Tweedie 公式
学习路径
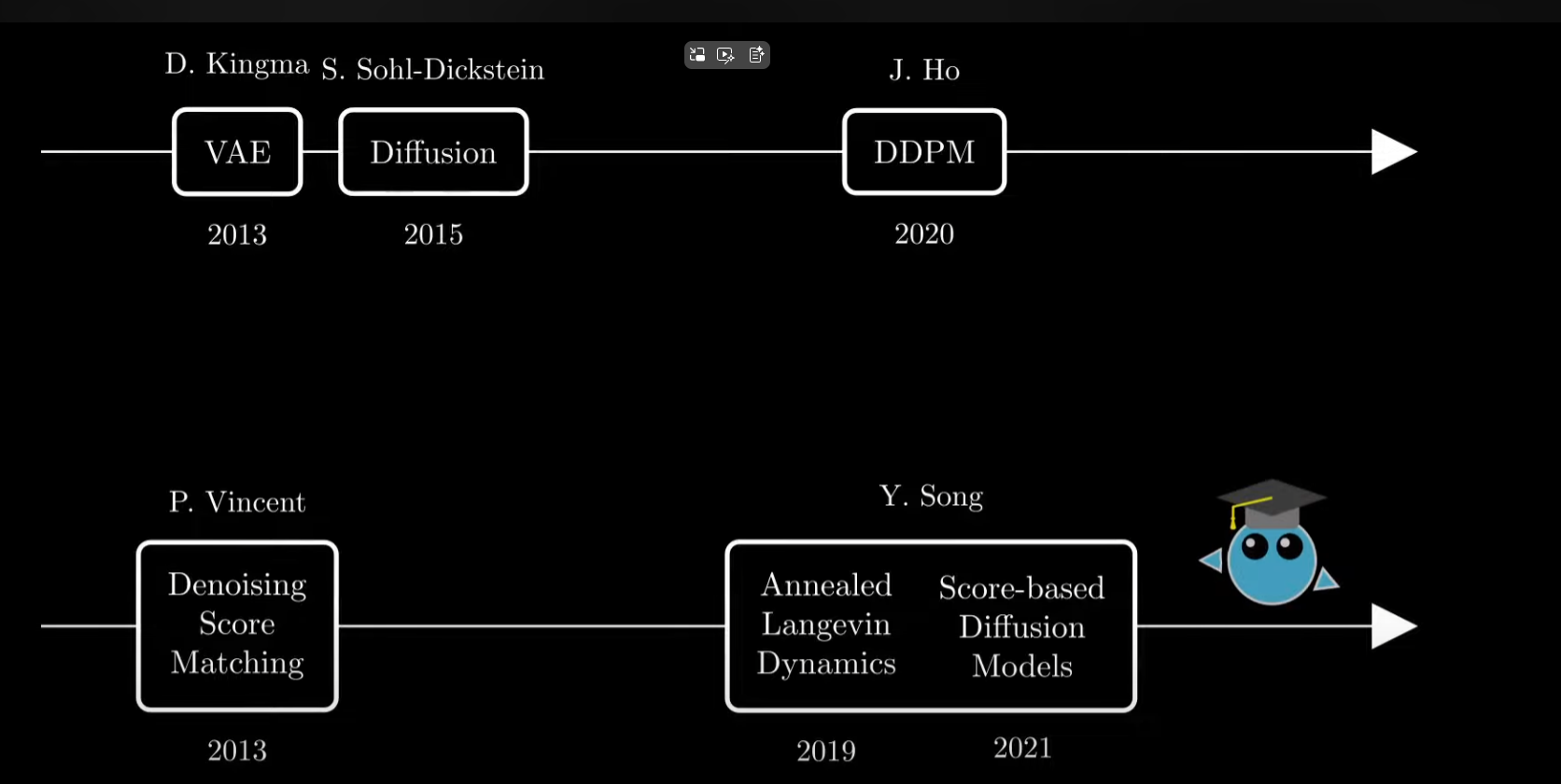
概论
Tweedie’s Formula(特维迪公式) 是这些Denoising Autoencoder、Score-based 模型 或 Diffusion Model 的理论基础背后“从噪声中恢复信号”的数学核心。
0. 场景与记号(全部变量的意义)
- (x∈Rd)(x\in\mathbb{R}^d)(x∈Rd):真实的干净信号(先验 p(x)p(x)p(x) 未知但假设良好)。
- (y∈Rd)(y\in\mathbb{R}^d)(y∈Rd):观测(被噪声污染后的样本)。
- ε∈Rd\varepsilon\in\mathbb{R}^dε∈Rd:高斯噪声,(ε∼N(0,Σ))(\varepsilon\sim\mathcal{N}(0,\Sigma))(ε∼N(0,Σ))。
- Σ∈Rd×d\Sigma\in\mathbb{R}^{d\times d}Σ∈Rd×d:噪声协方差,对称正定。各向同性时 Σ=σ2I\Sigma=\sigma^2 IΣ=σ2I。
- p(x)p(x)p(x):先验密度;(p(y∣x)(p(y\mid x)(p(y∣x):似然(由噪声模型);p(y)p(y)p(y):边际密度;p(x∣y)p(x\mid y)p(x∣y):后验密度。
- ∇y\nabla_y∇y:对向量 (y) 的梯度算子(见 §1 解释)。
- 目标是平方误差意义下的最优去噪:x^(y):=E[x∣y]\hat x(y):=\mathbb{E}[x\mid y]x^(y):=E[x∣y]。
噪声模型:y=x+ε,ε∼N(0,Σ)⇒p(y∣x)=N(y;x,Σ)y=x+\varepsilon,\ \varepsilon\sim\mathcal{N}(0,\Sigma)\Rightarrow p(y\mid x)=\mathcal{N}(y;x,\Sigma)y=x+ε, ε∼N(0,Σ)⇒p(y∣x)=N(y;x,Σ)
1. 概念解释
1.1. ∇y\nabla_y∇y 向量梯度算子 是什么?
对标量函数 (f:Rd→R)(f:\mathbb{R}^d\to\mathbb{R})(f:Rd→R),
∇yf(y)=[∂f∂y1(y)⋮∂f∂yd(y)]∈Rd.\nabla_y f(y) =\begin{bmatrix} \frac{\partial f}{\partial y_1}(y)\\\vdots\\\frac{\partial f}{\partial y_d}(y) \end{bmatrix}\in\mathbb{R}^d. ∇yf(y)=∂y1∂f(y)⋮∂yd∂f(y)∈Rd.
它是所有一阶偏导的“向量打包”。几何意义:在点 yyy,∇yf(y)\nabla_y f(y)∇yf(y) 指向 fff 增长最快的方向,模长给出最大增长率。
在 Tweedie 里我们会用到 s(y):=∇ylogp(y)s(y):=\nabla_y\log p(y)s(y):=∇ylogp(y)(score 函数)。
1.2. Σ\SigmaΣ 协方差矩阵(Covariance Matrix)是什么
推荐好文:https://zhuanlan.zhihu.com/p/37609917
设有d组随机向量xk=[x1x2⋮xd]kk=1,2,...,d\mathbf x_k = \begin{bmatrix} x_1\\ x_2\\ \vdots \\ x_d\\ \end{bmatrix}_k\qquad k=1,2,...,dxk=x1x2⋮xdkk=1,2,...,d
