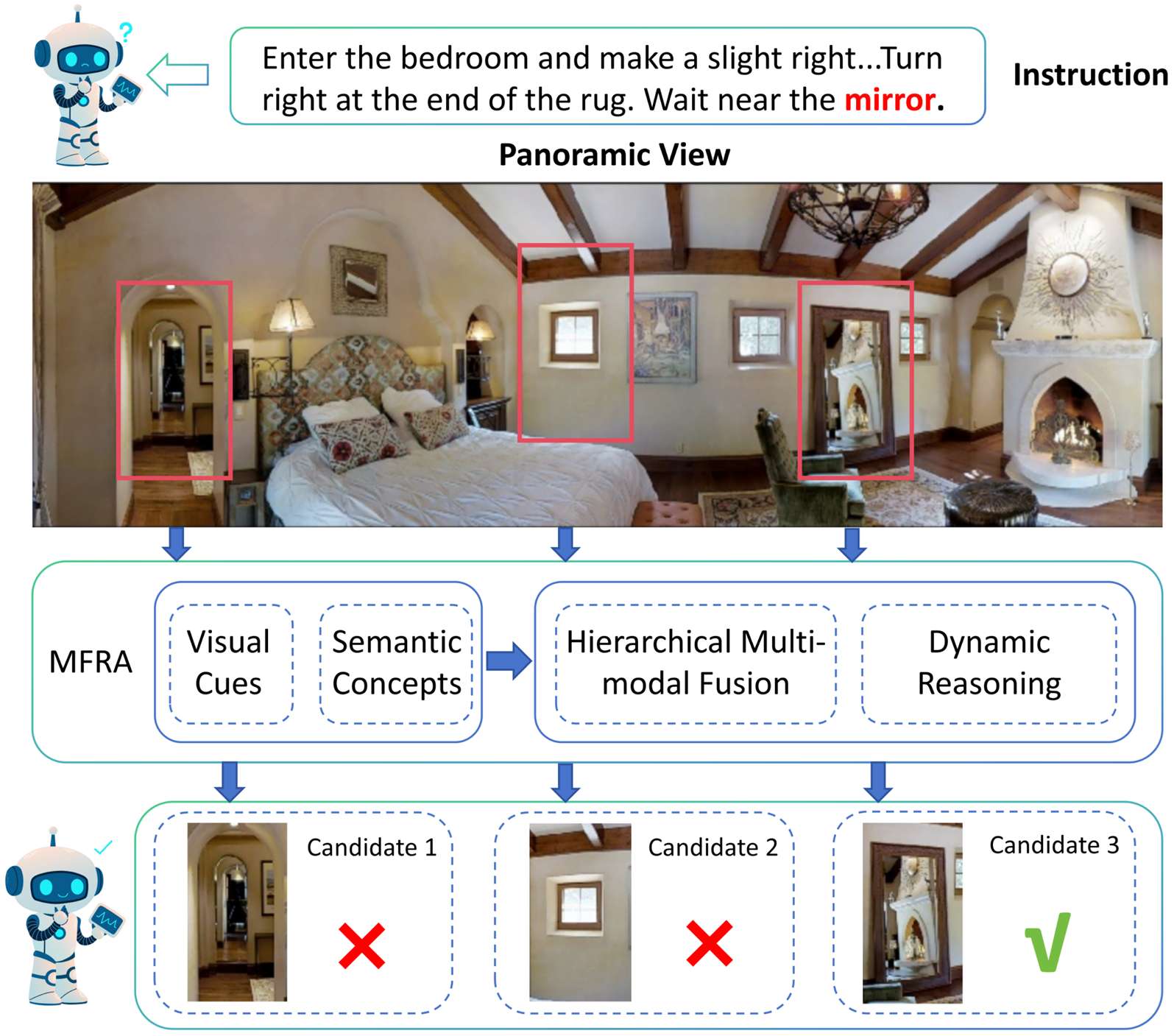
为了解决VLN任务中多模态语义对齐和上下文感知推理的挑战,提出了多级融合和推理架构(MFRA),该架构能够联合建模全景视觉观察、自然语言指令和智能体的导航历史。
多模态特征提取
- 视觉特征提取:在每个时间步,智能体接收由36个离散单视图图像组成的全景视觉观察,每个视图使用CLIP的视觉编码器进行编码,得到视觉特征向量集合。
- 语言特征提取:将自然语言指令表示为令牌序列,使用CLIP文本编码器嵌入,得到令牌级嵌入以及用于捕获全局语义意图的句子级表示。
- 对象特征提取:对于涉及对象级定位的数据集(如REVERIE和SOON),还从每个全景观察中提取对象中心区域特征,这些特征由预训练的对象检测器生成,并通过可学习的适配器投影到与CLIP相同的嵌入空间。
- 历史特征提取:通过GRU维护一个循环历史嵌入,以总结到时间步t为止观察到的轨迹。在每一步,将当前视觉观察和其指令注意力上下文融合,然后传递到GRU中以更新时间状态。
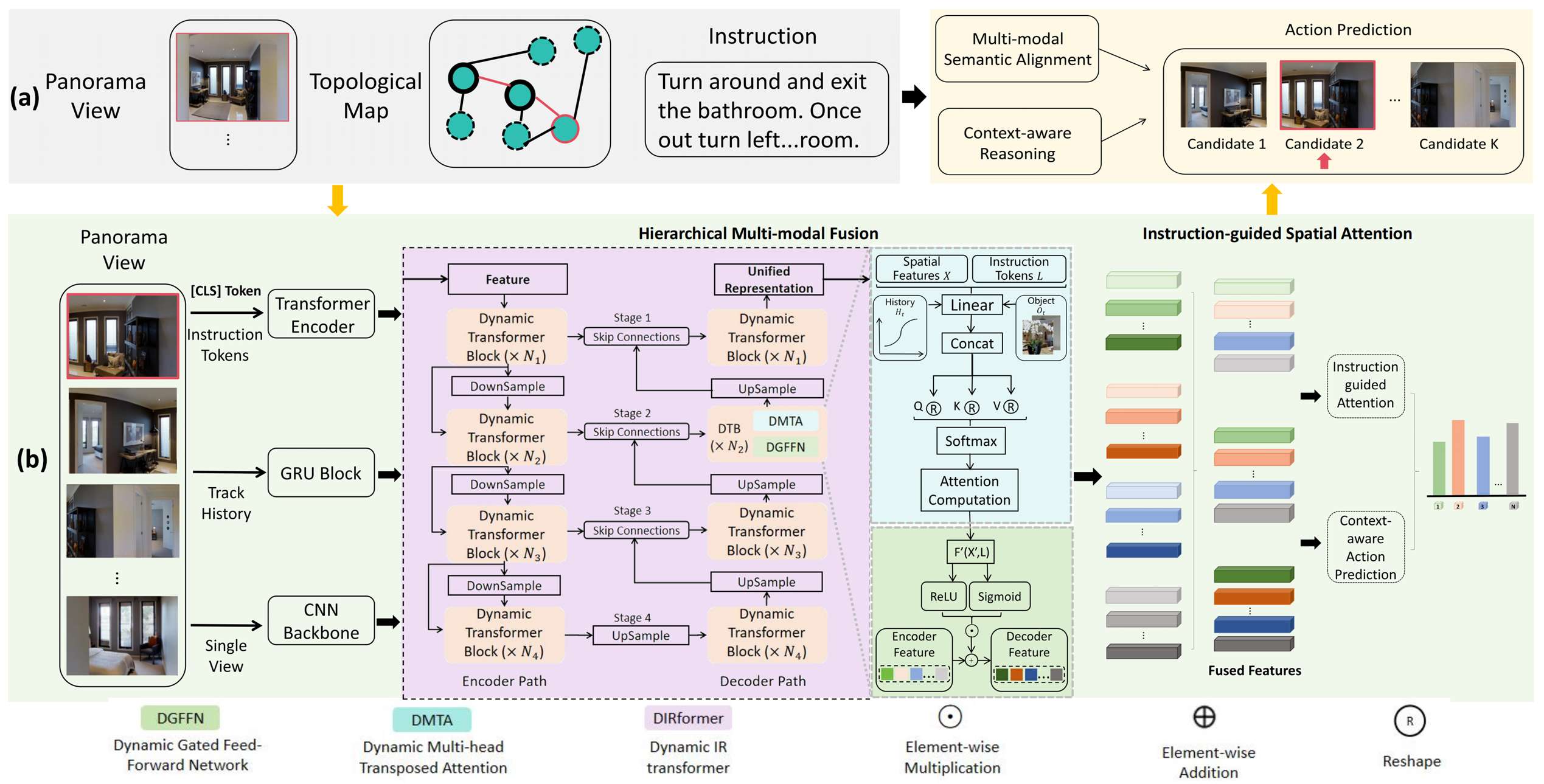
层次化多模态融合
模仿人类认知层次,从低级(对象形状)到中级(空间布局)再到高级(语义上下文),设计层次化融合策略,以实现多语义层次上的细粒度跨模态对齐,并确保每个层次为下一个层次提供指导。
