【迭代】本地高性能c++对话系统e2e_voice
为C++智能语音对话系统添加说话人识别功能:基于声纹的访问控制实现
引言
在构建智能语音对话系统时,安全性和个性化是两个重要的考量因素。本文将详细介绍如何为一个基于C++的端到端语音对话系统(ASR-LLM-TTS)添加说话人识别功能,实现基于声纹的访问控制,确保只有授权用户才能使用系统的核心功能。
项目地址
- GitHub: e2e_Voice
- 模型下载:系统首次运行时自动下载
项目背景
本项目是一个完整的C++智能语音对话系统,集成了:
- ASR(自动语音识别):基于SenseVoice模型
- LLM(大语言模型):通过Ollama集成各种开源模型
- TTS(文本转语音):基于Matcha-TTS的高质量语音合成
在实际应用场景中,我们需要限制系统的使用权限,避免未授权用户访问敏感功能。因此,我们引入了基于3D-Speaker Cam++模型的说话人识别功能。
技术架构
1. 系统整体架构
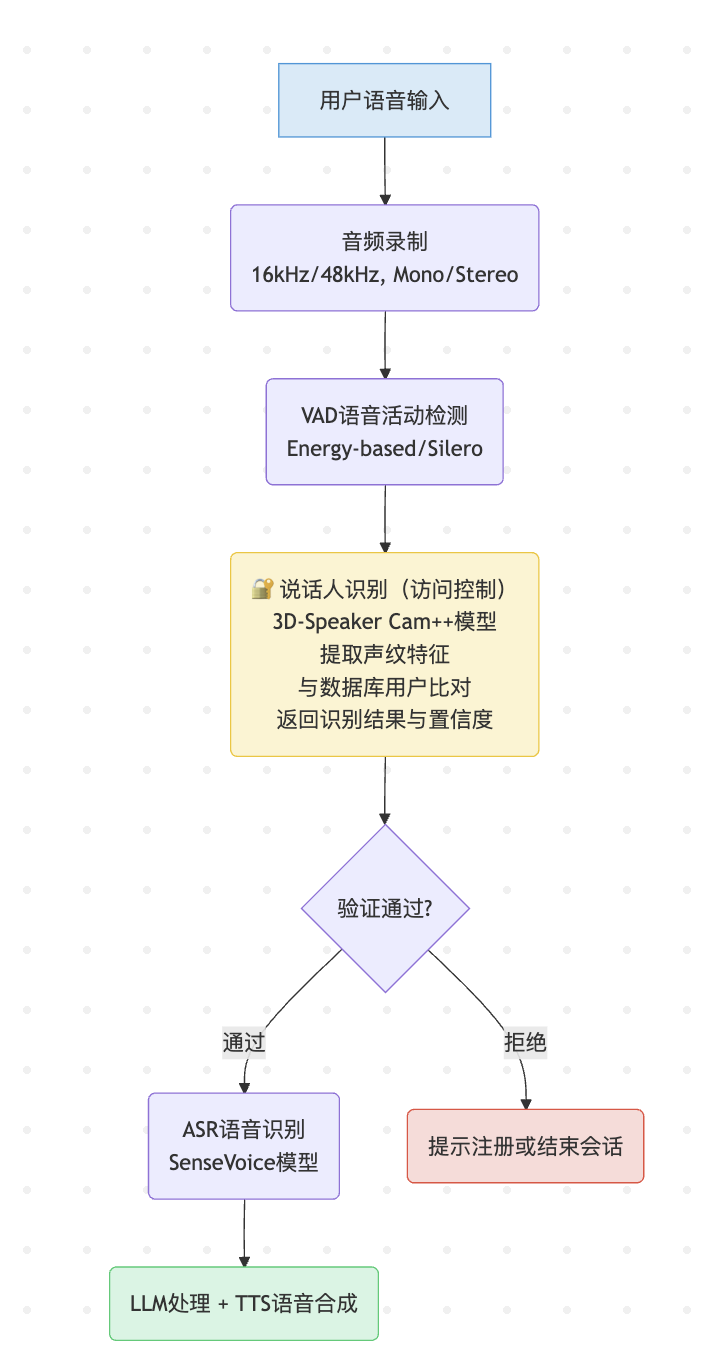
2. 核心模块设计
2.1 SpeakerEmbedder(声纹特征提取器)
class SpeakerEmbedder {
public:// 创建embedder实例static std::unique_ptr<SpeakerEmbedder> Create(const EmbedderConfig& config);// 获取嵌入向量维度(192维)virtual int32_t GetEmbeddingDimension() const = 0;// 创建音频流处理器virtual std::unique_ptr<Stream> CreateStream() const = 0;// 计算声纹嵌入向量virtual std::vector<float> ComputeEmbedding(const Stream* stream) const = 0;// 从文件直接计算嵌入向量virtual std::vector<float> ComputeEmbeddingFromFile(const std::string& filename) const = 0;
};
2.2 SpeakerManager(说话人数据库管理器)
class SpeakerManager {
public:// 注册说话人(支持多个样本)virtual bool RegisterSpeaker(const std::string& name,const std::vector<std::vector<float>>& embeddings) = 0;// 搜索说话人(基于余弦相似度)virtual std::string SearchSpeaker(const std::vector<float>& embedding,float threshold) const = 0;// 获取最佳匹配结果virtual std::vector<SpeakerMatch> GetBestMatches(const std::vector<float>& embedding,float threshold,int32_t max_results) const = 0;// 数据库持久化virtual bool SaveDatabase(const std::string& filename) const = 0;virtual bool LoadDatabase(const std::string& filename) = 0;
};
2.3 AudioRecorder集成(音频录制器增强)
class AudioRecorder {
public:struct Config {// 原有配置...// 说话人识别配置bool enable_speaker_recognition = false;float speaker_threshold = 0.6f;std::string speaker_database = "speakers.db";};// 初始化说话人识别bool initializeSpeakerRecognition();// 识别说话人std::string identifySpeaker(const std::vector<float>& audio);// 获取识别结果std::string getLastIdentifiedSpeaker() const;bool isSpeakerRegistered() const;private:std::unique_ptr<SpeakerEmbedder> speaker_embedder_;std::unique_ptr<SpeakerManager> speaker_manager_;std::string last_identified_speaker_;bool speaker_registered_ = false;
};
实现细节
1. 条件编译设计
为了保持系统的灵活性,我们使用条件编译来控制说话人识别功能:
#ifdef WITH_SPEAKER_RECOGNITION
