Web 开发 28
1 如何安全存储用户名和密码信息
详细解释现有内容
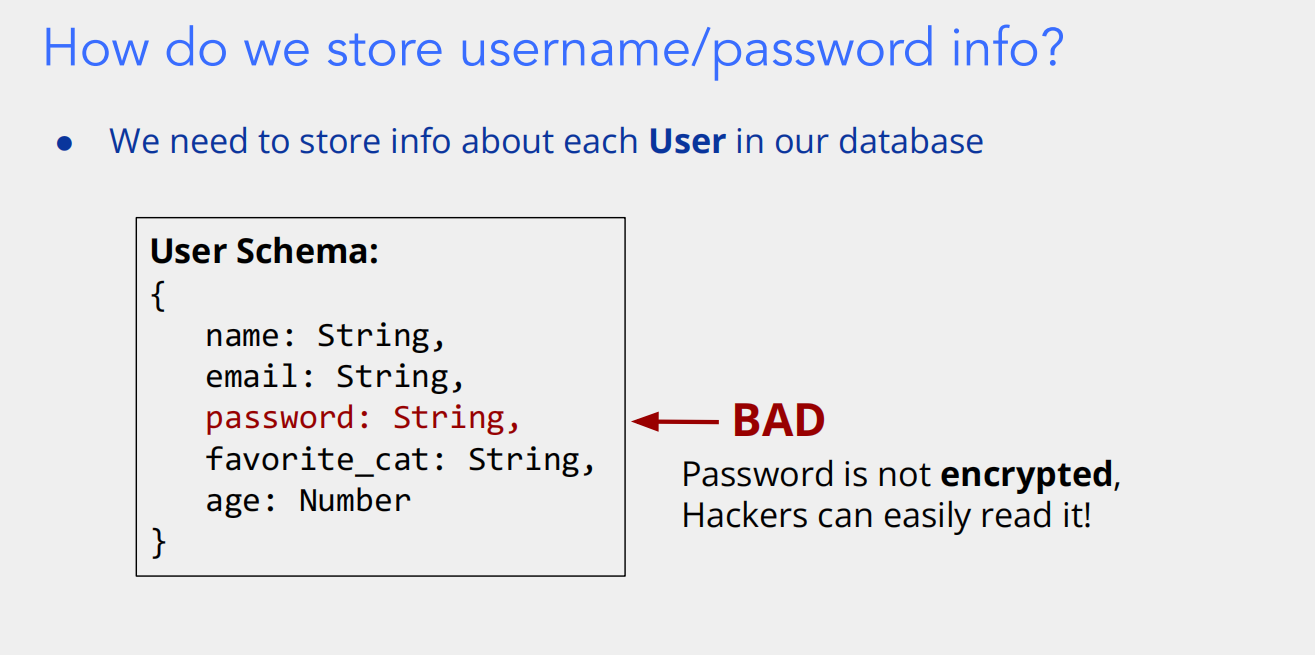
- 首先,幻灯片提出问题 “我们如何存储用户名 / 密码信息?”,并说明需要在数据库中存储每个用户的信息。
- 接着展示了一个
User Schema(用户数据结构),其中包含name(姓名,字符串类型)、email(电子邮箱,字符串类型)、password(密码,字符串类型)、favorite_cat(最喜欢的猫,字符串类型)、age(年龄,数字类型)这些字段。 - 然后用 “BAD” 标注并指出,这种将
password以普通字符串形式存储的方式是 “糟糕的”,因为密码没有被加密,黑客可以很容易地读取到。这是因为如果数据库被入侵,纯文本的密码会直接暴露,导致用户账户面临极大的安全风险,比如黑客可以用这些密码去尝试登录用户的其他账户(很多用户有在多个平台使用相同密码的习惯)。
扩展:正确的密码存储方式
为了保障密码安全,不能直接存储明文密码,通常采用 ** 哈希(Hash)结合盐值(Salt)** 的方式:
- 哈希:哈希函数是一种单向加密函数,它能将任意长度的输入(这里是密码)转换为固定长度的输出(哈希值)。并且从哈希值很难反向推导出原始密码。例如,常用的哈希算法有 SHA - 256 等。
- 盐值:盐值是一个随机生成的字符串,在对密码进行哈希之前,将盐值与密码拼接在一起,然后再进行哈希运算。这样做的好处是,即使两个用户使用了相同的密码,由于盐值不同,最终的哈希值也会不同,能有效防止 “彩虹表”(一种预先计算好的、用于快速破解哈希密码的表)攻击。
当用户登录时,系统会将用户输入的密码,与该用户对应的盐值拼接后进行哈希,然后将得到的哈希值与数据库中存储的该用户的密码哈希值进行比对,如果一致则登录成功,这样既保证了密码不会以明文形式存储,又能验证用户身份。
人们想象中的黑客行为和现实中的黑客行为

左边:人们想象的黑客操作
画面里,黑客们好像执行了很 “硬核” 的任务 —— 飞到美国、闯入目标房屋,然后发现目标把所有密码都写在一本标着 “密码” 的本子里,黑客还大喊 “蠢货!”。这是人们常想象的黑客场景:充满 “特工式” 的冒险,靠翻找物理记录(比如密码本)来获取密码。
右边:现实中的黑客操作
画面里,两个人很轻松地坐在电脑前,看到有人泄露了 “碎嘴合唱团(Smash Mouth,一支乐队)留言板” 的邮箱和密码,就说 “酷,咱们去 Venmo(一款支付应用)上试试这些(账号密码)”。这才是更常见的现实情况:黑客更多是利用数据泄露事件(比如某网站的用户信息被非法获取并公开),拿到一批账号密码后,去其他平台(因为很多人会在不同平台用相同 / 相似的账号密码)尝试登录,从而非法访问用户账户。