- 融合过程:
- 编码器路径:包含多个动态Transformer块,每个块包括动态多头转置注意力(DMTA)层和动态门控前馈网络(DGFFN)。在每个阶段,特征图通过DMTA模块在空间特征和指令令牌之间进行注意力计算,然后通过DGFFN模块进行非线性变换和动态门控,以聚合对象交互。
- 解码器路径:对称地包含上采样块,以重建更高分辨率的表示,并通过跳跃连接连接编码器和解码器阶段。解码器特征通过与编码器阶段相同的DMTA和DGFFN操作进行更新。
- 对象和历史上下文集成:将对象级特征和轨迹历史融入每个融合阶段,这些特征被投影到令牌嵌入中,并通过辅助DMTA层进行融合,以增强模型对细粒度实体和序列模式的推理能力。
- 双向交互:低级细节约束中级布局,中级布局为高级目标提供上下文;高级语义(如“找到卧室”)剪枝不相关的中级配置,中级配置细化低级特征提取,从而实现统一表示,所有层次共同演化以解决歧义并符合任务目标。
动态推理模块
将层次化融合后的统一表示转化为可操作的决策。
- 指令引导的空间注意力:使用从CLIP文本编码器的[CLS]令牌中提取的全局指令嵌入,计算空间特征上的注意力权重,得到捕获当前步骤指令条件视觉上下文的向量。
- 上下文感知决策制定:将当前注意力上下文和历史表示进行拼接,通过前馈网络(FFN)投影到固定维度的决策空间中,形成最终决策嵌入。