期望为对每个维度的数据求平均。
μ=E[x]=[E[x1]E[x2]⋮E[xd]],E[xi]=1d∑k=1dxk(i)\mu = \mathbb{E}[\mathbf{x}] = \begin{bmatrix} \mathbb{E}[x_1]\\ \mathbb{E}[x_2]\\ \vdots\\ \mathbb{E}[x_d] \end{bmatrix},\qquad \mathbb{E}[x_i] = \frac{1}{d}\sum_{k=1}^d \mathbf x_{{k}_{(i)}}μ=E[x]=E[x1]E[x2]⋮E[xd],E[xi]=d1k=1∑dxk(i)
Σ 是在所有样本中,不同维度之间的方差和相关性结构,协方差为
Σ=E[(x−μ)(x−μ)T]=E[[x1−μ1x2−μ2⋮xd−μd][x1−μ1,x2−μ2,…,xd−μd]]⇒Σ=[E[(x1−μ1)2]E[(x1−μ1)(x2−μ2)]...E[(x2−μ2)(x1−μ1)]E[(x2−μ2)2]...⋮⋮⋱]其中:E[(x1−μ1)2]=1d∑k=1d(xk(i)−μi)2\Sigma=\mathbb E[(\mathbf x - \mu)(\mathbf x - \mu)^T]=\mathbb E \left[ \begin{bmatrix} x_1-\mu_1\\ x_2-\mu_2\\ \vdots\\ x_d-\mu_d\\ \end{bmatrix} \begin{bmatrix} x_1-\mu_1, x_2-\mu_2, \dots, x_d-\mu_d \end{bmatrix} \right]\\ \\\quad \\\quad \Rightarrow \Sigma= \begin{bmatrix} \mathbb E[(x_1-\mu_1)^2] &\mathbb E[(x1−μ1)(x2−μ2)] & ... \\ \mathbb E[(x2−μ2)(x1−μ1)] & \mathbb E[(x_2-\mu_2)^2] & ...\\ \vdots & \vdots & \ddots \end{bmatrix}\\ \\\quad \\\quad 其中:\mathbb E[(x_1-\mu_1)^2] = \frac{1}{d}\sum_{k=1}^d (\mathbf x_{{k}_{(i)}}- \mu_i)^2Σ=E[(x−μ)(x−μ)T]=Ex1−μ1x2−μ2⋮xd−μd[x1−μ1,x2−μ2,…,xd−μd]⇒Σ=E[(x1−μ1)2]E[(x2−μ2)(x1−μ1)]⋮E[(x1−μ1)(x2−μ2)]E[(x2−μ2)2]⋮......⋱其中:E[(x1−μ1)2]=d1k=1∑d(xk(i)−μi)2
- μ(mu) 是每个维度上的平均值;
- Σ(Sigma) 描述的是整个样本(或总体)中,各个维度之间的方差与相关性结构。
2. 关键步骤:把梯度搬进积分号
我们先写出边际密度
p(y)=∫Rdp(y∣x)p(x)dx.(2.1)p(y)=\int_{\mathbb{R}^d} p(y\mid x)p(x)dx. \tag{2.1} p(y)=∫Rdp(y∣x)p(x)dx.(2.1)
想要 ∇yp(y)\nabla_y p(y)∇yp(y),最直接是逐分量地对 yiy_iyi 求偏导:
∂∂yip(y)=∂∂yi∫p(y∣x)p(x)dx.\frac{\partial}{\partial y_i}p(y) =\frac{\partial}{\partial y_i}\int p(y\mid x)p(x)dx. ∂yi∂p(y)=∂yi∂∫p(y∣x)p(x)dx.