简单说,漫画讽刺了一种认知偏差:大家总觉得黑客要搞很 “戏剧化” 的操作,实际多数时候,黑客是靠 “捡漏”(利用已泄露的弱密码 / 重复密码)来搞破坏的。
2 密码哈希加盐(Password Hash Salting)
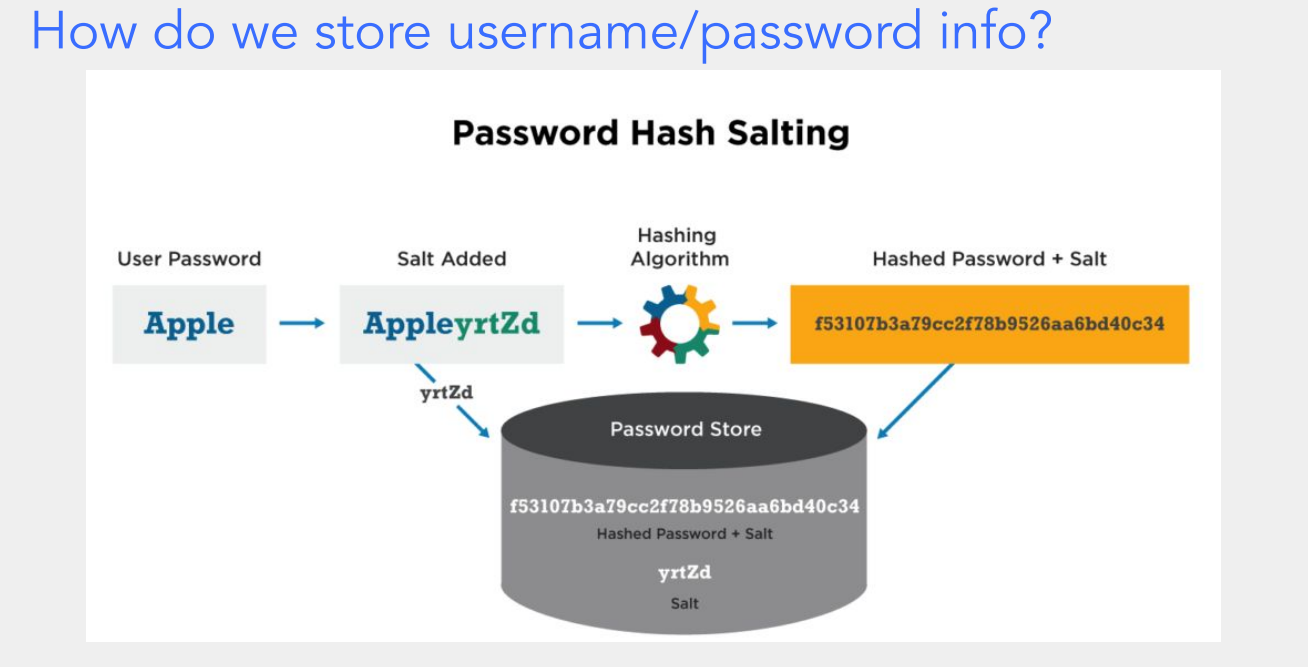
第一步:先理解核心问题 ——“为啥不能直接存密码?”
如果直接把用户密码(比如 “Apple”)以明文存在数据库里,一旦数据库被黑客入侵,所有密码就会被直接看到,用户账号就全暴露了,特别危险。所以得把密码 “变个样”,让别人就算拿到数据库里的内容,也认不出原来的密码。
第二步:认识 “哈希(Hashing)”—— 把密码变 “乱码”
哈希是一种单向加密的操作:给它一个输入(比如密码 “Apple”),它会生成一个固定长度的 “哈希值”(类似乱码的字符串)。
- 特点 1:不可逆。从哈希值,几乎没法反推出原来的密码(就像把饺子包成了馄饨,没法再变回饺子原样)。
- 特点 2:相同输入,相同输出。如果两次输入都是 “Apple”,生成的哈希值肯定一样。
- 但有个问题:如果很多人都用 “Apple” 当密码,那他们的哈希值也会一样。黑客可以提前做一个 “常用密码 - 哈希值” 的对照表(叫 “彩虹表”),直接通过哈希值反查密码,这就有风险了。
第三步:引入 “盐(Salt)”—— 让相同密码也有不同的 “乱码”
“盐” 是一个随机生成的字符串(比如图里的 “yrtZd”)。给每个用户的密码都配一个独一无二的盐,然后把 “密码 + 盐” 拼接起来,再去做哈希。
具体过程(对应图里的步骤):
- 用户输入密码:用户设置的密码是 “Apple”。
- 添加盐:系统给这个密码随机生成一个盐 “yrtZd”,然后把密码和盐拼在一起,变成 “AppleyrtZd”。
- 哈希运算:用哈希算法(图里的齿轮图标代表哈希算法)处理 “AppleyrtZd”,生成一个哈希值(比如图里的 “f53107b3a79cc2f78b9526aa6bd40c34”)。
- 存储到数据库:数据库里存的不是明文密码 “Apple”,而是两部分:
- 哈希后的密码 + 盐(“f53107b3a79cc2f78b9526aa6bd40c34”);
- 单独的盐(“yrtZd”)。
第四步:登录时怎么验证?
当用户下次登录,输入密码 “Apple” 时:
- 系统从数据库里取出这个用户对应的盐 “yrtZd”;
- 把用户输入的 “Apple” 和盐 “yrtZd” 拼接,得到 “AppleyrtZd”;
- 对 “AppleyrtZd” 做同样的哈希运算,得到一个新的哈希值;
- 把这个新哈希值,和数据库里存的 “f53107b3a79cc2f78b9526aa6bd40c34” 对比:
- 如果一样,说明密码正确,允许登录;
- 如果不一样,说明密码错误,拒绝登录。
第五步:“加盐哈希” 为啥更安全?