- 动作预测:计算候选可导航方向(包括停止动作)的嵌入与决策嵌入的相似度,并应用softmax归一化,预测最合适的下一个动作。
训练目标
- 监督动作学习:使用行为克隆法,以训练数据集中的专家轨迹来监督策略网络,定义导航损失为预测动作分布和真实动作之间的交叉熵。
- 辅助目标:
- 掩码语言建模(MLM):在预训练期间,随机掩盖指令令牌的一个子集,并训练模型使用融合的视觉上下文来重构它们,以增强指令理解并促进令牌级注意力。
- 掩码视图分类(MVC):在训练期间掩盖一部分全景视图,并要求模型预测它们的语义类别,以鼓励视觉令牌的语义区分。
- 对象定位(OG):对于涉及对象级定位的任务,添加辅助损失,训练模型在最终位置定位指令所指的正确对象。
- 总损失:总训练目标是上述组件的加权组合,通过联合训练目标,使MFRA能够学习跨模态的语义丰富且对齐良好的表示,同时定位对象引用并增强指令条件推理。
实验
数据集与评估指标
- 数据集:
- REVERIE:提供高级导航指令,平均长度21词。每个全景节点包含预定义的对象边界框,智能体需在导航路径终点识别目标对象。轨迹长度为4到7步。
- SOON:指令更长更复杂,平均长度47词,不包含预定义边界框。智能体需使用对象检测器预测对象中心位置。路径长度为2到21步。
- R2R:包含逐步导航指令,平均长度32词,平均轨迹长度6步,专注于空间导航,无明确对象定位任务。
