第六章 与学习相关的技巧
参数的更新
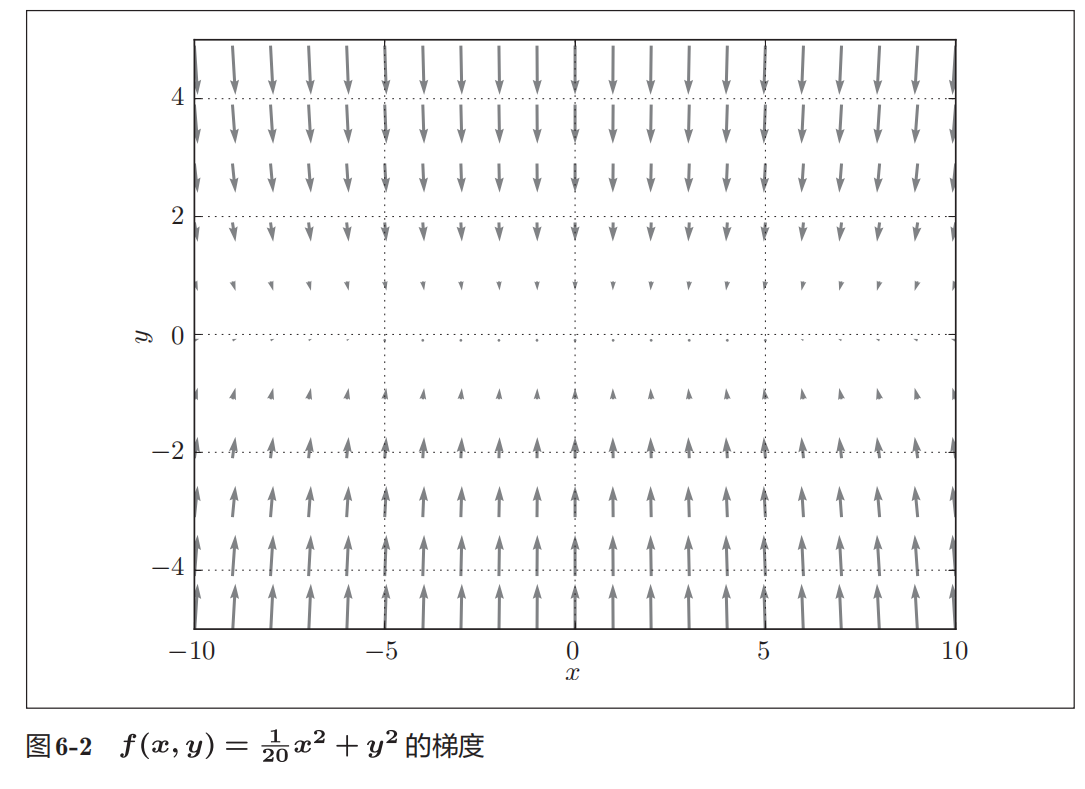
以这个函数的梯度为例
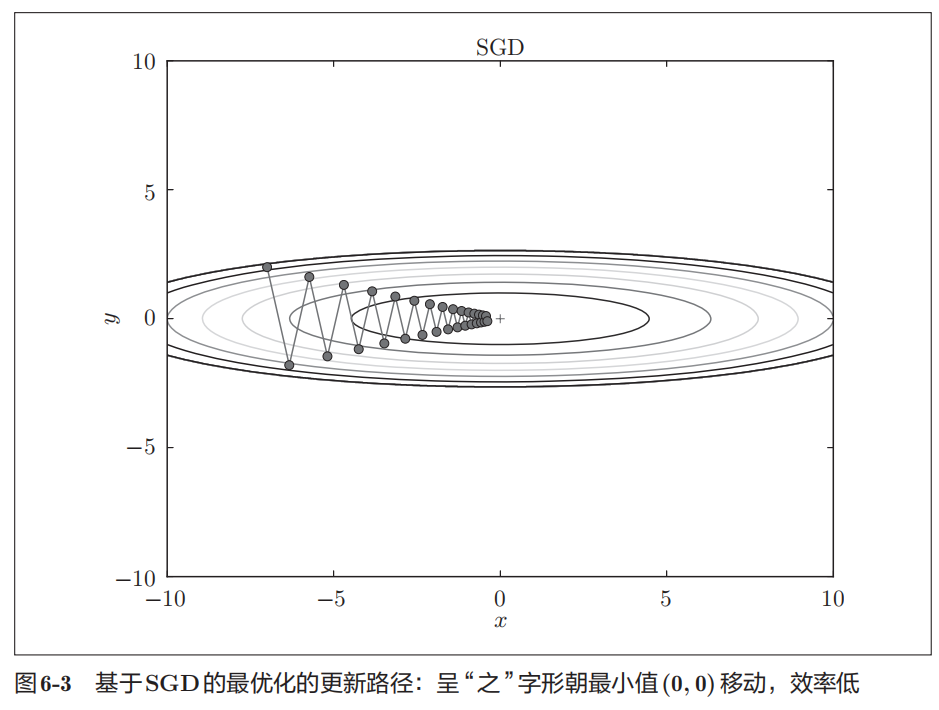
SGD
SGD梯度指示的方向是各点处的函数值减小最多的方向。
SGD低效的根本原因是,梯度的方向并没有指向最小值的方向。
Momentum
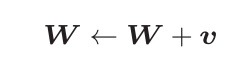
Momentum方法给人的感觉就像是小球在地面上滚动。