- 就算两个用户密码都是 “Apple”,因为各自的盐(比如你的盐是 “yrtZd”,我的盐是 “abc123”)不同,拼接后的数据 “AppleyrtZd” 和 “Appleabc123” 不同,哈希值也完全不同。
- 黑客就算有 “彩虹表”,也没法覆盖 “密码 + 随机盐” 的组合,因为盐是每个用户独有的、随机的,根本提前列不出来。
简单总结就是:加盐哈希让密码存储更安全,既藏起了明文密码,又防住了黑客用 “彩虹表” 批量破解的套路。
3 第三方登录
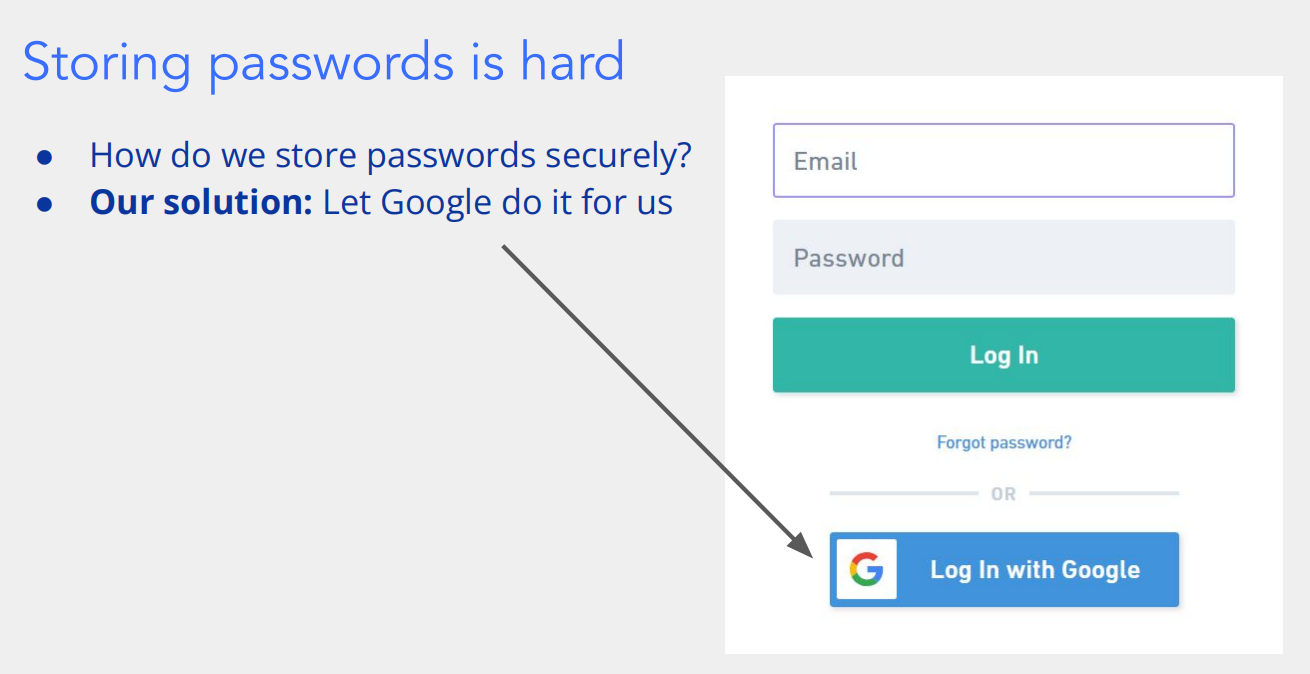
这部分内容围绕第三方登录(以 “通过 Google 登录” 为例)的安全性和原理展开,我们分两部分来详细解释~
第一部分:“Storing passwords is hard(存储密码很难)” 的逻辑
- 首先,“How do we store passwords securely?(我们如何安全存储密码?)” 是个难题:之前讲过,直接存明文密码会被黑客轻易获取;用 “哈希 + 盐” 虽然安全,但对很多小型开发者 / 企业来说,要自己实现完善的密码安全存储(包括防黑客攻击、定期更新安全策略等),技术成本和维护成本都很高。
- 所以才有了 “Our solution: Let Google do it for us(我们的解决方案:让 Google 来为我们做这件事)”:与其自己费力搞密码存储,不如借助 Google 这样的大型平台的身份验证服务。用户通过 “Log In with Google(用 Google 登录)” 按钮,直接用自己的 Google 账号登录第三方网站 / 应用,第三方就不用存储用户密码了,既省了事儿,又更安全(因为 Google 有强大的安全团队和技术来保障账号安全)。
第二部分:“How does the website know that we logged into Google?(网站怎么知道我们登录了 Google?)” 的原理
这背后是OAuth(开放授权)协议在起作用,流程大致如下:
- 用户发起登录请求:当你点击 “Log In with Google” 按钮时,第三方网站会向 Google 发送一个 “授权请求”,请求中包含第三方的身份信息(比如网站的客户端 ID)。
- Google 验证用户身份:Google 会跳转到自己的登录页面(如果用户还没登录 Google,就需要输入 Google 账号密码;如果已经登录,就直接验证通过)。
- 用户授权第三方访问:验证通过后,Google 会让用户确认:“是否允许 [第三方网站名称] 获取你的基本信息(比如姓名、邮箱),以完成登录?” 用户点击 “允许” 后,Google 会生成一个授权令牌(Authorization Token)。
- 令牌传递与验证:Google 把这个授权令牌发送给第三方网站。第三方网站拿到令牌后,会向 Google 发送一个 “令牌验证请求”,问 Google:“这个令牌是你发的吗?是有效的吗?”
- Google 确认令牌有效性:Google 验证令牌有效后,会告诉第三方网站:“没错,这个用户已经成功登录我的系统了,你可以信任。” 同时,还会把用户的基本信息(比如邮箱)一起传给第三方。
- 第三方创建用户会话:第三方网站拿到确认和用户信息后,就知道 “这个用户通过 Google 成功登录了”,于是会为用户创建登录会话(比如生成一个 Cookie 或 Token 存在用户浏览器里),这样用户就能在第三方网站上正常使用了。
简单总结:
- 第一部分是 “为什么选第三方登录”—— 因为自己存密码太麻烦且不安全;
- 第二部分是 “第三方登录怎么实现”—— 靠 OAuth 协议,通过 “请求→验证→授权→令牌传递→验证令牌” 的流程,让第三方网站确认用户已经登录了 Google。
4 用户身份验证后,服务器如何通过请求源 IP 等信息保障后续访问安全
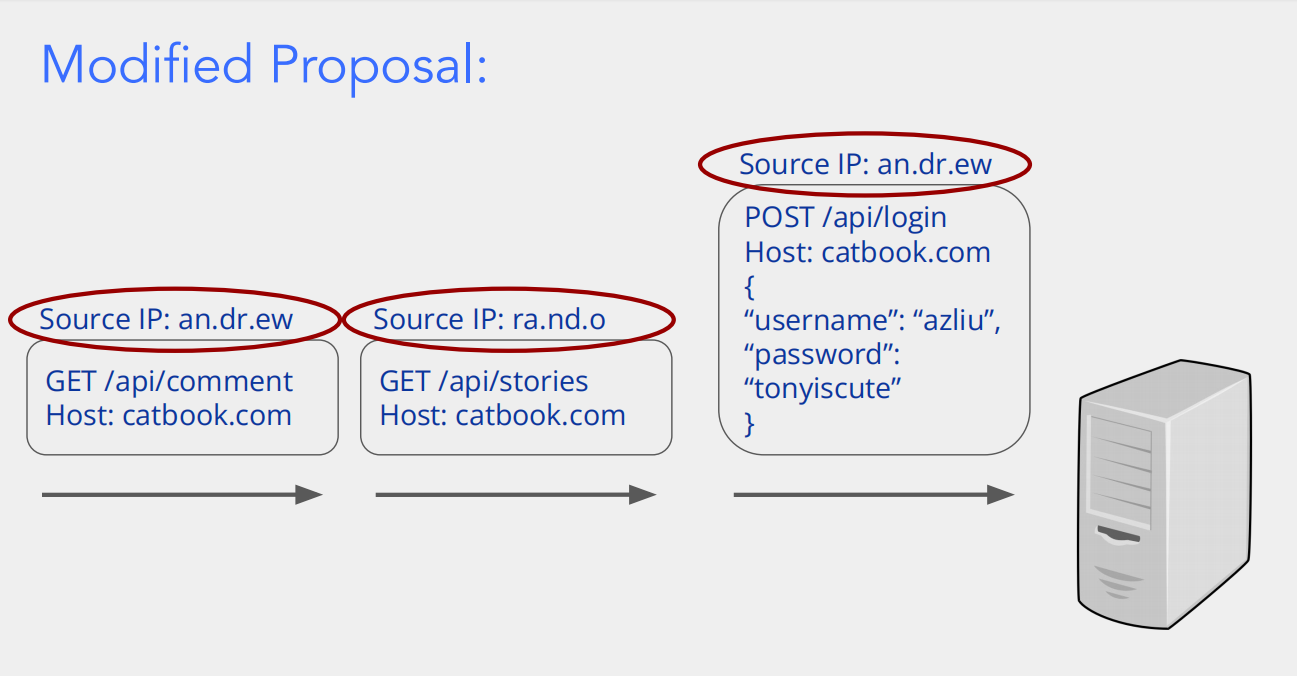
1. 先拆解图中每个请求的含义
图里展示了三个向 catbook.com 服务器发起的网络请求,核心是 “请求的来源 IP(Source IP)” 和 “请求类型 / 内容”:
右侧:登录请求(
POST /api/login)- 这是一个账号密码登录的请求(也可以类比 “第三方登录后,服务器拿到用户身份的‘初始验证’”)。
- 源 IP 是
an.dr.ew,表示 “发起登录的设备 IP 是an.dr.ew”。 - 请求体里有
username: azliu和password: tonyiscute,即用户用账号密码向服务器证明 “我是谁”。
左侧两个请求:资源访问请求(
GET /api/comment和GET /api/stories)- 第一个:
GET /api/comment(获取评论资源),源 IP 也是an.dr.ew—— 说明 “发起登录的同一台设备,在登录后请求了评论资源”。 - 第二个:
GET /api/stories(获取故事资源),源 IP 是ra.nd.o—— 说明 “另一台 IP 为ra.nd.o的设备,请求了故事资源”。
- 第一个:
2. 结合 “第三方登录” 的关联逻辑
第三方登录(比如 “用 Google 登录”)的核心是:委托第三方(如 Google)完成 “用户身份验证”,然后第三方给网站一个 “凭证”,证明 “用户已通过验证”。而这张图,是在更底层的 “登录 / 验证后,服务器如何确保后续请求是合法用户发起的” 层面,补充说明:
场景 1:同一设备后续请求(源 IP 匹配)假设用户是通过 “Google 登录” 完成初始验证的(替代图里的 “账号密码登录”),那么当用户用登录时的设备(IP 为
an.dr.ew) 后续请求api/comment时:服务器会验证 “源 IP 是否和‘登录时的设备 IP’一致”,再结合 “Google 给的身份凭证是否有效”,来判断 “这个请求是不是登录用户本人发起的”。如果 IP 匹配 + 凭证有效,就允许访问资源。场景 2:陌生设备请求(源 IP 不匹配)若有一台 IP 为
ra.nd.o的设备,请求api/stories:服务器会发现 “这个 IP 不是‘登录时的设备 IP(an.dr.ew)’”,即使请求里有 “看似合法的凭证”,也可能触发 “额外安全验证”(比如要求二次验证、提示风险)—— 因为 “用户登录用的是an.dr.ew,现在突然有陌生 IP 来请求资源,可能是黑客伪造凭证”。
3. 核心结论
这张图想表达的是:不管是 “账号密码登录” 还是 “第三方登录”,服务器除了验证 “用户身份凭证(密码或第三方凭证)”,还会通过 “源 IP” 等信息,判断 “请求是不是登录用户的常用设备发起的”,从而进一步保障 “登录后的数据安全”—— 防止 “凭证被盗后,黑客用其他设备非法访问资源”。
5 设计安全、可靠、不依赖不可信客户端的验证机制需求

这段内容聚焦于网站身份认证的核心问题,尤其是在涉及第三方登录(如谷歌登录)以及用户登录后持续操作的场景下,如何安全且可靠地验证用户身份,且强调 “不依赖客户端(即不能只相信用户设备侧的信息,要从服务端等更可信的角度去验证)”。下面分部分详细解释:
左侧内容
“When logging in to our website with google or another third-party service...”意思是:当使用谷歌或者其他第三方服务(比如 Facebook、Twitter 等提供的身份认证服务)登录我们的网站时……
“How do we prove to our website that we logged in to Google?”这是在问:我们要如何向我们的网站证明 “我们已经成功登录了谷歌(账号)”?
背后的逻辑是:很多网站支持 “第三方登录”,比如用谷歌账号直接登录某个网站,而不用单独注册该网站的账号。但此时,网站需要确认 “用户确实是合法的谷歌账号持有者,且已经通过谷歌的认证了”。如果网站直接相信用户说 “我登录谷歌了”,是不安全的(比如可能有伪造情况),所以得有一套机制,让网站能从可靠的渠道(比如和谷歌的服务端进行验证交互)确认这一点。
右侧内容
“After we’ve logged into our website and are making subsequent requests...”意思是:在我们已经登录到我们的网站之后,进行后续的请求(比如登录后,点击查看个人信息、提交订单、发表评论等操作,都需要向网站服务器发请求)时……
“How do we prove to our website that we already logged in?”这是在问:我们要如何向我们的网站证明 “我们已经(在这个网站上)登录过了”?
背后的逻辑是:用户登录网站后,不会只做一次操作,后续还会有很多和网站的交互。但 HTTP 协议本身是 “无状态” 的,也就是网站服务器默认记不住 “这个用户之前已经登录过了”。如果每次操作都让用户重新登录,体验很差;
但如果直接相信用户设备里存的 “登录标记”(比如客户端的 cookie),又可能被篡改或伪造。所以需要一种机制,让用户在后续操作时,能向网站证明 “我之前确实合法登录过,现在是合法用户在操作”,同时这种证明还得是可靠的,不能被轻易欺骗。
底部内容
“Without trusting the client!”意思是:(要实现上述验证)不能依赖 / 信任客户端(这里的 “client” 可以理解为用户的浏览器、手机 APP 等用户侧的设备或程序)!
