GRU模型这波牛市应用股价预测
之前学了大部分的基础,学习率,损失函数的。现在开始进入正式的应用探索。
我以前觉得AI用在学语言,画图,生成视频。挺有创意的。现在呢不搞那些了,折腾来去的也没挣钱,趁着牛市就预测股价。还是应用在金融上直接粗暴,搞点钱继续周游世界。
GRU是(Gated Recurrent Unit),它是循环神经网络(RNN)的一种改进形式。目的是解决RNN在长序列中存在梯度消失的问题,同时保持计算效率。
第一步,咱先回顾下RNN是个啥,反正我记性不好。
数学表达:
设:
- 当前输入为x_t
- 上一时刻的隐藏状态为h_t-1
- 当前时刻的隐藏状态为h_t
- 输出为y_t
1、隐藏状态更新:h_t=tanh(Wxh * x_t+Whh * h_t-1 +b_h)
2、输出计算:y_t=Why * h_t+b_y
其中:
- Wxh,Whh,Why是权重矩阵
- b_h,b_y是偏置项
- tanh是激活函数
这里举例下:
假设输入向量x_t是3维度,(价格,成交量,新闻情绪),隐藏状态h_t是128维。
那么Wxh是128*3的矩阵,Whh是128*128的矩阵。h_t是一个128维向量。这里的h是hidden的意思
这个简单的讲,就是一个矩阵乘法,把输入的维度变成另一个维度而已。输出y也是,你想输出几维就几维度。比如想输出2维度,(价格,涨的概率);一维度,就是价格。
什么是时间步?
在RNN种,时间步指的是序列种每一个位置,比如:
对于序列【x1,x2,x3,x4,x5】,我们可以说它有5个时间步。
每个时间步都有一个输入x_t,RNN会根据当前输入和前一个隐藏状态来更新当前隐藏状态。
什么是样本?
一个样本是一个完整输入序列和目标,例如:
样本1:输入【x1,x2,x3,x4,x5】,目标预测x6
样本2:输入【x2,x3,x4,x5,x6】,目标预测x7
但是这样的样本存在一个问题,不同时间2个输入如果完全一样的,模型是区分不出时间概念的。
RNN怎么处理的呢?
向前传播:通过不断计算每一个时间步,得到隐藏状态h5,来预测x6。
向后传播:因为我们只有最后一个预测值,所以求导只能直接用最后一个∂L/∂h_T。那么我们要求导上一个咋办,∂L/∂h_(T-1)=∂L/∂h_T * ∂h_T/∂h_(T-1)。
我们算这些值干啥呢,目的什么?最终是要更新W_h和W_x和b的。因为算这些要用到。
因为∂h/∂W= ∂h/∂z * ∂z/∂W( 你看h_t的公式就明白了,这些都是大一高数,简单的很)
RNN的问题
梯度消失:早期的信息会再反向传播时逐渐冲淡,大破之模型难以学习长期依赖。
梯度爆炸:梯度在传播过程种指数级增长,导致训练不稳定。
【你看公式∂L/∂h_(T-1),发现很多个要乘,要么乘来乘去越来越小梯度消失;要么乘来乘去越来越大梯度爆炸】
那怎么解决?
