LLM 笔记 —— 04 为什么语言模型用文字接龙,图片模型不用像素接龙呢?
01 引子
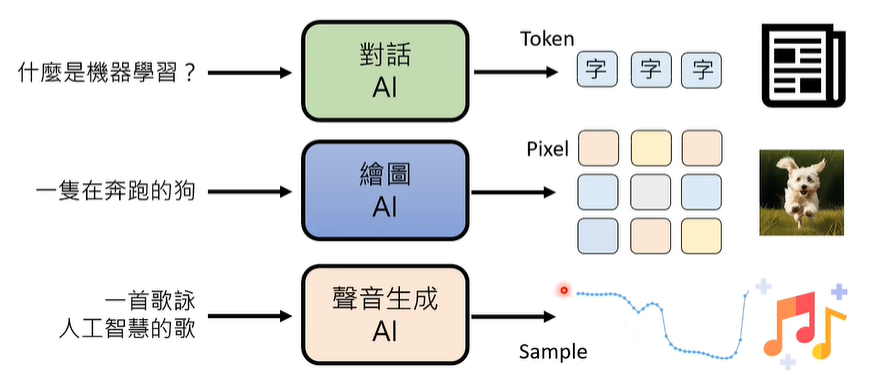
生成式人工智能(Generative AI)包含文字,影像,声音三个方面,其中,文字由 Token 组成、影像由 Pixel(像素)组成,声音由 Sample(取样点)组成。因此,生成式人工智能的核心问题是,如何给一段输出,让其利用基本单位组合成一段输出。
02 Autoregressive Generation (AR)
① 文字接龙
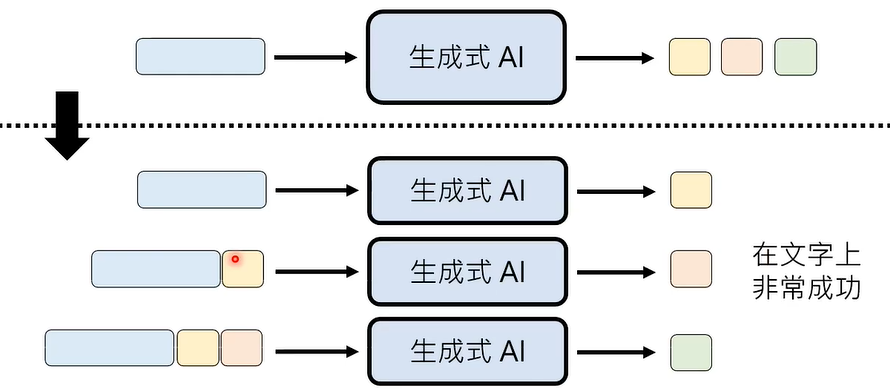
② 图像“接龙”

③ 声音“接龙”
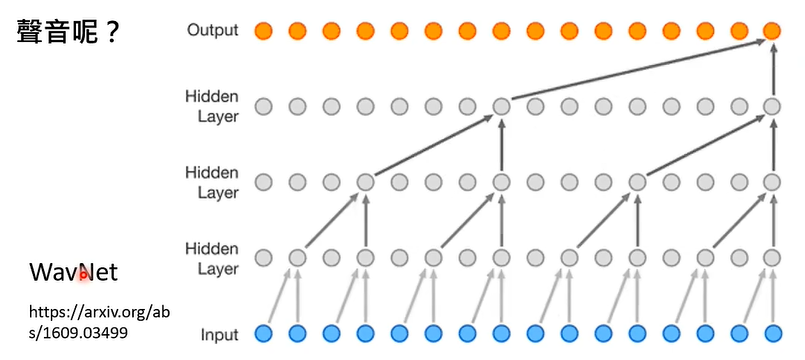
接龙有一个本质的陷阱,即我们需要按部就班的,按照某种特定的顺序,生成越来越长的输出。假设我们要生成一张 1024 * 1024 解析度的图片,需要大约 100 万次接龙!
那么,如何解决这一问题呢,我们可以让模型一次性输出多个位置的答案!