这是核心的约束条件。因为客户端的环境是 “不可信” 的 —— 用户可能会修改客户端的代码、数据(比如伪造 cookie、篡改本地存储的登录状态),所以网站的身份验证机制,不能只看客户端传来的信息,必须有服务端(网站自己的服务器)主导的、更安全的验证逻辑。比如,通过服务端生成并验证 token(令牌)、session(会话)等方式,来确保身份验证的可靠性。

总结一下,这段内容是在探讨网站身份认证的两个关键场景(第三方登录时的身份溯源、登录后持续操作的身份保持)下,如何设计安全、可靠、不依赖不可信客户端的验证机制,来证明用户的合法身份。
6 session
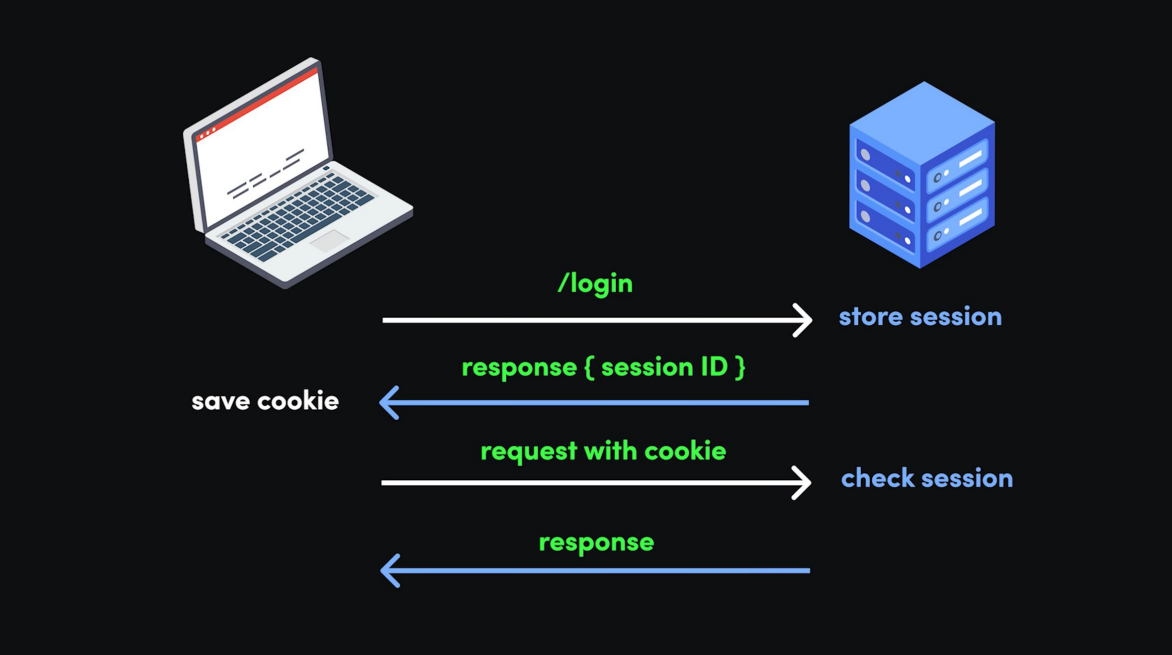
这张图展示了 Session(会话)机制 在 Web 身份认证中的完整流程,下面一步步详细拆解:
步骤 1:用户发起登录请求
左侧的笔记本电脑代表客户端(用户的浏览器 / 设备),右侧的蓝色服务器代表服务端(网站的后台服务器)。当用户在客户端输入账号密码,点击 “登录” 时,客户端会向服务端发送一个 /login 请求(可以理解为 “告诉服务器:我要登录啦”)。
步骤 2:服务端创建 Session 并返回 Session ID
服务端收到 /login 请求后,会做两件事:
- 验证用户身份:检查账号密码是否正确。如果正确,说明用户是 “合法用户”。
- 创建 Session:服务端会生成一个唯一的 “会话”(Session),里面存储着该用户的登录状态、权限等信息(比如 “用户 A 已登录,权限是普通会员”)。
- 返回 Session ID:服务端不会把整个 Session 都传给客户端(太占空间且不安全),而是生成一个Session ID(相当于 “会话的身份证号”),并通过
response { session ID }(响应消息)把这个 ID 传给客户端。
步骤 3:客户端保存 Cookie(存储 Session ID)
客户端收到服务端返回的 session ID 后,会把这个 ID 存到 Cookie 里(图中 “save cookie”)。Cookie 是客户端(浏览器)的一种存储机制,专门用来存一些小数据(比如 Session ID),而且后续请求会自动带着这些数据发给服务端。
步骤 4:客户端带 Cookie 发起后续请求
用户登录后,后续要做其他操作(比如查看个人信息、下单等),客户端会再次向服务端发请求。这时候,客户端会自动把存着 Session ID 的 Cookie 一起发给服务端(图中 “request with cookie”),相当于 “告诉服务器:我是刚才登录的那个用户,这是我的会话身份证号”。
步骤 5:服务端验证 Session 并响应
服务端收到带 Cookie(含 Session ID)的请求后,会:
- 查找 Session:用 Cookie 里的 Session ID,去服务端自己存储的 “Session 列表” 里找对应的 Session。
- 验证状态:如果找到 Session,并且 Session 里的 “登录状态” 是有效的,就说明 “这个用户确实已经登录过,是合法的”。
- 返回响应:服务端会处理用户的请求(比如返回个人信息页面),并通过
response把结果发给客户端。
总结 Session 机制的核心逻辑
Session 是服务端主导的 “会话跟踪” 机制:
- 服务端存完整的 Session 数据(用户状态、权限等),客户端只存 “Session ID”(通过 Cookie)。
- 每次请求都靠 “Session ID + 服务端 Session 验证”,确保 “用户是已登录的合法身份”,从而实现 “登录后持续识别用户” 的效果。

会话(Session)存储在服务器上:
这体现的是Web开发中Session机制的一个核心特点:Session相关的数据是存储在服务器端的,而不是客户端(比如浏览器),这样能更好地保障用户身份认证等信息的安全性与可靠性,因为服务器端相对客户端更不易被非法篡改。
7 tokens




这些图片展示了两种 Web 身份认证机制:Token(以 JWT 为例)和Session。
一、Token 机制(以 JWT 为例)