- 评估指标:
- Trajectory Length (TL):导航路径的平均长度。
- Navigation Error (NE):智能体最终位置与目标之间的平均距离。
- Success Rate (SR):导航误差小于3米的剧集百分比。
- Oracle Success Rate (OSR):假设采用Oracle停止策略的SR。
- SPL:按路径效率加权的SR。
- Remote Grounding Success (RGS):成功定位指令的比率(仅限REVERIE和SOON)。
- RGSPL:按路径长度加权的RGS。
实验结果与分析
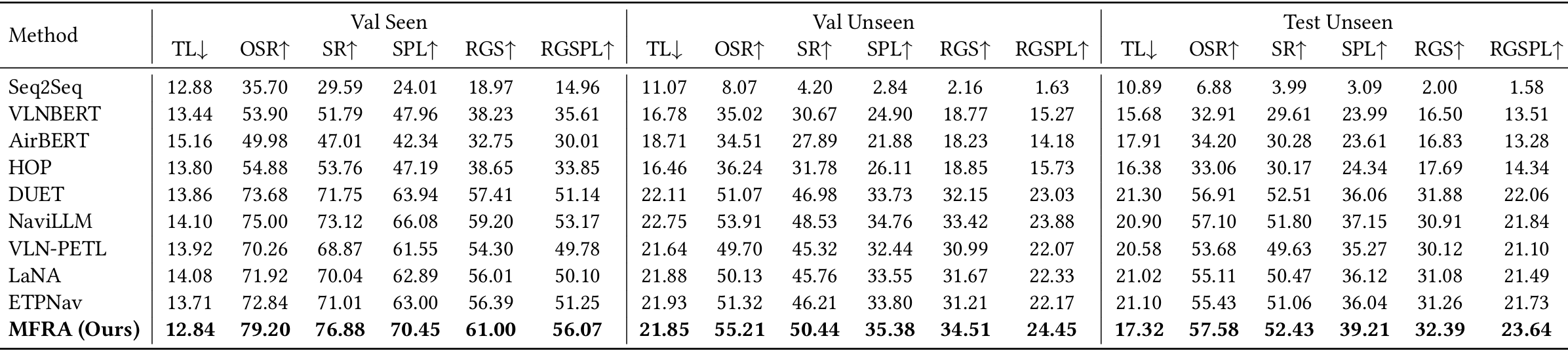
- 在R2R数据集上,MFRA与其他多种代表性最新方法相比,在所有评估指标上均展现出优越性。例如,与DUET相比,在验证集上SR提升了5.13%,SPL提升了6.51%。
- 与NaviLLM和ETPNav等最新方法相比,MFRA在SR和RGS上具有2%到5%的明显优势,即使这些方法利用了大型语言模型先验和演变拓扑规划。
- VLN-PETL和LaNA等方法在参数高效调整和双向语言理解方面表现出色,但在导航准确性方面仍低于MFRA,尤其是在面对领域变化和对象模糊性时。
