光子计算突破:3ns超低延迟AI加速器精读分析:自然《一种具有超低延迟的大规模集成光子加速器》
全球顶级学术期刊《自然》(Nature)刊载了曦智科技的光电混合计算成果:《超低延迟大规模集成光子加速器》(An integrated large-scale photonic accelerator with ultralow latency)。
精读分析:自然《一种具有超低延迟的大规模集成光子加速器》
An integrated large-scale photonic accelerator with ultralow latency
本文报道了一种突破性的大规模集成光子计算系统,通过创新的光电协同设计与先进封装技术,在计算延迟和能效方面实现了数量级提升。以下从多个维度进行深入分析:
一、研究背景与核心创新
随着AI计算需求爆炸式增长,传统电子计算面临功耗墙和延迟瓶颈。光子计算虽具有高通量和低功耗潜力,但长期受限于大规模集成难题:
• 光子组件性能一致性难以保证
• 复杂电路缺乏标准化设计流程
• 光电协同封装技术不成熟
本研究通过16,000+光子元件集成(商业65nm硅光工艺)与2.5D先进封装,首次实现64×64光学矩阵乘加运算(oMAC),单周期延迟仅3ns,比传统TPU加速器提升两个数量级。
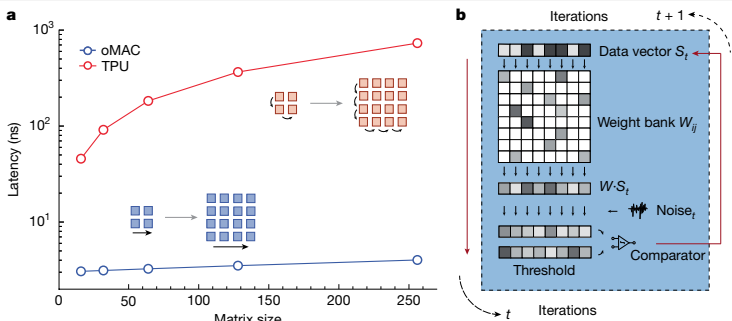
二、关键技术突破
- 系统架构设计
• 光电协同芯片:光子芯片(PIC)处理线性运算,电子芯片(EIC,28nm CMOS)实现逻辑控制与存储
• 异构集成方案:采用光纤阵列耦合外部激光源,通过光栅耦合器(插入损耗<3dB)实现光信号输入/输出
• 动态噪声调控:通过激光功率、TIA增益和数字噪声注入三重机制优化信噪比
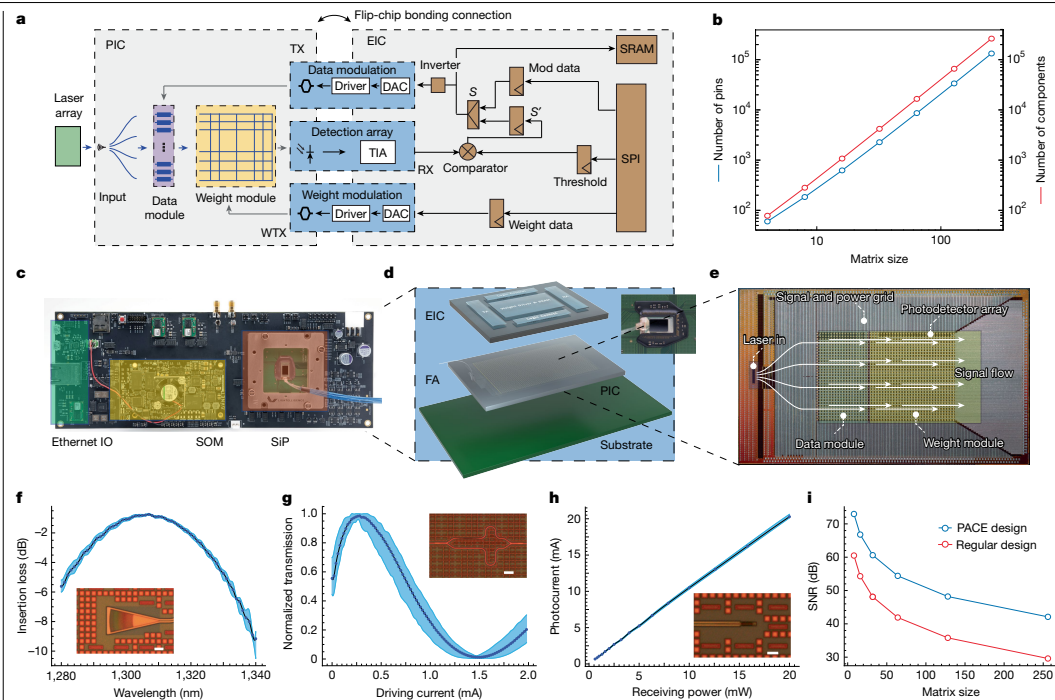
- 核心器件性能
• 马赫-曾德尔调制器:1GHz工作频率,NRZ调制方案