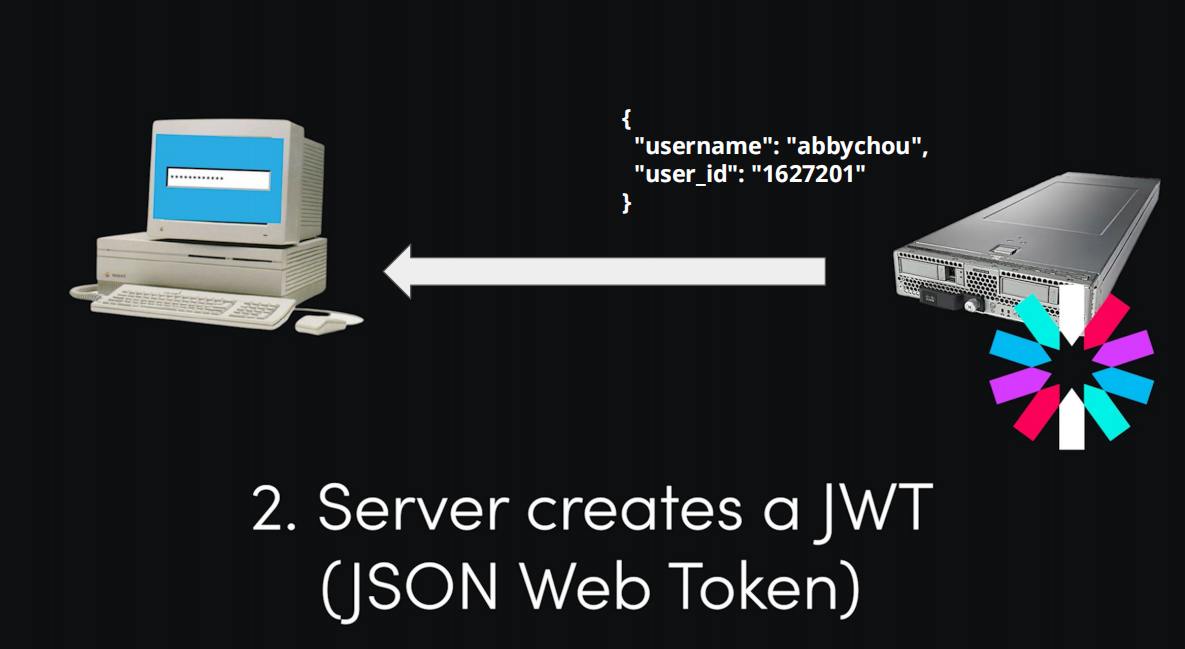
步骤 1:用户提交登录表单
左侧的老式电脑代表客户端(浏览器 / 用户设备),用户在登录界面输入账号密码后,点击 “登录”,客户端通过 HTTP 协议向右侧的服务器发送登录请求(把账号密码等信息传给服务器)。
步骤 2:服务器创建 JWT(JSON Web Token)
服务器收到登录请求后:
- 验证用户身份:检查账号密码是否正确。如果正确,说明用户是 “合法用户”。
- 生成 JWT:服务器会根据用户信息(比如图中的
username: "abbychou"、user_id: "1627201"),生成一个 JWT(JSON Web Token)。JWT 是一串经过加密签名的字符串,里面包含了用户的身份信息(相当于 “带签名的身份凭证”)。 - 返回 JWT:服务器把生成的 JWT 作为响应,发回给客户端。
步骤 3:浏览器存储 JWT 到本地存储
客户端(浏览器)收到服务器返回的 JWT 后,会把这个 JWT ** 存到 “本地存储(Local Storage)”** 里。本地存储是浏览器提供的一种存储方式,专门用来存一些数据(比如 Token),方便后续请求时取用。
步骤 4:后续请求携带 JWT,服务器验证
当用户后续要进行操作(比如查看个人信息、下单等),客户端会:
- 从本地存储取出 JWT;
- 在请求的 **“Authorization” 头 ** 里带上这个 JWT(格式是
Authorization: Bearer <token>,<token>就是 JWT 字符串); - 服务器收到请求后,会验证 JWT 的签名(确保没被篡改),并解析出里面的用户信息(比如
username、user_id); - 验证通过后,服务器就知道 “这个用户是合法登录的”,然后处理请求并返回响应。
二、Session 机制
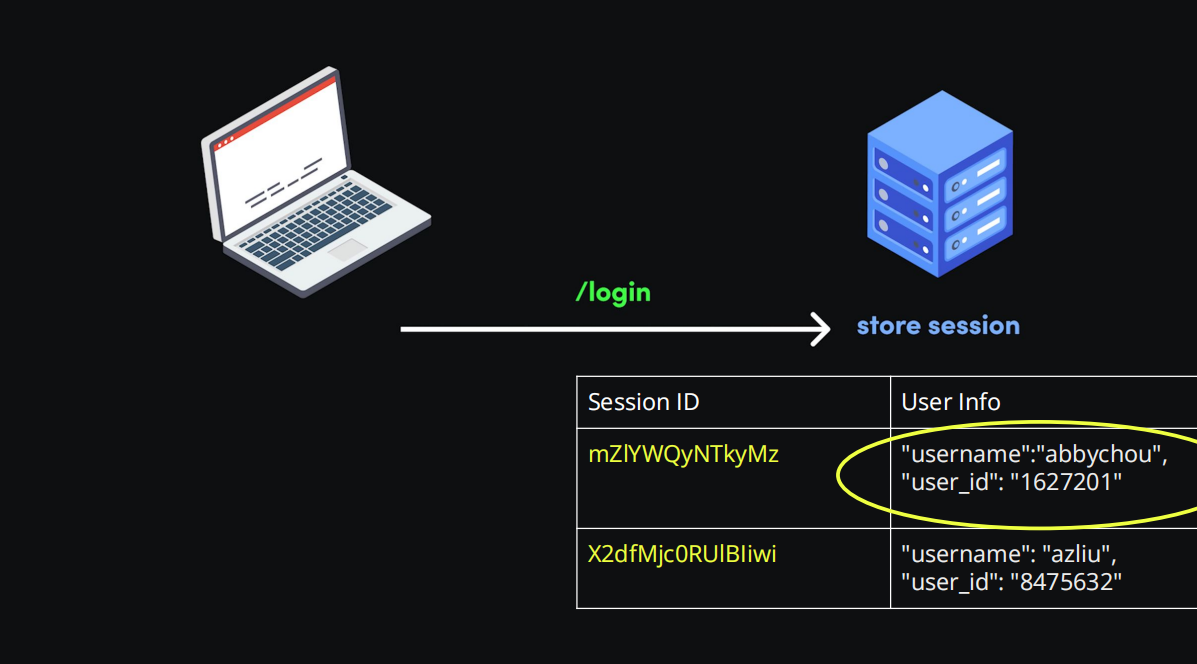
步骤:用户登录,服务器存储 Session
左侧的笔记本电脑代表客户端,用户发起 /login(登录)请求到右侧的服务器后:
- 服务器验证用户身份:检查账号密码是否正确。
- 创建 Session:如果验证通过,服务器会生成一个唯一的 Session(会话),并在 Session 里存储用户信息(比如图中
username: "abbychou"、user_id: "1627201")。 - 存储 Session:服务器把 Session 存到自己的存储系统里(比如内存、数据库),同时生成一个Session ID(相当于 “会话的身份证号”)。
- 返回 Session ID:服务器把 Session ID 通过响应发给客户端,客户端通常会把 Session ID 存到 Cookie 里(Cookie 是浏览器存储小数据的另一种方式,后续请求会自动携带)。
两种机制的核心区别
| 特点 | Token(JWT)机制 | Session 机制 |
|---|---|---|
| 存储位置 | Token 存在客户端(浏览器本地存储、Cookie 等) | Session 存在服务端(服务器自己的存储里) |
| 验证方式 | 服务器验证 Token 的签名和内容,无需查服务端存储(因为 Token 里带了用户信息 + 签名) | 服务器用 Session ID 查服务端存储的 Session,验证用户状态 |
| 扩展性 | 适合分布式系统(多台服务器之间,只要有 Token 就能验证,不用共享 Session 存储) | 分布式场景下,需要共享 Session 存储(比如 Redis 集群),否则多服务器之间认不出 Session |
| 安全性 | 签名机制能防止 Token 篡改,但 Token 一旦泄露,别人能直接用(所以要注意过期时间、传输加密) | Session ID 存在 Cookie 里,若被窃取也有风险,但 Session 本身存在服务端,相对更 “集中可控” |
简单来说:
- Token(JWT) 是 “把身份信息加密后给客户端自己存,服务器靠签名验证”;
- Session是 “服务器自己存身份信息,客户端只存一个‘身份证号(Session ID)’,服务器靠查自己的存储验证”。