bool AudioRecorder::initializeSpeakerRecognition() {// 初始化说话人识别模块SRModelDownloader downloader;if (!downloader.ensureModelsExist()) {return false;}// 创建embedderspeaker_recognition::EmbedderConfig config;config.model_path = downloader.getModelPath(SRModelDownloader::AR_MODEL_NAME);config.num_threads = 1;config.provider = "cpu";speaker_embedder_ = SpeakerEmbedder::Create(config);speaker_manager_ = SpeakerManager::Create(speaker_embedder_->GetEmbeddingDimension());// 加载数据库if (speaker_manager_->LoadDatabase(config_.speaker_database)) {std::cout << "[Speaker Recognition] Loaded "<< speaker_manager_->GetSpeakerCount()<< " speakers" << std::endl;}return true;
}
#else
// Stub实现
bool AudioRecorder::initializeSpeakerRecognition() { return true; }
#endif
2. 识别流程实现
std::string AudioRecorder::identifySpeaker(const std::vector<float>& audio) {// 1. 预处理音频(立体声转单声道)std::vector<float> mono_audio;if (config_.channels == 2) {for (size_t i = 0; i < audio.size(); i += 2) {float left = audio[i];float right = (i + 1 < audio.size()) ? audio[i + 1] : left;mono_audio.push_back((left + right) / 2.0f);}} else {mono_audio = audio;}// 2. 创建流并处理音频auto stream = speaker_embedder_->CreateStream();stream->AcceptWaveform(config_.sample_rate, mono_audio);stream->InputFinished();// 3. 计算声纹嵌入向量auto embedding = speaker_embedder_->ComputeEmbedding(stream.get());// 4. 获取最佳匹配auto matches = speaker_manager_->GetBestMatches(embedding, 0.0f, 5);std::cout << "[Speaker Recognition] Top matches:" << std::endl;for (const auto& match : matches) {std::cout << " - " << match.name << ": score=" << match.score<< (match.score >= config_.speaker_threshold ? " ✓" : " ✗")<< std::endl;}// 5. 返回识别结果return speaker_manager_->SearchSpeaker(embedding, config_.speaker_threshold);
}
3. 访问控制集成
在主程序中集成访问控制逻辑:
void ASRLLMTTSDemo::processVoiceInteraction() {// 1. 录音std::vector<float> audio = audio_recorder_->recordAudio();// 2. ASR语音识别std::string asr_result = asr_model_->recognize(audio);// 3. 说话人识别和访问控制if (params_.enable_speaker_recognition) {if (!audio_recorder_->isSpeakerRegistered()) {std::cout << "[Speaker Recognition] Speaker not recognized. "<< "Skipping LLM and TTS." << std::endl;std::cout << "Please register using register_speaker program." << std::endl;return; // 拒绝访问}std::cout << "[Speaker Recognition] Speaker verified: "<< audio_recorder_->getLastIdentifiedSpeaker() << std::endl;}// 4. LLM处理(仅授权用户)std::string llm_response = processWithLLM(asr_result);// 5. TTS合成(仅授权用户)playTTS(llm_response);