03 Non-autoregressive Generation (NAR)
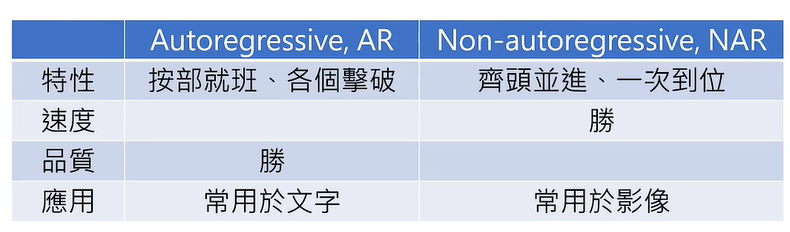
Autoregressive Generation (AR) VS Non-autoregressive Generation (NAR)
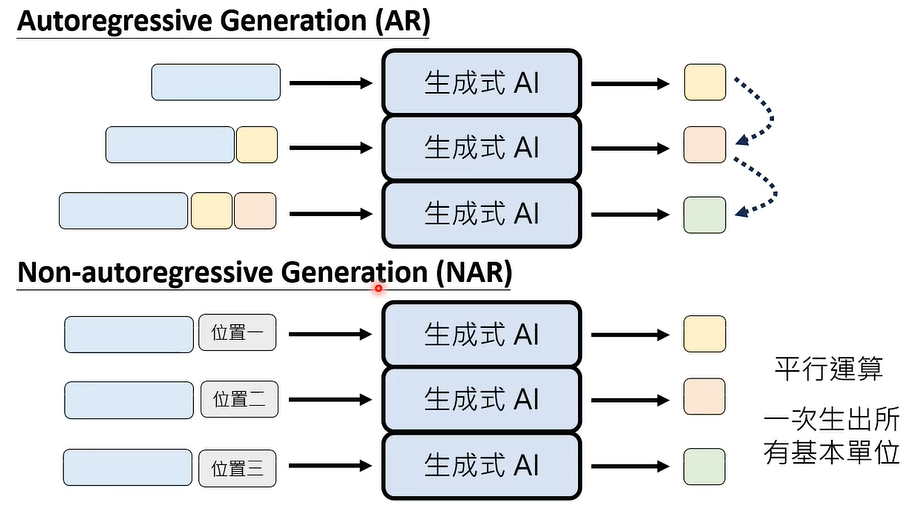
其实,文字也可以用 Non-autoregressive Generation (NAR) 生成。
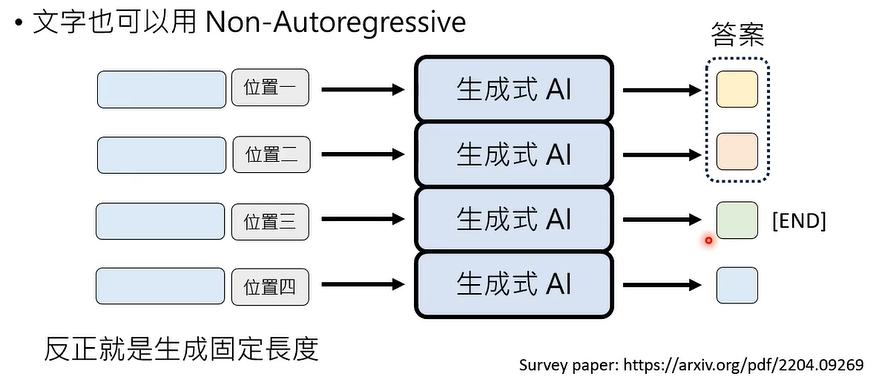
有一个问题是,生成往往需要 AI 字形脑补,给定条件下,仍有很多不同可能的输出,这个问题,被称为 multi-modality problem。
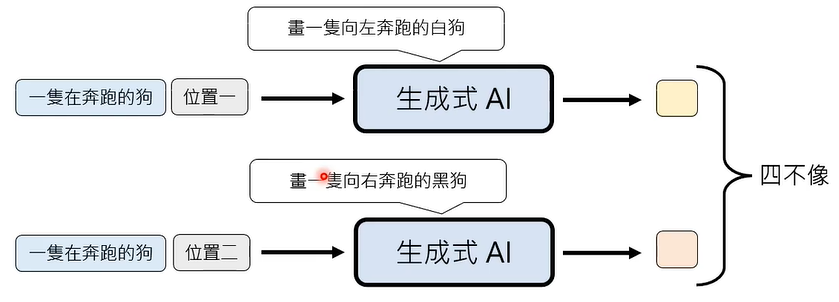
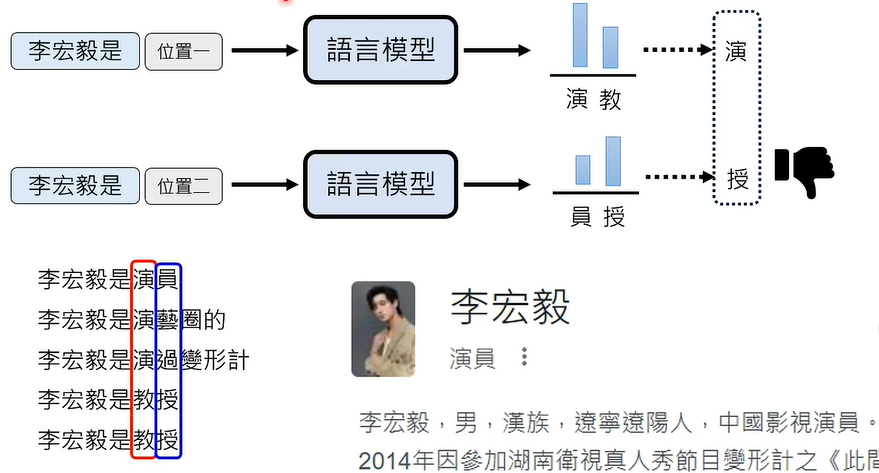
这个问题,在 Autoregressive Generation (AR) 情况下往往不会出现。