有v这一项。在物体不受任何力时,该项承担使物体逐渐减速的任务
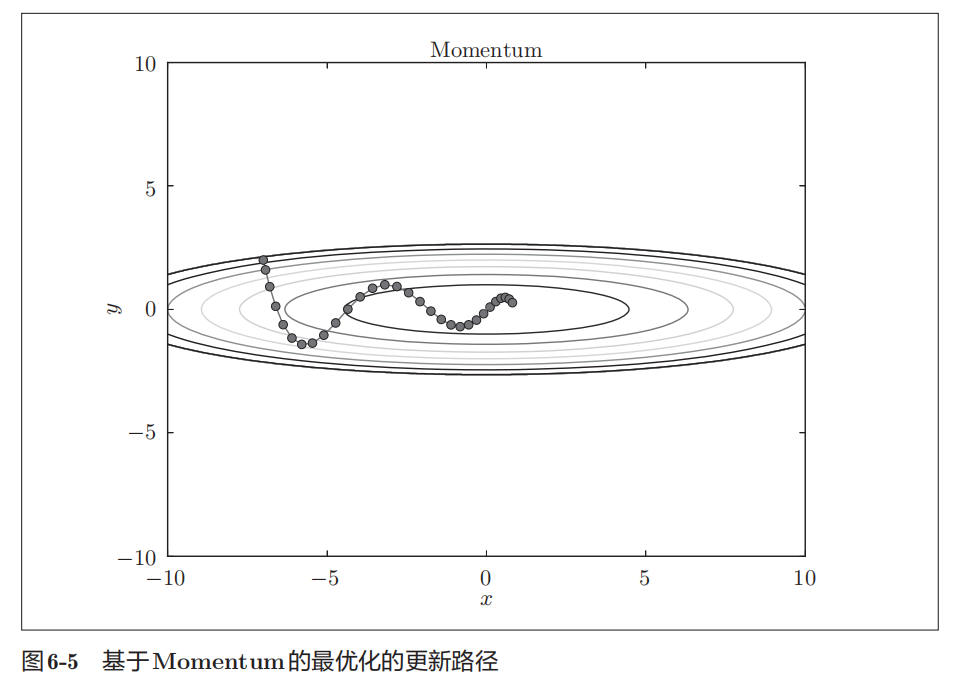
虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速。反过来,虽然y轴方向上受到的力很大,但是因为交互地受到正方向和反方向的力,它们会互相抵消,所以y轴方向上的速度不稳定。
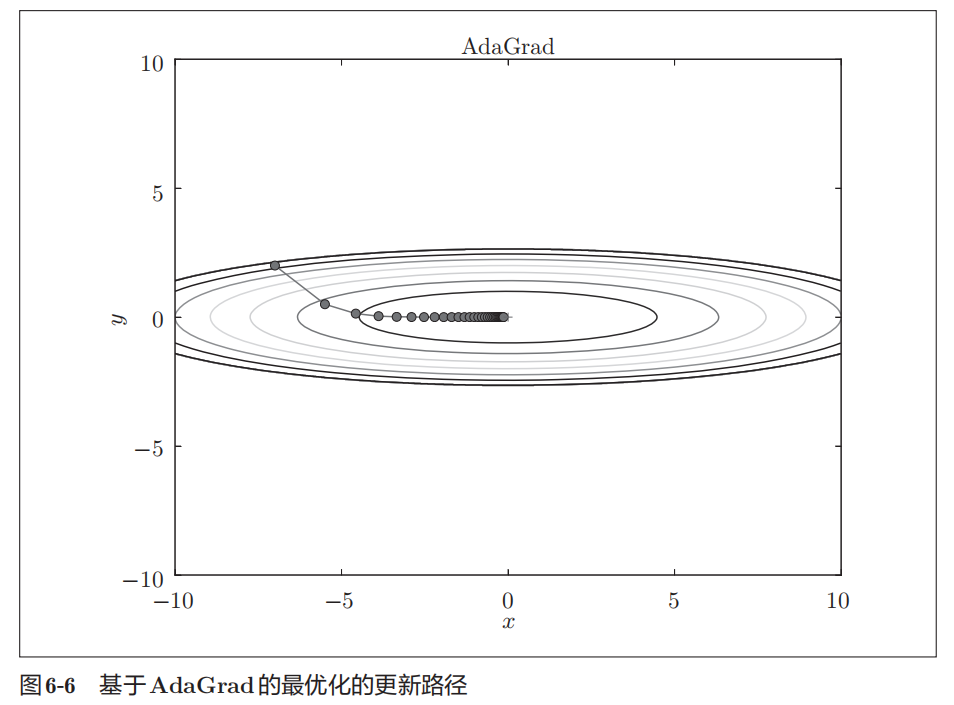
Adagrad
AdaGrad会为参数的每个元素适当地调整学习率,与此同时进行学习。