}
关键技术点
1. 采样率处理
说话人识别模型期望16kHz的音频输入,但实际录音可能是48kHz或其他采样率。系统会自动进行重采样:
if (config_.sample_rate != 16000) {std::cout << "[Speaker Recognition] WARNING: Sample rate mismatch! "<< "Got " << config_.sample_rate << "Hz but model expects 16000Hz"<< std::endl;
}
2. 多样本注册
为提高识别准确率,支持使用多个音频样本注册同一说话人:
// 使用多个音频文件注册
./register_speaker -n zhang_san sample1.wav sample2.wav sample3.wav// 系统会计算多个嵌入向量的平均值作为该说话人的特征
3. 阈值调优
系统提供灵活的阈值配置,可根据实际场景调整:
- 0.3-0.4:宽松模式,适用于环境噪声较大的场景
- 0.5-0.6:平衡模式,推荐设置
- 0.7-0.8:严格模式,高安全性要求场景
4. 调试信息
系统提供详细的调试输出,方便问题排查:
[Speaker Recognition] Starting identification...
[Speaker Recognition] Audio buffer size: 79872 samples (4.99s)
[Speaker Recognition] Processing 79872 samples at 16000Hz
[Speaker Recognition] Computing embedding...
[Speaker Recognition] Embedding computed, dimension: 192
[Speaker Recognition] Top matches:- muggle: score=0.59 ✓- john: score=0.32 ✗
[Speaker Recognition] Match found: muggle
使用示例
1. 注册说话人
# 使用音频文件注册
./register_speaker -n zhang_san voice1.wav voice2.wav voice3.wav# 通过麦克风注册(录制3次,每次4秒)
./register_speaker -n zhang_san# 查看已注册说话人
./list_speakers speakers.db
2. 启用说话人识别的对话系统
# 启动带说话人识别的系统
./asr_llm_tts \--enable_speaker \--speaker_threshold 0.5 \--speaker_database speakers.db \--device_index 1
3. 识别效果
=== Recording Phase ===
▶ Speech detected, starting recording...
⏹ Max recording time reached[Speaker Recognition] ✓ Identified speaker: zhang_san
Recording completed (5.00s)=== ASR Phase ===
ASR Result: 你好,请帮我查询天气[Speaker Recognition] Speaker verified: zhang_san=== LLM Phase ===
[Processing with LLM...]=== TTS Phase ===
[Playing synthesized speech...]
性能优化
1. 内存优化
- 使用移动语义减少内存拷贝
- 预分配向量空间避免动态扩展
- 条件编译减少不必要的内存占用
2. 计算优化
- ONNX Runtime推理加速
- 多线程并行处理
- 缓存已计算的嵌入向量
3. 准确性优化
- 多样本注册提升鲁棒性
- 自适应阈值调整
- 噪声抑制预处理
应用场景
- 企业会议系统:只有员工能使用AI助手
- 智能家居:家庭成员个性化服务
- 教育场景:学生身份验证
- 医疗咨询:患者隐私保护
- 金融服务:声纹认证增强安全性
未来展望
- 在线学习:支持动态更新说话人特征
- 情感识别:结合声纹识别情感状态
- 多语言支持:跨语言说话人识别
- 分布式部署:云端声纹数据库同步
- 隐私保护:联邦学习保护用户隐私
联系方式
- GitHub: muggle-stack
- 项目地址: e2e_voice
- 邮箱: promuggle@gmail.com
如果觉得这个项目对您有帮助,请给个⭐Star支持一下!
欢迎提交Issue和PR,一起完善这个开源语音对话系统!
开源许可:个人学习研究免费使用,商业用途需要许可