- MFRA从已见到未见环境的性能下降幅度远小于基线方法,显示出更强的泛化能力,这归功于使用CLIP基础的多模态特征进行大规模语言监督训练,以及统一的DIRformer融合主干支持模态不变表示学习。
- 动态多头转置注意力和门控前馈网络的集成使模型能够选择性地关注与指令相关的区域,提高跨模态语义对齐和决策信心。与AirBERT或VLNBERT等以对象为中心的方法相比,MFRA受益于事实级定位机制,能够捕捉到超出静态对象标签的丰富上下文信息,使智能体能够在指令中推理出细粒度视觉线索和高级语义引用。
- 结论:MFRA能够学习到鲁棒的、可泛化的、语义上定位良好的导航策略,在不同条件下的指令复杂性、场景多样性和任务要求方面均优于现有方法。

消融研究
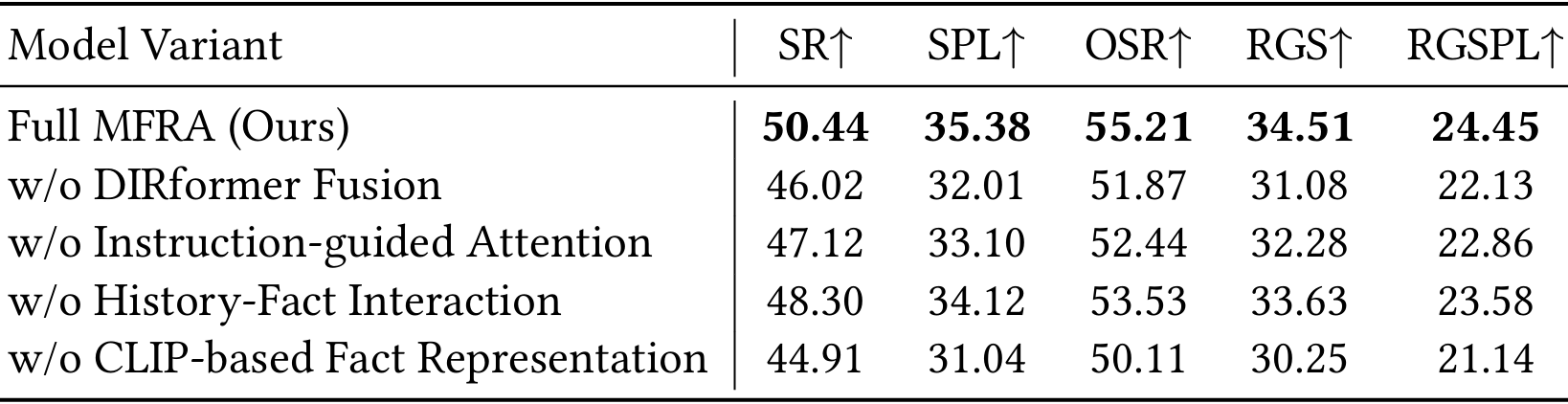
通过在REVERIE验证集上逐步移除或修改MFRA架构中的关键模块,评估其对导航和定位性能的影响。
- 移除层次化DIRformer融合模块会导致性能显著下降,SR下降4.42%,RGSPL下降超过2.3%,表明多级跨模态推理在MFRA中起着核心作用。
- 禁用指令引导的注意力模块也会降低SR和RGS,说明指令级抽象与视觉上下文之间的语义对齐对于准确决策至关重要。
- 排除历史-事实交互模块会导致中等程度的性能下降,表明时间信息对全局上下文推理有实质性贡献。