结论(Leibniz 规则 / 主导收敛)
在常见的正则条件下(见下),可以交换“对 yiy_iyi 的偏导”和“对 xxx 的积分”:
∂∂yip(y)=∫∂∂yip(y∣x)p(x)dx.(2.2)\frac{\partial}{\partial y_i}p(y) =\int \frac{\partial}{\partial y_i}p(y\mid x)p(x)dx. \tag{2.2} ∂yi∂p(y)=∫∂yi∂p(y∣x)p(x)dx.(2.2)
把各分量重新打包回梯度向量,就得到
∇yp(y)=∫∇yp(y∣x)p(x)dx.(2.3)\nabla_y p(y)=\int \nabla_y p(y\mid x)p(x)dx. \tag{2.3} ∇yp(y)=∫∇yp(y∣x)p(x)dx.(2.3)
什么时候合法?(足够条件)
对每个分量 iii:
- p(y∣x)p(y\mid x)p(y∣x) 关于 yiy_iyi 处处可导;
- 存在某个与 yyy 无关、可积的支配函数 gi(x)g_i(x)gi(x),使得
∣∂p(y∣x)/∂yi∣⋅p(x)≤gi(x)|\partial p(y\mid x)/\partial y_i|\cdot p(x) \le g_i(x)∣∂p(y∣x)/∂yi∣⋅p(x)≤gi(x) 对所有 yyy 成立;
则由主导收敛定理或Leibniz 积分求导法则,(2.2) 成立。
(高斯密度关于 (y) 光滑且衰减良好,通常满足这些条件。)
直观解释(非形式):
因为 𝑝(𝑦∣𝑥) 对 𝑦 是一个平滑的钟形曲线,而且 𝑝(𝑥) 是固定的权重,所以当我们稍微改变 𝑦时,整个积分的变化等价于“每个 𝑥 对 𝑝(𝑦∣𝑥)”变化的加总”。
3. 先求 ∇yp(y)\nabla_y p(y)∇yp(y) 的表达式
由 (2.3):
∇yp(y)=∫∇yp(y∣x)p(x)dx.(3.1)\nabla_y p(y)=\int \nabla_y p(y\mid x)p(x)dx. \tag{3.1} ∇yp(y)=∫∇yp(y∣x)p(x)dx.(3.1)
再用“对数的梯度乘密度”技巧:
∇yp(y∣x)=p(y∣x)∇ylogp(y∣x).(3.2)\nabla_y p(y\mid x) = p(y\mid x)\nabla_y \log p(y\mid x). \tag{3.2} ∇yp(y∣x)=p(y∣x)∇ylogp(y∣x).(3.2)
首先我们知道
f(y)=elogf(y)f(y) = e^{\log f(y)}f(y)=elogf(y)
运用链式法则
∇f(y)=∇elogf(y)=elogf(y)∇logf(y)=f(y)∇logf(y)\nabla f(y) = \nabla e^{\log f(y)} = e^{\log f(y)} \nabla \log f(y) = f(y) \nabla \log f(y) ∇f(y)=∇elogf(y)=elogf(y)∇logf(y)=f(y)∇logf(y)
直观理解:密度的相对变化率 = 对数密度的梯度。
- dpdy\frac{dp}{dy}dydp:告诉你p(y)绝对值变化多块
- dlogpdy\frac{d\log p}{dy}dydlogp:相对增长率,告诉你“p(y)在y方向上相对自己变化的速度”
代回 (3.1):
∇yp(y)=∫p(y∣x)∇ylogp(y∣x)p(x)dx.(3.3)\nabla_y p(y) = \int p(y\mid x)\nabla_y \log p(y\mid x)p(x)dx. \tag{3.3} ∇yp(y)=∫p(y∣x)∇ylogp(y∣x)p(x)dx.(3.3)