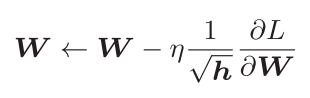 h为所有梯度值的平方和
h为所有梯度值的平方和
AdaGrad会记录过去所有梯度的平方和。因此,学习越深入,更新的幅度就越小。
Adam
融合了Momentum和AdaGrad的方法
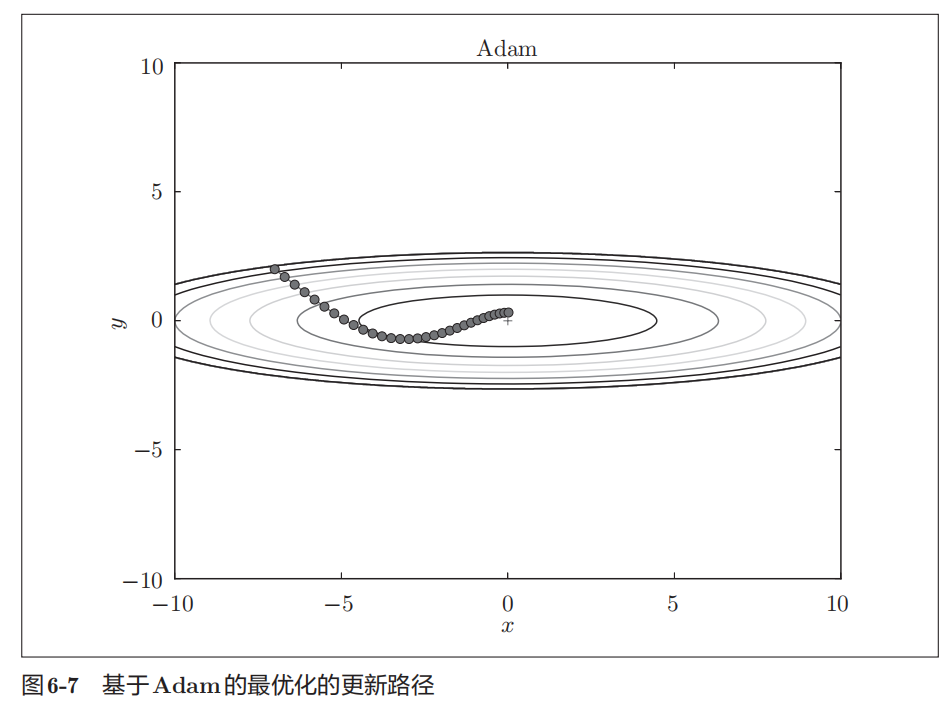
并不存在能在所有问题中都表现良好的方法。这4种方法各有各的特点,都有各自擅长解决的问题和不擅长解决的问题。
权重的初始值
为什么不能把权重初始值设置为0?
