自注意力机制、交叉注意力、向量填充、填充掩码、位置编码、多头注意力、层归一化的基本原理
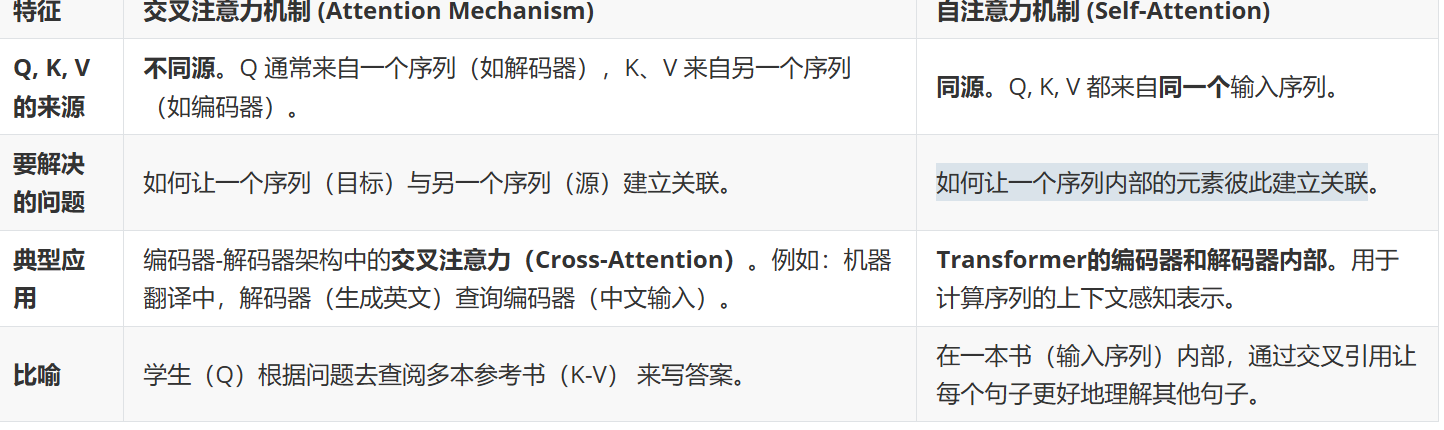
自注意力机制与交叉注意力
(1)自注意力机制
主要关注如何让一个序列内部的元素彼此建立关联
重点是内部
核心思想:让每个词都能“看见”句子中其他词,从而理解上下文关系。
作用:自注意力帮助模型理解句子中词与词之间的依赖关系,尤其是长距离依赖。例如在“我昨天在北京吃了烤鸭”中,“吃”和“烤鸭”的联系能被捕捉到。
(2)交叉注意力机制
核心思想:让“一个序列”关注“另一个序列”的信息
区别
(3)向量填充与填充掩码
向量填充
目的是让一批不同长度的序列在批处理时保持相同长度。
填充掩码
作用:在计算注意力时屏蔽掉填充的PAD部分,避免干扰模型计算。
(4)位置编码
为什么要使用位置编码?
Transformer不使用循环(RNN)或卷积(CNN),因此无法自动知道序列中词的顺序。
位置编码就是告诉模型:
“第一个词在句首,第二个词在中间,第三个词在句尾”。
作用:
给模型注入顺序感;
让模型知道“谁在前,谁在后”;
对应于人类语言的语序理解。

(5)多头注意力
多头注意力的核心目的是让模型能够同时从不同的表示子空间(Different Representation Subspaces)和不同的角度(Different Perspectives)关注输入信息的不同方面。
看下面的例子就能搞懂
单一注意力的局限性
想象一下你在分析一句话:“苹果公司发布了新一代iPhone,它的股价随之上涨。”
现在,我们让一个单一的注意力机制(可以想象成一位专家)来分析这句话。
这位专家会计算一个注意力分布。他可能会发现“苹果”、“iPhone”、“股价”这几个词高度相关。
最终,他可能会给出一个综合性的解读:“这是一条关于科技公司产品的财经新闻。”
这个解读是合理的,但可能丢失了细节。因为一位专家倾向于形成一个统一的、综合性的观点。
但这句话实际上包含了多种不同类型的信息:
词汇关系:“苹果”在这里是一个公司名,而不是一种水果。
语法关系:“它”指代的是“苹果公司”,这是一个指代消解问题。
语义关系:“发布”和“iPhone”是动作与对象的关系。
常识关系:“发布新产品”通常会导致“股价上涨”,这是一种因果逻辑关系。
一位专家(单一注意力)很难同时、同等地捕捉到所有这些迥异的关系。他的最终输出是所有这些关系的“平均值”,可能无法在每一个特定关系上都达到最优。
多头注意力的解决方案
多头注意力的思路是:与其让一位专家做所有事,不如组建一个专家团队,让每位专家专注于不同方面的研究,最后将他们的发现汇总起来。
继续上面的例子:
头一(语法专家):专门关注指代关系。它的注意力会高度集中在(“它”, “苹果公司”)这个对上。它输出的报告是:“‘它’指的是‘苹果公司’。”
头二(实体专家):专门关注实体类型。它的注意力会集中在“苹果”和“公司”上,判断出这是一个组织机构。它输出的报告是:“这里的‘苹果’是一个公司。”
头三(逻辑专家):专门关注因果关系。它的注意力会集中在(“发布”, “股价上涨”)这个对上。它输出的报告是:“发布新产品导致了股价上涨。”
头四(…专家):可以关注其他方面,比如时态、情感等。
最后,模型会将这几位专家的报告(它们各自的输出向量)拼接起来,再通过一个线性变换进行融合,形成一个极其丰富、全面且精细的最终表示。
这个最终表示的优势在于:它明确地包含了句法、语义、逻辑等多种信息,而不仅仅是它们的混合平均值。
(6)层归一化
规范化每一层的神经元输出,使模型训练更稳定、更快收敛。