两边同时除以 p(y)p(y)p(y)(假设 p(y)>0p(y)>0p(y)>0)得到 score:
∇ylogp(y)=1p(y)∫p(y∣x)∇ylogp(y∣x)p(x)dx.(3.4)\nabla_y \log p(y) = \frac{1}{p(y)}\int p(y\mid x)\nabla_y \log p(y\mid x)p(x)dx. \tag{3.4} ∇ylogp(y)=p(y)1∫p(y∣x)∇ylogp(y∣x)p(x)dx.(3.4)
4. 计算高斯似然的梯度 ∇ylogp(y∣x)\nabla_y\log p(y\mid x)∇ylogp(y∣x)
一维高斯函数
f(x)=12πσexp(−(x−μ)22σ2)f(x) = \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(x - \mu)^2}{2\sigma^2}\right)f(x)=2πσ1exp(−2σ2(x−μ)2)
当为标准正态分布时,函数为
f(x)=12πexp(−12x2)f(x) = \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{1}{2}x^2\right)f(x)=2π1exp(−21x2)
标准高维高斯分布函数,z=(z1,...,zd)Tz=(z_1,...,z_d)^Tz=(z1,...,zd)T
f(z)=1(2π)d/2exp(−12∑i=1dzi2)f(z) = \frac{1}{(2\pi)^{d/2}}\exp(-\frac{1}{2}\sum_{i=1}^dz_i^2)f(z)=(2π)d/21exp(−21i=1∑dzi2)
通过将标准高斯分布进行线性变换和平移 x=μ+Lz⇒z=L−1(x−μ)\mathbf x=\mu+Lz\Rightarrow z = L^{-1}(\mathbf x-\mu)x=μ+Lz⇒z=L−1(x−μ)。
将z=L−1(x−μ)z = L^{-1}(\mathbf x-\mu)z=L−1(x−μ)带入标准高斯分布函数得到如下,其中Σ=LLT\Sigma=LL^TΣ=LLT
p(x∣μ,Σ)=1(2π)d/2∣Σ∣1/2exp(−12(x−μ)⊤Σ−1(x−μ))p(\mathbf{x}|\mu,\Sigma) = \frac{1}{(2\pi)^{d/2} |\mathbf{\Sigma}|^{1/2}} \exp\left( -\frac{1}{2} (\mathbf{x} - \mathbf{\mu})^\top \mathbf{\Sigma}^{-1} (\mathbf{x} - \mathbf{\mu}) \right)p(x∣μ,Σ)=(2π)d/2∣Σ∣1/21exp(−21(x−μ)⊤Σ−1(x−μ))
Σ\SigmaΣ 将一个高维球经过旋转和缩放变成了一个高维椭球分布,μ\muμ将其进行平移
高斯似然:yyy 已知,求 N(x,Σ)\mathcal{N}({x}, {\Sigma})N(x,Σ)
p(y∣x)=1(2π)d/2∣Σ∣1/2exp(−12(y−x)⊤Σ−1(y−x)).p(y\mid x )=\frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}} \exp\Big(-\tfrac{1}{2}(y-x)^\top \Sigma^{-1}(y-x)\Big). p(y∣x)=(2π)d/2∣Σ∣1/21exp(−21(y−x)⊤Σ−1(y−x)).