两种机制各有优缺点,要根据项目的场景(比如是否分布式、对性能 / 安全的要求)选择。
8 关于 “catbook 如何管理登录”

在这段文本中,“auth” 是 “authentication ” 的缩写,意为身份验证 ,指的是确认用户身份的过程,即验证用户是否是其声称的人。
结合文本内容,关于 “catbook 如何管理登录” 有以下几点:
- 分离身份验证服务器和资源服务器:存储密码是一项具有挑战性的任务,所以选择让谷歌来处理身份验证工作。这是因为谷歌在身份验证方面有成熟的技术和较高的安全性保障,能降低 catbook 在密码存储与验证方面的安全风险。
- 初始登录:使用谷歌账号进行登录,并且采用 JSON Web Tokens(JWT) 令牌机制。当用户通过谷歌账号登录 catbook 时,系统会生成 JWT,里面包含用户的身份信息等内容,用于在后续的请求中证明用户的身份。
- 保持登录状态:采用基于 Express.js 的会话(sessions)机制。Express.js 是一个流行的 Node.js Web 应用框架,通过会话机制可以在用户登录后,在一段时间内记住用户的登录状态,使得用户在进行后续操作时无需反复登录 。
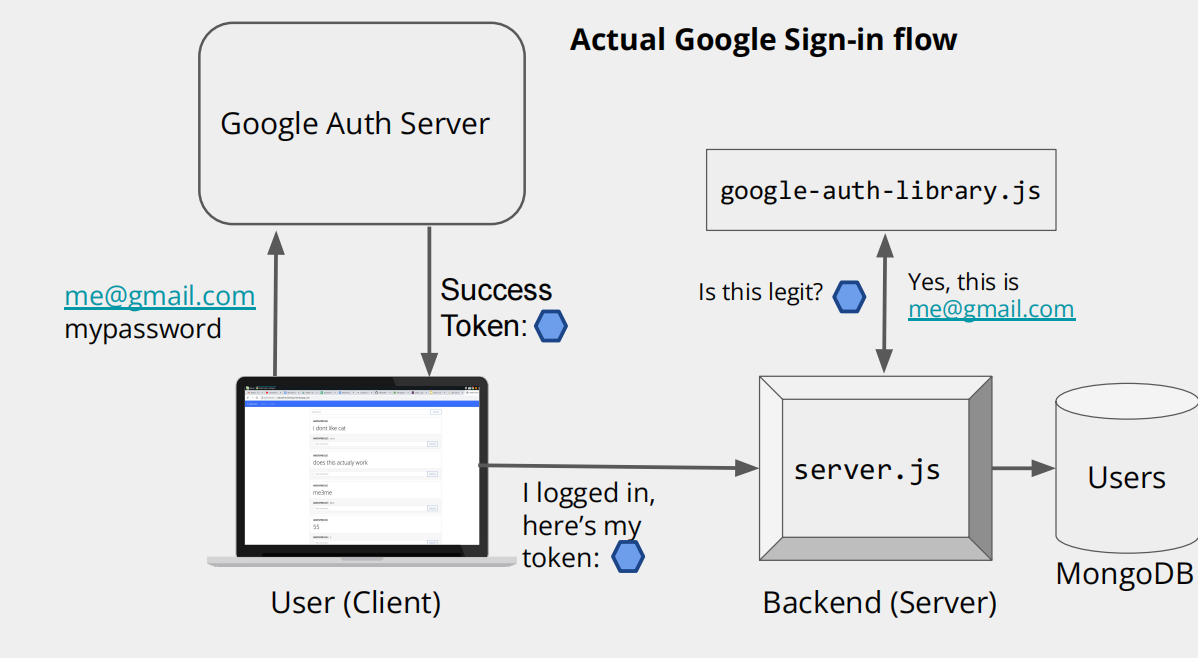
9 登录流程
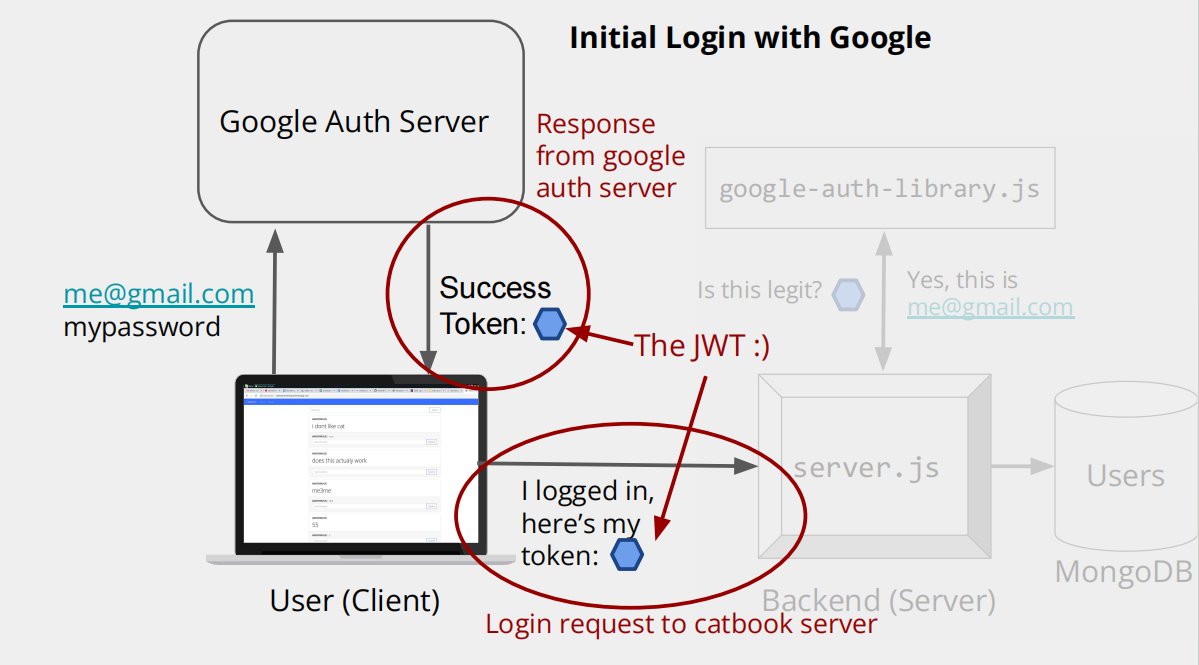
先看第一张图:Initial Login with Google(用谷歌初始登录的流程)
咱们把流程拆成一步步的角色互动,角色有:你(User/Client,用笔记本代表)、谷歌认证服务器(Google Auth Server)、catbook 的后端服务器(Backend/Server,用server.js等表示)。
步骤 1:你向谷歌提交账号密码
你在自己的设备(笔记本)上,输入谷歌账号(比如me@gmail.com)和密码(mypassword),然后把这些信息发给谷歌认证服务器(Google Auth Server),请求 “我要登录谷歌,证明我是这个账号的主人”。
步骤 2:谷歌认证服务器返回 “成功令牌(JWT)”
谷歌认证服务器收到你的账号密码后,会验证 “这账号密码对不对”。如果是对的,就会生成一个 **“成功令牌(Success Token)”**,这个令牌是 JWT(JSON Web Token)(图里标了The JWT :),JWT 是一种安全的 “身份凭证”,里面存了你的身份信息,还加了密防止篡改)。然后谷歌把这个 JWT 发给你(你的设备)。
步骤 3:你带着 JWT 找 catbook 服务器登录
你拿到谷歌给的 JWT 后,就去给catbook 的后端服务器发请求,说:“我登录谷歌成功啦,这是我的令牌(JWT),你看我能登录 catbook 不~”
步骤 4:catbook 服务器验证 JWT
catbook 的后端服务器收到你的 JWT 后,会用google-auth-library.js(谷歌提供的验证工具库)来检查这个 JWT “是不是合法的”。验证的时候,会确认 “这个 JWT 是不是谷歌真的发的,里面的身份信息对不对”。如果验证通过,服务器就知道 “哦,这确实是me@gmail.com的用户”,然后让你成功登录 catbook~
再看第二张图:Actual Google Sign-in flow(实际谷歌登录的完整流程)
这张图是更 “真实” 的流程,和第一张核心逻辑一样,只是更清晰展示各部分互动:
步骤 1:你向谷歌发账号密码
和第一张图步骤 1 一样,你把me@gmail.com和mypassword发给谷歌认证服务器。
步骤 2:谷歌发 JWT 给你
谷歌验证通过后,把 JWT(Success Token)发给你(你的设备)。
步骤 3:你带 JWT 找 catbook 服务器
你拿着 JWT,给 catbook 的server.js(后端核心代码)发请求:“我有 JWT,我要登录 catbook~”
步骤 4:catbook 服务器验证 + 处理用户数据