LSTM和GRU,就是让模型记住该记住的,忘掉该忘掉的。
| 特征 | LSTM | GRU |
| 结构复杂度 | 较复杂(有三个门: 输入门,遗忘门,输出门) | 较简单(只有2个门:更新门,重置门) |
| 参数数量 | 更多 | 更少 |
| 训练速度 | 慢 | 快 |
| 表现能力 | 某些任务中更强 | 多数任务中表现相近或更优 |
| 控制机制 | 显示控制记忆单元 | 合并隐藏状态和记忆单元 |
LSTM:
- 遗忘门:决定保留多少过去的信息
- 输入门:决定当前输入对记忆的影响
- 输出门:决定当前记忆对输出的影响
- 记忆单元:贯穿整个序列
GRU:(为了简化LSTM)
- 更新门:控制当前状态和过去状态的融合程度
- 重置门:控制当前输入与过去的结合方式
- 没有单独记忆单元,隐藏状态本身就携带信息
LSTM适合长期依赖的复杂任务,比如机器翻译
GRU适合资源受限或者要求训练速度高,比如移动端部署,快速原型。
目前选择简单轻量的GRU来预测股市。
这些门会根据当前输入和过去的隐藏状态,计算一个“保留比例”:
- 如果当前输入和过去状态 高度相关,门就倾向于保留过去信息
- 如果当前输入和过去状态差异较大,门就倾向与更新为新信息
第二步 拉数据
https://tushare.pro/ 注意一个点,价格要拉前复权的。这里没得说,拉csv用就是了
第三步 pytorch搞模型训练
自己写GRU的,很简单。
第四步 调整参数
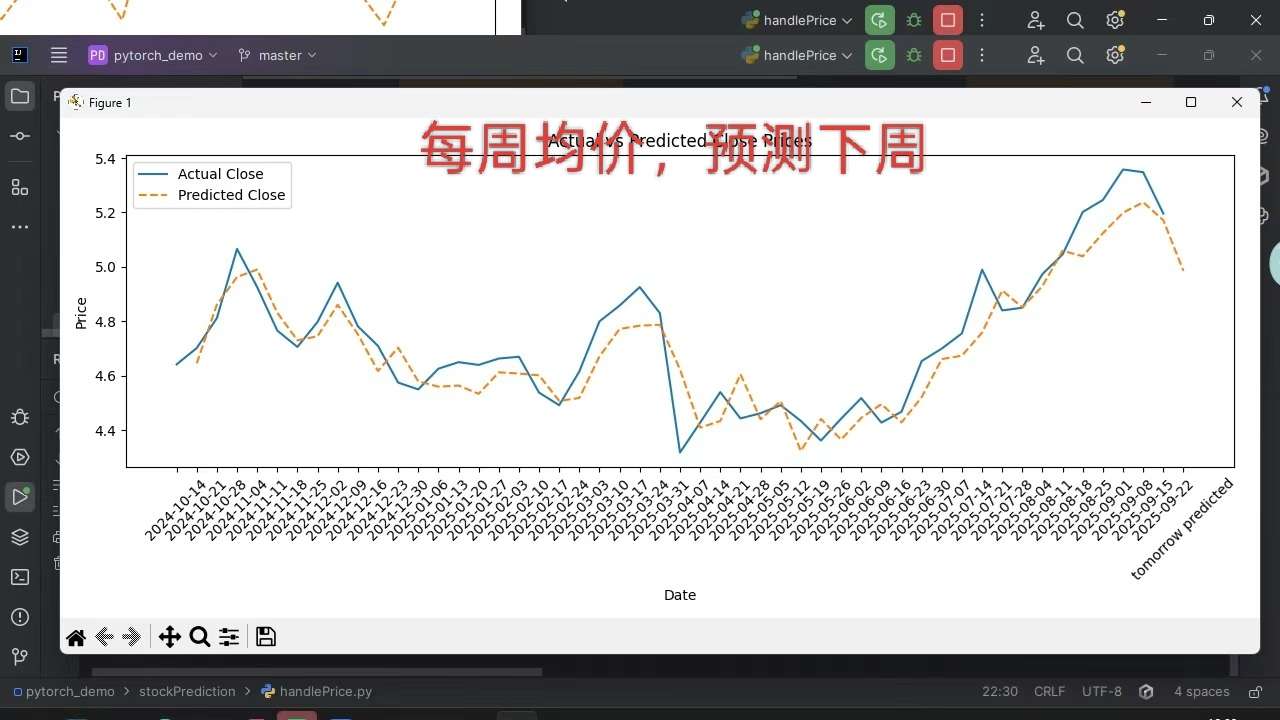
价格最好转成周平均,月平均,预测日的收盘价很难,波动大。
然后滑动窗口多大,选的股是季节性还是稳定向上的,波动大还是小的。得自己有个大致了解。
下图是中金岭南的,属于有色金属,季节性的。我来回收割过几波