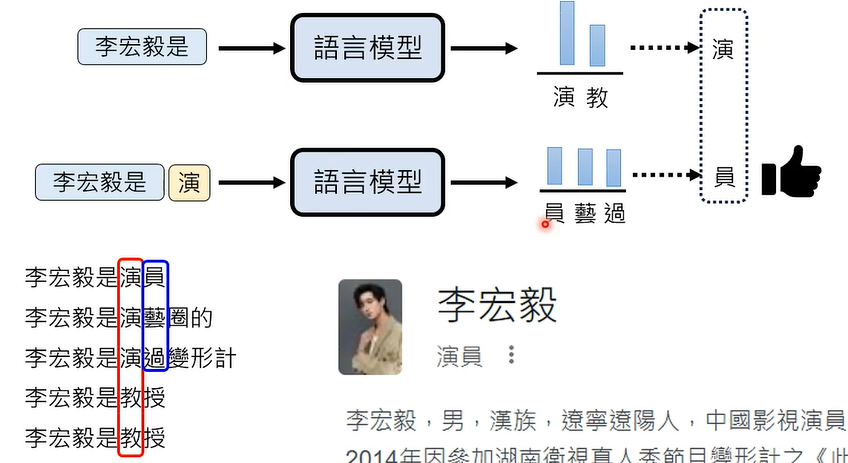
如何解决影像生成领域中的 multi-modality problem 呢?
让所有位置都脑补一样的内容。
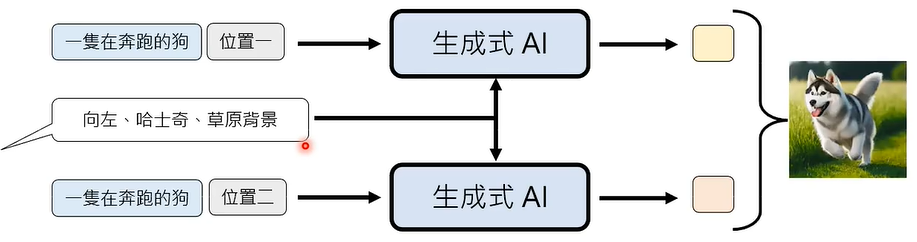
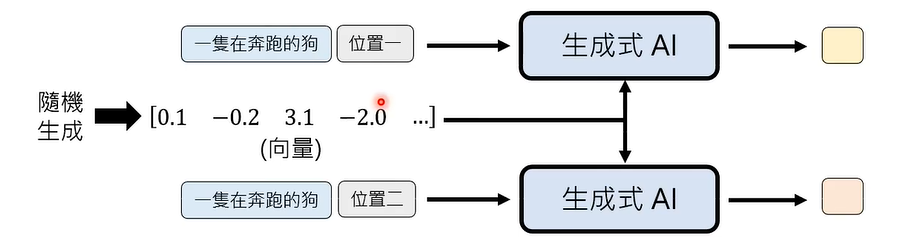
影像常用生成模型 VAE、GAN、FIow-based Model、Diffusion Model都有这样的设计。
Autoregressive Generation (AR) + Non-autoregressive Generation (NAR)
先用 Autoregressive Generation 产生精简版本,让 Non-autoregressive Generation 根据精简版本产生详细版本。
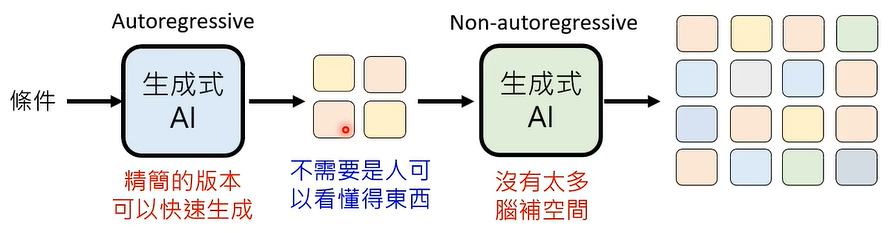
如何产生精简版本呢?