如果权重初始值设置为0,在误差反向传播法中,所有的权重值都会进行相同的更新。权重会被更新为相同的值,并拥有了重复的值。这使得神经网络拥有许多不同的权重的意义丧失了。为了防止“权重均一化”,必须随机生成初始值。
sigmoid函数的梯度消失现象
sigmoid函数是S型函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。因此,偏向0和1的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失。随着深度层次增加,梯度消失现象会更加严重。
Xavier初始值
如果前一层的节点数为n,则初始值使用标准差为的分布
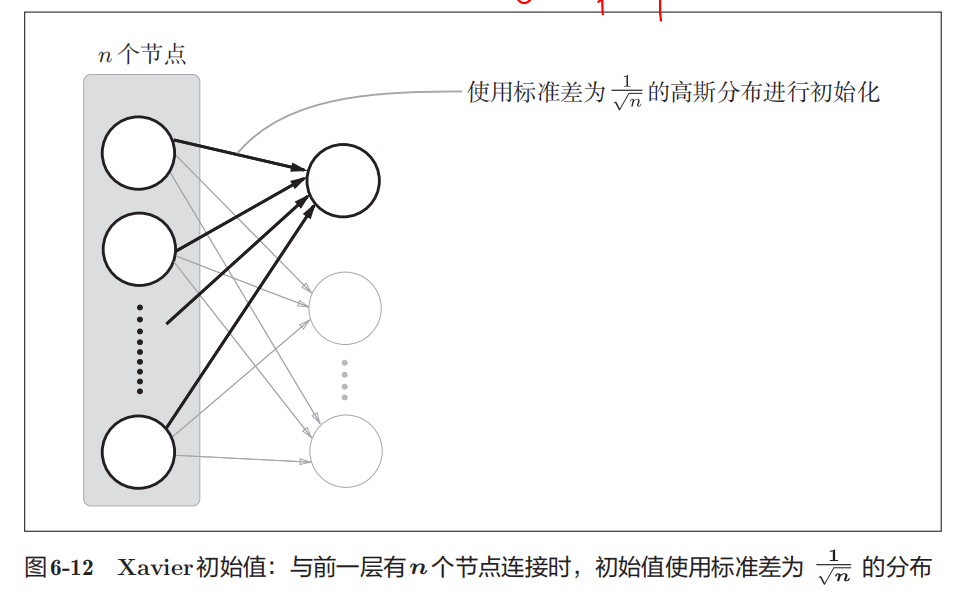
用作激活函数的函数最好具有关于原点对称的性质。
sigmoid函数和tanh函数左右对称,且中央附近可以视作线性函数,所以适合使用Xavier初始值
He初始值
当激活函数使用ReLU时,一般推荐使用ReLU专用的初始值,He初始值
总结一下,当激活函数使用ReLU时,权重初始值使用He初始值,当激活函数为sigmoid或tanh等S型曲线函数时,初始值使用Xavier初始值。
Batch Normalization
思路
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度
实现方法