取对数:
logp(y∣x)=const−12(y−x)⊤Σ−1(y−x).\log p(y\mid x)=\text{const}-\tfrac{1}{2}(y-x)^\top \Sigma^{-1}(y-x). logp(y∣x)=const−21(y−x)⊤Σ−1(y−x).
对 yyy 求梯度(用二次型求导公式):
∇ylogp(y∣x)=−Σ−1(y−x).(4.1)\nabla_y \log p(y\mid x) = -\Sigma^{-1}(y-x). \tag{4.1} ∇ylogp(y∣x)=−Σ−1(y−x).(4.1)
把 (4.1) 代入 (3.4):
∇ylogp(y)=1p(y)∫p(y∣x)[−Σ−1(y−x)]p(x)dx=−Σ−11p(y)∫(y−x)p(y∣x)p(x)dx.(4.2)\nabla_y \log p(y) = \frac{1}{p(y)}\int p(y\mid x)\big[-\Sigma^{-1}(y-x)\big]p(x)dx \\= -\Sigma^{-1}\frac{1}{p(y)}\int (y-x)p(y\mid x)p(x)dx.\tag{4.2} ∇ylogp(y)=p(y)1∫p(y∣x)[−Σ−1(y−x)]p(x)dx=−Σ−1p(y)1∫(y−x)p(y∣x)p(x)dx.(4.2)
5. 用后验 p(x∣y)p(x\mid y)p(x∣y) 化简
Bayes 定义:p(x∣y)=p(y∣x)p(x)p(y)p(x\mid y)=\dfrac{p(y\mid x)p(x)}{p(y)}p(x∣y)=p(y)p(y∣x)p(x)。
把它带入 (4.2):
∇ylogp(y)=−Σ−1∫(y−x)p(x∣y),dx.(5.1)\nabla_y \log p(y) = -\Sigma^{-1}\int (y-x)p(x\mid y),dx. \tag{5.1} ∇ylogp(y)=−Σ−1∫(y−x)p(x∣y),dx.(5.1)
把 (y) 拆出去(它不依赖 (x)):
∫(y−x)p(x∣y)dx=y∫p(x∣y)dx−∫xp(x∣y)dx=y−E[x∣y].(5.2)\int (y-x)p(x\mid y)dx\\ = y\int p(x\mid y)dx-\int xp(x\mid y)dx\\ = y-\mathbb{E}[x\mid y]. \tag{5.2} ∫(y−x)p(x∣y)dx=y∫p(x∣y)dx−∫xp(x∣y)dx=y−E[x∣y].(5.2)
p(x∣y)p(x|y)p(x∣y):在观察到 𝑦 后,𝑥 的概率权重
∫p(x∣y)dx=1\int p(x|y)dx=1∫p(x∣y)dx=1
- 在给定 𝑦 的条件下,所有可能的 𝑥 的概率总和为 1
∫xp(x∣y)dx=E[x∣y]\int xp(x|y)dx = \mathbb E[x|y]∫xp(x∣y)dx=E[x∣y]:加权平均后最可能的 x→x \rightarrowx→ 即 E[x∣y]\mathbb E[x|y]E[x∣y]
代回 (5.1):
∇ylogp(y)=−Σ−1(y−E[x∣y]).(5.3)\nabla_y \log p(y) = -\Sigma^{-1}\big(y-\mathbb{E}[x\mid y]\big). \tag{5.3} ∇ylogp(y)=−Σ−1(y−E[x∣y]).(5.3)
逐分量(索引)写法,便于核对
记 [⋅]∗i[\cdot]*i[⋅]∗i 表示向量的第 iii 个分量,Σ−1=[Σ−1]∗ij\Sigma^{-1}=[\Sigma^{-1}]*{ij}Σ−1=[Σ−1]∗ij。
由 (5.3):
∂∂yilogp(y)=−∑j=1d[Σ−1]ij(yj−E[xj∣y]).\frac{\partial}{\partial y_i}\log p(y) = -\sum_{j=1}^d [\Sigma^{-1}]_{ij}\big(y_j-\mathbb{E}[x_j\mid y]\big). ∂yi∂logp(y)=−j=1∑d[Σ−1]ij(yj−E[xj∣y]).