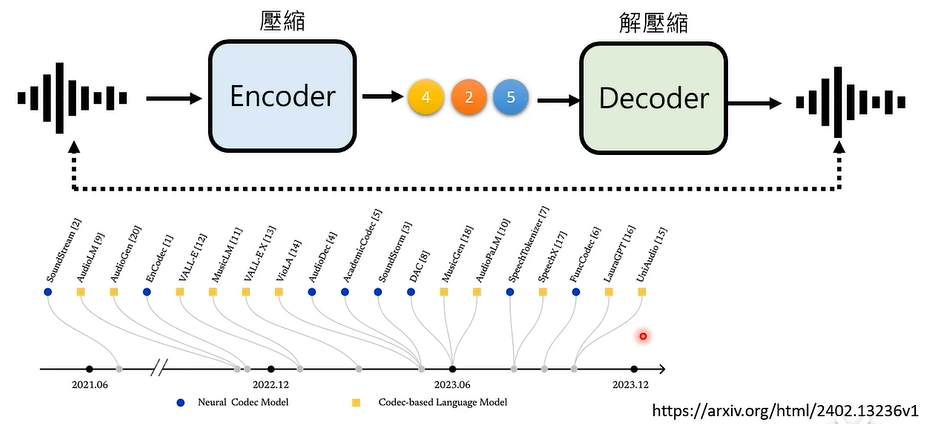
可以将像素矩阵利用 Encoder 压缩成数字矩阵,再利用 Decoder 解压缩还原成图片,Encoder 和 Decoder 都可以是类神经网络通过学习得到,这种方法叫做 Auto-Encoder。
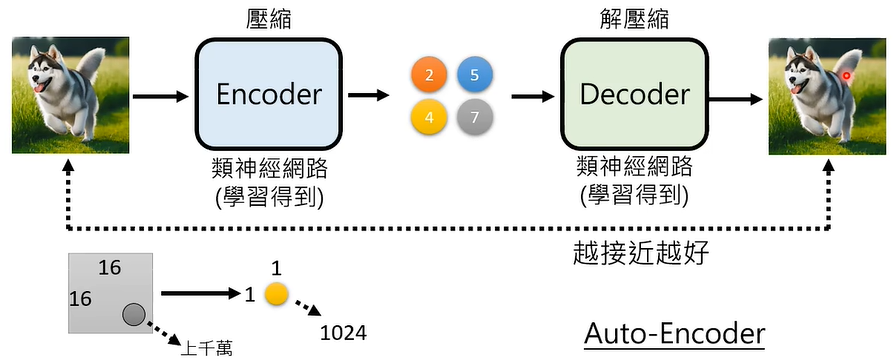
如此,Autoregressive Generation 只需要研究这个被压缩的数字矩阵就可以了,不需要人类能够看得懂。
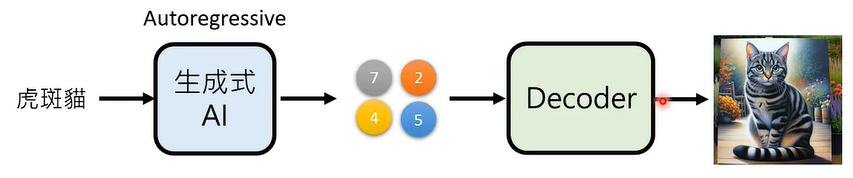
在语音生成上,也可以采用类似的策略。

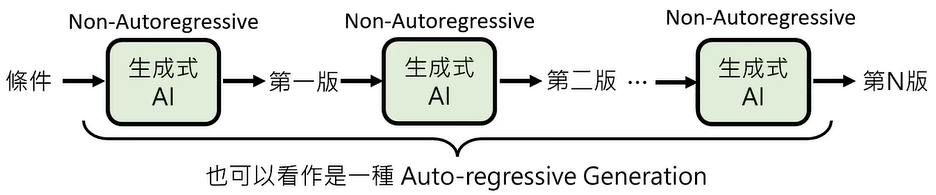