catbook 的服务器用google-auth-library.js验证 JWT 的合法性。验证通过后,服务器会去MongoDB(图里的数据库)里处理你的用户数据(比如查有没有你的账号、存你的登录状态等),最后让你成功登录,能正常用 catbook 的功能~
总结一下核心逻辑
整个流程就是:借助谷歌的 “身份认证能力”,用 JWT 当 “通行证”,让 catbook 相信 “你是你声称的谷歌账号用户”,从而完成登录。这样 catbook 不用自己存你的密码(因为密码是谷歌在管),既安全又方便~
10 详细说明JWT的加密方式和原理
JSON Web Token(JWT)是一种开放标准(RFC 7519),用于在网络应用中安全传输信息。它通常由三部分组成:头部(Header)、载荷(Payload)、签名(Signature),不同部分在加密和验证过程中发挥着不同的作用,以下是其加密方式和原理的详细说明:
1. 头部(Header)
- 内容:通常由两部分信息组成,令牌的类型(即 JWT)和使用的签名算法,如 HMAC SHA256 或 RSA 。示例:
{"alg": "HS256","typ": "JWT"
}
这里alg表示使用的签名算法是 HMAC SHA256,typ表示这是一个 JWT。
- 加密方式:将上述 JSON 对象进行 Base64Url 编码,得到 JWT 的第一部分。Base64Url 编码和传统的 Base64 编码类似, 只是对 URL 和文件名友好,会把
+和/分别替换成-和_,并且去掉了末尾的=。
2. 载荷(Payload)
- 内容:包含声明(claims),这些声明是关于实体(通常是用户)和其他数据的陈述。有三种类型的声明:注册声明(如 iss,exp,sub 等)、公共声明和私有声明 。示例:
{"sub": "1234567890","name": "John Doe","iat": 1516239022
}
上述示例中,sub是主题(subject),name是用户名,iat是令牌的签发时间(issued at)。
- 加密方式:同样对这个 JSON 对象进行 Base64Url 编码,得到 JWT 的第二部分。不过需要注意,载荷部分虽然被编码了,但并没有加密,任何人都可以解码它的内容, 所以不要在里面放置敏感信息(比如密码)。
3. 签名(Signature)
- 生成方式:为了创建签名部分,你需要使用编码后的头部、编码后的载荷、一个密钥(secret)和头部中指定的签名算法(如 HMAC SHA256)。示例,使用 HMAC SHA256 算法创建签名的公式如下:
HMACSHA256(base64UrlEncode(header) + "." +base64UrlEncode(payload),secret)
其中,secret是只有服务器知道的密钥,用于验证消息在传输过程中没有被更改,并且在使用私钥签名的情况下,还可以验证 JWT 的发送者的身份。
4. 验证和使用 JWT
- 验证流程:当接收方(如服务器)接收到 JWT 时,会进行以下验证步骤:
- 首先对 JWT 进行拆分,得到头部、载荷和签名部分;
- 验证头部中的签名算法是否是自己支持的;
- 使用头部指定的签名算法,结合存储的密钥,对编码后的头部和编码后的载荷进行签名计算,将计算结果与接收到的签名进行对比。如果两者一致,说明 JWT 是合法的,没有被篡改;同时,还可以根据载荷中的相关声明(如过期时间等)判断 JWT 是否有效。
- 使用场景:一旦 JWT 通过验证,接收方就可以从载荷中获取用户相关信息(如用户 ID、用户名等), 并基于这些信息进行权限控制、身份确认等操作,确认请求来自合法用户,并执行相应的业务逻辑。
5. 加密方式总结
JWT 本身并不是一种加密技术,而是通过 Base64Url 编码对数据进行格式化,然后结合签名算法(对称加密算法如 HMAC,非对称加密算法如 RSA )来确保数据的完整性和真实性,防止数据在传输过程中被篡改,并在一定程度上验证 JWT 的发送者身份。
JWT 的这种设计,使得它在分布式系统、前后端分离应用中,成为了一种非常方便的用户身份认证和信息传输方式, 比如在单点登录(SSO)场景中,不同的服务可以通过验证 JWT 来确认用户身份,而无需各自维护一套复杂的用户认证体系。