6. 得到 Tweedie 公式(一般协方差)
把 (5.3) 左右同乘 Σ\SigmaΣ 并移项:
E[x∣y]=y+Σ∇ylogp(y).(6.1)\boxed{\ \mathbb{E}[x\mid y] = y + \Sigma\nabla_y \log p(y)\ }. \tag{6.1} E[x∣y]=y+Σ∇ylogp(y) .(6.1)
形状检查(避免符号错误):
- ∇ylogp(y)∈Rd\nabla_y \log p(y)\in\mathbb{R}^d∇ylogp(y)∈Rd;
- Σ∈Rd×d\Sigma\in\mathbb{R}^{d\times d}Σ∈Rd×d;
- Σ∇ylogp(y)∈Rd\Sigma\nabla_y \log p(y)\in\mathbb{R}^dΣ∇ylogp(y)∈Rd,与 yyy 同维。
7. 各向同性特例(最常见)
若 Σ=σ2I\Sigma=\sigma^2 IΣ=σ2I:
E[x∣y]=y+σ2∇ylogp(y).(7.1)\boxed{\ \mathbb{E}[x\mid y] = y + \sigma^2\nabla_y \log p(y)\ }. \tag{7.1} E[x∣y]=y+σ2∇ylogp(y) .(7.1)
8. 小结(每一步做了什么 & 为什么合法)
-
写边际:p(y)=∫p(y∣x)p(x)dxp(y)=\int p(y\mid x)p(x)dxp(y)=∫p(y∣x)p(x)dx(定义)。
-
把梯度搬进积分号:∇yp(y)=∫∇yp(y∣x)p(x)dx\nabla_y p(y)=\int \nabla_y p(y\mid x)p(x)dx∇yp(y)=∫∇yp(y∣x)p(x)dx。
- 依据:Leibniz 规则 / 主导收敛(高斯情形满足光滑与支配条件)。
-
换成“对数梯度 × 密度”:∇yp(y∣x)=p(y∣x)∇ylogp(y∣x)\nabla_y p(y\mid x)=p(y\mid x)\nabla_y\log p(y\mid x)∇yp(y∣x)=p(y∣x)∇ylogp(y∣x)(链式法则)。
-
高斯对数梯度:∇ylogp(y∣x)=−Σ−1(y−x)\nabla_y\log p(y\mid x)=-\Sigma^{-1}(y-x)∇ylogp(y∣x)=−Σ−1(y−x)(二次型求导)。
-
Bayes 化简:把 p(y∣x)p(x)p(y)\frac{p(y\mid x)p(x)}{p(y)}p(y)p(y∣x)p(x) 认作 p(x∣y)p(x\mid y)p(x∣y),并用 ∫p(x∣y)dx=1\int p(x\mid y)dx=1∫p(x∣y)dx=1。
-
移项得结论:E[x∣y]=y+Σ∇ylogp(y)\mathbb{E}[x\mid y]=y+\Sigma\nabla_y\log p(y)E[x∣y]=y+Σ∇ylogp(y)。
9. 直觉回顾(把公式读成一句话)
- s(y):=∇ylogp(y)s(y):=\nabla_y\log p(y)s(y):=∇ylogp(y) 指向密度更高的方向;
- Σs(y)\Sigma s(y)Σs(y) 给出在噪声协方差尺度下的“回拉”位移;
- 把观测 yyy 朝这个方向推回去,就得到最优去噪估计 E[x∣y]\mathbb{E}[x\mid y]E[x∣y]。