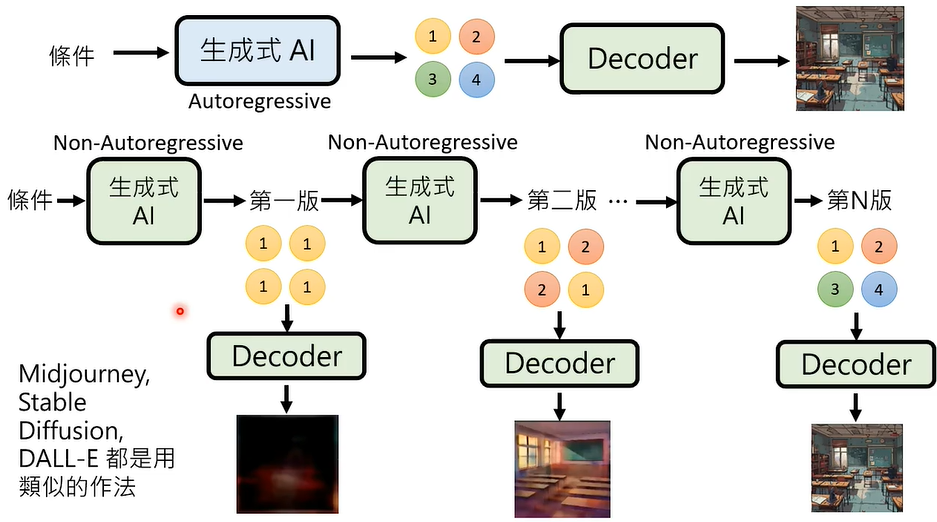
04 多次 Non-autoregressive Generation (NAR)
① 从小图到大图

② 从有杂讯到没有杂讯

③ 每次把不好的地方涂掉

可能的难点是,如何决定什么地方被涂掉,什么地方不被涂掉。
前文提到,我们可以将 Autoregressive Generation (AR) 和 Non-autoregressive Generation (NAR) 结合起来,如果我们仍然觉得第一段采用 Autoregressive 太耗费了呢,我们可以将这一段生成式 AI 替换为 多次 Non-autoregressive Generation (NAR)。
05 觉得现在的语言模型还不够快吗?