- 用传统的CNN+LSTM表示替换CLIP基础的事实特征会导致在导航和定位准确性方面最大的整体性能下降,证明预训练的多模态嵌入提供了卓越的语义对齐能力。
- 结论:MFRA中的每个模块,尤其是DIRformer融合和CLIP基础表示,对于实现准确且可泛化的指令定位导航至关重要。
多模态特征贡献分析
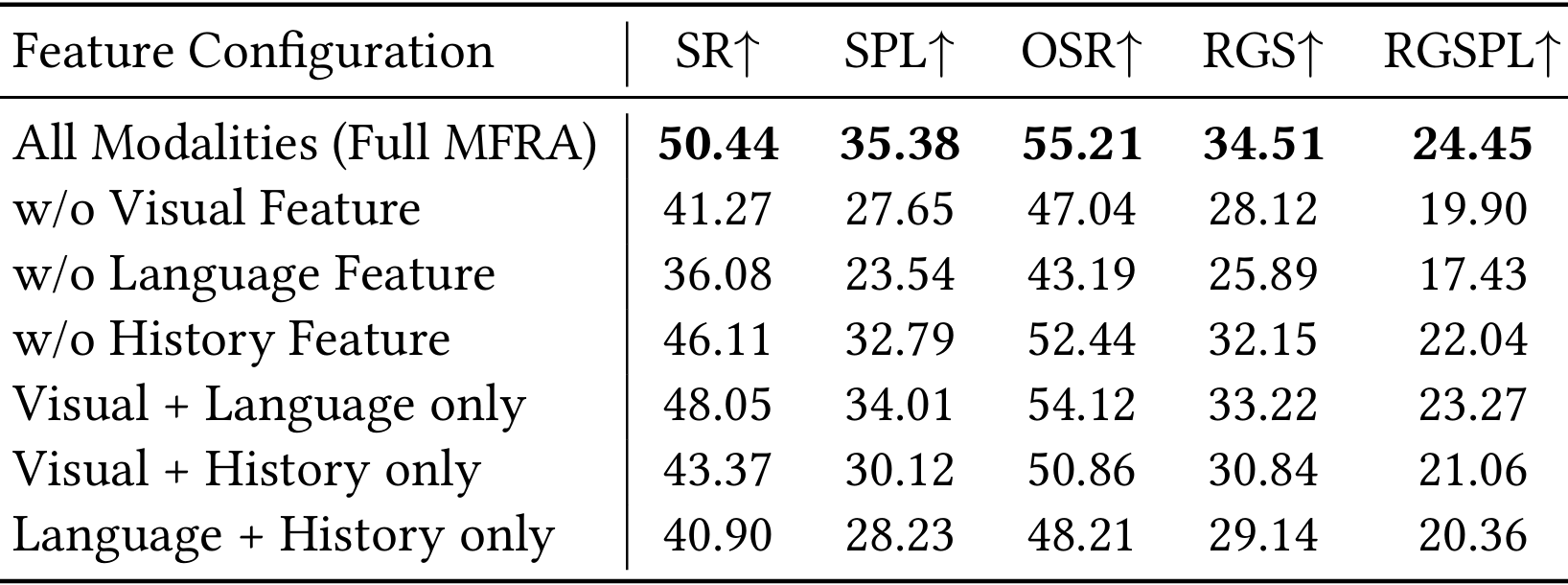
通过选择性地从多模态推理过程中移除视觉、语言或历史组件,分析各个模态对MFRA性能的贡献。
- 移除视觉模态会导致所有指标的性能急剧下降(SR下降9.17%,RGSPL下降4.55%),表明基于视觉的场景理解对于视觉定位至关重要。
- 排除指令输入会导致最大的性能下降(SR下降14.36%,RGSPL下降7.02%),因为语言提供了指导智能体决策的高级语义指导。
- 历史特征在定位导向指标中也有显著贡献,移除它会导致RGSPL下降2.41%。
- 进一步分析部分模态组合,发现视觉和语言特征单独可以支持合理的性能(48.05%的SR),但加入历史特征可以带来额外的增益,凸显了时间上下文的重要性。相比之下,仅使用语言和历史而不进行视觉定位会导致性能显著下降。
- 结论:视觉、语言和历史三种模态在支持有效导航和定位方面发挥了互补作用。
跨数据集评估
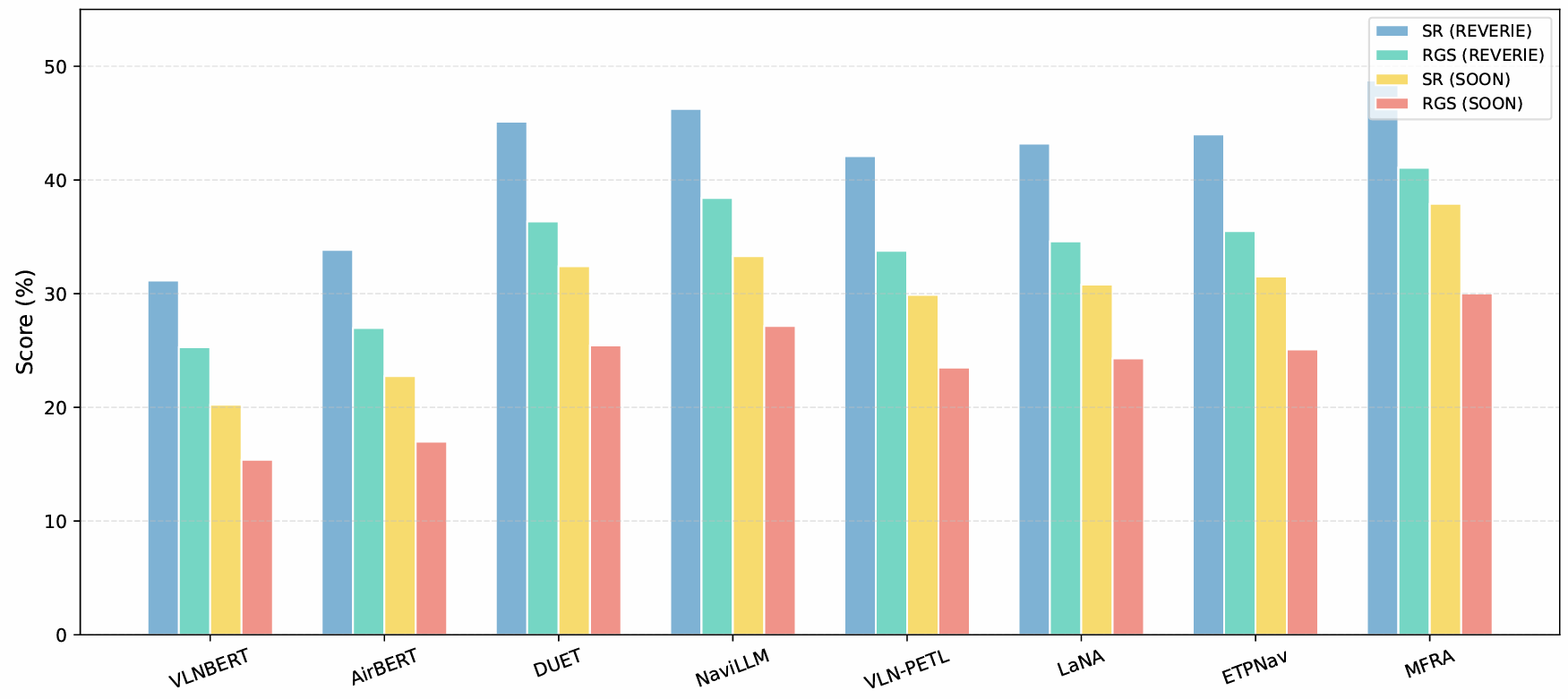