以进行学习时的mini-batch为单位,按mini-batch进行正规化。具体而言,就是进行使数据分布的均值为0、方差为1的正规化。
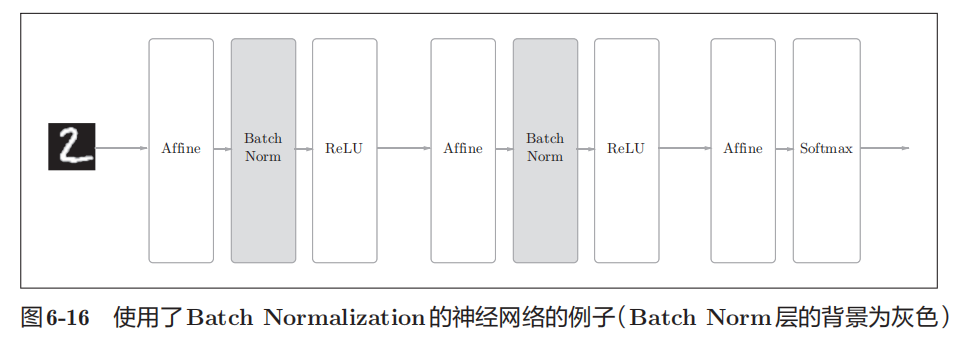
优点
1.增大学习率,使学习快速进行。
2.减小对于权重初始值的依赖
3.抑制过拟合
正则化
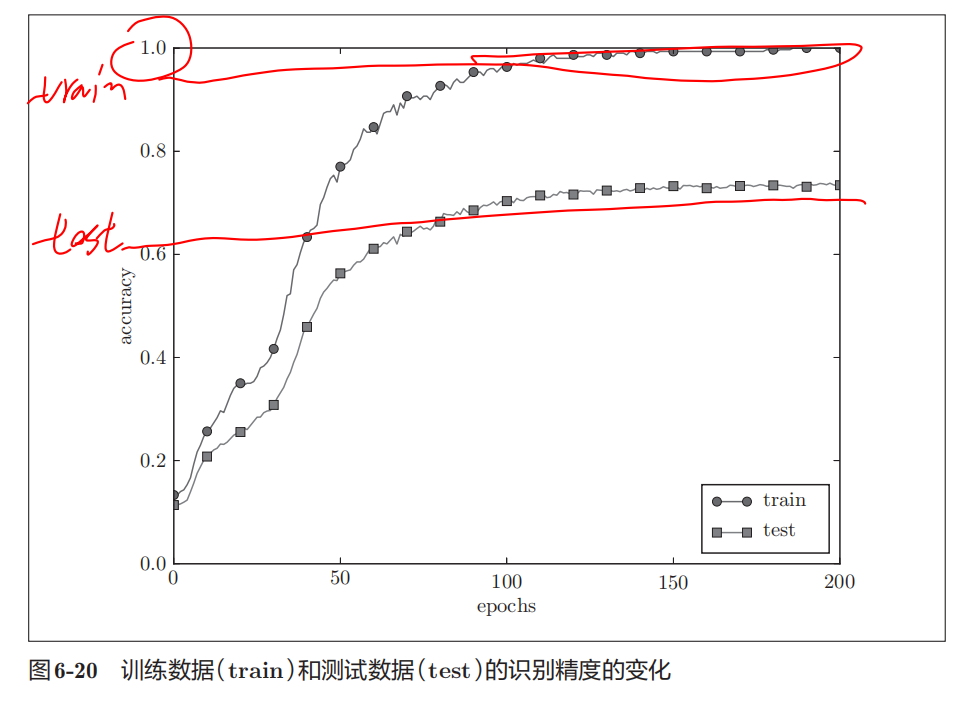
过拟合
过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。
原因
1.模型有大量参数、表现力强
2.训练数据少
例子
正则化方法一:权值衰减
在学习的过程中对大的权重进行惩罚,来抑制过拟合
λ是控制正则化强度的超参数。λ设置得越大,对大的权重施加的惩罚就越重。
正则化方法二:Dropout
Dropout是一种在学习的过程中随机删除神经元的方法。
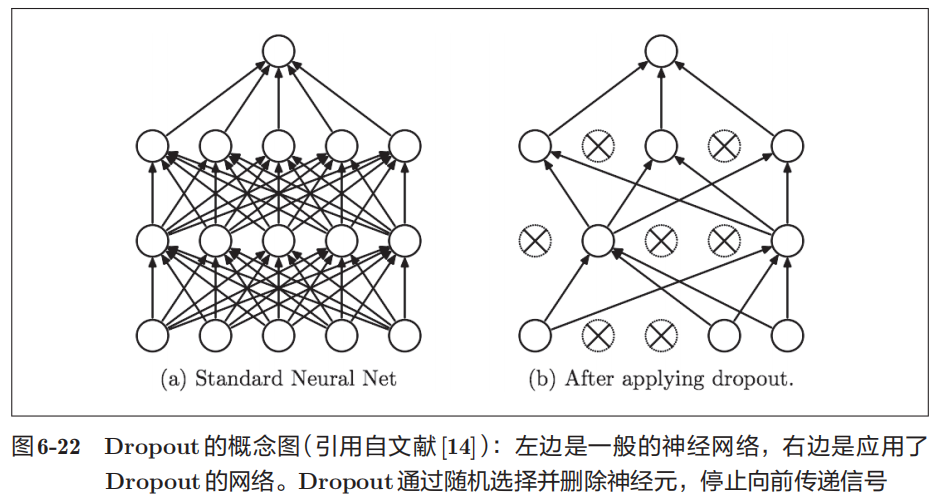
训练时,每传递一次数据,就会随机选择要删除的神经元。然后,测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出,要乘上训练时的删除比例后再输出。
超参数的验证
超参数指神经网络中除权重、偏置以外的其他参数
训练数据用于学习, 测试数据用于评估泛化能力,判断是否发生过拟合
用于调整超参数的数据,一般称为验证数据
超参数的最优化步骤
超参数的选择需要人为的决定