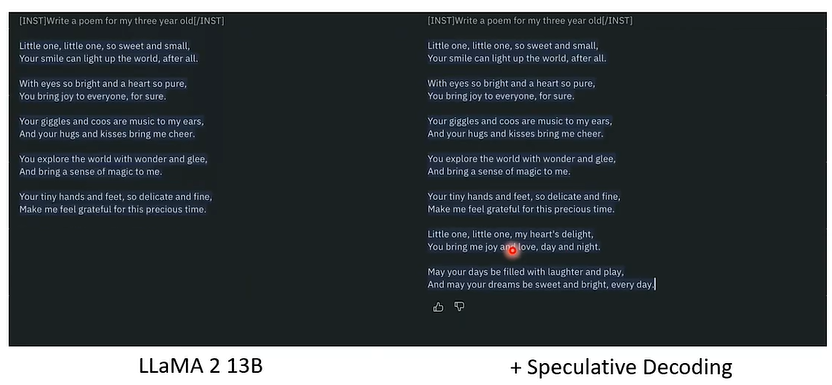
有一个外挂技术,叫做 Speculative Decoding,意思是猜测、投机,也就是说,有一个预言家,预言到语言模型接下来会说什么 Token,如此,生成速度会变为原来的两倍。
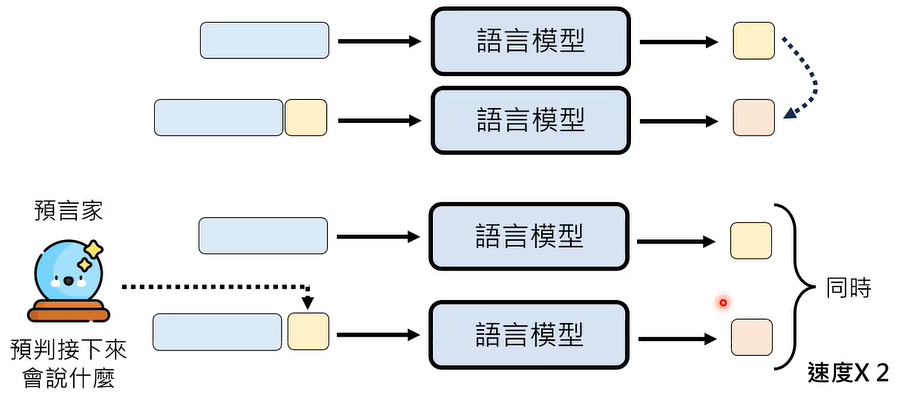
下一步、下下步的 Token 不断地被预测出来,也就说,这三个步骤几乎同时进行,模型生成的速度当然非常迅速了。
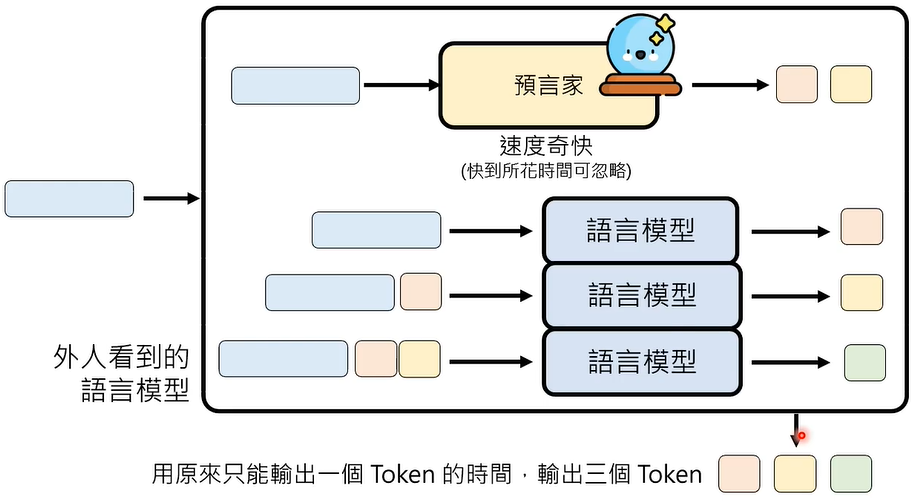
预言家这么厉害吗?
不,预言家不是语言模型,预言家也会犯错。
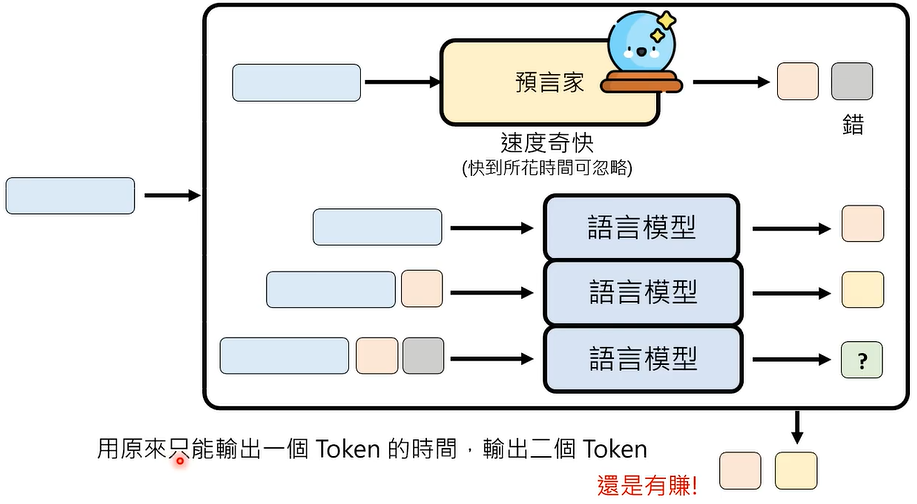
那么,我们怎么知道预言家是正确还是错误的呢,对比预言家输出的 Token 和模型输出的 Token,差异就是,在一个错误的情况下,模型每次输出两个 Token,还是有得赚。就算预言家的预测全是错的,至少模型还是每次能输出一个 Token,包不赔的。