在REVERIE和SOON数据集上进一步评估MFRA的泛化性能,这两个数据集在对象定位和长指令遵循方面提出了更大的挑战。
- 在这两个数据集上,MFRA在成功率(SR)和远程定位成功率(RGS)方面均优于包括VLNBERT、AirBERT、DUET等经典Transformer模型以及NaviLLM、VLN-PETL、LaNA和ETPNav等最新方法。
- 尽管NaviLLM和ETPNav受益于大型语言模型先验或拓扑规划,但它们的性能仍低于MFRA,尤其是在泛化到以前未见过的环境中时。
- VLN-PETL和LaNA引入了参数高效适应和生成能力,但在处理细粒度对象语义和长指令跨度时面临局限性。相比之下,MFRA利用从CLIP派生的统一视觉语言表示,结合基于DIRformer的层次化融合机制,实现了低级视觉线索和高级语义概念之间的有效跨模态对齐和稳健推理。
- 结论:MFRA在多个指令格式和定位要求下的设计具有优越的泛化能力,验证了其在现实具身导航任务中的有效性。
结论与未来工作
- 结论:
- MFRA通过层次化融合和推理机制,有效地整合了视觉、语言和历史信息,显著提升了VLN任务的性能,证明了层次化融合和推理在提高VLN和具身人工智能方面的潜力。
- 未来工作:
- 计划使用更大的训练数据集来改进MFRA,并将其应用于连续环境中的VLN任务。