• 锗光电探测器:响应度一致性达1A/W(±5%波动)
• 光栅耦合器:3dB带宽>40nm,耦合效率>35%
• 权重调制器:8bit分辨率,10MHz重配置频率
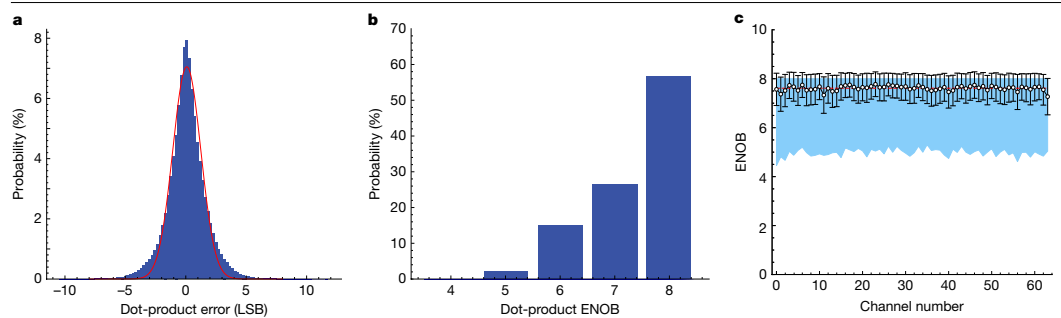
三、性能表征结果
- 计算精度
• 平均有效位数(ENOB):7.61bit
• 点积运算误差:0.06 LSB(均值),1.18 LSB(标准差)
• 温度容差:±5℃范围内性能衰减<1bit
- 能效指标
• 计算吞吐量:8.19 TOPS(含激光器)→ 2.38 TOPS/W
• 能效比:4.21 TOPS/W(不含激光器)
- 伊辛问题求解
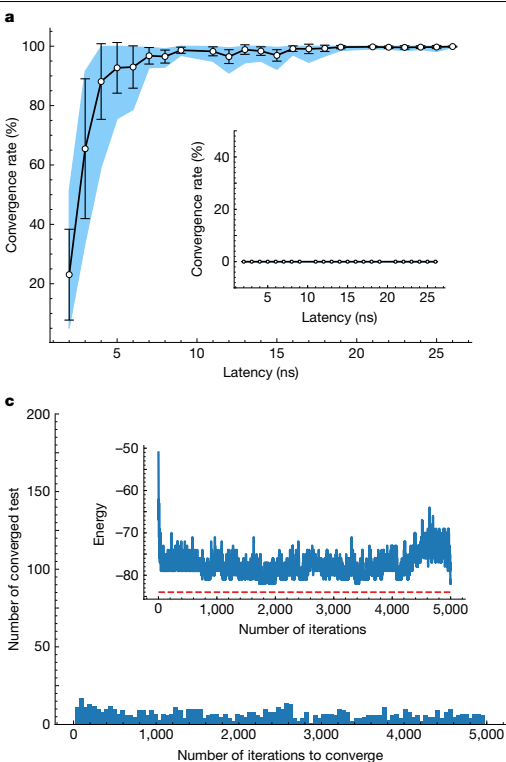
• 最大切割问题:6363节点图收敛率>92.72%(5ns延迟)
• 图像记忆问题:64像素猫图像重构成功
• 收敛迭代次数:平均537次(GPU需347次但单次延迟高)
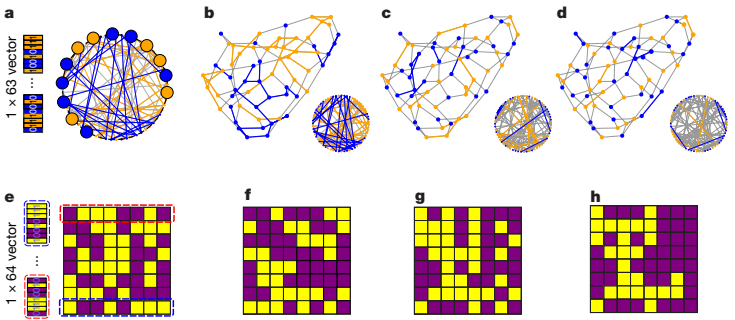
四、技术里程碑意义
- 首款万组件级光子计算芯片:突破光子集成规模瓶颈
- 纳秒级延迟优势:5ns单次迭代 vs GPU 2300ns
- 商业化可行路径:基于成熟半导体工艺(TSMC 65nm硅光)
- 算法-硬件协同设计:针对伊辛模型优化的光电联合架构
五、未来发展方向
- 波长分复用技术:进一步提升通量密度
- 主动反馈控制:增强温度稳定性和计算精度
- 三维集成技术:突破I/O密度限制
- 光电存算一体:集成非易失光子存储器
本研究通过系统性的光电协同创新,首次验证了大规模光子计算在实际优化问题中的超低延迟优势,为后摩尔时代计算架构发展提供了重要技术路径。其2.5D先进封装方案和商业化工艺适配策略,更凸显了工程落地的前瞻性设计。
注:本文实验数据截至2025年4月,发表于Nature主刊(Vol 640, 10 April 2025),所有图片版权归原作者所有