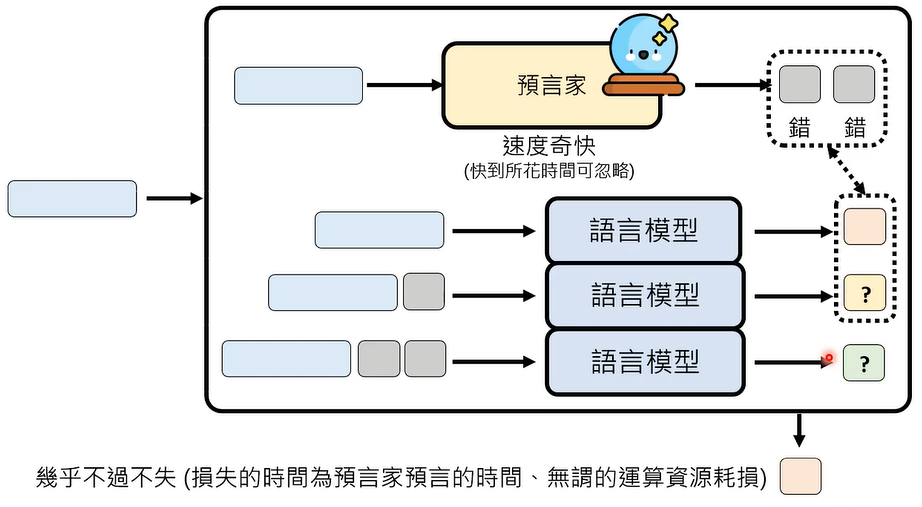
谁可以担任预言家呢?
要求是超快速,犯错也没关系。答案是 Non-autoregressive Model 或者压缩后的 Compressed Model。
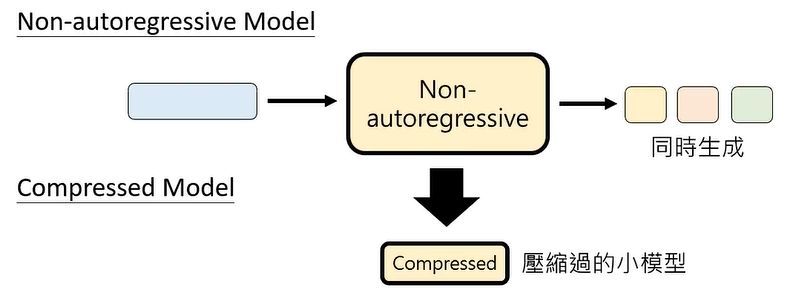
预言家一定要是语言模型吗?
不一定。
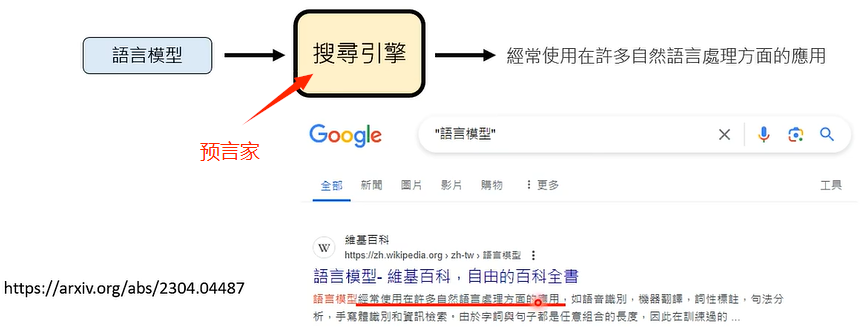
预言家一定要一个吗?
可以有很多个。
![转存中...(img-zo2ey6rc-1760189703041)]](https://i-blog.csdnimg.cn/direct/10f7cd9a945e461bab6b7698aac8b204.png)